「自然语言处理(NLP)」入门系列(三)单词表示、损失优化、文本标记化?
来源:AINLPer微信公众号(点击了解一下吧)
编辑: ShuYini
校稿: ShuYini
时间: 2020-01-09
本次主要内容:
1、知道词向量如何表示单词意思
2、如何可视化词向量
3、损失函数与优化
4、文本标记化(Tokenization)
自然语言处理下的单词表示
在我们建立一个模型并使用深度学习进行自然语言处理之前,我们必须弄清楚如何为计算机表示单词。在日常生活中,我们以多种方式来表达单词,通常是书面的符号(文字中的单词)或特定的声音(口语单词)。这两种方法都不能向计算机传递太多信息,因此我们需要采取不同的方法。机器学习的一个常见解决方案是将每个单词的意思表示为实数向量。
向量知识回顾
向量是一个有多个元素的量。当你第一次处理向量时,考虑二维向量是最简单的因为我们在二维空间中工作很舒服。对于这些向量,我们通常认为它们的两个元素表示大小(它们有多长)和方向(它们从原点延伸的方向)。我们可以把这些向量画成图上的箭头,从原点开始,延伸到平面上的不同点。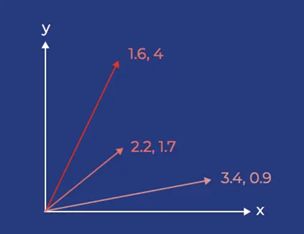 你也可以把一组向量表示成一个矩阵,其中每一行表示一个单独的向量。
你也可以把一组向量表示成一个矩阵,其中每一行表示一个单独的向量。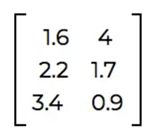 实际上,我们用来表示单词的向量远不止二维。许多字向量使用300维。很难想象三维空间中的向量是什么样子的,但是它的思想(和数学!)与二维向量非常相似。我们可以通过减少这些高维向量的维数并在二维空间中绘制它们来可视化这些高维向量。我们也可以用上面的方法把它们表示成矩阵。
实际上,我们用来表示单词的向量远不止二维。许多字向量使用300维。很难想象三维空间中的向量是什么样子的,但是它的思想(和数学!)与二维向量非常相似。我们可以通过减少这些高维向量的维数并在二维空间中绘制它们来可视化这些高维向量。我们也可以用上面的方法把它们表示成矩阵。
可以将单词向量中的每个数字看作一个特征。我们使用深度学习来创建这些向量并“选择”这些特性。记住,因为机器是通过深度学习来设计这些向量的,它们不容易被描述,比如“是动物”或者“是动词”。每个数字代表一个由模型本身决定的特征。
我们使用这些字向量来绘制高维向量空间中的字。当我们这样绘制单词向量时,具有相似含义的单词往往会聚集在一起。
例如,在一个给定的词云中,所有国家的名字可能会聚集在一起,因为它们很相似。在附近,你可能会发现像state, national, international这样的词。由于人类很难想象多维空间,我们使用降维来将字向量投射到二维或三维进行可视化。(这种文字图的坐标轴是什么?本质上,没有什么特别的。记住,我们看到的是一个300维的空间,被压缩到二维空间,所以我们结合了许多特性来制作这两个轴。有时,在一个词云中可能会出现坐标轴,比如在一个方向上增加形容词的强度,或者增加名词的特异性,但坐标轴实际上并没有那么简单。不要太担心弄清楚特定轴的含义。)
损失函数与优化
一旦你用向量来表示单词,接下来你需要训练你的模型的是一个损失函数(有时也称为目标函数)。
因为没有一个模型是完美的,你应该期望任何深度学习模型都有一定程度的错误。损失函数本质上是给定决策的期望值与模型得出的实际值之间的距离函数。损失函数描述模型的错误。
当您训练您的模型时,您试图最小化这个损失函数,使模型的决策尽可能接近您的预期结果。例如,均方误差(MSE)是一个流行的损失函数。均方误差是模型值与实际期望值的均方差。如果您学习过任何介绍性的机器学习材料,您可能已经遇到过并使用这个MSE等式。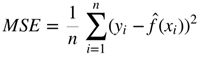 这里MSE的一个常见应用是作为k近邻分类器的损失函数。要优化一个模型,您需要一个损失函数(度量当前模型的错误)和一个优化器(对模型进行更改以减少错误度量)。
这里MSE的一个常见应用是作为k近邻分类器的损失函数。要优化一个模型,您需要一个损失函数(度量当前模型的错误)和一个优化器(对模型进行更改以减少错误度量)。
优化器通过更改模型的参数来帮助模型“学习”如何做出正确的决策。修改这些参数的目的是得到一个误差更小的模型。另一种考虑方法是,我们希望优化器最小化损失函数。
NLP实践之标记化(Tokenization)
在处理NLP问题时,有几个标准流程,其中第一个过程是文本的标记化(在中文处理中也成为分词)。该模型需要将字符序列处理为数字序列,因此NLP项目的第一步通常处理如何将这些字符分块并分组。 这些标记是模型能够理解的最小文本单元。也就是说我们将文本分割成一个小块一个小块的例如以一个英文单词为单位或者一个汉字为单位,这样子的操作主要是方便我们可以更集中的去分析文本信息的内容和文本想表达的含义。
