死磕Spring系列:BeanDefinition注册流程
在Spring项目中,为什么我们仅仅只需要在类上定义一个@Component之类的注解,就能让Spring去管理和使用这个类了呢?
聪明的小伙伴肯定很快就想到了,肯定是在启动项目的时候,框架去判断类上面有没有特定的注解,然后通过反射去创建对象的。Spring就是以这样的思路来进行Bean管理的,但是Spring在其中考虑的更细致,比如这个bean在以后使用的时候是新创建,还是使用最开始创建的对象,还是在每个请求或者每个session作用域中使用同一个或者多个这个类的实例,又比如这个类是否依赖于其他类实例,在什么条件下才应该去生成这个类实例,基本上在实际业务上使用的到的场景,Spring统统对其进行了功能的提供。
在Spring的启动流程中,Spring会去根据指定路径下加载类信息,然后封装成BeanDefinition,就是bean的定义信息,之后会通过BeanDefinition来创建和初始化实例存入上下文中。
今天我们先来对扫描并封装为BeanDefinition的这一过程做一个细致的说明
1. 执行入口
在SpringBoot项目中,基本都是通过SpringApplication.run去启动一个项目,在这个方法里面,会去创建一个ApplicationContext,也就是IOC容器,然后对容器执行刷新操作。在刷新的过程中,会去调用所有BeanDefinitionRegistryPostProcessor的postProcessBeanDefinitionRegistry去往容器中注册BeanDefinition。在Spring中,ConfigurationClassPostProcessor实现了从文件中去读取生成BeanDefinition并注册到容器的功能。
类的继承关系:
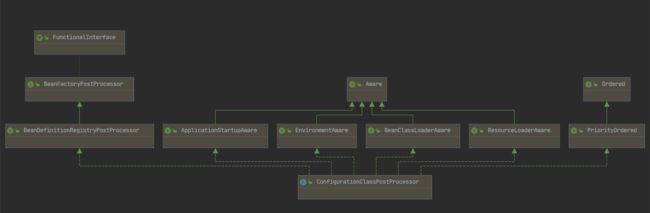
ConfigurationClassPostProcessor实现了BeanDefinitionRegistryPostProcessor,所以它拥有了注册bean的能力;因为在执行BeanDefinitionRegistryPostProcessor时对实现了PriorityOrdered类的优先执行,所以ConfigurationClassPostProcessor具有较高的优先级。
首先来看被调用的方法:
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) {
int registryId = System.identityHashCode(registry);
if (this.registriesPostProcessed.contains(registryId)) {
throw new IllegalStateException(
"postProcessBeanDefinitionRegistry already called on this post-processor against " + registry);
}
if (this.factoriesPostProcessed.contains(registryId)) {
throw new IllegalStateException(
"postProcessBeanFactory already called on this post-processor against " + registry);
}
this.registriesPostProcessed.add(registryId);
processConfigBeanDefinitions(registry);
}
对registry生成了一个id,来防止重复执行。
接下来贴一下processConfigBeanDefinitions方法的源码,再对代码片段进行解析:
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
List<BeanDefinitionHolder> configCandidates = new ArrayList<>();
String[] candidateNames = registry.getBeanDefinitionNames();
for (String beanName : candidateNames) {
BeanDefinition beanDef = registry.getBeanDefinition(beanName);
if (beanDef.getAttribute(ConfigurationClassUtils.CONFIGURATION_CLASS_ATTRIBUTE) != null) {
if (logger.isDebugEnabled()) {
logger.debug("Bean definition has already been processed as a configuration class: " + beanDef);
}
}
else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {
configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));
}
}
// Return immediately if no @Configuration classes were found
if (configCandidates.isEmpty()) {
return;
}
// Sort by previously determined @Order value, if applicable
configCandidates.sort((bd1, bd2) -> {
int i1 = ConfigurationClassUtils.getOrder(bd1.getBeanDefinition());
int i2 = ConfigurationClassUtils.getOrder(bd2.getBeanDefinition());
return Integer.compare(i1, i2);
});
// Detect any custom bean name generation strategy supplied through the enclosing application context
SingletonBeanRegistry sbr = null;
if (registry instanceof SingletonBeanRegistry) {
sbr = (SingletonBeanRegistry) registry;
if (!this.localBeanNameGeneratorSet) {
BeanNameGenerator generator = (BeanNameGenerator) sbr.getSingleton(
AnnotationConfigUtils.CONFIGURATION_BEAN_NAME_GENERATOR);
if (generator != null) {
this.componentScanBeanNameGenerator = generator;
this.importBeanNameGenerator = generator;
}
}
}
if (this.environment == null) {
this.environment = new StandardEnvironment();
}
// Parse each @Configuration class
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry);
Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates);
Set<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size());
do {
StartupStep processConfig = this.applicationStartup.start("spring.context.config-classes.parse");
parser.parse(candidates);
parser.validate();
Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());
configClasses.removeAll(alreadyParsed);
// Read the model and create bean definitions based on its content
if (this.reader == null) {
this.reader = new ConfigurationClassBeanDefinitionReader(
registry, this.sourceExtractor, this.resourceLoader, this.environment,
this.importBeanNameGenerator, parser.getImportRegistry());
}
this.reader.loadBeanDefinitions(configClasses);
alreadyParsed.addAll(configClasses);
processConfig.tag("classCount", () -> String.valueOf(configClasses.size())).end();
candidates.clear();
if (registry.getBeanDefinitionCount() > candidateNames.length) {
String[] newCandidateNames = registry.getBeanDefinitionNames();
Set<String> oldCandidateNames = new HashSet<>(Arrays.asList(candidateNames));
Set<String> alreadyParsedClasses = new HashSet<>();
for (ConfigurationClass configurationClass : alreadyParsed) {
alreadyParsedClasses.add(configurationClass.getMetadata().getClassName());
}
for (String candidateName : newCandidateNames) {
if (!oldCandidateNames.contains(candidateName)) {
BeanDefinition bd = registry.getBeanDefinition(candidateName);
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bd, this.metadataReaderFactory) &&
!alreadyParsedClasses.contains(bd.getBeanClassName())) {
candidates.add(new BeanDefinitionHolder(bd, candidateName));
}
}
}
candidateNames = newCandidateNames;
}
}
while (!candidates.isEmpty());
// Register the ImportRegistry as a bean in order to support ImportAware @Configuration classes
if (sbr != null && !sbr.containsSingleton(IMPORT_REGISTRY_BEAN_NAME)) {
sbr.registerSingleton(IMPORT_REGISTRY_BEAN_NAME, parser.getImportRegistry());
}
if (this.metadataReaderFactory instanceof CachingMetadataReaderFactory) {
// Clear cache in externally provided MetadataReaderFactory; this is a no-op
// for a shared cache since it'll be cleared by the ApplicationContext.
