构建Transformer模型 | 在wikiText-2数据集上训练一个语言模型
0 Introduction
自然语言处理通用解决方案
- 需要熟悉word2Vec, 了解词向量如何建模
- 重点在于Transformer网络架构,BERT训练方法,实际应用
- 开源项目,都是现成的,套用进去就OK了
- 提供预训练模型,基本任务拿过来直接用都成
关于Transformer, CSDN上有很多关于Transformer模型代码及解析的教程,但总体感觉还是不够直观,本文来自以B站上一个公开课,讲得非常详细,建议花一点时间从头到尾跟做一遍,单纯看静态的代码和文字描述,还是比较抽象。
该公开课的P1-P46部分,为Transformer模型的内部实现,包括如何构建Attention Is All you Need一文中Figure1中的各个部分,如词嵌入,位置编码,多头注意力,前馈全连接,规范化层,编码器层,编码器,解码器层,解码器,输出层等,以及如何将上述各个模块组件成一个完整的transformer模型
P47-P56 为使用torchtext包,在wikiText-2数据集上训练一个语言模型。原教程非常详细,不再赘述,此处仅贴代码留作笔记。
需要提前说明的是,视频中的P1-P46部分,对Pytorch的版本没有太多要求,随便装一个即可,这里装的是比较稳定的版本torch 1.13.1,安装命令详见官网。
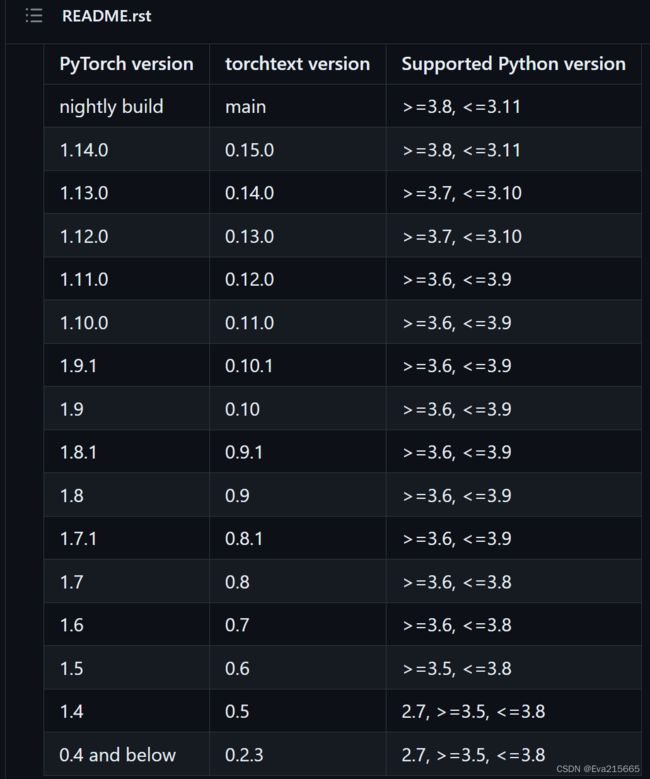
但是视频的P47-P56,作者用的pytorch==1.3,是一个比较古早的版本,对应的torchtext也是古早的版本(应该是torchtext 0.9之前的版本),如果不指定版本默认安装的话,会默认安装最新版torchtext0.14,但torchtext0.14相比torchtext0.9,API有很大的调整,因此跟着视频操作,会导致很多地方报错,对新手很不友好。torch和torchtext的版本匹配参照这里, 也如下图所示。这里指定安装了torchtext 0.4版本。
1 创建环境
在D:\Code\Transformer路径下创建虚拟环境venv
- 打开
Anaconda Prompt,输入conda create --prefix=D:\Code\Transformer\venv python=3.7,关于创建虚拟环境,可参考我之前的博客。现在这个虚拟环境下面仅有python解释器及一些基础的库,还没有构建transformer所需的torch等库。(可以进去这个路径看一下,此时venv大小只有100MB左右) - 在该虚拟环境下安装
torch:继续在Anaconda Prompt中输入:activate D:\Code\Transformer\venv以激活该环境,然后参考torch官网上的安装命令:conda install pytorch==1.13.0 torchvision==0.14.0 torchaudio==0.13.0 -c pytorch,安装完后,此时venv环境已经有1G左右。 - 在该虚拟环境下安装
torchtext:继续在Anaconda Prompt中输入:pip install torchtext==0.4。如果对torchtext 0.14最新版感兴趣,可参考torchtext官网
2 公开课中的P1-P46:用PyCharm构建Transformer项目
PyCharm版本:2020.1,打开D:\Code\Transformer这个项目,创建Transformer.py文件,书写以下代码。在main函数中,有针对每一个模块的测试,可以看到张量的变化情况,详细还是参加B站上的公开课。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy
# 导入优化器工具包get_std_opt,该工具用于获得标准的针对Transformer模型的优化器
# 该标准优化器基于Adam优化器,使其对序列到序列的任务更有效
from pyitcast.transformer_utils import get_std_opt
# 导入标签平滑工具包,该工具用于标签平滑,标签平滑的作用就是小幅度的改变原有标签值的值域
# 因为在理论上即使是人工的标注数据也可能并非完全正确,会收到一些外界因素的影响而产生一些微小的偏差
# 因此使用标签平滑来弥补这种偏差,减少模型对某一条规律的绝对认知,以防止过拟合,通过下面示例了解
from pyitcast.transformer_utils import LabelSmoothing
# 导入损失计算工具包,该工具能够使用标签平滑后的结果进行损失的计算
# 损失的计算方法可以认为是交叉熵损失函数
from pyitcast.transformer_utils import SimpleLossCompute
from pyitcast.transformer_utils import run_epoch
from pyitcast.transformer_utils import greedy_decode
# 输入部分1: 构建Embeddings类实现文本嵌入
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
# d_model : 词嵌入维度
# vocab : 词表的大小
super(Embeddings, self).__init__()
#定义Embedding层
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
# x : 代表输入进模型的文本通过词汇映射后的数字张量,假设x的shape为(x,y),则下面代码以后,输出形状为(x, y, d_model)
return self.lut(x) * math.sqrt(self.d_model)
# 输入部分2:位置编码
"""位置编码器的作用,因为在Transformer的编码器结构中,并没有针对词汇位置信息的处理,因此需要在Embedding层加入
位置编码器,将词汇位置不同可能会产生不同语义的信息加入到词嵌入张量中,以弥补位置信息的缺失"""
# 定位位置编码器,同样把它看做一个层
class PostionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
# d_model: 词嵌入维度
# dropout : 置零比率
# max_len : 每个句子最大长度,即包含单词的个数
# 最终输出一个加入了位置编码信息的词嵌入张量
super(PostionalEncoding, self).__init__()
# 实例化nn中预定义的Droupout层,并将dropout传入其中,获得对象self.droput
self.dropout = nn.Dropout(p=dropout)
# 初始化一个位置编码矩阵,它是一个0矩阵,它的形状是(max_len, d_model),用tensor.zeros产生
pe = torch.zeros(max_len, d_model)