当然分割是一个大范围,不仅仅是文本分成不同的词,也可以将整个文本分成段落,进而分成句子,句子在细分到词。当然,我们一般所说的标识化就是将整句分割为单个标识符(tokens)。对于某些NLP模型来说,标记化可能会对性能产生惊人的影响,因此熟练权衡标记化也是很重要的。
让我们来比较四种不同的标记化:字符级,它将所有内容分割为单个字符,基于空格的标记化,机器翻译中常见的摩西标记化,以及spaCy标记化。
1. import nltk
2. nltk.download('perluniprops')
3. nltk.download('nonbreaking_prefixes')
4. import nltk.tokenize.moses as moses
5. import spacy
6. spacy.cli.download("en")
7.
8. # 例子
9. sentence = " I can't fathom the depths of the deepest neural nets. "
10. print('Example sentence: ', sentence)
11.
12. #下面将用不同的方法标记化这个句子
13.
14. ##首先是字符级别的
15. ##分的块越小,模型需要学习的符号就越少。更少的标记意味着从一个句子到另一个句子,
16. ##从一个词到另一个词,或者从一个文档到另一个文档的标记之间有更多的重叠。
17. ##在这种极端情况下,我们可以在字符级别处理事情。
18. character_tokenization = [c for c in sentence]
19. print('Character Tokenization: ', character_tokenization)
20.
21. ## 单词级别
22. ##但是单词是字符的集合,在训练的时候我们可能给模型单词级别的意思。
23. word_tokenization = sentence.split()
24. print('Space-based Word Tokenization: ', word_tokenization)
25.
26. ## 短序列级别(自然语言处理多采用这种模式)
27. ##有些短序列可以更快的处理,比如“help”这样的词,但是“can't”和“can”这样的词是完全不同的标记,
28. ##也许我们可以选择一个合适的分词方式,将“can't”分解成“can”和“not”
29.
30. #下面是两个常见的自由分词器,它们对如何进行分词做出各种各样的决定。moses和spacy比较一下:
31. moses_tokenizer = moses.MosesTokenizer()
32. spacy_tokenizer = spacy.load('en')
33. println('Moses Word Tokenization: ', moses_tokenizer.tokenize(sentence, escape=False))
34. def spacy_tokenize(s):
35. return [t.text for t in spacy_tokenizer(s)]
36. println('spaCy Word Tokenization: ', spacy_tokenize(sentence))
37.
38. ## 另一种常见的标记工具是CoreNLP,但它需要更多的工作来设置,无论您选择使用哪个记号赋予器,都需要了解一下他们的特性。
结果输出:
1. Example sentence: I can't fathom the depths of the deepest neural nets.
2.
3. Character Tokenization: ['I', ' ', 'c', 'a', 'n', "'", 't', ' ', 'f', 'a', 't', 'h', 'o', 'm', ' ', 't', 'h', 'e', ' ', 'd', 'e', 'p', 't', 'h', 's', ' ', 'o', 'f', ' ', 't', 'h', 'e', ' ', 'd', 'e', 'e', 'p', 'e', 's', 't', ' ', 'n', 'e', 'u', 'r', 'a', 'l', ' ', 'n', 'e', 't', 's', '.']
4.
5. Space-based Word Tokenization: ['I', "can't", 'fathom', 'the', 'depths', 'of', 'the', 'deepest', 'neural', 'nets.']
6.
