内存DMA及设备内存控制详解
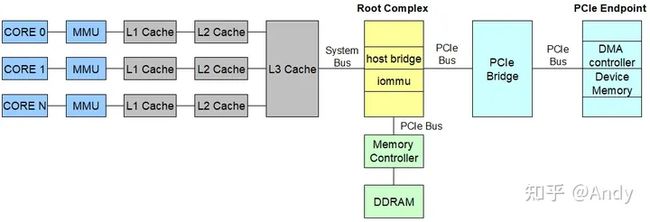
序言
对于PCIe 设备(PCIe Endpoint)来说,其和CPU CORE、DRAM 的交互,主要涉及两种类型的内存访问:
- 设备内存访问:PCIe 设备的 Device Memory(设备内存)的访问,例如CPU 需要读写配置 PCIe 网卡或显卡的 寄存器(设备内存)。发起者是CPU,响应者是设备。
- DMA内存访问:PCIe 设备需要 DMA 读写 主机的 DRAM 内存,例如 网卡收到数据报文后,需要将其上报主机,则通过 PCIe Endpoint 中的 DMA 控制器 进行 DMA 写 主机的 DRAM 内存。发起者是设备DMA控制器,响应者主机内存DRAM,不需要CPU的参与。
以CPU CORE 发起设备内存读访问为例。从上图的左侧开始,CPU CORE 执行程序指令时,发出内存读写访问的地址是虚拟地址,接着MMU(内存管理单元或称为地址翻译单元更好) 将该虚拟地址转换为物理地址。如果物理地址访问的数据不在Cache中,则通过 Root Complex 中的 host bridge,将物理地址转换为总线地址,最后基于总线地址访问设备内存空间(Device Memory)。本文将基于上图的计算机系统架构,追本溯源,详细的解释设备内存 和 DMA内存 的访问细节。
重要概念
对于本文架构图中涉及的主要概念解释如下,如果不想被概念搞晕,建议暂时滤过,等不清楚时再回查即可。
System Bus:系统总线,用于CPU Package 内部子系统之间的连接,例如连接L3 Cache 和 Root Complex。
Cache:X86 的 Cache 通常分为三级,各个CPU CORE 有自己的 L1和L2 Cache,所有CPU CORE 共享 L3 Cache。Intel I7 L3 为 8MB,L2 256KB,L1 共64KB,所以Cache Size从 L1 到L3是递增。对于程序指令或数据都可以加载到Cache,加载的单位是 Cache Line,通常为 64B。
Root Complex:其中包括了两个重要组件,一个是 PCIe Root Bridge,通常称为 Host Bridge,其 Bus:Device. Function 为 00:00.0;另一个是 iommu,其用于将设备(如PCIe Endpoint 网卡)发起DMA读写DRAM使用的总线地址,转换为DRAM内存的 物理地址。
Memory Controller:DRMA 内存控制器,通常包含在CPU package 中,用于控制对内存的访问。
PCIe bus:PCIe 总线,用于连接 Host Bridge 到 PCIe Switch,PCIe Bridge 以及 PCIe Endpoint。
DMA Controller:DMA 控制器,其通常位于 PCIe Endpoint 内,用于设备对 DRAM 中数据进行 ”DMA 读”或“DMA 写”。
Device Memory:设备内存,用于对设备进行控制,如配置设备、获取设备状态等;在系统对PCIe 总线进行深度优先扫描时,会根据设备的 Bar 空间大小(Device Memory Size,如下面的网卡例如,Bar 0,2,4 Size 分别为64K,1M,8K),分配 iomem 中映射的物理地址,下文会提到 iomem 的细节。

内存访问
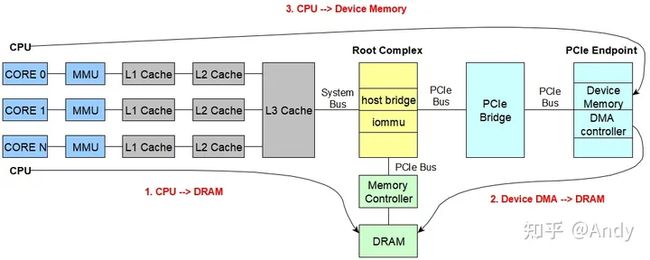
如前面所所述,计算机内部主要涉及两种内存访问。一种是 物理内存DRAM,另一种是 设备内存(如网卡,显卡等PCIe设备)。
内存访问方向
以上两种类型内存的访问,主要包括上图中三个方向:
- CPU -> DRAM: 从CPU 读写物理内存中的数据或程序指令;
- Device DMA -> DRAM: 设备的DMA 控制器发出针对DRAM的 DMA 读写,例如网卡从物理内存中DMA读取数据包进行发包。
- CPU -> Device Memory: 主机CPU 发出针对设备的读写,例如主机需要初始化设置显卡寄存器,让其开始工作。
内存访问过程
A. CPU访问物理内存(CPU -> DRAM)
- CPU使用虚拟地址发出内存读写请求
- MMU将虚拟地址转为DRAM的物理地址
- 如果访问数据的物理地址在Cache 有缓存数据,则直接从Cache 读取即可
- 如果Cache 中没有缓存,则通过内存控制器,访问DRMA(当然这涉及到页表的管理,不在本文的讨论范围),如果有兴趣,强烈建议深入阅读《深入理解计算机系统》
B. 设备访问物理内存(Device DMA -> DRAM)
- 外设使用总线地址,发起针对DRAM的DMA读写访问
- IOMMU负责将总线地址转为物理地址
- 通过内存控制器,访问DRMA
C. 设备内存访问(CPU -> Device Memory)
- CPU使用虚拟地址发出内存读写请求
- MMU将虚拟地址转为设备内存的物理地址(通过 cat /proc/iomem 可以查看到)
- Host Bridge 将物理地址转为总线地址
- 通过PCIe总线寻址到设备,并进行设备内存读写
总结:访问物理内存时,可以认为 虚拟地址 和 总线地址 都是Virtual的地址,都需要通过一个地址转换硬件(CPU侧是MMU,device侧是IOMMU),将虚拟地址转换为物理内存DRAM的实际物理地址。而访问设备内存时,通过Host Bridge将物理地址转换为设备内存的总线地址。
地址空间

虚拟地址:CPU Virtual Address Space(VA)