# 初始化一个绝对位置矩阵,在我们这里,词汇的绝对位置就是用它的索引去表示
# 所以我们首先用tensor.arange方法获得一个连续自然数向量,然后用unsqueeze拓展向量维度
# 又因为参数传递的是1,代表矩阵拓展的位置,会使向量变成一个max_len * 1的矩阵
position = torch.arange(0, max_len).unsqueeze(1)
print("position:", position)
print(position.shape)
#绝对位置矩阵初始化后,接下来就是考虑如何将这些位置信息加入到位置编码矩阵中
# 最简单思路就是先将max_len * 1的绝对位置矩阵position,变成max_len * d_model形状,然后覆盖原来的初始位置编码矩阵pe
# 要做这种矩阵变换,就需要一个1 * d_model形状的变换矩阵div_term,我们对这个变换矩阵的要求是除了形状满足1*d_model之外
# 还希望它能够将自然数的绝对位置编码缩放成足够小的数字,有助于在之后的梯度下降过程中更快收敛
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)) #注意这里div_term是一维张量,形状是(256)
# print(div_term)
# print(div_term.shape)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 这样我们就得到了位置编码矩阵pe,pe现在还只是(max_len, d_model)的二维矩阵,要想和embedding的输出(一个三维张量)进行运算
# 就必须拓展一个维度,所以这里使用unsqueeze拓展维度
pe = pe.unsqueeze(0) # pe.shape = (1, 5000, 512)
# 最后把pe位置编码矩阵注册成模型的buffer
self.register_buffer('pe', pe)
def forward(self, x):
# x : 文本序列的词嵌入表示,也就是Embeddings类输出的张量,是一个三维张量
# 在positional encoding与input embedding相加之前,已经对pe做了一些适配工作,将这个三维张量的第二维也就是句子最大长度的
# 那一维切片,与输入的x的第二维相同即x.size(1), 输入x的第二维代表什么?
# 因为我们默认max_len为5000一般来讲是在太长了,很难有一条句子包含5000个词汇,所以要进行与输入张量的适配
# 最后使用Variable进行封装,使其与x的样式相同,但是它是不需要进行梯度求解的,因此把requires_grad=False
# 以下代码即完成了Figure1中PositionalEncoding与Input Embedding的相加
x = x + Variable(self.pe[:, :x.size(1)], requires_grad = False) # pe[:, :x.size(1)],提取所有行,提取前x.size(1)列
return self.dropout(x)
"""==================================2.3 编码器部分实现======================================"""
# 2.3.1掩码张量
def subsequent_mask(size):
"""生成向后遮掩的掩码张量,参数size是掩码张量最后两个维度的大小,它的最后两维形成一个方阵"""
# 在函数中,首先定义掩码张量的形状
attn_shape = (1, size, size)
# 然后使用np.ones向这个形状中添加1元素,形成上三角阵,最后为了节约空间,再使其中的数据类型变为无符号8位整形unit8
subsequent_mask = np.triu(np.ones(attn_shape, k=1).astype('uint8'))
# 最后将numpy类型转化为torch中的tensor,内部做一个1-的操作
# 在这个其实是做了一个三角阵的反转,subsequent_mask中的每个元素都会被1减
# 如果是0, subsequent_mask中的该位置由0变成1
# 如果是1,subsequent_mask中的该位置由1变成0
return torch.from_numpy(1 - subsequent_mask)
# 2.3.2 ============================注意力机制============================
# 注意力计算规则:它需要三个指定的输入Q(query),K(key), V(value),然后通过公式得到注意力的计算结果
# 这个结果代表query 在key和value作用下的表示
# 学习了Q,K,V的比喻解释
# Q是一段准备被概括的文本,K是给出的提示,V是大脑中的对提示K的延伸
# 当Q=K=V时,称为自注意力机制
def attention(query, key, value, mask=None, dropput=None):
"""注意力机制的实现,输入分别是query, key, value, mask:掩码张量,
dropout是nn.Dropout层的实例化对象,默认为None"""
# 在函数中,首先取query的最后一维的大小,一般情况下等同于词嵌入维度,命名为d_k
d_k = query.size(-1)
# 按照注意力公式,将query与key的转置相乘,这里面key是将最后两个维度进行转置,再除以缩放系数,得到注意力得分张量scores
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 接着判断是否使用掩码张量
if mask is not None:
# 使用tensor的masked_fill方法,将掩码张量和scores张量每个位置一一比较,如果掩码张量处为0
# 则对应的scores张量用-1e9这个值来替换
scores = scores.masked_fill(mask == 0, -1e9)
# 之后对socres的最后一维进行softmax操作,使用F.softmax方法,第一个参数是softmax对象,第二个是最后一维
# 这样获得最终的注意力张量
p_attn = F.softmax(scores, dim=-1)
# 再判断是否使用dropout进行随机置0
if dropput is not None:
# 将p_attn传入dropout对象中进行丢弃
p_attn = dropput(p_attn)
# 最后根据公式将p_attn与value张量相乘获得最终的query注意力表示,同时返回注意力张量
return torch.matmul(p_attn, value), p_attn
# 2.3.3 ==============================================多头注意力机制==============================================
"""什么是多头注意力?
