基于时间窗口统计数据
文章目录
- 如何对请求进行限制
- 对于限流的三种常见算法
-
- 令牌桶算法
- 漏桶算法
- 时间窗口(滑动窗口)
- 实现
-
- 窗口对象
- 操作对象
- 总结
如何对请求进行限制
这个问题其实分为两步
第一步,需要明确进行限制的规则数据,比如说接口的qps,线程数,报错数,传入参数等
第二步,根据上面的统计数据,实现自己的规则
这篇文章主要讲第一步中的一种统计数据结构,基于时间窗口(或者滑动窗口)来统计信息
对于限流的三种常见算法
常见的有三种,令牌桶,漏桶,时间窗口
前两中算法由于不是本章的重点,就稍微讲述下是什么。
令牌桶算法
令牌桶的思路呢,是按一定速率向桶中投入令牌,只有获取到令牌的请求才允许通过
如下图
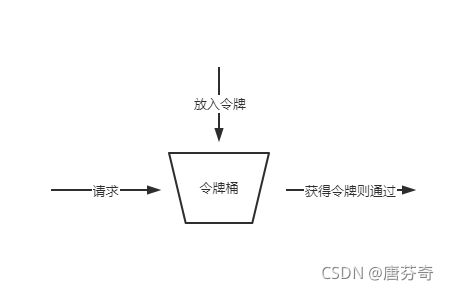
该算法允许突发流量的出现,因为是否通过取决于桶中是否堆积有多余的令牌嘛。
漏桶算法
漏桶的思路呢,是将请求放入漏桶中,然后漏桶在匀速取出。
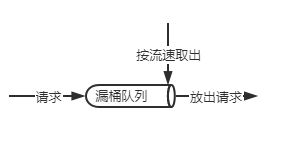
该算法不处理突发流量,只是匀速从队列中方形请求,不适用与突发型请求。
时间窗口(滑动窗口)
原本呢,滑动窗口是TCP协议中用于控制流量速率的一种算法,在处理字符串与数组上也有使用滑动窗口算法来缩小问题的规模。
但这里的窗口其实与上述两种使用场景还是有一丢丢区别,什么意思呢?就是不懂上面两个也没有任何问题 ^ O ^。
这里我们来看下窗口的定义 :

其实就是根据一定的间隔时间,将时间轴切分成一块一块的独立小块,然后基于这些小块进行自己的统计。
实现
看到上面的描述是否觉得easy? 本来嘛,麻烦的我也写不出来呐,不过还是有一些小细节噢。
首先我们要定义一个窗口对象,一个基于窗口进行操作的对象。
窗口对象
首先我们看下窗口对象,应该有些什么
/**
* 窗口对象
* @Author:TangFenQi
* @Date:2021/11/10 10:12
**/
public class WindowBucket {
private long windowStartInMs;//窗口的起始时间
private long intervalInMs;//窗口的间隙时间
private LongAdder counter;//计数器
}
如上图所示,基本属性,起始时间,间隙时间,以及一个计数器。
这里我们选用的是JUC包里面的LongAdder,而不是Atomic里面的数字类型。
原因是在于这种流量计数统计都是高写入的,而我们知道JUC是基于CAS原理来进行修改值,那么就必定会导致大量的线程进行自旋(热点冲突嘛,大家都要改,你改我就不能改),而LongAdder在Atomic基础上进行了针对这种情况的改造,将热点分散到一个数组。 这里有同学就疑惑了?我就该一个值,你怎么把这个分散到数组中?