虚拟地址 被主机CPU用于访问物理内存,或者设备(PCIe EP Device)的 Bar 空间的内存(寄存器)。每个进程都有相同的虚拟地址空间(例如32位Linux系统,最大支持4G的地址空间,但只有高地址3GB用于进程的虚拟地址空间,低地址或顶端的1G给内核使用)。CPU执行指令访问内存使用的地址是虚拟地址,然后通过MMU、TLB 及 Page Tables 将虚拟地址转换为内存的物理地址。
物理地址:CPU Physical Address Space(PA)
我们可以认为物理地址空间,就是所有硬件的内存映射空间(MMIO- memory map I/O)。可将物理内存RAM看成一种特殊的MMIO空间。OS在给硬件设备编址时,其会看到物理内存 以及设备内存(通过PCIe Bar 空间映射的设备寄存器),所以进行了统一的物理地址的编址。如下,低地址给RAM使用,而PCI 设备内存通常位于高地址。
物理地址空间的编址 可以通过 cat /proc/iomem 查看:
[root@node2 ~]# cat /proc/iomem
00000000-00000fff : Reserved
00001000-0005cfff : System RAM // System RAM:物理内存
0005d000-0005dfff : Reserved
0005e000-0009ffff : System RAM
......
00100000-3fffffff : System RAM // Kernel Space
01000000-01c00ea0 : Kernel code
01e00000-02214fff : Kernel rodata
02400000-026294bf : Kernel data
02893000-02bfffff : Kernel bss
......
8f800000-dfffffff : PCI Bus 0000:00 // PCI Root Bridge Bus 0 下挂PCIe 设备内存的总大小
8f800000-8f9fffff : PCI Bus 0000:02
8fa00000-8fbfffff : PCI Bus 0000:02
8fc00000-8fdfffff : PCI Bus 0000:04
8fe00000-8fffffff : PCI Bus 0000:04
90000000-9fffffff : 0000:00:02.0
90000000-902fffff : BOOTFB
a0000000-a02fffff : PCI Bus 0000:01 // PCIe bus 01 下挂PCIe 设备内存的总大小
a0000000-a00fffff : 0000:01:00.1 // PCIe 网卡 Bar 2 空间(设备内存)映射的物理内存
a0000000-a00fffff : bnxt_en
a0100000-a01fffff : 0000:01:00.0
a0100000-a01fffff : bnxt_en
a0200000-a020ffff : 0000:01:00.1 // PCIe 网卡 Bar 0 空间(设备内存)映射的物理内存
a0200000-a020ffff : bnxt_en
a0210000-a021ffff : 0000:01:00.0
a0210000-a021ffff : bnxt_en
a0220000-a0221fff : 0000:01:00.1 // PCIe 网卡 Bar 1 空间(设备内存)映射的物理内存
a0220000-a0221fff : bnxt_en
a0222000-a0223fff : 0000:01:00.0
a0222000-a0223fff : bnxt_en
a0224000-a0243fff : 0000:01:00.1
a0244000-a0263fff : 0000:01:00.1在作者使用这台主机上,物理地址范围 a0000000-a02fffff 对应: PCI Bus 0000:01。该Bus位于PCI Bridge 和 PCI Endpoint之间(可以回到文章开始的图查看),所以可以通过命令 ( lspci -s 00:01.0 -vvv )查看到 Bus 上一级 Bridge 的信息,得到Bridge下挂设备的总地址空间,即下图中可以被CPU访问预取的 Memory 范围:00000000a0000000-00000000a02fffff

而在该PCI Bridge下,下挂PCIe Endpoint的其中一个Function(01:00.1),其 Bar2 对应物理地址范围:a0000000-a00fffff : 0000:01:00.1(Bus:Device.Function),即为 PCIe 网卡 Bar 2(下图Region 2)空间(设备内存)映射的物理地址空间。
总线地址:Bus Address Space(BA)
总线地址是为 终端设备读写DMA 内存 或者 主机读写设备配置空间(PCIe Bar)使用的总线地址空间的地址(PCI 总线)。
我们在调用【dma = dma_map_single(device, buf, size, DMA_TO_DEVICE)】,将数据 buf(虚拟地址) 建立 dma地址映射给device 访问时,返回的类型为 dma_addr_t 的 dma 地址,就是 bus address。该地址可以传给设备用于DMA的物理内存数据读取。
在一些系统中,总线地址和物理地址是一样的(我们可以调用 phy = virt_to_phys(buf) 得到虚拟地址buf 对应的物理地址 phy, 确认 phy 和 dma 地址是否相同)。Host Bridge和 IOMMU可以实现 物理地址和总线地址的任意映射。
