网络爬虫——urllib(5)
前言
❤️❤️❤️网络爬虫专栏更新中,各位大佬觉得写得不错,支持一下,感谢了!❤️❤️❤️
Python网络爬虫_热爱编程的林兮的博客-CSDN博客
上一篇我们讲解有关ajax的相关案例,下面我们来学习新的关于urllib的知识。
11、URLError\HTTPError
简介:
- HTTPError类是URLError类的子类
- 导入的包urllib.error.HTTPError urllib.error.URLError
- http错误:http错误是针对浏览器无法连接到服务器而增加出来的错误提示。引导并告诉浏览者该页是哪里出 了问题。
- 通过urllib发送请求的时候,有可能会发送失败,这个时候如果想让你的代码更加的健壮,可以通过try‐ except进行捕获异常,异常有两类,URLError\HTTPError
那我们下面来举一个例子,获取下面页面的网页源码

正常代码:
# 异常
import urllib.request
url ="https://blog.csdn.net/m0_63951142/article/details/134013573"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request = urllib.request.Request(url = url, headers = headers)
response = urllib.request.urlopen(request)
content =response.read().decode('utf-8')
print(content)运行代码:

我们这是不是就爬取成功了,但是如果我们万一有哪些地方出错了,比如url多了一个1,我们就需要添加try‐ except进行捕获异常
# 异常
import urllib.request
import urllib.error
url ="https://blog.csdn.net/m0_63951142/article/details/1340135731"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
try:
request = urllib.request.Request(url = url, headers = headers)
response = urllib.request.urlopen(request)
content =response.read().decode('utf-8')
print(content)
except urllib.error.HTTPError:
print('系统正在升级!')我们这代码url错误,可以提供添加try‐ except进行捕获异常
运行结果:

那么什么时候报URLError呢?一般是主机地址和参数地址错误
# 异常
import urllib.request
import urllib.error
# url ="https://blog.csdn.net/m0_63951142/article/details/1340135731"
url = "https://www.linxi.com"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
try:
request = urllib.request.Request(url = url, headers = headers)
response = urllib.request.urlopen(request)
content =response.read().decode('utf-8')
print(content)
except urllib.error.HTTPError:
print('系统正在升级!')运行结果:

这时候就会报URLError了
那我们一样添加try‐ except进行捕获异常:
# 异常
import urllib.request
import urllib.error
# url ="https://blog.csdn.net/m0_63951142/article/details/1340135731"
url = "https://www.linxi.com"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
try:
request = urllib.request.Request(url = url, headers = headers)
response = urllib.request.urlopen(request)
content =response.read().decode('utf-8')
print(content)
except urllib.error.HTTPError:
print('系统正在升级!')
except urllib.error.URLError:
print('系统真的在升级!!!!')运行结果:

12、cookie登录
那什么是cookie登录呢?
在适用的场景下,数据采集的时候 需要绕过登陆 然后进入到某个页面
我们打算去获取下面这个页面的源码
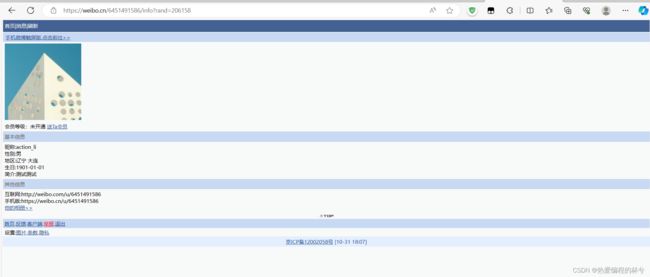
代码:
# 适用的场景:数据采集的时候 需要绕过登陆 然后进入到某个页面
import urllib.request
url = 'https://weibo.cn/6451491586/info'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/92.0.4515.159 Safari/537.36',
}
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
# 将数据保存到本地
with open('weibo.html', 'w', encoding='utf-8') as fp:
fp.write(content)
运行结果:
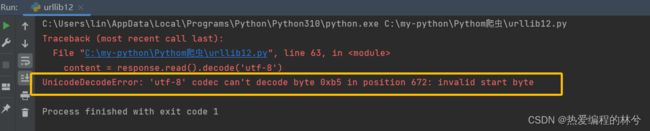
发现报错了,提示字符编码不对,不是utf-8,难度页面字符编码不是utf-8吗?
这是因为这是一个经典的反爬手段(个人信息页面是utf-8 但是还报错了编码错误 ,因为并没有进入到个人信息页面 而是跳转到了登陆页面 )