我们结合图来看下,当出现大批写入时
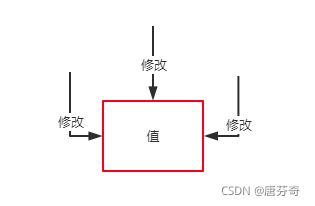
这时,只会有一个线程获取修改值的权利,其他两个将会到数组中进行修改。
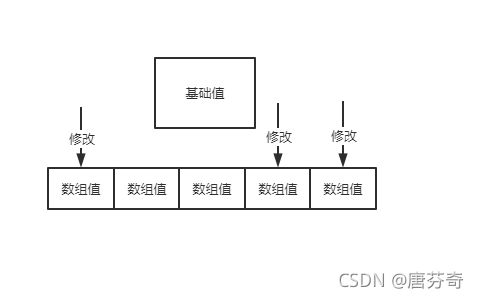
这样,其他两个线程就不必自旋等待值修改权利,避免了冲突。
同样获取值的方式就变更为了数组之和加上基础值,并发自然就上去咯。
窗口还应该有的方法
/**
* 计数器进行累加
* @param count 本次增加的次数
*/
public void add(long count)
/**
* 获取当前的次数
* @return 当前的次数
*/
public long get()
/**
* 重置窗口对象
* @param startTime 窗口新的开始时间
* @param intervalTime 窗口的间隔时间
*/
public void reset(long startTime,long intervalTime)
操作对象
窗口对象设计完毕之后,我们就可以开始设计操作对象啦。
public class WindowWorker {
private AtomicReferenceArray<WindowBucket> buckets;//窗口容器
private long intervalInMs;//间隔时间
private long windowsCount;//窗口数量
private long windowsInterval;//窗口间隔时间
private ReentrantLock resetLock = new ReentrantLock();//重置时使用
}
这里使用线程安全的集合使用了AtomicReferenceArray,而没使用CopyOnWriteArrayList也是因为这种场景是高写入,不适用CopyOnWriteArrayList。
对于操作对象主要需要两种操作方式,第一对于当前窗口进行操作,第二获取窗口的信息
我们先来看下第一个操作,对于当前窗口进行操作
public void count() {
count(1L, System.currentTimeMillis());
}
public void count(long acquireCount, long currentTime) {
if (acquireCount < 1) throw new RuntimeException(String.format("invalid acquireCount[%s]", acquireCount));
WindowBucket bucket = getBucket(currentTime);
bucket.add(acquireCount);
}
主要看下如何获取到窗口,也就是getBucket()方法。
private WindowBucket getBucket(long currentTime) {
//获取currentTime标识的时间所对应的buckets索引
int bucketId = getIndexId(currentTime);
//对当前时间进行修剪,得到窗口开始时间
long startTime = trimTime(currentTime);
/**
* 判断bucket情况,这里分为两种情况
* 1.根据索引,拿到的bucket为null,代表这个未被使用过,可以直接使用
* 2.根据索引,拿到的bucket不为null,代表已经被使用,也分为两种情况
* 2.1 bucket的windowStartInMs窗口开始时间,与currentTime对齐时间一致,代表是当前时间的窗口,直接使用
* 2.2 与currentTime对齐时间不一致
* 2.2.1 如果是过期时间,是之前,那么进行重置
* 2.2.2 如果是未来时间,那么抛出异常
*/
//如果更新失败,进行自旋
while (true) {
WindowBucket bucket = buckets.get(bucketId);
if (bucket == null) {
WindowBucket newBucket = new WindowBucket(startTime, windowsInterval);
if (buckets.compareAndSet(bucketId, null, newBucket)) {
return newBucket;
}
} else {
if (bucket.windowStart() == startTime) {
return bucket;
} else if (bucket.windowStart() < startTime) {
try {
resetLock.tryLock();
bucket.reset(startTime, windowsInterval);
return bucket;
} catch (Exception ex) {
//让出当前cpu分配的时间分片,等待下次cpu唤醒(可能下次还是该线程执行,只是标识为可让出)
Thread.yield();
} finally {
resetLock.unlock();
}
} else {
throw new RuntimeException(String.format("bucket window start[%s] beyond current time[%s]", bucket.windowStart(), currentTime));
}
}
}
}
备注都有啦,写的很详细,这里在补充一下。
我们知道时间是无限的,而数组空间有限。以有限逐无限,内存溢出也!
所有就需要将数组连成环,重复时间,不停覆盖上一个周期的值,也就有了上面代码里面的几种情况。
后面还有get获取方法,比较简单,就不写出来了。
总结
整体思路不复杂,但在落地的时候一定要想清楚,使用的场景,选用的方式是否适用于该场景。
其中窗口中的统计器,可以换成更复杂的结构,统计更复杂的信息,活学活用嘛,不要死脑筋。
上述代码的实现地址:github。
代码无涯,与君共勉。
喜欢的同学,不介意的话给我点个star吧 (* ̄︶ ̄)