RocketMQ(7)消费者核心配置和核心知识
1、消息队列RocketMQ4.X消费者核心配置

- consumeFromWhere配置(某些情况失效:参考https://blog.csdn.net/a417930422/article/details/83585397)
创建新的topic和group组的时候有可能存在消费之前历史消息(存在内存中的)
CONSUME_FROM_FIRST_OFFSET: 初次从消息队列头部开始消费,即历史消息(还储存在broker的)全部消费一遍,后续再启动接着上次消费的进度开始消费
CONSUME_FROM_LAST_OFFSET: 默认策略,初次从该队列最尾开始消费,即跳过历史消息,后续再启动接着上次消费的进度开始消费
CONSUME_FROM_TIMESTAMP : 从某个时间点开始消费,默认是半个小时以前,后续再启动接着上次消费的进度开始消费
- allocateMessageQueueStrategy:
负载均衡策略算法,即消费者分配到queue的算法,默认值是AllocateMessageQueueAveragely即取模平均分配
- offsetStore:消息消费进度存储器 offsetStore 有两个策略:
LocalFileOffsetStore 和 RemoteBrokerOffsetStor 广播模式默认使用LocalFileOffsetStore 集群模式默认使用RemoteBrokerOffsetStore
- consumeThreadMin 最小消费线程池数量
- consumeThreadMax 最大消费线程池数量
- pullBatchSize: 消费者去broker拉取消息时,一次拉取多少条。可选配置
- consumeMessageBatchMaxSize: 单次消费时一次性消费多少条消息,批量消费接口才有用,可选配置
- messageModel : 消费者消费模式, CLUSTERING——默认是集群模式CLUSTERING BROADCASTING——广播模式
2、集群和广播模式下RocketMQ消费端处理
Topic下队列的奇偶数会影响Customer个数里面的消费数量
如果是4个队列,8个消息,4个节点则会各消费2条,如果不对等,则负载均衡会分配不均,(让每个消费者分配多个相同的queue个数)
如果consumer实例的数量比message queue的总数量还多的话,多出来的consumer实例将无法分到queue,也就无法消费到消息,也就无法起到分摊负载的作用,所以需要控制让queue的总数量大于等于consumer的数量
- 集群模式(默认):
Consumer实例平均分摊消费生产者发送的消息
例子:订单消息,一般是只被消费一次
- 广播模式:
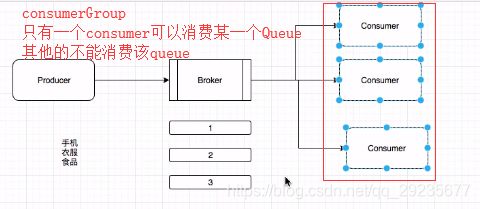
广播模式下消费消息:投递到Broker的消息会被每个Consumer进行消费,一条消息被多个Consumer消费,广播消费中ConsumerGroup暂时无用
例子:群公告,每个人都需要消费这个消息
群聊
- 怎么切换模式:通过setMessageModel()

3、RocketMQ4.X里面的标签Tag实战和消息过滤原理
一个Message只有一个Tag,tag是二级分类
订单:数码类订单、食品类订单
过滤分为Broker端和Consumer端过滤(从broker中拿取自己需要的tag)
Broker端过滤,减少了无用的消息的进行网络传输,增加了broker的负担
Consumer端过滤,完全可以根据业务需求进行实习,但是增加了很多无用的消息传输
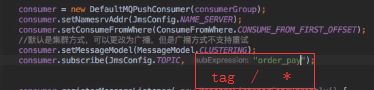
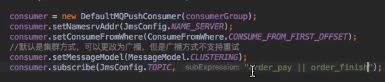
一般是监听 * ,或者指定 tag,|| 运算 , SLQ92 , FilterServer等;
tag性能高,逻辑简单
SQL92 性能差点,支持复杂逻辑(只支持PushConsumer中使用) MessageSelector.bySql
语法:> , < = ,IS NULL, AND, OR, NOT 等,sql where后续的语法即可(大部分)
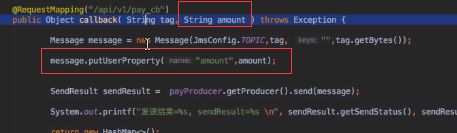