可以看到这不是utf-8,所以我们需要去修改我们的代码,获取的响应数据时的decode应该设置为(gb2312)
import urllib.request
url = 'https://weibo.cn/6451491586/info'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('gb2312')
# 将数据保存到本地
with open('weibo.html', 'w', encoding='gb2312') as fp:
fp.write(content)我们继续运行代码,就将源码下载下来了:

在浏览器打开html页面,但是它会一直在转圈圈:

这是因为什么呢? 因为请求头的信息不够 所以访问不成功
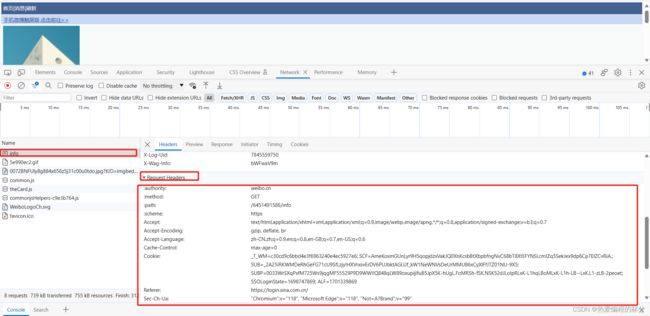
所以我们在Request Headers中需要添加新的信息:
# 适用的场景:数据采集的时候 需要绕过登陆 然后进入到某个页面
# 个人信息页面是utf-8 但是还报错了编码错误 因为并没有进入到个人信息页面 而是跳转到了登陆页面
# 那么登陆页面不是utf-8 所以报错
# 什么情况下访问不成功?
# 因为请求头的信息不够 所以访问不成功
import urllib.request
url = 'https://weibo.cn/6451491586/info'
headers = {
# 带冒号的不好使
# ':authority': 'weibo.cn',
# ':method': 'GET',
# ':path': '/6451491586/info',
# ':scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,'
'application/signed-exchange;v=b3;q=0.9',
# 'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
# cookie中携带着你的登陆信息 如果有登陆之后的cookie 那么我们就可以携带着cookie进入到任何页面
'Cookie':
'_T_WM=c30cd9c6bbd4e3f6963240e4ec5927e6; '
'SCF=AmeKosmGUnLyr9H5qopjdzxVakJQ0XnKcsbBtXbpbfngNvC68bT8XtEFYNSLcmIZq5SekJex9dp6Cp7ElZCvRiA.; '
'SUB=_2A25IRKWMDeRhGeFG71cU9SfLzjyIHXVrxsvErDV6PUJbktAGLUf_kW1NeWNVsDeUrMMUB6xCyXlFfJTZ01NU-9X5; '
'SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WWIIQ848qLW89oxupijIfuB5JpX5K-hUgL.FoMRSh-fSK.NSK52dJLoIpRLxK'
'-L1hqLBoMLxK-L1h'
'-LB--LxK.L1-zLB-2peoet; SSOLoginState=1698747869; ALF=1701339869',
# referer 判断当前路径是不是由上一个路径进来的 一般情况下 是做图片防盗链
'referer': 'https://weibo.cn/',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/92.0.4515.159 Safari/537.36',
}
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
# 将数据保存到本地
with open('weibo.html', 'w', encoding='utf-8') as fp:
fp.write(content)
注:字符编码需要重新修改为utf-8
运行成功,我们继续在浏览器中打开wbibo.html:

成了!

通过以上步骤,我们就可以实现爬虫cookie登录,从而获取目标网站的数据。需要注意的是,不同的网站可能有不同的登录机制,因此在实际操作时需要根据具体情况进行调整。