((CachingMetadataReaderFactory) this.metadataReaderFactory).clearCache();
}
}
2 获取候选name
String[] candidateNames = registry.getBeanDefinitionNames();
这里一进来会有多个已经存在的name,其中包含框架内部的几个beanName和注解了@SpringBootApplication类的name。
3 获取候选配置类
for (String beanName : candidateNames) {
BeanDefinition beanDef = registry.getBeanDefinition(beanName);
if (beanDef.getAttribute(ConfigurationClassUtils.CONFIGURATION_CLASS_ATTRIBUTE) != null) {
if (logger.isDebugEnabled()) {
logger.debug("Bean definition has already been processed as a configuration class: " + beanDef);
}
}
else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {
configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));
}
}
这一步是遍历candidateNames从而去获取带配置类,并存入到configCandidates。
什么样的类才是配置类呢?这是根据ConfigurationClassUtils.checkConfigurationClassCandidate来判断的。
3.1 判断是否是配置类
public static boolean checkConfigurationClassCandidate(
BeanDefinition beanDef, MetadataReaderFactory metadataReaderFactory) {
String className = beanDef.getBeanClassName();
if (className == null || beanDef.getFactoryMethodName() != null) {
return false;
}
AnnotationMetadata metadata;
if (beanDef instanceof AnnotatedBeanDefinition &&
className.equals(((AnnotatedBeanDefinition) beanDef).getMetadata().getClassName())) {
// Can reuse the pre-parsed metadata from the given BeanDefinition...
metadata = ((AnnotatedBeanDefinition) beanDef).getMetadata();
}
else if (beanDef instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) beanDef).hasBeanClass()) {
// Check already loaded Class if present...
// since we possibly can't even load the class file for this Class.
Class<?> beanClass = ((AbstractBeanDefinition) beanDef).getBeanClass();
if (BeanFactoryPostProcessor.class.isAssignableFrom(beanClass) ||
BeanPostProcessor.class.isAssignableFrom(beanClass) ||
AopInfrastructureBean.class.isAssignableFrom(beanClass) ||
EventListenerFactory.class.isAssignableFrom(beanClass)) {
return false;
}
metadata = AnnotationMetadata.introspect(beanClass);
}
else {
try {
MetadataReader metadataReader = metadataReaderFactory.getMetadataReader(className);
metadata = metadataReader.getAnnotationMetadata();
}
catch (IOException ex) {
if (logger.isDebugEnabled()) {
logger.debug("Could not find class file for introspecting configuration annotations: " +
className, ex);
}
return false;
}
}
Map<String, Object> config = metadata.getAnnotationAttributes(Configuration.class.getName());
if (config != null && !Boolean.FALSE.equals(config.get("proxyBeanMethods"))) {
beanDef.setAttribute(CONFIGURATION_CLASS_ATTRIBUTE, CONFIGURATION_CLASS_FULL);
}
else if (config != null || isConfigurationCandidate(metadata)) {
beanDef.setAttribute(CONFIGURATION_CLASS_ATTRIBUTE, CONFIGURATION_CLASS_LITE);
}
else {
return false;
}
// It's a full or lite configuration candidate... Let's determine the order value, if any.
Integer order = getOrder(metadata);
if (order != null) {
beanDef.setAttribute(ORDER_ATTRIBUTE, order);
}
return true;
}
这个方法就分为3部分:
- 根据BeanDefinition的不同类型采用不同api来获取
AnnotationMetadata,就是当前类所有注解的配置信息。 - 根据得到
@Configuration注解的信息,给BeanDefinition设置FULL/LITE信息。 - 给BeanDefinition设置排序信息,排序来源于类的Order注解的value。
总结一下,不为配置类的有这几种情况:
- BeanDefinition的className为null,或者其factoryMethodName不为null。
- 如果这个BeanDefinition是
AbstractBeanDefinition,但是这个bean是BeanFactoryPostProcessor、BeanPostProcessor、AopInfrastructureBean、EventListenerFactory的实例。 - 在获取
AnnotationMetadata时出现错误。 - 没有
@Configuration注解的。 - 有
@Configuration注解,但其属性proxyBeanMethods值为false,且该类是接口,如果类不是接口,那没有注解@Component、@ComponentScan、@Import、@ImportResource且类中没有被@Bean标注的方法。
经过判断之后,将这个配置类的BeanDefinition包装成一个BeanDefinitionHolder存入configCandidates中。
4 配置类排序
configCandidates.sort((bd1, bd2) -> {
int i1 = ConfigurationClassUtils.getOrder(bd1.getBeanDefinition());
int i2 = ConfigurationClassUtils.getOrder(bd2.getBeanDefinition());
return Integer.compare(i1, i2);
});
这个是根据BeanDefinition的排序值进行升序排序,这个印证了order中value越小,优先级越高的说法。
5 BeanName生成器设置
SingletonBeanRegistry sbr = null;
if (registry instanceof SingletonBeanRegistry) {
sbr = (SingletonBeanRegistry) registry;
if (!this.localBeanNameGeneratorSet) {
BeanNameGenerator generator = (BeanNameGenerator) sbr.getSingleton(
AnnotationConfigUtils.CONFIGURATION_BEAN_NAME_GENERATOR);
if (generator != null) {
this.componentScanBeanNameGenerator = generator;
this.importBeanNameGenerator = generator;
}
}
}
如果registry是一个SingletonBeanRegistry,则可能需要从一级缓存中取BeanNameGenerator,然后赋值给componentScanBeanNameGenerator(给扫描出来的bean定义名称用)和importBeanNameGenerator(给import进来的bean定义名称用)。
6 实例化配置类解析器
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry);
实例化并初始化ConfigurationClassParser,后续用于扫描和注册BeanDefinition。
7 解析流程
前面都是为了解析做准备,现在开始是真正干事儿的流程。这是ConfigurationClassParser类中的parse实例方法:
public void parse(Set<BeanDefinitionHolder> configCandidates) {
for (BeanDefinitionHolder holder : configCandidates) {
BeanDefinition bd = holder.getBeanDefinition();
try {
if (bd instanceof AnnotatedBeanDefinition) {
parse(((AnnotatedBeanDefinition) bd).getMetadata(), holder.getBeanName());
}
else if (bd instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) bd).hasBeanClass()) {
parse(((AbstractBeanDefinition) bd).getBeanClass(), holder.getBeanName());
}
else {
parse(bd.getBeanClassName(), holder.getBeanName());
}
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to parse configuration class [" + bd.getBeanClassName() + "]", ex);
}
}
this.deferredImportSelectorHandler.process();
}
这里是根据BeanDefinition的不同类型来使用不同的方法进行处理,这里我们直接分析AnnotatedBeanDefinition的处理方式。
protected final void parse(AnnotationMetadata metadata, String beanName) throws IOException {
processConfigurationClass(new ConfigurationClass(metadata, beanName), DEFAULT_EXCLUSION_FILTER);
}
protected void processConfigurationClass(ConfigurationClass configClass, Predicate<String> filter) throws IOException {
if (this.conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.PARSE_CONFIGURATION)) {
return;
}
ConfigurationClass existingClass = this.configurationClasses.get(configClass);
if (existingClass != null) {
if (configClass.isImported()) {
if (existingClass.isImported()) {
existingClass.mergeImportedBy(configClass);
}
// Otherwise ignore new imported config class; existing non-imported class overrides it.