"""
# 首先定义克隆函数,因为在多头注意力机制的实现中,用到多个结构相同的线性层
# 我们将使用clone函数将他们一同初始化在一个网络层列表对象中,之后的结构中也会用到该函数
def clones(module, N):
# 用于生成相同网络层的克隆函数,它的参数module表示要克隆的目标网络层,N代表克隆数量
# 在函数中,通过for循环对module进行N次深度拷贝,使其每个module成为独立的层
# 然后将其放在nn.ModuleList类型的列表中存放
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class MultiHeadAttention(nn.Module):
def __init__(self, head, embedding_dim, dropout = 0.1):
super(MultiHeadAttention, self).__init__()
# 首先使用一个测试中常用的assert语句,判断h是否能被d_model整除
# 这是因为我们之后要给每个头分配等量的词特征,也就是embedding_dim / head个
assert embedding_dim % head == 0
# 得到每个头获得的分割词向量维度
self.d_k = embedding_dim // head
# 传入头数h
self.head = head
# 然后获得线性层对象,通过nn的Linear实例化,多头注意力机制中,它的内部变换矩阵是embedding_dim * embedding_dim
# 注意它的内部变换矩阵是方阵,目的是不改变输入张量的形状,例如,input = torch.randn(40,20),
# m=nn.Linear(20,20), output=m(input), 则output的形状仍然是(40,20)
m = nn.Linear(embedding_dim, embedding_dim)
# 将线性层m拷贝4次,为什么是4次?因为在多头注意力中,Q,K,V各需要一个,最后拼接的矩阵还需要一个
self.linears = clones(module=m, N=4)
# self.attn为None,它代表最后得到的注意力张量,现在还没有结果所以为None
self.attn = None
# 最后就是一个self.dropout对象,它通过nn中的Dropout实例化而来
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"""前向逻辑函数,它的输入参数有4个,前三个就是注意力机制需要的Q,K,V
最后一个是注意力机制中可能需要的mask掩码张量,默认是None"""
# 如果存在掩码张量mask
if mask is not None:
# 使用unsqueeze拓展维度,代表多头中的第n头
mask = mask.unsqueeze(1)
# 接着需要获取query形状的第一个数字,代表有多少个样本
batch_size = query.size(0)
"""之后进入多头处理环节,首先利用zip将输入QKV与ModuleList中的前三个线性层组到一起
然后使用for循环,将输入QKV分别传入线性层中"""
# 执行完以下代码后,query, key, value变成了4维张量,代表多头
query, key, value = \
[model(x).view(batch_size, -1, self.head, self.d_k).transpose(1,2) for model, x in zip(self.linears, (query, key, value))]
# print("多头query: ", query.size())
# print("多头key: ", key.size())
# print("多头value: ", value.size())
# 得到每个头的输入后,接下来将他们传入attention中
# 直接调用之前实现的attention函数,同时也将mask和dropout传入其中
x, self.attn = attention(query, key, value, mask = mask, dropput=self.dropout)
# 得到每个头的计算结果,是4维的张量,需要形状转换,
# 前面已经将1,2两个维度进行过转置,在这里要重新转置回来
# 注意:经历了transpose()方法后,必须要用contigous方法,不然无法使用view方法
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head * self.d_k)
# 最后将x输入线性层列表中的最后一个线性层中进行处理,得到最终的多头注意力结构输出
return self.linears[-1](x)
# 2.3.4 ============================构建前馈全连接==================================
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
# d_model: 词嵌入维度,同时也是两个线性层的输入维度与输出维度
# d_ff:第1个线性层的输出维度与第2个线性层的输入维度
# dropout:
super(PositionwiseFeedForward, self).__init__()
# 定义2层全连接的线性层
self.w1 = nn.Linear(d_model, d_ff)
self.w2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x):
# x: 代表来自上一层的输出
# 首先将x送入第一个线性层网络层 x= self.w1(x)
# 然后经历relu函数的激活,x = F.relu(x)
# 再经历dropout层处理,x = self.dropout(x)
# 最后送入第二个线性层 x = self.w2(x)
return self.w2(self.dropout((F.relu(self.w1(x)))))
# 2.3.5 ============================构建规范化层的类==================================
"""规范化层的作用:
它是所有深层网络模型都需要的标准网络层,因为随着网络层数的增加,通过多层的计算后参数可能开始出现过大或过小的情况,
这样可能会导致学习过程出现异常,模型可能收敛非常慢,因此都会在一定层数后接规范化层进行数值的规范化,使其特征数值在合理
的范围内"""
class LayerNorm(nn.Module):
"""初始化函数有两个参数,一个是feature,表示词嵌入的维度,另一个eps是一个足够小的数,在规范化公式的分母中出现
防止分母为0, 默认是1e-6"""
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
# 根据feature的形状初始化两个参数张量a2, 和b2,第一个初始化为1张量
# 也就是里面的元素都是1,第二个初始化为0张量,也就是里面的元素都是0,这两个张量就是规范化层的参数
# 因为直接对上一层得到的结果做规范化公式计算,将改变结果的正常表征,因此就需要有参数作为调节因子
# 使其既能满足规范化要求,又能不改变针对目标的表征,最后使用nn.parameter封装,代表他们是模型的参数
self.a2 = nn.Parameter(torch.ones(features))
self.b2 = nn.Parameter(torch.zeros(features))
# 把eps传到类中
self.eps = eps
def forward(self, x):
"""输入参数x代表上一层的输出
在函数中,首先对输入变量x求其最后一个维度的均值,并保持输出维度与输入维度一致
接着再求最后一个维度的标准差,然后就是根据规范化公式,用x减去均值除以标准差获得规范化的结果
最后对结果乘以我们的缩放参数,即a2,*号代表同型点乘,即对应位置进行乘法操作,加上位移参数"""
mean = x.mean(-1, keepdim = True)
std = x.std(-1, keepdim = True)
return self.a2 * (x-mean) / (std + self.eps) + self.b2
# 2.3.6 ============================构建子层连接的类==================================
# 如图所示,输入到每个子层以及规范化层的过程中,还使用了残差连接,因此我们把这一部分结构整体叫做子层连接(代表子层及其连接结构)
# 在每个编码器层中,都有两个子层,这两个子层加上周围的连接结构就形成了两个子层连接结构
class SublayerConnection(nn.Module):
def __init__(self, size, dropout = 0.1):
"""它输入参数有两个,size以及dropout, size一般是词嵌入维度
dropout本身是对模型结构中的节点数进行随机抑制的比率
又因为节点被抑制等效就是该节点的输出都是0,因此也可以把dropout看做是对输出矩阵的随机"""
super(SublayerConnection, self).__init__()
