mybatis连接mysql数据库步骤_框架学习系列 mybatis 第一篇 mybatis简介&原生jdbc连接分析...
框架学习系列 mybatis 第一篇 mybatis简介&原生jdbc连接分析
凯哥Java 凯哥java
本节主要内容
1:mybatis的介绍
2:原始jdbc问题分析
3:JDBC演变成mybatis的过程
4:总结&下节预告
本文是《凯哥陪你学系列-框架学习之mybatis框架学习》中第一篇 mybatis简介&原生jdbc连接分析
声明:本文系凯哥Java(www.kaigejava.com)原创。未经允许禁止转载!

一:mybatis的介绍
1.1:mybatis是什么?
MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code,并且改名为MyBatis,实质上Mybatis对ibatis进行一些改进。
MyBatis是一个优秀的持久层框架,它对jdbc的操作数据库的过程进行封装,使开发者只需要关注 SQL 本身,而不需要花费精力去处理例如注册驱动、创建connection、创建statement、手动设置参数、结果集检索等jdbc繁杂的过程代码。
Mybatis通过xml或注解的方式将要执行的各种statement(statement、preparedStatemnt、CallableStatement)配置起来,并通过java对象和statement中的sql进行映射生成最终执行的sql语句,最后由mybatis框架执行sql并将结果映射成java对象并返回。
与hibernate都属于是ORM框架。但是具体的说,hibernate是一个完全的ORM框架,二mybatis是一个不完全的orm框架。
mybatis让程序开发者只关注sql本事,而不需要关注如何连接的创建、statement的创建等操作。
mybatis会将输入参数、输出结果进行映射。
二:分析原生JDBC程序中存在的问题
2.1:原生jdbc程序代码
2.1.1 数据库脚本。
1:创建mybatis这个数据库。脚本:
CREATE DATABASE `mybatis` DEFAULT CHARACTER SET utf8;
2:使用刚创建的mybatis这个数据库
USE `mybatis`;
3:创建用户(user)这个表。字段有 id/nam/gender/age
脚本如下:
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`name` varchar(16) DEFAULT NULL COMMENT '姓名',
`gender` char(1) DEFAULT NULL COMMENT '性别 0 男 1女',
`age` int(11) DEFAULT NULL COMMENT '年龄',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
初始化三条数据:
insert into `user`(`id`,`name`,`gender`,`age`) values (1,'张三','0',23),(2,'凯哥Java','0',25),(3,'校花','1',22);
2.2 jdbc连接数据库及查询步骤
1:引入所需要的jar(mysql的)
![]()
2:使用java程序连接mysql数据库步骤
a:获取加载数据库的驱动

b:通过驱动管理类获取数据库连接
其中包括数据库地址、用户名、密码
![]()
说明:
设置数据库连接地址、连接的库名及使用编码:jdbc:mysql://localhost:3306/mybatis?characterEncoding=utf-8
数据库用户名:root
数据库密码为:123456
c:定义sql语句使用?表示占位符
![]()
d:获取预处理的statement

e:设置参数、第一个参数为sql语句中参数的序号(?的位置。从1开始的),第二个参数为设置的参数值

f:向数据库发送sql执行查询。查询结果集

g:遍历查询结果集

h:释放资源
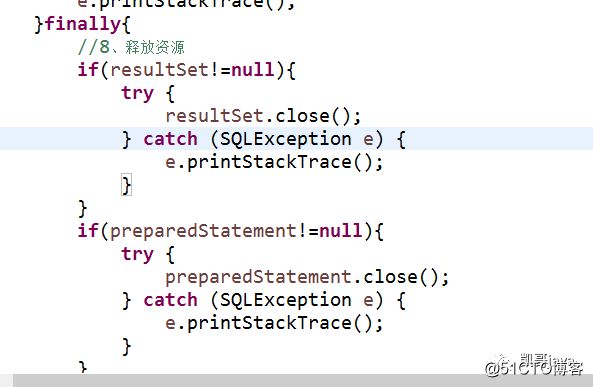
执行完成后控制台输出为:
![]()
完整代码:
public class JDBCTest {
public static void main(String[] args) {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
//1、加载数据库驱动
Class.forName("com.mysql.jdbc.Driver");
//2、通过驱动管理类获取数据库链接
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/mybatis?characterEncoding=utf-8", "root", "123456");
//3、定义sql语句 ?表示占位符
String sql = "select * from user where name = ?";
//4、获取预处理statement
preparedStatement = connection.prepareStatement(sql);
//5、设置参数,第一个参数为sql语句中参数的序号(从1开始),第二个参数为设置的参数值
preparedStatement.setString(1, "校花");
//6、向数据库发出sql执行查询,查询出结果集
resultSet = preparedStatement.executeQuery();
//7、遍历查询结果集
while(resultSet.next()){
System.out.println(resultSet.getString("id")+" "+resultSet.getString("name"));
}
} catch (Exception e) {
e.printStackTrace();
}finally{
//8、释放资源
if(resultSet!=null){
try {
resultSet.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(preparedStatement!=null){
try {
preparedStatement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(connection!=null){
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
2.3:使用原生jdbc的问题
1:在创建连接的时候,存在硬编码(数据非动态的)
对应程序中:

数据库连接、用户名、密码都是在程序中写死的。
解决方案:
可以将这些信息存放在全局的配置文件中
2:在执行statement的时候存在硬编码
对应程序中:
![]()
我们可以看到,这里查询学在程序中,是固定的。
解决方案:
sql卸载配置文件(映射文件中)
3:频繁的开启和关闭数据库连接,会造成数据库性能的下降
对应程序中:
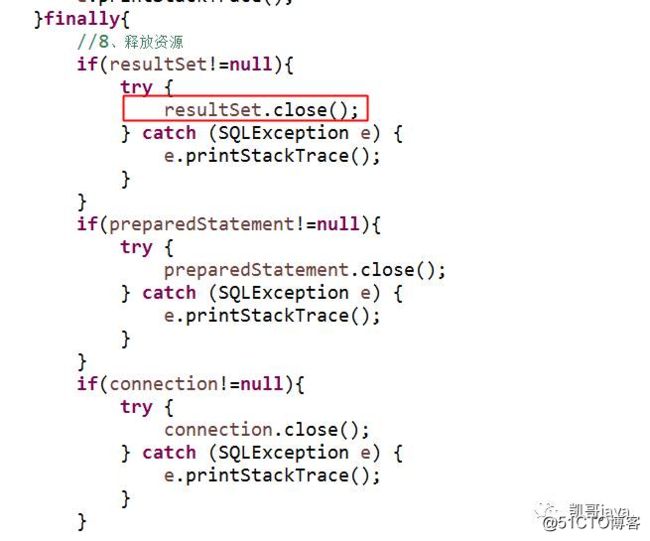
解决方案:
使用数据库连接池(全局配置文件)
三: JDBC演变到Mybatis过程
上面我们看到了实现JDBC有七个步骤,哪些步骤是可以进一步封装的,减少我们开发的代码量。
3.1 第一步优化:连接获取和释放
问题描述:
数据库连接频繁的开启和关闭本身就造成了资源的浪费,影响系统的性能。
解决问题:
数据库连接的获取和关闭我们可以使用数据库连接池来解决资源浪费的问题。通过连接池就可以反复利用已经建立的连接去访问数据库了。减少连接的开启和关闭的时间。
问题描述:
但是现在连接池多种多样,可能存在变化,有可能采用DBCP的连接池,也有可能采用容器本身的JNDI数据库连接池。
解决问题:
我们可以通过DataSource进行隔离解耦,我们统一从DataSource里面获取数据库连接,DataSource具体由DBCP实现还是由容器的JNDI实现都可以,所以我们将DataSource的具体实现通过让用户配置来应对变化。
3.2 第二步优化:SQL统一存取
问题描述:
我们使用JDBC进行操作数据库时,SQL语句基本都散落在各个JAVA类中,这样有三个不足之处:
第一,可读性很差,不利于维护以及做性能调优。
第二,改动Java代码需要重新编译、打包部署。
第三,不利于取出SQL在数据库客户端执行(取出后还得删掉中间的Java代码,编写好的SQL语句写好后还得通过+号在Java进行拼凑)。
解决问题:
我们可以考虑不把SQL语句写到Java代码中,那么把SQL语句放到哪里呢?首先需要有一个统一存放的地方,我们可以将这些SQL语句统一集中放到配置文件或者数据库里面(以key-value的格式存放)。然后通过SQL语句的key值去获取对应的SQL语句。
既然我们将SQL语句都统一放在配置文件或者数据库中,那么这里就涉及一个SQL语句的加载问题。
3.3 第三步优化:传入参数映射和动态SQL
问题描述:
很多情况下,我们都可以通过在SQL语句中设置占位符来达到使用传入参数的目的,这种方式本身就有一定局限性,它是按照一定顺序传入参数的,要与占位符一一匹配。但是,如果我们传入的参数是不确定的(比如列表查询,根据用户填写的查询条件不同,传入查询的参数也是不同的,有时是一个参数、有时可能是三个参数),那么我们就得在后台代码中自己根据请求的传入参数去拼凑相应的SQL语句,这样的话还是避免不了在Java代码里面写SQL语句的命运。既然我们已经把SQL语句统一存放在配置文件或者数据库中了,怎么做到能够根据前台传入参数的不同,动态生成对应的SQL语句呢?
解决问题:
第一,我们先解决这个动态问题,按照我们正常的程序员思维是,通过if和else这类的判断来进行是最直观的,这个时候我们想到了JSTL中的这样的标签,那么,能不能将这类的标签引入到SQL语句中呢?假设可以,那么我们这里就需要一个专门的SQL解析器来解析这样的SQL语句,但是,if判断的变量来自于哪里呢?传入的值本身是可变的,那么我们得为这个值定义一个不变的变量名称,而且这个变量名称必须和对应的值要有对应关系,可以通过这个变量名称找到对应的值,这个时候我们想到了key-value的Map。解析的时候根据变量名的具体值来判断。
假如前面可以判断没有问题,那么假如判断的结果是true,那么就需要输出的标签里面的SQL片段,但是怎么解决在标签里面使用变量名称的问题呢?这里我们需要使用一种有别于SQL的语法来嵌入变量(比如使用#变量名#)。这样,SQL语句经过解析后就可以动态的生成符合上下文的SQL语句。
还有,怎么区分开占位符变量和非占位变量?有时候我们单单使用占位符是满足不了的,占位符只能为查询条件占位,SQL语句其他地方使用不了。这里我们可以使用#变量名#表示占位符变量,使用$变量名$表示非占位符变量。
3.4 第四步优化:结果映射和结果缓存
1. 问题描述:
执行SQL语句、获取执行结果、对执行结果进行转换处理、释放相关资源是一整套下来的。假如是执行查询语句,那么执行SQL语句后,返回的是一个ResultSet结果集,这个时候我们就需要将ResultSet对象的数据取出来,不然等到释放资源时就取不到这些结果信息了。我们从前面的优化来看,以及将获取连接、设置传入参数、执行SQL语句、释放资源这些都封装起来了,只剩下结果处理这块还没有进行封装,如果能封装起来,每个数据库操作都不用自己写那么一大堆Java代码,直接调用一个封装的方法就可以搞定了。
解决问题:
我们分析一下,一般对执行结果的有哪些处理,有可能将结果不做任何处理就直接返回,也有可能将结果转换成一个JavaBean对象返回、一个Map返回、一个List返回等`,结果处理可能是多种多样的。从这里看,我们必须告诉SQL处理器两点:第一,需要返回什么类型的对象;第二,需要返回的对象的数据结构怎么跟执行的结果映射,这样才能将具体的值copy到对应的数据结构上。
接下来,我们可以进而考虑对SQL执行结果的缓存来提升性能。缓存数据都是key-value的格式,那么这个key怎么来呢?怎么保证唯一呢?即使同一条SQL语句几次访问的过程中由于传入参数的不同,得到的执行SQL语句也是不同的。那么缓存起来的时候是多对。但是SQL语句和传入参数两部分合起来可以作为数据缓存的key值。
3.5 第五步优化:解决重复SQL语句问题
1. 问题描述:
由于我们将所有SQL语句都放到配置文件中,这个时候会遇到一个SQL重复的问题,几个功能的SQL语句其实都差不多,有些可能是SELECT后面那段不同、有些可能是WHERE语句不同。有时候表结构改了,那么我们就需要改多个地方,不利于维护。
解决问题:
当我们的代码程序出现重复代码时怎么办?将重复的代码抽离出来成为独立的一个类,然后在各个需要使用的地方进行引用。对于SQL重复的问题,我们也可以采用这种方式,通过将SQL片段模块化,将重复的SQL片段独立成一个SQL块,然后在各个SQL语句引用重复的SQL块,这样需要修改时只需要修改一处即可。
四:总结&下节预告
通过本节学习我们需要掌握的
1:jdbc怎么连接数据库进行操作的
下节预告: 我们知道jdbc连接数据库的步骤(原理),那么mybatis的工作原理又是什么呢?
欢迎学习下一节:《 mybatis 第二篇 mybatis的工作原理》