return;
}
else {
// Explicit bean definition found, probably replacing an import.
// Let's remove the old one and go with the new one.
this.configurationClasses.remove(configClass);
this.knownSuperclasses.values().removeIf(configClass::equals);
}
}
// Recursively process the configuration class and its superclass hierarchy.
SourceClass sourceClass = asSourceClass(configClass, filter);
do {
sourceClass = doProcessConfigurationClass(configClass, sourceClass, filter);
}
while (sourceClass != null);
this.configurationClasses.put(configClass, configClass);
}
代码贴好了,我们来对具体代码段进行解析:
if (this.conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.PARSE_CONFIGURATION)) {
return;
}
这是条件判断器,如果条件不成立,直接返回,不进行parse流程。条件判断具体如框架自带的条件,或者使用@Conditional并指定一个自定义的Condition。
ConfigurationClass existingClass = this.configurationClasses.get(configClass);
if (existingClass != null) {
if (configClass.isImported()) {
if (existingClass.isImported()) {
existingClass.mergeImportedBy(configClass);
}
// Otherwise ignore new imported config class; existing non-imported class overrides it.
return;
}
else {
// Explicit bean definition found, probably replacing an import.
// Let's remove the old one and go with the new one.
this.configurationClasses.remove(configClass);
this.knownSuperclasses.values().removeIf(configClass::equals);
}
}
这里使用了configurationClasses的一个Map来避免同一个配置类的重复解析。
在同一个配置类已经解析过的情况下,有几种应对措施:
- 在当前正在解析的配置类是被Import进来的情况下,如果原来的配置类也是被Import进来的,那就对其进行合并(更新importedBy)。如果原来的配置类是内部的,那就直接return,不解析了,因为内部的肯定要比外部的优先级高,不能让外部的配置影响内部的功能。
- 如果当前正在解析的配置类是内部的,那就直接替换使用当前配置类。
SourceClass sourceClass = asSourceClass(configClass, filter);
do {
sourceClass = doProcessConfigurationClass(configClass, sourceClass, filter);
}
while (sourceClass != null);
这里首先将ConfigClass包装成一个SourceClass。再使用doProcessConfigurationClass方法去真正执行扫描注册,后得到一个sourceClass,如果sourceClass不为空,则一直执行。
private SourceClass asSourceClass(ConfigurationClass configurationClass, Predicate<String> filter) throws IOException {
AnnotationMetadata metadata = configurationClass.getMetadata();
if (metadata instanceof StandardAnnotationMetadata) {
return asSourceClass(((StandardAnnotationMetadata) metadata).getIntrospectedClass(), filter);
}
return asSourceClass(metadata.getClassName(), filter);
}
这里是根据AnnotationMetadata的不同类型通过不同的API获取到SourceClass。
doProcessConfigurationClass是真正干活儿的地方,贴一下所有代码先:
@Nullable
protected final SourceClass doProcessConfigurationClass(
ConfigurationClass configClass, SourceClass sourceClass, Predicate<String> filter)
throws IOException {
if (configClass.getMetadata().isAnnotated(Component.class.getName())) {
// Recursively process any member (nested) classes first
processMemberClasses(configClass, sourceClass, filter);
}
// Process any @PropertySource annotations
for (AnnotationAttributes propertySource : AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), PropertySources.class,
org.springframework.context.annotation.PropertySource.class)) {
if (this.environment instanceof ConfigurableEnvironment) {
processPropertySource(propertySource);
}
else {
logger.info("Ignoring @PropertySource annotation on [" + sourceClass.getMetadata().getClassName() +
"]. Reason: Environment must implement ConfigurableEnvironment");
}
}
// Process any @ComponentScan annotations
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
if (!componentScans.isEmpty() &&
!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
for (AnnotationAttributes componentScan : componentScans) {
// The config class is annotated with @ComponentScan -> perform the scan immediately
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// Check the set of scanned definitions for any further config classes and parse recursively if needed
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}
// Process any @Import annotations
processImports(configClass, sourceClass, getImports(sourceClass), filter, true);
// Process any @ImportResource annotations
AnnotationAttributes importResource =
AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class);
if (importResource != null) {
String[] resources = importResource.getStringArray("locations");
Class<? extends BeanDefinitionReader> readerClass = importResource.getClass("reader");
for (String resource : resources) {
String resolvedResource = this.environment.resolveRequiredPlaceholders(resource);
configClass.addImportedResource(resolvedResource, readerClass);
}
}
// Process individual @Bean methods
Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(sourceClass);
for (MethodMetadata methodMetadata : beanMethods) {
configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));
}
// Process default methods on interfaces
processInterfaces(configClass, sourceClass);
// Process superclass, if any
if (sourceClass.getMetadata().hasSuperClass()) {
String superclass = sourceClass.getMetadata().getSuperClassName();
if (superclass != null && !superclass.startsWith("java") &&
