【3】图书在线平台系统(SSH框架+Bootstrap/Angular+...)实现---【Python爬取页面图书数据源】
由于顺序问题,这里先发布python爬去图书网站里的内容以及图书封面照片
这里我从 《python网络书籍》 这本书里入门到的
项目具体源码可以点击打开链接
from urllib.request import urlopen
from bs4 import BeautifulSoup,Comment
import urllib
import re
import datetime
import random
import pymysql
import os
conn = pymysql.connect(host='127.0.0.1',user='',passwd='',db='mysql',charset='utf8')
cur = conn.cursor()
cur.execute("USE pythondb")
#存储数据
def store(title,author,belongg,leibie,sum,PicUrl):
cur.execute("INSERT INTO PythonBook (title,author,belongg,leibie,summaryy,PicUrl) VALUES (\"%s\",\"%s\",\"%s\",\"%s\",\"%s\",\"%s\")", (title,author,belongg,leibie,sum,PicUrl))
cur.connection.commit()
#打开文本文件里的网址,选择性读取
with open('testUrl.txt') as file:
for url in file:
# 打开每一页
html = urlopen(url)
bsObj = BeautifulSoup(html, "html.parser")
#选出所有的media的div
bsss = bsObj.find_all('div',class_='media')
for tag in bsss:
#书名
title = tag.find('h4',class_='media-heading').find('a').text
#抓取图片,并保存至文件系统---同时补全不同的路径,可放入数据库
Pic = tag.find('img',class_='media-object')['src']
#清洗图片来源路径
if Pic.startswith('http') :
pic = Pic
else:
pic = "http://www.dqiu.net"+Pic
#所有p标签的信息
infomation = tag.find('div',class_='media-body').find_all('p')
#只要前四个,因为有一个评论,没用的
#作者**-数据清洗一下
author = infomation[0].text
author2 = author.replace('作者','')
#清洗出版信息
belong = infomation[1].text
belong2 = belong.replace('出版信息','')
#清洗类别
leibie = infomation[3].text
leibie2 = leibie.replace('类别','')
#清洗摘要
######清洗数据的问题
infoo = tag.find('div',class_='media-body').findAll(text=lambda text:isinstance(text, Comment))
infoo2 = str(infoo)
infoo3 = infoo2.replace("摘要
\\r\\n","").replace("","").replace("
\\r\\n","").replace("['","").replace("]","").replace("'","")
#保存图片至本地文件系统,并给出路径,数据库保存用
urllib.request.urlretrieve(pic,'F:\Python项目\BookShopPic\%s.jpg' %title)
strr = 'F:\Python项目\BookShopPic\%s.jpg' %title
#转存数据库的方法
store(title,author2,belong2,leibie2,infoo3,strr)
print("---读完 一 页---")
print("---结束---")
我们需要去爬取的网站进行分析
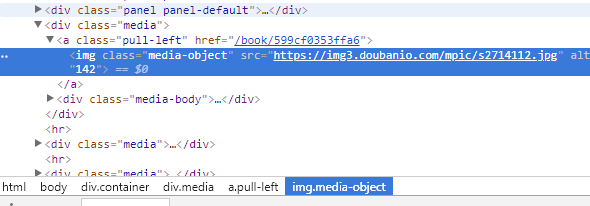

我们可以看到,页面上的书本封面图,是有直接放在大主页的;
以及书籍各种相关内容,都是以段落的形式存放着,这就对于我们爬取方便了蛮多的
title = tag.find('h4',class_='media-heading').find('a').text我们可以用Python里的BeautifulSoup框架进行爬取,详情可读代码
需要注意的地方是:
1、爬虫的程序是适用于所有网站,需要为每一个网站去“量身定做”
2、爬取的数据格式不一定是我们想要的格式,所以我们需要对数据进行一次“改造”再存入数据库
3、分析每一页时,要记得补全的网址路径
其他的想起来再说吧~第一个爬虫程序,写的不好,希望可以帮助到有需要或者正在学习的人。