7. Moses Word Tokenization: ['I', 'can', "'t", 'fathom', 'the', 'depths', 'of', 'the', 'deepest', 'neural', 'nets', '.']
8.
9. spaCy Word Tokenization: ['I', 'ca', "n't", 'fathom', 'the', 'depths', 'of', 'the', 'deepest', 'neural', 'nets', '.']
一旦对文本进行了标记,就可能需要某种词汇表来跟踪不同类型的标记以及标记与数值之间的映射。
1. import spacy
2. import collections
3. spacy.cli.download("en")
4. spacy_tokenizer = spacy.load('en')
5. document = "One thing was certain, that the WHITE kitten had had nothing to do with it:--it was the black kitten’s fault entirely. For the white kitten had been having its face washed by the old cat for the last quarter of an hour (and bearing it pretty well, considering); so you see that it COULDN’T have had any hand in the mischief. The way Dinah washed her children’s faces was this: first she held the poor thing down by its ear with one paw, and then with the other paw she rubbed its face all over, the wrong way, beginning at the nose: and just now, as I said, she was hard at work on the white kitten, which was lying quite still and trying to purr—"
6. ##最简单的词汇表可能需要跟踪所有标记,但通常最好跟踪每个标记的使用频率,然后保持词汇表的顺序。
7. ##在这里,我们首先按单词排序,然后按频率排序,但是任何从相同数据集创建词汇表的人都可以得到完全相同的顺序
8. tokens_with_counts = collections.Counter(spacy_tokenize(document))
9. tokens_with_counts = sorted(tokens_with_counts.items(), key=lambda tup: tup[0])
10. tokens_with_counts.sort(key=lambda tup: tup[1], reverse=True)
11. print(tokens_with_counts)
12.
13. #如果我们的词汇量太大,我们可能想要删除一些罕见的单词,通常是那些出现次数少于4次的单词,
14. #但是我们现在只有一个长句子,所以让我们保留出现次数超过1次的单词
15. print(len(tokens_with_counts))
16. tokens_with_counts_pruned = [t for t in tokens_with_counts if t[1] > 1]
17. print(len(tokens_with_counts_pruned))
18.
19. #建立单词和索引之间的关系
20. index_to_token = [t[0] for t in tokens_with_counts_pruned]
21. token_to_index = {t: i for i, t in enumerate(index_to_token)}
结果输出:
1. [('the', 11), (',', 8), ('was', 5), ('and', 4), ('had', 4), ('kitten', 4), ('its', 3), ('she', 3), ('with', 3), ('.', 2), (':', 2), ('at', 2), ('by', 2), ('face', 2), ('it', 2), ('paw', 2), ('that', 2), ('thing', 2), ('to', 2), ('washed', 2), ('way', 2), ('white', 2), ('’s', 2), ('(', 1), (')', 1), (';', 1), ('COULDN’T', 1), ('Dinah', 1), ('For', 1), ('I', 1), ('One', 1), ('The', 1), ('WHITE', 1), ('all', 1), ('an', 1), ('any', 1), ('as', 1), ('bearing', 1), ('been', 1), ('beginning', 1), ('black', 1), ('cat', 1), ('certain', 1), ('children', 1), ('considering', 1), ('do', 1), ('down', 1), ('ear', 1), ('entirely', 1), ('faces', 1), ('fault', 1), ('first', 1), ('for', 1), ('hand', 1), ('hard', 1), ('have', 1), ('having', 1), ('held', 1), ('her', 1), ('hour', 1), ('in', 1), ('it:--it', 1), ('just', 1), ('last', 1), ('lying', 1), ('mischief', 1), ('nose', 1), ('nothing', 1), ('now', 1), ('of', 1), ('old', 1), ('on', 1), ('one', 1), ('other', 1), ('over', 1), ('poor', 1), ('pretty', 1), ('purr--', 1), ('quarter', 1), ('quite', 1), ('rubbed', 1), ('said', 1), ('see', 1), ('so', 1), ('still', 1), ('then', 1), ('this', 1), ('trying', 1), ('well', 1), ('which', 1), ('work', 1), ('wrong', 1), ('you', 1)]
2. 93
3. 23
有了上面之间的mapping关系,我们可以将标记的文档转换为数字序列。这一数值化过程将是大多数NLP的早期步骤。
ACED
Attention
更多自然语言处理相关知识,还请关注 AINLPer 公众号,极品干货即刻送达。