!this.knownSuperclasses.containsKey(superclass)) {
this.knownSuperclasses.put(superclass, configClass);
// Superclass found, return its annotation metadata and recurse
return sourceClass.getSuperClass();
}
}
// No superclass -> processing is complete
return null;
}
7.1 处理内部配置类
if (configClass.getMetadata().isAnnotated(Component.class.getName())) {
// Recursively process any member (nested) classes first
processMemberClasses(configClass, sourceClass, filter);
}
这一步是判断如果配置类是含有@Component注解的,注意注解的多重注解关系,比如@Service注解中是引用了@Component注解的,所以也算是含有@Component。
private void processMemberClasses(ConfigurationClass configClass, SourceClass sourceClass,
Predicate<String> filter) throws IOException {
Collection<SourceClass> memberClasses = sourceClass.getMemberClasses();
if (!memberClasses.isEmpty()) {
List<SourceClass> candidates = new ArrayList<>(memberClasses.size());
for (SourceClass memberClass : memberClasses) {
if (ConfigurationClassUtils.isConfigurationCandidate(memberClass.getMetadata()) &&
!memberClass.getMetadata().getClassName().equals(configClass.getMetadata().getClassName())) {
candidates.add(memberClass);
}
}
OrderComparator.sort(candidates);
for (SourceClass candidate : candidates) {
if (this.importStack.contains(configClass)) {
this.problemReporter.error(new CircularImportProblem(configClass, this.importStack));
}
else {
this.importStack.push(configClass);
try {
processConfigurationClass(candidate.asConfigClass(configClass), filter);
}
finally {
this.importStack.pop();
}
}
}
}
}
这里是对子类进行解析的具体方法,可以看到并不是所有子类都能被解析的。
ConfigurationClassUtils.isConfigurationCandidate(memberClass.getMetadata()) && !memberClass.getMetadata().getClassName().equals(configClass.getMetadata().getClassName())
能被解析的子类需要满足以下几个条件:
- 含有Component、ComponentScan、Import、ImportResource注解。
- 如果不含上述注解,需要其内部含有Bean Method。
- 子类的类名与父类的名称不同。
7.2 处理PropertySource
// Process any @PropertySource annotations
for (AnnotationAttributes propertySource : AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), PropertySources.class,
org.springframework.context.annotation.PropertySource.class)) {
if (this.environment instanceof ConfigurableEnvironment) {
processPropertySource(propertySource);
}
else {
logger.info("Ignoring @PropertySource annotation on [" + sourceClass.getMetadata().getClassName() +
"]. Reason: Environment must implement ConfigurableEnvironment");
}
}
AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), PropertySources.class,
org.springframework.context.annotation.PropertySource.class)
这一步其实就是在当前的注解元数据(AnnotationMetadata)中找到所有PropertySource数据。这里PropertySources就是一个集合,它可以用一个注解来集合多个。
使用示例:
@PropertySources({@PropertySource("1.properties"), @PropertySource("2.properties")})
接着使用processPropertySource去处理单个PropertySource。
private void processPropertySource(AnnotationAttributes propertySource) throws IOException {
String name = propertySource.getString("name");
if (!StringUtils.hasLength(name)) {
name = null;
}
String encoding = propertySource.getString("encoding");
if (!StringUtils.hasLength(encoding)) {
encoding = null;
}
String[] locations = propertySource.getStringArray("value");
Assert.isTrue(locations.length > 0, "At least one @PropertySource(value) location is required");
boolean ignoreResourceNotFound = propertySource.getBoolean("ignoreResourceNotFound");
Class<? extends PropertySourceFactory> factoryClass = propertySource.getClass("factory");
PropertySourceFactory factory = (factoryClass == PropertySourceFactory.class ?
DEFAULT_PROPERTY_SOURCE_FACTORY : BeanUtils.instantiateClass(factoryClass));
for (String location : locations) {
try {
String resolvedLocation = this.environment.resolveRequiredPlaceholders(location);
Resource resource = this.resourceLoader.getResource(resolvedLocation);
addPropertySource(factory.createPropertySource(name, new EncodedResource(resource, encoding)));
}
catch (IllegalArgumentException | FileNotFoundException | UnknownHostException | SocketException ex) {
// Placeholders not resolvable or resource not found when trying to open it
if (ignoreResourceNotFound) {
if (logger.isInfoEnabled()) {
logger.info("Properties location [" + location + "] not resolvable: " + ex.getMessage());
}
}
else {
throw ex;
}
}
}
}
- 首先创建得到一个
PropertySourceFactory,方便后续通过Resource创建PropertySource。 - 通过从指定路径中得到解析后的路径
resolvedLocation。 - 通过资源加载器
resourceLoader从指定路径加载资源,得到一个Resource。 - 根据指定编码
encoding得到一个EncodedResource。 - 使用工厂创建得到一个
PropertySource。 - 添加
PropertySource到environment环境。
这里我们来看一下添加的方法:
private void addPropertySource(PropertySource<?> propertySource) {
String name = propertySource.getName();
MutablePropertySources propertySources = ((ConfigurableEnvironment) this.environment).getPropertySources();
if (this.propertySourceNames.contains(name)) {
// We've already added a version, we need to extend it
PropertySource<?> existing = propertySources.get(name);
if (existing != null) {
PropertySource<?> newSource = (propertySource instanceof ResourcePropertySource ?