# 实例化了规范化对象self.norm
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(p=dropout)
def forward (self, x, sublayer):
"""前向逻辑函数中,接收上一个层或者子层的输入作为第一个参数,将该子层连接中的子层函数作为第二个参数"""
# x: 代表上一层的输出
# 我们首先对输出进行规范化,然后将结果传给子层处理,之后再对子层进行dropout操作
# 随机停止一些网络中的神经元的作用,来防止过拟合,最后还有一个add操作
return x + self.dropout(sublayer(self.norm(x))) # 先对上一层输入的x进行Norm操作,即先扔进norm层,然后再进行sublayer层,最后再相加即残差连接
# 2.3.7 ============================构建编码器层==================================
class EncoderLayer(nn.Module):
def __init__(self, size, self_attn, feed_forward, dropout):
"""它的初始化函数有4个,分别是size,其实就是词嵌入维度的大小"""
# self_attn: 传入的多头自注意力子层的实例化对象
# feed_forward:前馈全连接层实例化的对象
# dropout: 置0比率
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
# 把size传入其中
self.size = size
# 如图所示,编码器中有两个子层连接结构,所有用clone函数进行克隆
self.sublayer = clones(SublayerConnection(size, dropout), 2) # 复制2个子层连接结构
def forward(self, x, mask):
# 首先让x经过第一个子层连接结构,内部包含多头自注意力机制子层
# 再让张量经过第二个子层连接结构,其中包含前馈前连接网络
x = self.sublayer[0](x, lambda x: self_attn(x, x, x, mask)) #自注意力机制
return self.sublayer[1](x, self.feed_forward) # 执行feed_forward
# 2.3.8 ================================构建编码器======================================
class Encoder(nn.Module):
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N) # 复制N个layer
# 再初始化一个规范化层,它将作用在编码器的最后面
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
# x: 上一层输出张量
# mask: 掩码张量
# 让x依次经历N个编码器层的处理,最后经过规范化层就可以输出了
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
# 2.4.1============================解码器层=====================================
# 解码器是由N个解码器层堆叠而成
# 每个解码器层由三个子层连接结构组成
# 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
# 第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接
# 第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
# 解码器层的作用,作为解码器的组成单元,每个解码器层根据给定的输入向目标方向进行特征提取操作,即解码过程
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
# size : 词嵌入维度
# self_attn : 多头自注意力对象,也就是说这个注意力机制里面,需要Q=K=V
# src_attn : 多头注意力对象,这里Q!K=V,
# feed_forward : 前馈前连接层对象
super(DecoderLayer, self).__init__()
# 在初始化函数中,主要就是将这些输入传到类中
self.size = size
self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
# 按照结构图,使用clones函数克隆三个子层连接对象
self.layers = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, source_mask, target_mask):
# x: 来自上一层的输入x
# mermory : 来自编码器层的语义存储变量
# source_mask : 源数据掩码张量
# target_mask : 目标数据掩码张量
m = memory
"""将x传入第一个子层结构,第一个子层结构的输入分别是x和self_attn函数,因为是自注意力机制,所以QKV相等,最后
一个参数是目标数据掩码张量,这时要对目标数据进行遮掩,因此此时模型可能还没有生成任何目标数据,比如在解码器准备生成第一个字符或词汇时
我们其实已经传入了第一个字符以便计算损失,但我们不希望在生成第一个字符时模型能利用这个信息,因此我们会将其遮掩,同样生成第二个字符或词汇时
模型只能使用第一个字符或词汇信息,第二个字符以及之后的信息都不允许被模型使用"""
x = self.layers[0](x, lambda x: self.src_attn(x, x, x, target_mask))
# 接着进入第二个子层,这个子层中常规的注意力机制,q是输入x; k, v是编码层输出memory
# 同样也传入source_mask, 但进行源数据遮掩的原因并非是抑制信息泄露,而是遮蔽掉对结果没有意义的字符而产生的注意力之
# 依次提升模型效果和训练速度,这样就完成了第二个子层的处理
x = self.layers[1](x, lambda x: self.src_attn(x, m, m, source_mask))
# 最后一个子层就是前馈全连接子层,经过它的处理后就可以返回结果,这就是解码器层的结构
return self.layers[2](x, self.feed_forward)
# 2.4.2============================解码器=====================================
class Decoder(nn.Module):
def __init__(self, layer, N):
"""初始化函数的参数有两个,第一个就是解码器层layer,第二个是解码器层的个数N"""
super(Decoder, self).__init__()
# 首先使用clones方法克隆N个layer,然后实例化一个规范化层,因为数据走过了所有的解码器层最后要做规范化处理
# layer: 代表解码器层的对象
# N: 代表将layer进行几层的拷贝
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memoroy, source_mask, target_mask):
# x: 上一层的输出x
# memory: 编码器的输出
# source_mask: 源数据掩码张量
# target_mask: 目标数据掩码张量
for layer in self.layers:
x = layer(x, memoroy, source_mask, target_mask)
return self.norm(x)
# 2.5.1============================输出部分实现=====================================
# 学习目标:
# 了解线性层和softmax的作用
# 掌握线性层和softmax的实现过程
# 输出部分包括
# 线性层: 其作用是通过对上一步的线性变化得到指定维度的输出,也就是转换维度的作用
# softmax层:使最后一维的向量中的数字缩放到0-1的概率值域内,并满足他们的和为1
class Generator(nn.Module):
def __init__(self, d_model, vocab_size):
# d_model:词嵌入维度
# vocab_size: 词表大小
super(Generator, self).__init__()
# 首先使用nn中预定义线性层进行实例化,得到一个对象self.project等待使用
# 这个线性层有两个参数,就是初始化函数传进来的两个参数:d_model和vocab_size
self.project = nn.Linear(d_model, vocab_size)
def forward(self, x):
return F.log_softmax(self.project(x), dim=-1) # 最后一个维度