注意:从设备的角度,不管是访问设备内存,或者设备发起DMA读写,都是使用的总线地址。
访问过程详解

CPU 读取设备内存
首先,CPU需要通过ioremap,将虚拟地址A映射到物理地址空间 MMIO 中物理机地址B;
然后,CPU发起 ioread、iowrite 请求,发起时用的虚拟地址C,接着MMU转换为物理地址B;
最后,PCIe Host Bridge 将物理地址B转换为总线地址A,通过总线地址A对Bar空间进行读写。
注意:对Bar Register 的读写基于 PCIe的 Configuration TLP 操作。
代码示例:
/* CPU ioremap */
struct pci_dev *pdev;
u8 __iomem *hw_addr = ioremap(pci_resource_start(pdev, 0),
pci_resource_len(pdev, 0));
u32 val = 10;
u32 reg_offset = 0;
/* 将 10 写入hw_addr[reg_offset] */
writel(val, &hw_addr[reg_offset]);
value = readl(&hw_addr[reg]);
Device DAM 访问物理内存
首先,CPU基于虚拟机地址X,通过MMU,将数据写入物理地址Y对应的 物理内存中;
然后,CPU 调用如dma_map_single 这样的API,将总线地址Z 映射到 虚拟地址X和物理地址Y。
最后,Device 通过总线地址Z,发出DMA读请求(PCIe Memeory Read),接着IOMMU将总线地址翻译为物理地址Y 去 读写物理内存 DMA Buffer.
编程示例:
struct device *dev; /* device for DMA mapping */
struct sk_buff *skb;
dma = dma_map_single(dev, skb->data, size, DMA_TO_DEVICE);
/* tx_desc 是网卡发包时用到的描述符,
* 硬件设备可以通过DMA 访问到描述符绑定的dma地址,然后硬件可以基于该DMA地址发起内存访问
*/
tx_desc->read.buffer_addr = cpu_to_le64(dma);DMA映射编程
常用的DMA映射有两种类型,一种是一致性DMA映射(consistent DMA mapping);另一种是流式DMA映射(streaming DMA mapping)。理解这两种常用的 DMA映射类型,是编程的基础。
一致性DMA映射
一致性DMA 映射关闭了 L1/L2/L3 Cache。首先,当 CPU 写入数据时,则会直接放入内存,而不会在Cache进行缓存,所以设备可以立即DMA读取到CPU写入的数据;其次,当设备DMA写入数据到内存后,则CPU可以立即读取到该变化的数据,而不会读取Cache中的脏数据,因为Cache关闭了。
Consistent DMA mapping的常用场景:
- 网卡驱动程序 和 网卡DMA控制器往往是通过内存中的一些描述符(形成环)进行交互(描述符中包括收发数据包用到的大块DMA内存地址),这些保存描述符的memory,需要被主机CPU和网卡DMA控制器频繁的读写,并且在任何一端写,都需要另一端立即可以访问到,所以通常采用Consistent DMA mapping比较方便。
2. SCSI硬件适配器上的DMA 与 主存中的一些数据结构(mailbox command)进行交互,这些保存mailbox command的memory一般采用Consistent DMA mapping。
代码示例
如下调用 dma_alloc_coherent 分配一块一致性DMA内存(取自intel ixgbe驱动 linux-4.18.0-348\drivers\net\ethernet\intel\ixgbe\ixgbe.h & linux-4.18.0-348\drivers\net\ethernet\intel\ixgbe\ixgbe_main.c):
struct ixgbe_ring {
struct device *dev; /* device for DMA mapping */
void *desc; /* descriptor ring memory */
dma_addr_t dma; /* phys. address of descriptor ring */
unsigned int size; /* length in bytes */
u16 count; /* amount of descriptors */
}
/**
* ixgbe_setup_tx_resources - allocate Tx resources (Descriptors)
* @tx_ring: tx descriptor ring (for a specific queue) to setup
*
* Return 0 on success, negative on failure
**/
int ixgbe_setup_tx_resources(struct ixgbe_ring *tx_ring)
{
struct device *dev = tx_ring->dev;
// 返回是 DMA地址 对应的虚拟地址 (tx_ring->desc)
tx_ring->desc = dma_alloc_coherent(dev, // 进行DMA映射的PCI设备对应的device
tx_ring->size, // 描述符环对应的总大小(bytes)
&tx_ring->dma, // 输出:DMA 地址
GFP_KERNEL);
...