((ResourcePropertySource) propertySource).withResourceName() : propertySource);
if (existing instanceof CompositePropertySource) {
((CompositePropertySource) existing).addFirstPropertySource(newSource);
}
else {
if (existing instanceof ResourcePropertySource) {
existing = ((ResourcePropertySource) existing).withResourceName();
}
CompositePropertySource composite = new CompositePropertySource(name);
composite.addPropertySource(newSource);
composite.addPropertySource(existing);
propertySources.replace(name, composite);
}
return;
}
}
if (this.propertySourceNames.isEmpty()) {
propertySources.addLast(propertySource);
}
else {
String firstProcessed = this.propertySourceNames.get(this.propertySourceNames.size() - 1);
propertySources.addBefore(firstProcessed, propertySource);
}
this.propertySourceNames.add(name);
}
首先判断当前处理的配置文件名称是否存在于已经添加过的配置文件中,如果是,那么需要取出environment环境中已经存在的PropertySource,并将新的和原来存在的同名的配置文件合并成一个CompositePropertySource对象,CompositePropertySource内部有个propertySources集合,而PropertySource中只有单个source,所以CompositePropertySource能以一个对象表示多个资源文件。
if (this.propertySourceNames.isEmpty()) {
propertySources.addLast(propertySource);
}
else {
String firstProcessed = this.propertySourceNames.get(this.propertySourceNames.size() - 1);
propertySources.addBefore(firstProcessed, propertySource);
}
在这段代码中,我们可以看到,如果propertySourceNames不为空,那么就将当前处理的propertySource放到其尾部元素在propertySources中的前一个位置去。
这里的处理逻辑就是,最后加载的资源文件在使用的时候最先去匹配。
7.3 处理ComponentScan
// Process any @ComponentScan annotations
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
if (!componentScans.isEmpty() &&
!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
for (AnnotationAttributes componentScan : componentScans) {
// The config class is annotated with @ComponentScan -> perform the scan immediately
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// Check the set of scanned definitions for any further config classes and parse recursively if needed
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}
这一步是去扫描指定包下的类信息,封装为BeanDefinition,并注册。
ComponentScans注解的用法和PropertySources类似,都是某个注解的组合注解。
其使用示例:
@ComponentScans({@ComponentScan(basePackages = "cn.javayuli.bootdemo"), @ComponentScan(basePackages = "cn.javayuli.bootdemo2")})
如果没有ComponentScans注解的数据,且条件表达式不满足,则不执行扫描。
7.3.1 ComponentScanParser
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
这里是去扫描类信息成BeanDefinition。进入org.springframework.context.annotation.ComponentScanAnnotationParser#parse方法:
public Set<BeanDefinitionHolder> parse(AnnotationAttributes componentScan, String declaringClass) {
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(this.registry,
componentScan.getBoolean("useDefaultFilters"), this.environment, this.resourceLoader);
Class<? extends BeanNameGenerator> generatorClass = componentScan.getClass("nameGenerator");
boolean useInheritedGenerator = (BeanNameGenerator.class == generatorClass);
scanner.setBeanNameGenerator(useInheritedGenerator ? this.beanNameGenerator :
BeanUtils.instantiateClass(generatorClass));
ScopedProxyMode scopedProxyMode = componentScan.getEnum("scopedProxy");
if (scopedProxyMode != ScopedProxyMode.DEFAULT) {
scanner.setScopedProxyMode(scopedProxyMode);
}
else {
Class<? extends ScopeMetadataResolver> resolverClass = componentScan.getClass("scopeResolver");
scanner.setScopeMetadataResolver(BeanUtils.instantiateClass(resolverClass));
}
scanner.setResourcePattern(componentScan.getString("resourcePattern"));
for (AnnotationAttributes includeFilterAttributes : componentScan.getAnnotationArray("includeFilters")) {
List<TypeFilter> typeFilters = TypeFilterUtils.createTypeFiltersFor(includeFilterAttributes, this.environment,
this.resourceLoader, this.registry);
for (TypeFilter typeFilter : typeFilters) {
scanner.addIncludeFilter(typeFilter);
}
}
for (AnnotationAttributes excludeFilterAttributes : componentScan.getAnnotationArray("excludeFilters")) {
List<TypeFilter> typeFilters = TypeFilterUtils.createTypeFiltersFor(excludeFilterAttributes, this.environment,
this.resourceLoader, this.registry);
for (TypeFilter typeFilter : typeFilters) {
scanner.addExcludeFilter(typeFilter);
}
}
boolean lazyInit = componentScan.getBoolean("lazyInit");
if (lazyInit) {
scanner.getBeanDefinitionDefaults().setLazyInit(true);
}
Set<String> basePackages = new LinkedHashSet<>();
String[] basePackagesArray = componentScan.getStringArray("basePackages");
for (String pkg : basePackagesArray) {
String[] tokenized = StringUtils.tokenizeToStringArray(this.environment.resolvePlaceholders(pkg),
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
Collections.addAll(basePackages, tokenized);
}
for (Class<?> clazz : componentScan.getClassArray("basePackageClasses")) {
basePackages.add(ClassUtils.getPackageName(clazz));
}
if (basePackages.isEmpty()) {
basePackages.add(ClassUtils.getPackageName(declaringClass));
}
scanner.addExcludeFilter(new AbstractTypeHierarchyTraversingFilter(false, false) {
@Override
protected boolean matchClassName(String className) {
return declaringClass.equals(className);
}
});
return scanner.doScan(StringUtils.toStringArray(basePackages));
}
其中最主要分为两步:
- 创建并初始化
ClassPathBeanDefinitionScanner。- nameGenerator
- scopedProxy
- scopeResolver
- resourcePattern
- includeFilters
- excludeFilters
- lazyInit
- basePackages
- basePackageClasses
- 执行doScan。
接下来继续分析doScan:
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
我们来逐个对核心功能进行解析:
-
findCandidateComponentspublic Set<BeanDefinition> findCandidateComponents(String basePackage) { if (this.componentsIndex != null && indexSupportsIncludeFilters()) { return addCandidateComponentsFromIndex(this.componentsIndex, basePackage); } else { return scanCandidateComponents(basePackage); } }componentsIndex这个功能后面补充,现在我们来看看