# 2.6.1=================================Transformer模型构建==========================================
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, source_embed, target_embed, generator):
# encoder : 编码器对象
# decoder : 解码器对象
# source_embed : 源数据嵌入函数
# target_embed : 目标数据嵌入函数
# generator : 输出部分的类别生成器对象
super(EncoderDecoder, self).__init__()
# 将参数传入到类中
self.encoder = encoder
self.decoder = decoder
self.src_embed = source_embed
self.tgt_embed = target_embed
self.generator = generator
def forward(self, source, target, source_mask, target_mask):
# 在函数中,将source, source_mask传入编码函数,得到结果后与source_mask, target, target_mask一同传给解码函数
return self.decode(self.encode(source, source_mask), source_mask, target, target_mask)
def encode(self, source, source_mask):
# 先使用src_embed对source做处理,然后和source_mask一起传给self.encoder
return self.encoder(self.src_embed(source), source_mask)
def decode(self, memory, source_mask, target, target_mask):
# 以memory即编码器的输出,source_mask, target, target_mask为参数
# 使用tgt_embed对target做处理,然后和source_mask, target_mask, memory一起传给
return self.decoder(self.tgt_embed(target), memory, source_mask, target_mask)
# 2.6.2 ==============================Transformer模型构建过程的代码分析================================
def make_model(source_vocab, target_vocab, N=6, d_model = 512, d_ff = 2048, head = 8, dropout = 0.1):
"""该函数用来构建模型,有7个参数"""
# source_vocab : 代表源数据的词汇总数
# target_vocab: 代表目标数据的词汇综述
# N : 编码器和解码器堆叠的层数
# d_model : 代表词嵌入的维度
# d_ff : 前馈全连接层中变换矩阵的维度
# head : 多头注意力机制中的头数
# dropout : 置零比率
# 首先得到一个深度拷贝命令,接下来很多结构都需要进行深度拷贝,来保证他们彼此之间相互独立,不受干扰
c = copy.deepcopy
# 实例化多头注意力类
attn = MultiHeadAttention(head, d_model)
# 实例化前馈全连接
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
# 实例化位置编码器,得到对象position
position = PostionalEncoding(d_model, dropout)
"""根据结构图,最外层是EncoderDecoder,在EncoderDecoder中,分别是编码器层,
解码器层,源数据Embedding层和位置编码组成的有序结构,目标数据Embedding层和位置编码组成的有序结构,以及类别生成器层
在编码器层中有attention子层以及前馈全连接子层
在解码器中有两个attention子层以及前馈全连接层"""
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, source_vocab), c(position)),
nn.Sequential(Embeddings(d_model, target_vocab), c(position)),
Generator(d_model, target_vocab)
)
# 模型构建完成后,接下来就是初始化模型中的参数,比如线性层中的变换矩阵
# 这里一旦判断参数的维度大于1,则会将其初始化成一个服从均匀分布的矩阵
for p in model.parameters():
if p.dim()>1:
nn.init.xavier_normal_(p)
return model
# 2.7 ========================================模型基本测试运行==============================================
# 学习目标:了解Transformer模型基本测试的copy任务,掌握实现copy任务的四部曲
# copy任务介绍:
# 任务描述:针对数字序列进行学习,学习的最终目标是使输出与输入的序列相同,如输入[1,5,8,9,3],输出也是[1,5,8,9,3]
# 任务意义:copy任务在模型基础测试中具有重要意义,因为copy操作对于模型来讲是一条明显规律,因此模型能否在短时间内,小数据集中学会它,可以帮助
# 我们断定模型所有过程是否正常,是否已具备基本学习能力
# 使用copy任务进行模型基本测试的四部曲
# 第一步:构建数据集生成器
# 第二步:获得Transformer模型及其优化器和损失函数
# 第三步:运行模型进行训练和评估
# 第四步:使用模型进行贪婪解码
# 第一步:构建数据集生成器
from pyitcast.transformer_utils import Batch
def data_generator(V, batch_size, num_batch):
""""该函数用于随机生成copy任务的数据,它的三个输入参数是V:随机生成数字的最大值+1
batch_size:每次输送给模型更新一次参数的数据量,num_batch:一共输送num_batch次完成一轮"""
# 使用for 循环遍历
for i in range(num_batch):
# 在循环中使用np的random.randint方法随机生成[1,V)的整数
# 分布在(batch_size, 10)形状的矩阵中,然后再把numpy形式转换成torch中的tensor
data_temp = np.random.randint(1, V, size=(batch_size, 10), dtype="int64")
data = torch.from_numpy(data_temp)
# print("生成的数据为:++++++++++++++++++", data)
data[:, 0] = 1 # 第一列初始化成1,作为起始标志
# 因为是copy任务,所有源数据与目标数据完全一致
source = Variable(data, requires_grad = False) # 将requires_grad参数设置为False,表示这些数据不在模型训练的过程中更新
target = Variable(data, requires_grad = False)
# 使用Batch对source和target进行对应批次的掩码张量生成,最后使用yield返回
yield Batch(source, target)
# ======================================四部曲中第三步:运行模型进行训练和评估=================================
# 导入模型单轮训练工具包run_epoch,该工具将对模型使用给定的损失函数计算方法进行单轮参数更新
# 并打印每轮参数更新的损失结果
from pyitcast.transformer_utils import run_epoch
def run(model, loss, epochs = 10, V=11):
"""模型训练函数,共有三个参数,model代表将要进行训练的模型,loss代表使用的损失计算方法,epochs代表模型训练的轮次"""
for epoch in range(epochs):
# 模型使用训练模式,所有参数将本更新
model.train()
# 训练时,batch_size = 20
run_epoch(data_generator(V, 8, 20), model, loss)
#模型使用评估模式,参数将不会变化
model.eval()
#评估时,batch_size = 5
run_epoch(data_generator(V, 8, 5), model, loss)
def run_greedy_decode(model, loss, epochs=10):
for epoch in range(epochs):
model.train() #模型进入train模式,参数更新
run_epoch(data_generator(V, 8, 20), model, loss)
