北京大学王选所推出 ALCUNA ,大模型新知识理解能力评测再添一榜!

夕小瑶科技说 原创
作者 | 付奶茶、ZenMoore
你是否好奇大型语言模型(LLMs)在面对未知新知识时会有怎样的表现呢?或者你想知道我们如何让这些大模型了解新知识呢?
让我们一起探索北京大学王选计算机研究所的研究工作。在这项研究中,他们采用了一种创新的方法,通过修改现有实体的属性和关系,快速生成全新的知识(保证是大模型没见过的)。这种方法旨在提升大型语言模型在新知识理解、区分和关联等方面的能力。这项工作的目标是让LLMs更好地应对新知识,使它们能够在新信息面前表现得更加智能和灵活。
论文标题:
ALCUNA: Large Language Models Meet New Knowledge
论文链接:
https://arxiv.org/pdf/2310.14820.pdf
前言
通常,我们将大多数知识表示为实体、它们所属的类别、它们的属性以及它们之间的关系。这种方式受到生物体的启发,因为生物体可以通过遗传和自然变异产生具有新特性的物种。这引发了一个有趣的问题:是否可以将类似的“遗传”和“变异”思维应用到更广泛的知识背景中?也就是说,知识是否也可以通过一种自然的方式不断继承和变异,产生新的知识形式?
这样,产生新的知识之后,我们就可以保证这些知识是大模型前所未见的,就可以用此来分析大模型面对未知新知识的各种能力和表现。
KnowGen 生产知识的方法
作者提出,同一类别的不同实体通常具有不同的属性和共性。一般而言,同一类别的实体在某种程度上相似,但它们也具备一些不同之处。借鉴生物学的术语,作者将这种相似实体之间的知识特性描述为"杂交能力"。这一观点启发了作者采用同一类别的不同实体,通过融合它们的属性来模拟生物的遗传和变异过程,从而生成全新的实体知识。
知识的形式化
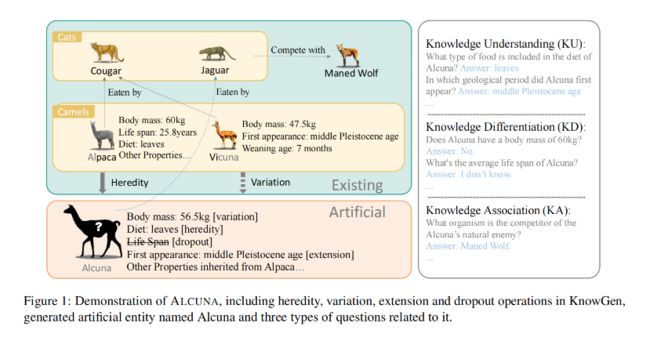
▲图1
作者采用实体的角度表示知识,实体 是世界中的一个独特和可识别的对象或个体,每个实体 可以拥有各种属性 ,值 描述实体的属性值。同时,每个实体与其他实体具有关系 . 实体 的属性和关系可以表示为一组性质三元组: 和 . 其中,具有相似特征的实体可以聚合到一个类别 中。为方便起见,将同一类别 中所有实体的相同性质表示为,在没有特殊说明的情况下,实体 的三元组 指的是它的唯一性质。例如,图1显示了这种结构化知识形式的示例,其中Alpaca和Vicuna都是属于Camels类别的现有实体,而Alcuna是生成的人工实体。Alpaca具有属性,如"体重"和关系(如"被...吃掉"),可以形成三元组,如(Alpaca,体重,60kg)和(Alpaca,被...吃掉,Puma)。
新实体的构建
研究的目标是合理地构建人工实体,以加速现实世界中大模型获取新知识的过程。在创建属于特定类别的人工实体时,它必须遵循同一类别中其他实体共享的某些共同属性。此外,人工实体必须具备一些使其与现有实体不同的独特属性。为了满足这些个性和共性的要求,作者融合了同一类别内实体的属性和关系。
-
选择一个来自特定类别 的现有实体 ,作为人工实体 的父实体,同时将同一类别 中的其他实体视为父实体的兄弟实体,表示为 . 目标是构建一个与父实体相似性较高的情况下符合类别的共性(遗传)的人工实体,同时融合来自兄弟实体的属性或合理改变属性值(变异)。如图1中的示例,人工实体Alcuna继承了父实体Alpaca的"Diet"和其他属性,但改变了"体重"。
-
对新实体的属性进行扩展和删除,以模拟人类对实体的渐进性认知过程。如图1中的示例,将"First appearance"属性从Vicuna扩展到Alcuna,并从父实体Alpaca中删除了"Life span"属性。
作为评估任务的问题回答
那构建了人工实体,怎么样评估模型面对这个新实体时候的表现呢?
作者提出,最自然的评估形式是在新知识的背景下向LLMs提出问题:
利用属性三元组 生成一次性问题 ,具体询问关于对象 的问题,给定主体 和属性 。通过一条关系三元组链:,构建一个多跳问题 ,询问关于尾对象 的问题,给定头部主体 和关系。
在面对新知识时,LLM需要具备知识理解、知识区分和知识关联能力。图1右侧展示了作者设计不同类别的问题来详细的评估。
ALCUNA 新的评估基准
数据集来源
借助前文提到的KnowGen工具,可以在现有的结构化知识基础上快速创建大量新的实体。基于这个能力,作者构建了一个用于评估模型在面对新知识时表现的生物学数据集,名为ALCUNA。这个数据集的信息来自EOL3(生命百科全书)数据库,这是一个在线可访问的数据库,旨在提供有关地球上已知所有物种的信息。EOL将所有生物实体组织成了一个分类树状结构,其中每个实体都属于某一个类别。
EOL数据库最引人注目的特点之一是它为每个生物实体构建了形式为键值对的丰富结构化数据,包括分类级别、属性、关系和信息来源等信息。这些数据为构建人工实体提供了有力支持。
具体而言,研究人员可以从EOL的分类树中选择一个特定类别,并将该类别中的成员视为潜在的实体,进而将它们划分为一个父实体 以及其兄弟.