scanCandidateComponents方法:private Set<BeanDefinition> scanCandidateComponents(String basePackage) { Set<BeanDefinition> candidates = new LinkedHashSet<>(); try { String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX + resolveBasePackage(basePackage) + '/' + this.resourcePattern; Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath); boolean traceEnabled = logger.isTraceEnabled(); boolean debugEnabled = logger.isDebugEnabled(); for (Resource resource : resources) { if (traceEnabled) { logger.trace("Scanning " + resource); } try { MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource); if (isCandidateComponent(metadataReader)) { ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader); sbd.setSource(resource); if (isCandidateComponent(sbd)) { if (debugEnabled) { logger.debug("Identified candidate component class: " + resource); } candidates.add(sbd); } else { if (debugEnabled) { logger.debug("Ignored because not a concrete top-level class: " + resource); } } } else { if (traceEnabled) { logger.trace("Ignored because not matching any filter: " + resource); } } } catch (FileNotFoundException ex) { if (traceEnabled) { logger.trace("Ignored non-readable " + resource + ": " + ex.getMessage()); } } catch (Throwable ex) { throw new BeanDefinitionStoreException( "Failed to read candidate component class: " + resource, ex); } } } catch (IOException ex) { throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex); } return candidates; }首先去组装
classpath下匹配resourcePattern(默认"**/*.class")的路径,然后使用resourcePatternResolver去本地资源文件下加载所匹配的class文件成Resource。然后根据
isCandidateComponent方法判断是否能成为候选组件,就是根据excludeFilters、includeFilters以及Condition进行匹配。再根据
isCandidateComponent(与上同名方法不同参)方法判断,如果类是独立的类(top level class or static inner class)且非接口与非抽象类,如果是抽象类,那需要其内部有一个被@Lookup标注的方法。 -
给BeanDefinition设值
if (candidate instanceof AbstractBeanDefinition) { postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName); } if (candidate instanceof AnnotatedBeanDefinition) { AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate); }如果是AbstractBeanDefinition,则设置autowireCandidate属性;如果是AnnotatedBeanDefinition,设置Lazy、Primary、DependsOn、Role、Description信息。
-
代理
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry)这一步是挺重要的,主要用途是生成代理的BeanDefinition,从而后续实例化bean时,生成的是代理对象。
static BeanDefinitionHolder applyScopedProxyMode( ScopeMetadata metadata, BeanDefinitionHolder definition, BeanDefinitionRegistry registry) { ScopedProxyMode scopedProxyMode = metadata.getScopedProxyMode(); if (scopedProxyMode.equals(ScopedProxyMode.NO)) { return definition; } boolean proxyTargetClass = scopedProxyMode.equals(ScopedProxyMode.TARGET_CLASS); return ScopedProxyCreator.createScopedProxy(definition, registry, proxyTargetClass); }ScopedProxyMode有四个值:
- DEFAULT,使用ComponentScan的ScopedProxy值
- NO,不创建代理对象。
- INTERFACES,创建JDK动态代理对象。
- TARGET_CLASS,创建CGLIB代理对象。
public static BeanDefinitionHolder createScopedProxy(BeanDefinitionHolder definition, BeanDefinitionRegistry registry, boolean proxyTargetClass) { String originalBeanName = definition.getBeanName(); BeanDefinition targetDefinition = definition.getBeanDefinition(); String targetBeanName = getTargetBeanName(originalBeanName); // Create a scoped proxy definition for the original bean name, // "hiding" the target bean in an internal target definition. RootBeanDefinition proxyDefinition = new RootBeanDefinition(ScopedProxyFactoryBean.class); proxyDefinition.setDecoratedDefinition(new BeanDefinitionHolder(targetDefinition, targetBeanName)); proxyDefinition.setOriginatingBeanDefinition(targetDefinition); proxyDefinition.setSource(definition.getSource()); proxyDefinition.setRole(targetDefinition.getRole()); proxyDefinition.getPropertyValues().add("targetBeanName", targetBeanName); if (proxyTargetClass) { targetDefinition.setAttribute(AutoProxyUtils.PRESERVE_TARGET_CLASS_ATTRIBUTE, Boolean.TRUE); // ScopedProxyFactoryBean's "proxyTargetClass" default is TRUE, so we don't need to set it explicitly here. } else { proxyDefinition.getPropertyValues().add("proxyTargetClass", Boolean.FALSE); } // Copy autowire settings from original bean definition. proxyDefinition.setAutowireCandidate(targetDefinition.isAutowireCandidate()); proxyDefinition.setPrimary(targetDefinition.isPrimary()); if (targetDefinition instanceof AbstractBeanDefinition) { proxyDefinition.copyQualifiersFrom((AbstractBeanDefinition) targetDefinition); } // The target bean should be ignored in favor of the scoped proxy. targetDefinition.setAutowireCandidate(false); targetDefinition.setPrimary(false); // Register the target bean as separate bean in the factory. registry.registerBeanDefinition(targetBeanName, targetDefinition); // Return the scoped proxy definition as primary bean definition // (potentially an inner bean). return new BeanDefinitionHolder(proxyDefinition, originalBeanName, definition.getAliases()); }这一块的主要功能是创建一个代理的RootBeanDefinition,并使用原来bean的名称注册到IOC容器,而原原来的Bean,在名字面前加一个
scopedTarget.前缀注册到IOC容器。 -
registerBeanDefinition
public static void registerBeanDefinition( BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry) throws BeanDefinitionStoreException { // Register bean definition under primary name. String beanName = definitionHolder.getBeanName(); registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition()); // Register aliases for bean name, if any. String[] aliases = definitionHolder.getAliases(); if (aliases != null) { for (String alias : aliases) { registry.registerAlias(beanName, alias); } } }这里实际上就是把BeanDefinition放入到beanDefinitionMap,把aliases放入aliasMap中去。
7.3.2 parse
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
这一步是对扫描出来的BeanDefinition的判断,如果扫描出来的类是配置类,那么它依然有能力对bean进行扫描,所以继续递归解析。
7.4 处理Import
processImports(configClass, sourceClass, getImports(sourceClass), filter, true);
getImports可以获取到类上所有的@Import注解信息。
private void processImports(ConfigurationClass configClass, SourceClass currentSourceClass,