model.eval()
run_epoch(data_generator(V, 8, 5), model, loss)
# 模型进入测试模式
model.eval()
# 定义源数据掩码张量,因为元素都是1,在我们这里1代表不遮掩
# 因此相当于对源数据没有任何遮掩
source_mask = Variable(torch.ones(1, 1, 10))
# 最后将model, src, src_mask, 解码的最大长度限制max_len,默认为0
# 以及其实标志数字,默认为1,我们这里使用的也是1
result = greedy_decode(model, source, source_mask, max_len=10, start_symbol = 1)
print(result)
if __name__ == '__main__':
d_model = 512
vocab = 1000
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embeddings(d_model, vocab)
embr = emb(x)
# print("embr:", embr)
# print(embr.shape)
# ============================测试PostionalEncoding=====================================
pe = PostionalEncoding(d_model, dropout=0.1, max_len=60) #初始化PotionalEncoding层
# embr就是PostionalEncoding类里面forward函数中的x,也就是Embedding层的输出,文本的词嵌入张量
pe_result = pe(embr)
# pe_result的形状(2,4,512),最后一维是词嵌入维度
# print("pe_result:", pe_result)
# print(pe_result.shape)
# ===================================测试自注意力机制=====================================
# 得到pe_result后,就要进入注意力机制了
# 令query = key = value,即所谓的自注意力机制
query = key = value = pe_result
mask = Variable(torch.zeros(2,4,4))
attn, p_attn = attention(query, key, value, mask=mask)
print("attn:", attn)
print(attn.shape) # attn的shape(2,4,512)
print("p_attn:", p_attn)
print(p_attn.shape) #p_attn的shape(2,4,4)
# ===================================测试多头自注意力机制=====================================
head = 8
mha = MultiHeadAttention(head, d_model, dropout=0.2)
mha_result = mha(query, key, value, mask=mask) #实例化MultiHeadAttention层
print(mha_result)
print(mha_result.shape)
# ===================================测试前馈全连接====================================
ffn = PositionwiseFeedForward(d_model, d_ff=64, dropout=0.2) #实例化全连接层
x = mha_result
ffn_result = ffn(x)
print(ffn_result)
print(ffn_result.shape)
# ===================================测试规范化层====================================
x = ffn_result
ln = LayerNorm(features=d_model, eps=1e-6)
ln_result = ln(x)
print(ln_result)
print(ln_result.shape)
# ===================================测试子层连接层====================================
x = pe_result
self_attn = MultiHeadAttention(head=head, embedding_dim=d_model) #实例化一个MultiHeadAttention层
sublayer = lambda x :self_attn(x,x,x,mask) #定义sublayer层,这里采用自注意力机制,因为query=key=value=x
sc = SublayerConnection(d_model, dropout=0.2)# 实例化一个SublayerConnection层
sc_result = sc(x, sublayer)
print(sc_result)
print(sc_result.shape)
# ===================================测试EncoderLayer层====================================
size = d_model =512
head = 8
d_ff = 64
x = pe_result
dropout = 0.2
self_attn = MultiHeadAttention(head=head, embedding_dim=d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
mask = Variable(torch.zeros(2, 4, 4))
el = EncoderLayer(size, self_attn=self_attn, feed_forward=ff, dropout=dropout)
el_result = el(x, mask)
print(el_result)
print(el_result.shape)
# ===================================测试Encoder====================================
size = d_model=512
d_ff=64
head=8
c = copy.deepcopy
attn = MultiHeadAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
dropout = 0.2
layer = EncoderLayer(size, c(attn), c(ff), dropout)
N = 8 # 8个编码器层
mask = Variable(torch.zeros(2,4,4))
en = Encoder(layer, N)
en_result = en(x, mask)
print("en_result: ", en_result)
print(en_result.shape)
# ===================================测试Decoder类====================================
size = d_model =512
d_ff=64
head = 8
c = copy.deepcopy
dropout=0.2
self_attn = MultiHeadAttention(head, d_model) # 实例化多头注意力对象
src_attn = MultiHeadAttention(head, d_model) # 实例化多头注意力对象
ff = PositionwiseFeedForward(d_model=d_model, d_ff=d_ff, dropout=dropout) # 实例化前馈全连接层
de_layer = DecoderLayer(size=size, self_attn=c(self_attn), src_attn=c(src_attn), feed_forward=ff, dropout=dropout) # 实例化解码器层
N=8 # 8个编码器堆叠
x = pe_result
memory = en_result
mask = Variable(torch.zeros(2, 4, 4))
source_mask = target_mask = mask
de = Decoder(layer=de_layer, N=N) # 实例化解码器
de_result = de(x, memory, source_mask, target_mask)
print(de_result)
print(de_result.shape)
# ===================================测试输出类====================================
d_model = 512
vocab_size = 1000
x = de_result
