LSTM模型
LSTM简介
长短期记忆人工神经网络(Long-Short Term Memory, LSTM)是一种时间递归神经网络(RNN),论文首次发表于1997年。由于独特的设计结构,LSTM适合于处理和预测时间序列中间隔和延迟非常长的重要事件。
LSTM(Long short-term memory)是一种RNN模型是对simple rnn的一种改进,可以避免梯度消失的问题,可以有更长的记忆。LSTM是一种循环神经网络!
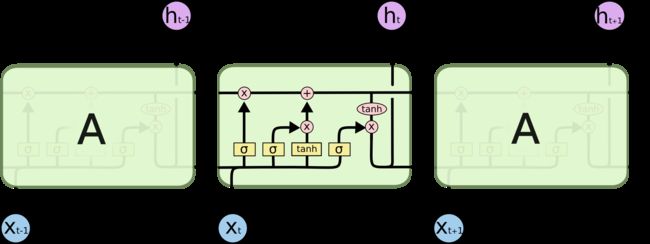
每当读取一个新的输入x,就会更新状态h。
LSTM的核心思想
理解LSTM的关键就是下面的矩形方框,被称为memory block(记忆块),主要包含了三个门(forget gate、input gate、output gate)与一个记忆单元(cell)。方框内上方的那条水平线,被称为cell state(单元状态),它就像一个传送带,可以控制信息传递给下一时刻。

LSTM就是通过传输带来防止梯度消失。
遗忘门(forget gate)
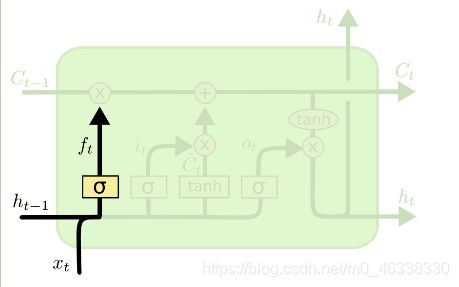
遗忘门由Sigmoid函数和Elementwise multiplication两个部分组成,输入sigmoid是一个向量a,Sigmoid作用在向量a的每一个元素上,把每个元素都加到0~1之间。
例如:向量a :[1,3,0,-2] 通过Sigmoid函数—>输出同维向量
f:[0.73,0.95,0.5,0.12],然后通过c。(multiplication)f算出输出 output,遗忘门有选择让传送带c通过。

输入门(input gate)

输入门(input gate)通过sigmoid来决定哪些值用来更新,tanh层用来生成新的候选值相加,得到了候选值。
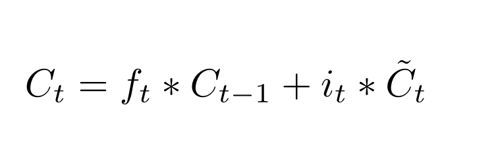
输出门(output gate)
首先是通过sigmoid层来得到一个初始输出,然后使用tanh将
值缩放到-1到1间,再与sigmoid得到的输出逐对相乘,从而得到模型的输出。
通过tensorflow跑一段文字预测
import numpy
from keras.models import Sequential
from keras.layers import Dense, Dropout, LSTM
from keras.callbacks import ModelCheckpoint
from keras.utils import np_utils
# 读取txt文件
filename = 'comments.txt'
with open(filename, 'r', encoding='utf-8') as f:
raw_text = f.read().lower()
# 创建文字和对应数字字典
chars = sorted(list(set(raw_text)))
char_to_int = dict((c, i) for i, c in enumerate(chars))
int_to_char = dict((i, c) for i, c in enumerate(chars))
# 对加载数据做总结
n_chars = len(raw_text)
n_vocab = len(chars)
print("总的文字数:", n_chars)
print("总的文字类别:", n_vocab)
# 生成数据集,转化为输入向量和输出向量
seq_length = 10
dataX = []
dataY = []
for i in range(0, n_chars - seq_length, 1):
seq_in = raw_text[i: i + seq_length] # 输入前10个字
seq_out = raw_text[i + seq_length] # 输出后 1个字
dataX.append([char_to_int[char] for char in seq_in]) # 将字转化成对应的序号
dataY.append(char_to_int[seq_out])
n_patterns = len(dataX) # 数据集的大小
print("Total Patterns: ", n_patterns)
# 将X重新转化为[samples, time_steps, features]形状
X = numpy.reshape(dataX, (n_patterns, seq_length, 1))
X = X / n_vocab
y = np_utils.to_categorical(dataY)
# 定义LSTM
model = Sequential()
model.add(LSTM(256, input_shape=(X.shape[1], X.shape[2]))) # 输入维度(10, 1)
model.add(Dropout(0.2))
model.add(Dense(y.shape[1], activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
filepath = "./LSTM/weights-improvement.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=1, save_best_only=True, mode='min')
callbacks_list = [checkpoint]
# 模型训练
epochs = 1000
model.fit(X, y, epochs=epochs, batch_size=128, callbacks=callbacks_list)
## 模型预测 ====
input = '杭州西湖天下闻名,西'
pattern = [char_to_int[value] for value in input]
print("输入:")
print(''.join([int_to_char[value] for value in pattern]))
print("输出:")
for i in range(1000):
x = numpy.reshape(pattern, (1, len(pattern), 1))
x = x / float(n_vocab)
prediction = model.predict(x, verbose=0)
index = numpy.argmax(prediction)
result = int_to_char[index]
print(result, end='')
seq_in = [int_to_char[value] for value in pattern]
pattern.append(index)
pattern = pattern[1: len(pattern)] # 这里的pattern永远都是10个字
print("\n生成完毕。")用pytorch有点麻烦,相对tensorflow较为轻松!