Collection<SourceClass> importCandidates, Predicate<String> exclusionFilter,
boolean checkForCircularImports) {
if (importCandidates.isEmpty()) {
return;
}
if (checkForCircularImports && isChainedImportOnStack(configClass)) {
this.problemReporter.error(new CircularImportProblem(configClass, this.importStack));
}
else {
this.importStack.push(configClass);
try {
for (SourceClass candidate : importCandidates) {
if (candidate.isAssignable(ImportSelector.class)) {
// Candidate class is an ImportSelector -> delegate to it to determine imports
Class<?> candidateClass = candidate.loadClass();
ImportSelector selector = ParserStrategyUtils.instantiateClass(candidateClass, ImportSelector.class,
this.environment, this.resourceLoader, this.registry);
Predicate<String> selectorFilter = selector.getExclusionFilter();
if (selectorFilter != null) {
exclusionFilter = exclusionFilter.or(selectorFilter);
}
if (selector instanceof DeferredImportSelector) {
this.deferredImportSelectorHandler.handle(configClass, (DeferredImportSelector) selector);
}
else {
String[] importClassNames = selector.selectImports(currentSourceClass.getMetadata());
Collection<SourceClass> importSourceClasses = asSourceClasses(importClassNames, exclusionFilter);
processImports(configClass, currentSourceClass, importSourceClasses, exclusionFilter, false);
}
}
else if (candidate.isAssignable(ImportBeanDefinitionRegistrar.class)) {
// Candidate class is an ImportBeanDefinitionRegistrar ->
// delegate to it to register additional bean definitions
Class<?> candidateClass = candidate.loadClass();
ImportBeanDefinitionRegistrar registrar =
ParserStrategyUtils.instantiateClass(candidateClass, ImportBeanDefinitionRegistrar.class,
this.environment, this.resourceLoader, this.registry);
configClass.addImportBeanDefinitionRegistrar(registrar, currentSourceClass.getMetadata());
}
else {
// Candidate class not an ImportSelector or ImportBeanDefinitionRegistrar ->
// process it as an @Configuration class
this.importStack.registerImport(
currentSourceClass.getMetadata(), candidate.getMetadata().getClassName());
processConfigurationClass(candidate.asConfigClass(configClass), exclusionFilter);
}
}
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to process import candidates for configuration class [" +
configClass.getMetadata().getClassName() + "]", ex);
}
finally {
this.importStack.pop();
}
}
}
这个方法虽然很长,但是总结下来就很简单。就是通过判断@Import的参数的类型来执行不同的逻辑。
-
ImportSelector
需要实现
ImportSelector接口,并重写selectImports方法,返回一个className数组。会递归注册。 -
ImportBeanDefinitionRegistrar
需要实现
ImportBeanDefinitionRegistrar接口,实现registerBeanDefinitions方法,此方法会将BeanDefinitionRegistry暴露给你,想怎样玩儿怎样玩儿。 -
以配置类的方式去引入BeanDefinition
执行常规扫描注册流程。
7.5 处理ImportResource
AnnotationAttributes importResource =
AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class);
if (importResource != null) {
String[] resources = importResource.getStringArray("locations");
Class<? extends BeanDefinitionReader> readerClass = importResource.getClass("reader");
for (String resource : resources) {
String resolvedResource = this.environment.resolveRequiredPlaceholders(resource);
configClass.addImportedResource(resolvedResource, readerClass);
}
}
它的作用是导入外部的xml IOC配置文件。
7.6 收集BeanMethod
Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(sourceClass);
for (MethodMetadata methodMetadata : beanMethods) {
configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));
}
这是在本类中将Bean Method添加到configClass中。
processInterfaces(configClass, sourceClass);
private void processInterfaces(ConfigurationClass configClass, SourceClass sourceClass) throws IOException {
for (SourceClass ifc : sourceClass.getInterfaces()) {
Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(ifc);
for (MethodMetadata methodMetadata : beanMethods) {
if (!methodMetadata.isAbstract()) {
// A default method or other concrete method on a Java 8+ interface...
configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));
}
}
processInterfaces(configClass, ifc);
}
}
这是将接口中的默认方法的Bean Method添加到configClass中。
如:
public interface People {
@Bean
default Map<String, Object> prop() {
Map<String, Object> prop = new HashMap<>();
prop.put("head", 1);
prop.put("hands", 2);
return prop;
}
}
7.7 循环父类
if (sourceClass.getMetadata().hasSuperClass()) {
String superclass = sourceClass.getMetadata().getSuperClassName();
if (superclass != null && !superclass.startsWith("java") &&
!this.knownSuperclasses.containsKey(superclass)) {
this.knownSuperclasses.put(superclass, configClass);
// Superclass found, return its annotation metadata and recurse
return sourceClass.getSuperClass();
}
}
如果当前sourceClass的父类不为java开头的,且父类之前未被执行过,那就返回父类。
回到解析流程:
SourceClass sourceClass = asSourceClass(configClass, filter);
do {
sourceClass = doProcessConfigurationClass(configClass, sourceClass, filter);
}
while (sourceClass != null);
sourceClass返回不为空,就会进行递归,而这里返回的是当前sourceClass的父类,所以是对父类进行递归解析,直到父类是以java开头的类。
8. 检验解析数据
public void validate() {
for (ConfigurationClass configClass : this.configurationClasses.keySet()) {
configClass.validate(this.problemReporter);
}
}
void validate(ProblemReporter problemReporter) {
// A configuration class may not be final (CGLIB limitation) unless it declares proxyBeanMethods=false
Map<String, Object> attributes = this.metadata.getAnnotationAttributes(Configuration.class.getName());
if (attributes != null && (Boolean) attributes.get("proxyBeanMethods")) {
if (this.metadata.isFinal()) {
problemReporter.error(new FinalConfigurationProblem());
}
for (BeanMethod beanMethod : this.beanMethods) {
beanMethod.validate(problemReporter);
}
}
}
如果一个配置的@Configuration注解的proxyBeanMethods属性值为true,但是这个类确是被final修饰的,那就会报错,如果这个配置类中的Bean Method不能被重写,也会报错。
9. 加载BeanDefinitions
这里就有小伙伴有疑问了,上面的parse流程不是已经有加载BeanDefinition到beanDefinitionMap中去了吗?为什么这里还要去加载一次?