gen = Generator(d_model, vocab_size)
gen_result = gen(x)
print(gen_result)
print(gen_result.shape)
# ===================================测试Transformer模型====================================
vocab_size = 1000
d_model = 512
encoder = en
decoder = de
source_embed = nn.Embedding(vocab_size, d_model)
target_embed = nn.Embedding(vocab_size, d_model)
generator = gen
# 假设源数据与目标数据相同,实际中并不相同
source = target = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
# 假设src_mask与tgt_mask相同,实际中并不相同
source_mask = target_mask = Variable(torch.zeros(2, 4, 4))
# 调用
ed = EncoderDecoder(encoder, decoder, source_embed, target_embed, generator) #实例化一个transformer模型
ed_result = ed(source, target, source_mask, target_mask)
print(ed_result)
print(ed_result.shape)
# ==========================================测试make_model函数===========================================
source_vocab = 11 # 源数据词汇总量
target_vocab = 11 # 目标数据词汇总量
N = 6
res = make_model(source_vocab, target_vocab, N) # res为返回的模型
# print("The structure of model is:", res)
# ===========================================data_generator函数测试=========================================
V = 11
batch = 20
num_batch = 30
res = data_generator(V, batch, num_batch)
print("打印res", res) # res是一个data_generator是一个对象
#======================================四部曲中第二步:获得Transformer模型及其优化器和损失函数=================================
model = make_model(V, V, N=2)
# 使用get_std_opt获得模型优化器
model_optimizer = get_std_opt(model)
# 使用LabelSmoothing获得标签平滑对象
criterion = LabelSmoothing(size = V, padding_idx = 0, smoothing = 0.0)
# 使用SimpleLoassCompute获得利用标签平滑结果的损失计算方法
loss = SimpleLossCompute(model.generator, criterion, model_optimizer)
# ======================================测试run函数======================================
run(model, loss, epochs=10, V=V)
# ======================================第四步: 使用模型进行贪婪解码======================================
# 假定的输入张量
source = Variable(torch.LongTensor([[1, 3, 2, 5, 4, 6, 7, 8, 9, 10]]))
run_greedy_decode(model, loss)
公开课中的P47-P56:用torchtext包在wikiText2上构建语言模型
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
# 导入经典文本相关数据集的工具包
import torchtext
# 导入专门用于英文分词的工具
from torchtext.data.utils import get_tokenizer
#导入已经构建完成的transformer包
from pyitcast.transformer import TransformerModel
import time
# 导入wikiText-2数据集并作基本处理
TEXT = torchtext.data.Field(tokenize=get_tokenizer("basic_english"),
init_token='' ,
eos_token = '' ,
lower=True)
# 最终获得了一个Field对象,即TEXT是一个Field对象
# 使用torchtext的数据集方法导入WikiText2数据
# 并切分为对应训练文本,验证文本,测试文本,并对这些文本施加刚刚创建的预料阈
train_txt, val_txt, test_txt, = torchtext.datasets.WikiText2.splits(TEXT) # splits切分
#可以通过examples[0].text取出文本对象进行查看
print(test_txt.examples[0].text[:10]) #本质上是一个列表
# 将训练集文本数据构建成一个vocab对象
TEXT.build_vocab(train_txt) #把原始语料扔进去构建单词表
# 然后选择cuda或cpu
device = torch.device("cuda" if torch.cuda. is_available() else "cpu")
# ============================构建用于模型输入的批次化数据============================
def batchify(data, bsz):
"""batchify函数用于将文本数据映射成连续数字,并转换成指定的样式,指定的样式可参考下图
batchify函数有两个参数,data是我们之前得到的文本数据(train_txt, val_txt, test_txt),
bsz是就是batch_size,每次模型更新参数的数据量"""
# 使用TEXT对象的numericalize方法将单词映射成对应的连续数字
data = TEXT.numericalize([data.examples[0].text])
# 单词的总数除以批次数,得到nbatch,nbatch代表需要多少次batch后能够遍历完所有数据,data.size(0),就是单词的总数
nbatch = data.size(0) // bsz
# 之后使用narrow方法对不规整的剩余数据进行删除
# 第一个参数是代表横轴删除还是纵轴删除,0为横轴,1为纵轴
# 第二个和第三个参数代表保留开始轴到结束轴的数值,类似切片
data = data.narrow(0, 0, nbatch*bsz)
# 经过上面的操作,data目前的形状是(numWord,1),其中numWord是单词的个数,每一列的数字为单词的映射
# print(data)
# print(data.shape)
# 下面我们需要将data的形状变成(bsz, -1),即bsz行
data = data.view(bsz,-1).t().contiguous() # contiguous,将data在内存中存储在一片连续的区域
return data.to(device)
# 上面的分割批次并没有进行源数据与目标数据的处理,接下来我们将根据语言模型训练的语料规定来构建源数据与目标数据
# ============================批次化过程的第二个函数get_batch代码分析======================
# 令句子长度允许的最大值是bptt为35
bptt = 35 #即一个句子里,最多包含35个单词
def get_batch(source, i):
"""用于获得每个批次合理大小的源数据和目标数据
参数source是通过batchify得到的train_data/ val_data / test_data,i是具体的批次次数"""
# 首先确定句子长度,它将是在bptt和len(source)-1-i中最小的值
# 实质上,前面的批次中都会是bptt的值,只不过最后一个批次中,句子长度可能不够bptt的35,因此会变为len(source)-1-i的值
seq_len = min(bptt, len(source)-1-i)
# 语言模型训练的源数据的第i批数据将是batchify的结果的切片[i:i+seq_len]
data = source[i:i+seq_len]