注意:消费者订阅关系要一致,不然会消费混乱,甚至消息丢失
订阅关系一致:订阅关系由 Topic和 Tag 组成,同一个 group name,订阅的 topic和tag 必须是一样的
在Broker 端进行MessageTag过滤,遍历Topic下的message queue存储的 message tag和 订阅传递的tag 的hashcode不一样则跳过,符合的则传输给Consumer,在consumer queue存储的是对应的hashcode, 对比也是通过hashcode对比;
Consumer收到过滤消息后也会进行匹配操作,但是是对比真实的message tag而不是hashcode(防止hash碰撞)
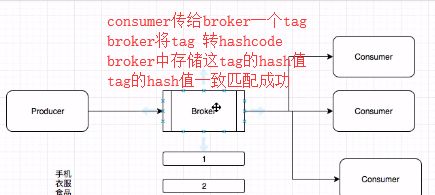

consume queue存储使用hashcode定长,节约空间
过滤中不访问commit log,可以高效过滤
如果存在hash冲突,Consumer端可以进行再次确认
如果想使用多个Tag,可以使用sql表达式,但是不建议,单一职责,多个队列
常见错误
The broker does not support consumer to filter message by SQL92
解决:broker.conf 里面配置如下
增加 enablePropertyFilter=true
备注,修改之后要重启Broker
master节点配置:vim conf/2m-2s-async/broker-a.properties ![]()
slave节点配置:vim conf/2m-2s-async/broker-a-s.properties
4、PushConsumer、PullConsumer消费模式分析
Push和Pull优缺点分析
Push
- 实时性高;
- 但增加服务端负载,消费端能力不同,如果Push推送过快,消费端会出现很多问题(消费不过来使得连接占满,堆积,消息丢失)
Pull
- 消费者从Server端拉取消息,主动权在消费者端,可控性好;
- 但 间隔时间不好设置,间隔太短,则空请求,浪费资源;(没有消息产生)
- 间隔时间太长,则消息不能及时处理(broker堆积)
长轮询:
- Client请求Server端也就是Broker的时候, Broker会保持当前连接一段时间 默认是15s,如果这段时间内有消息到达,则立刻返回给Consumer.
- 没消息的话 超过15s,则返回空,再进行重新请求;
- 主动权在Consumer中,Broker即使有大量的消息 也不会主动提送Consumer,
- 缺点:服务端需要保持Consumer的请求,会占用资源,需要客户端连接数可控 否则会一堆连接(broker服务端压力大)
RockerMQ采用的 PushConsumer和pullConsumer
PushConsumer本质是长轮训
- 系统收到消息后自动处理消息和offset,如果有新的Consumer加入会自动做负载均衡,
- 在broker端可以通过longPollingEnable=true来开启长轮询
- 消费端代码:DefaultMQPushConsumerImpl->pullMessage->PullCallback(存在pull的方法)
- 服务端代码:broker.longpolling
- 虽然是push,但是代码里面大量使用了pull,是因为使用长轮训方式达到Push效果,既有pull有的,又有Push的实时性
- 优雅关闭: 主要是释放资源和保存Offset, 调用shutdown()即可 ,参考 @PostConstruct、@PreDestroy
PullConsumer需要自己维护Offset(参考官方例子)
官方例子路径:org.apache.rocketmq.example.simple.PullConsumer(rocketmq下载的包)
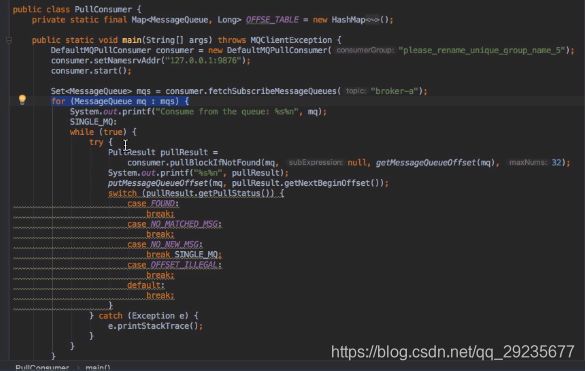
- 获取MessageQueue遍历
- 客户维护Offset,要用户本地存储Offset,存储内存、磁盘、数据库等(下次向broker请求才能不至于重复拉取之前的消息)
- 处理不同状态的消息 FOUND、NO_NEW_MSG、OFFSET_ILLRGL、NO_MATCHED_MSG、4种状态
- 灵活性高可控性强,但是编码复杂度会高
- 优雅关闭:主要是释放资源和保存Offset,需用程序自己保存好Offset,特别是异常处理的时候