我们先来回忆一下,在解析流程parse中,只是将ComponentScan扫描出来的BeanDefinition添加到IOC容器中的,而其他方式,如Bean Method、@Import引入的均为注册到容器中。所以这里就是对其他BeanDefinition的处理。
现在来对这个功能做一个说明:
Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());
configClasses.removeAll(alreadyParsed);
this.reader.loadBeanDefinitions(configClasses);
这里parser.getConfigurationClasses()是扫描或者import进来的类。
public void loadBeanDefinitions(Set<ConfigurationClass> configurationModel) {
TrackedConditionEvaluator trackedConditionEvaluator = new TrackedConditionEvaluator();
for (ConfigurationClass configClass : configurationModel) {
loadBeanDefinitionsForConfigurationClass(configClass, trackedConditionEvaluator);
}
}
首先创建一个TrackedConditionEvaluator,然后循环对ConfigurationClass进行处理。
TrackedConditionEvaluator见名知意,是一个可跟踪的条件计算器,它的核心代码为:
public boolean shouldSkip(ConfigurationClass configClass) {
Boolean skip = this.skipped.get(configClass);
if (skip == null) {
if (configClass.isImported()) {
boolean allSkipped = true;
for (ConfigurationClass importedBy : configClass.getImportedBy()) {
if (!shouldSkip(importedBy)) {
allSkipped = false;
break;
}
}
if (allSkipped) {
// The config classes that imported this one were all skipped, therefore we are skipped...
skip = true;
}
}
if (skip == null) {
skip = conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN);
}
this.skipped.put(configClass, skip);
}
return skip;
}
}
其主要逻辑为:首先判断所有引入它的类的的Condition条件是否成立,如果任一一个成立,那就说明当前类有能被注册的可能,那就再去对自身的Condition进行判断。
这是对单个configClass的处理方法,它的源代码为:
private void loadBeanDefinitionsForConfigurationClass(
ConfigurationClass configClass, TrackedConditionEvaluator trackedConditionEvaluator) {
if (trackedConditionEvaluator.shouldSkip(configClass)) {
String beanName = configClass.getBeanName();
if (StringUtils.hasLength(beanName) && this.registry.containsBeanDefinition(beanName)) {
this.registry.removeBeanDefinition(beanName);
}
this.importRegistry.removeImportingClass(configClass.getMetadata().getClassName());
return;
}
if (configClass.isImported()) {
registerBeanDefinitionForImportedConfigurationClass(configClass);
}
for (BeanMethod beanMethod : configClass.getBeanMethods()) {
loadBeanDefinitionsForBeanMethod(beanMethod);
}
loadBeanDefinitionsFromImportedResources(configClass.getImportedResources());
loadBeanDefinitionsFromRegistrars(configClass.getImportBeanDefinitionRegistrars());
}
9.1 条件判断
首先根据TrackedConditionEvaluator进行判断,如果其判断的结果为这个类不应该被注入IOC,那么清除其在registry(实际就是beanFactory)、importRegistry中已存在的数据。
9.2 处理Import
isImported方法是判断这个类是不是使用@Import引入的,该方法也挺简单:
public boolean isImported() {
return !this.importedBy.isEmpty();
}
那么importedBy是何时被赋值的呢?
在上述第7节解析流程中,一共有两处地方对其赋值。
-
在processImports时,如果Import进来的类不是ImportSelector,也不是ImportBeanDefinitionRegistrar,那就会将引入进来的类包装为一个ConfigurationClass类。
candidate.asConfigClass(configClass);public ConfigurationClass asConfigClass(ConfigurationClass importedBy) { if (this.source instanceof Class) { return new ConfigurationClass((Class<?>) this.source, importedBy); } return new ConfigurationClass((MetadataReader) this.source, importedBy); }在这里就为其内部importedBy属性赋了初始值。
-
在
processConfigurationClass方法中,会取configurationClasses中已经处理的该ConfigurationClass,并可能进行mergeImportedBy,就是合并其内部importedBy属性。
使用registerBeanDefinitionForImportedConfigurationClass方法注册Import及其
9.3 处理BeanMethod
使用loadBeanDefinitionsForBeanMethod方法对Bean Method来对于Bean Definition进行注册。
值得注意的是,在对Bean Method的处理中,需要注意在Bean Method方法上的@Scope注解,如果其proxyMode不为NO,那么需要创建一个并注册代理的BeanDefinition。
9.4 处理ImportedResources
根据@ImportedResource注解向容器中注册BeanDefinition。
9.5 处理ImportBeanDefinitionRegistrar
在使用@Import时,可以指定一个ImportBeanDefinitionRegistrar的实现类,通过重写其registerBeanDefinitions方法来使用registry来进行bean注册。
这里就是获取所有当前类的所有ImportBeanDefinitionRegistrar类,并循环执行其registerBeanDefinitions方法。
10 循环执行解析注册
if (registry.getBeanDefinitionCount() > candidateNames.length) {
String[] newCandidateNames = registry.getBeanDefinitionNames();
Set<String> oldCandidateNames = new HashSet<>(Arrays.asList(candidateNames));
Set<String> alreadyParsedClasses = new HashSet<>();
for (ConfigurationClass configurationClass : alreadyParsed) {
alreadyParsedClasses.add(configurationClass.getMetadata().getClassName());
}
for (String candidateName : newCandidateNames) {
if (!oldCandidateNames.contains(candidateName)) {
BeanDefinition bd = registry.getBeanDefinition(candidateName);
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bd, this.metadataReaderFactory) &&
!alreadyParsedClasses.contains(bd.getBeanClassName())) {
candidates.add(new BeanDefinitionHolder(bd, candidateName));
}
}
}
candidateNames = newCandidateNames;
}
这里从源码看的逻辑就是:
如果此时在registry中的beanDefinition既不属于此次BeanDefinitionRegistry后置处理传进来的类,又不属于在此次处理中被解析出来的类,但是这个又是个配置类,那么就将其添加到candidates中,如果当前逻辑执行完成之后,candidates不为空,那么循环执行解析的和注册这一步骤。
11 功能末尾
这里两步,一步是将ImportRegistry注册为一个单例bean,第二步是清除metadataReaderFactory的缓存。
12 小结
根据启动类的@ComponentScan指定的包扫描路径进行扫描,并将结果封装为BeanDefinition注册到beanDefinitionMap中,再对@Import的类和BeanMethod进行注册。总体逻辑就是这样简单,但是其中有很多细节的处理,比如对Scope的proxyMode的处理、对@Import的三种方式的处理,对父类扫描的处理等等。