在现实世界中,对于新发现的生物体,通常会采用与同一物种的其他生物体相似的前缀或后缀的命名方案。为了模拟这种现实情境,并考虑到大型语言模型(LLMs)中所使用的标记化算法,研究人员首先将相关现有实体的名称(即父实体和父实体的兄弟实体)进行了分词处理。接着,他们随机选择了与相关实体名称相对应的部分,并对于所选择的每一个实体,选取了其相应的子词。以"ALCUNA"为例,它是从Alpaca和Vicuna的名称中创建的。这一过程旨在在模型中模拟实际生物体命名方式,使得新构建的人工实体能够更好地融入已知的生物体类别中。
基于模版的问题生成
给定属性三元组或属性三元组链(多跳设置),目标是生成关于尾对象的自然语言问题。
在问题生成过程中,作者利用ChatGPT生成一个带有占位符[T]的问题模板,只提供相关属性,以避免引入太多特定实体的模型知识。然后,通过用头部主体的名称替换[T]来从问题模板生成问题。作者为每个属性组生成五个问题模板,形式为多项选择、填空和布尔问题。结果表明,生成的一次性问题中有98%是正确的;多跳问题中有95%是正确的。这表明这种问题构建方式是可以接受的。




通过前面的步骤构建了一个用于评估LLMs在面对新知识时的能力的数据集ALCUNA,其中包括关于3554个人工实体的共计84351个问题,每个人工实体平均包含11.75个属性三元组和25.39个兄弟实体。属性三元组数量的分布如图2所示。

作者将数据集组织成问题,并针对每个问题收集相应的属性三元组作为证据以及相关人工实体的信息作为新知识,将所有问题分为三个子集,KU、KD和KA。
在大模型上的实验
作者验证LLMs在基准测试中在不同设置下的表现如表1所示。

我们可以看到,在所有设置中,ChatGPT的性能最好,Vicuna在所有模型中表现第二好。在方法方面,少样本设置在整体上优于零样本设置,CoT在大多数情况下优于普通形式。面对新知识,除了ChatGPT在KU和KD实验上表现良好外,LLMs表现都较差。在所有能力中,知识关联显然是LLMs最难的,它们都难以通过提供的新知识与其内部知识相关联,因此难以正确进行多跳推理。知识理解和知识区分的表现优于知识关联,但对大多数LLMs来说仍然不令人满意。总之,目前的LLMs在面对新知识时表现相对较差,对知识理解和知识区分略有改善,但在跨越新知识和已有知识的推理方面更加困难。
此外,作者研究了实体相似性对模型在知识区分(KD)问题中表现的影响,KD问题旨在评估模型区分新知识和现有知识的能力,即属性相似性和名称相似性。
-
属性相似性:研究了实体之间属性重叠的比例,也称为属性相似性。实验结果表明,属性相似性对模型表现有影响,实体间属性越相似,模型越难区分它们,除了 ChatGPT 模型外,其他模型都受到实体相似性的影响。
-
名称相似性:名称对于模型的认知也有一定影响,相似的名称更容易导致模型混淆。不过,名称影响相对较小,结果略低,表明模型对新实体的建模既来源于名称又受属性的影响。
此外,还探究了在上下文中提供新知识的效果。特别是,加入父实体信息可能导致性能下降,因为模型会混淆新知识和内部知识。此外,链式实体对知识关联至关重要,模型在知识关联问题上表现不佳。
最后,研究表明,结构化知识输入方式更有助于模型理解高密度知识输入。这表明提出的清晰而结构化的表示对于模型的理解更有帮助。
对于将 ALCUNA 基准应用于其他模型,有两个不同的应用场景。首先,可以直接使用 ALCUNA 评估不同LLM在面对新知识时的知识理解性能。另一方面,如果要比较知识区分和关联能力,不同模型内部的不同背景知识可能会导致不公平的比较。因此,需要对ALCUNA进行额外的筛选,以确保所有模型都拥有的现有实体,尽管这将导致基准的缩减。然而,可以合理假定随后的模型将变得更加强大,因此缩减的影响不会非常严重。
小结
北京大学王选计算机研究所进行的研究探索了大型语言模型(LLMs)如何应对和理解它们以前未见过的新知识。这项研究的核心是通过模拟遗传和变异的方法,对现有的知识实体进行修改以生成全新的实体知识。这种方法的灵感来源于生物学,其中物种可以通过遗传和变异产生新的特性。
研究中提出了一个名为"KnowGen"的方法,通过结合同一类别内的不同实体的属性来模拟生物的遗传和变异过程,从而生成全新的实体知识。此外,研究还创建了一个名为"ALCUNA"的评估基准,用于评估LLMs在面对新知识时的表现。这个基准的数据集是基于EOL3(生命百科全书)数据库构建的,并通过特定的方法生成新的实体和问题。
实验结果显示,虽然某些LLMs(如ChatGPT)在某些任务上表现良好,但大多数LLMs在面对新知识时的表现仍然不佳。特别是在知识关联任务上,模型的表现显然是最困难的。
总的来说,该研究为我们提供了深入了解大型语言模型在面对新知识时的能力和局限性的宝贵机会,并为未来的研究提供了一个有用的工具和基准。