}参考内核 Document/core-api/dma-api.rst
void *
dma_alloc_coherent(struct device *dev, size_t size,
dma_addr_t *dma_handle, gfp_t flag)
Consistent memory is memory for which a write by either the device or
the processor can immediately be read by the processor or device
without having to worry about caching effects.流式DMA映射
因为一致性DMA关闭了Cache,虽然使用带来了方便,但是会牺牲数据读写的性能。例如Intel当前的CPU package,支持在 PCIe Endpoint DMA 访问内存时,将数据放入到L3 Cache,然后DMA 控制器从L3 Cache 读取数据(这是对我们DMA控制器直接访问DRAM内存常识的挑战)。而这些硬件的优化,在使用流式DMA影射时,可以充分发挥性能的优势。
streaming DMA mapping的常用场景:
- 网卡进行数据传输使用的DMA buffer,发送数据是,主机准备好DMA Buffer,由硬件DMA读取;接受数据时,也是主机准备好DMA Buffer,由硬件DMA 写入接受到的数据。
- 文件系统中的各种数据buffer,这些buffer中的数据最终要被读写到SCSI设备上去
代码示例1
如下dma_map_single 将 虚拟地址 skb->data 指向的内存,映射到dma 总线地址上,然后将dma 地址写入描述符给硬件DMA读取 skb->data 指向的内存数据。
需要注意的是,skb->data 指向的数据区域需要是连续物理内存。内核采用带k字的分配函数(如kmalloc)即得到连续的物理内存,而使用v开头的分配函数,如vmalloc,则不能保证。
struct device *dev; /* device for DMA mapping */
struct sk_buff *skb;
dma = dma_map_single(dev, skb->data, size, DMA_TO_DEVICE);
/* tx_desc 是网卡发包时用到的描述符,
* 硬件设备可以通过DMA 访问到描述符绑定的dma地址,然后硬件可以基于该DMA地址发起内存访问
*/
tx_desc->read.buffer_addr = cpu_to_le64(dma);代码示例2
如下调用dev_alloc_pages 分配一个page,再调用 dma_map_page_attrs 将该页映射dma 地址,最后调用dma_sync_single_range_for_device 将页面的数据同步给设备访问:
struct page *page;
dma_addr_t dma;
struct device *dev; /* device for DMA mapping */
int page_size = PAGE_SIZE;
/* alloc new page for storage */
page = dev_alloc_pages(0);
/* map page for use */
dma = dma_map_page_attrs(dev, page, 0,
page_size,
DMA_FROM_DEVICE,
DMA_ATTR_SKIP_CPU_SYNC);
/* sync the buffer for use by the device */
dma_sync_single_range_for_device(dev, dma,
0, page_size,
DMA_FROM_DEVICE);
总结
本文结合计算机系统的架构,我们从内存访问的角度,介绍了各种地址空间(虚拟、物理、总线)的概念。以及物理内存和设备内存访问三个方向(CPU->DRAM, CPU -> Device Memory, Device DMA -> DRAM)。最后介绍了DMA 映射编程常用的方法,如果觉得不过瘾,建议继续研究作者参考的内核 Document。
参考
1,linux-4.18.0-348/Document/core-api/dma-api-howto.rst
2,linux-4.18.0-348/Document/core-api/dma-api.rst