# 根据语言模型训练的语料规定,它的目标数据是源数据向后移动一位
# 因为最后目标数据的切片会越界,因此使用view(-1)来保证形状正常
target = source[i+1 : i+1+seq_len].view(-1)
return data, target
batch_size = 20
# 验证和测试数据(统称为评估数据)的batch size
eval_batch_size = 10
# 获得train_data, val_data, test_data
train_data = batchify(train_txt, batch_size)
val_data = batchify(val_txt, eval_batch_size)
test_data = batchify(test_txt, eval_batch_size)
# =======================================构建训练和评估函数============================================
# 设置模型超参数和初始化模型
# 通过TEXT.vocab.stoi方法获得不重复词汇
ntokens = len(TEXT.vocab.stoi)
# 词嵌入大小为200
emsize = 200
# 前馈全连接层节点数
nhid = 200
# 编码器层的数量
nlayers = 2
# 多头注意力机制头数
nhead = 2
# 置零比率
dropout = 0.2
#将参数传入TransformerModel中
model = TransformerModel(ntoken = ntokens, ninp = emsize, nhead = nhead, nhid = nhid, nlayers = nlayers, dropout = dropout).to(device)
# 模型初始化后,接下来进行损失函数和优化方法的选择
# 关于损失函数,我们使用nn自带的交叉熵孙淑
criterion = nn.CrossEntropyLoss()
# 学习率5.0
lr = 5.0
# 优化器选择torch自带的SGD,并把lr传入
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
# 定义学习率调整方法,使用torch自带的lr_scheduler,将优化器传入其中
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.95)
def train(epoch):
# 模型开启训练模式
model.train()
# 定义初始损失为0
total_loss = 0
# 获得当前时间
start_time = time.time()
# 开始遍历批次数据
for batch, i in enumerate(range(0, train_data.size(0)-1, bptt)):
# 通过get_batch获得源数据和目标数据
data, targets = get_batch(train_data, i)
# 设置优化器初始采样梯度为0梯度
optimizer.zero_grad()
# 将数据装入model得到输出
output = model(data)
# 将输出和目标数据传入损失函数对象
loss = criterion(output.view(-1, ntokens), targets)
# 损失进行反向传播已获得总损失
loss.backward()
# 用nn自带的clip_grad_norm_方法进行梯度规范化,防止出现梯度消失或爆炸
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
# 模型参数进行更新
optimizer.step()
# 将每层的损失相加得到总损失
total_loss += loss.item()
# 日志打印间隔200
log_interval = 200
# 如果batch是200的倍数且大于0,则打印相关日志
if batch % log_interval == 0 and batch > 0:
# 平均损失为总损失除以log_interval
cur_loss = total_loss / log_interval
# 需要的时间为当前时间减去开始时间
elapsed = time.time() - start_time
print('| epoch {:3d}| {:5d}/{:5d} batches|'
'lr {:02.2f} | ms/batch {:5.2f} |'
'loss {:5.2f} | ppl{:8.2f}'.format(
epoch, batch, len(train_data) // bptt, scheduler.get_lr()[0],
elapsed * 1000 / log_interval, cur_loss, math.exp(cur_loss)))
# 每个批次结束后,总损失归0
total_loss = 0
# 开始时间取当前时间
start_time = time.time()
def evaluate(eval_model, data_source):
"""评估函数,评估阶段包括验证和测试,它的两个参数eval_model为每轮训练产生的模型
data_source代表验证或测试数据集"""
# 模型开启评估模式
eval_model.eval()
# 总损失归0
total_loss = 0
# 因为评估模式参数不变,因此反向传播不需要求导,以加快计算
with torch.no_grad():
# 与训练过程相同,但是因为过程不需要打印信息,因此不需要batch数
for i in range(0, data_source.size(0)-1, bptt):
# 首先还是要通过get_batch获得验证数据集的源数据和目标数据
data, target = get_batch(data_source, i)
# 通过eval_model获得输出
output = eval_model(data)
# 对输出形状扁平化,变为全部词汇的概率分布
output_flat = output.view(-1, ntokens)
total_loss += criterion(output_flat, target).item()
return total_loss
# 首先初始化最佳验证损失,初始化值为无穷大
best_val_loss = float("inf")
# 定义训练轮数
epochs = 3
# 定义最佳模型变量,初始化为None
best_model = None
for epoch in range(1, epochs+1):
#首先获得轮数开始时间
start_time = time.time()
# 调用训练函数
train(epoch)
# 该轮训练后我们的模型参数已经发生了变化
# 将模型和评估数据传入到评估函数中
val_loss = evaluate(model, val_data)
# 之后打印每轮的评估日志,分别有轮数,耗时,验证损失以及验证困惑度
print('-' *89)
print('| end of epoch {:3d} | time: {:5.2f}s | valid loss {:5.2f} |'
'valid ppl {:8.2f}'. format(epoch, (time.time()-start_time), val_loss, math.exp(val_loss)))
print('-' * 89)
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model = model
# 每轮会对优化方法的学习率进行调整
scheduler.step()
3 遇到的问题
3.1. 视频中用到的torch版本是torch=1.3.1,
遇到from torch.data.utils import get_tokenizer,显示No module named torch.data,原因可能是torch 1.13版本对早期的版本的结构有所变更,改成以下from torchtext.data.utils import get_tokenizer可解决
Transformer论文精读
李沐论文精度
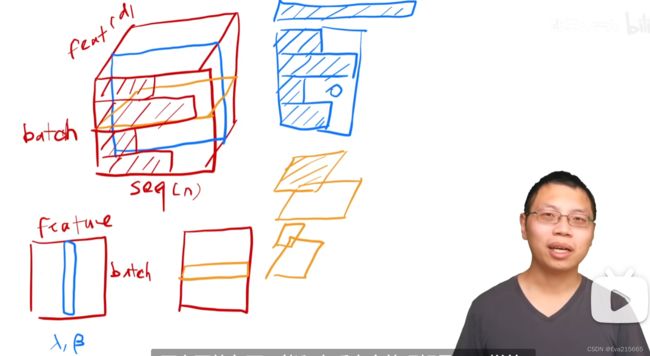
LayerNorm和BatchNorm的区别?为什么用LayerNorm?下图解释的比较清楚,其中蓝色是batchNorm的切法,橘色是layerNorm的切法。
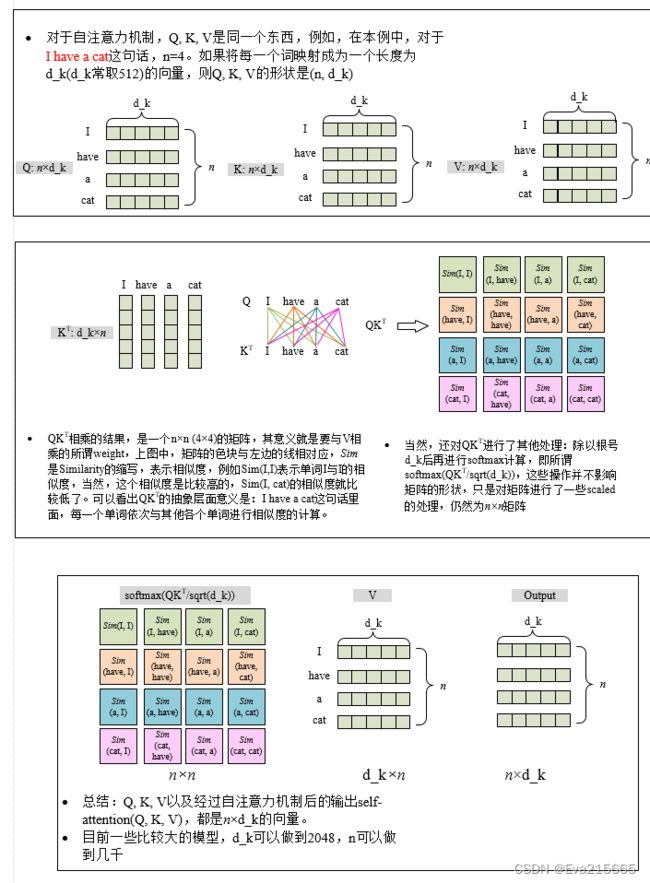
对于自注意力机制(以及常规注意力机制),网上有很多解释,这里根据自己的理解做了一个图,是自己能懂的版本。总结几点:
- 如果一句话有n个单词,把每一个单词映射成长度为d_k(d_k常取512)的向量,对于自注意力机制,Q, K, V以及自注意力机制的输出self-Attention(Q, K, V)都是同样的形状:(n, d_k)
- 对于常规注意力机制,K, V的形状是一样的,Q的形状为(m, d_k),也就是transformer架构里decoder部分,中间的那个东西:K, V是Encoder的输出(n, d_k),Q来自decoder下面那个注意力的输出,形状为(m, d_k)。输出Attention(Q, K, V)形状为(m, d_k),与Q的形状是一致的。