乘风破浪会有时
android
1.熟悉Java语言、了解C语言,具有一定的代码阅读与编写能力;
2.熟练掌握测试基础,能不断优化并规范测试流程,编写测试脚本来提高整体测试效率;
测试基础:
优化并规范:
1、写完测试计划后,根据测试计划中的测试点来编写测试用例,之后再去执行。
2、测试计划中,需要画一个表格,分配时间线,严格按照时间线来执行任务,整体把控需求准时上线发布
3、开发改完bug之后,需要备注修改代码的影响面,以及修改的内容测试点。
开发提测之前,需要跑冒烟用例,让开发充分自测,提高测试效率
4、比较大的需求,可以写一下测试报告:迭代bug类型,熟练,用例执行通过率,需求注意事项。
5、测试计划评审和需求评审合并到一起评审,开线下会议,讨论一下遗漏和注意点。
6、测试发现bug过程中,先整体跑完一遍用例,完成一轮测试,开发改完之后,执行二轮测试。(更适用于app测试)
测试完成之后,比较大的任务需要做一下交叉测试
编写测试脚本:

3.熟悉接口测试和接口前后端概念,了解计算机网络的基本知识,能熟练使用Jmeter工具做断言,参数化,业务闭环;
怎么判断是前端bug还是后端的bug
1.举个例子:前端页面上写的数据,存到request请求体里面,如果存错了,就是前端bug
2.数据如果没有成功入库,就是后端开发的bug
3.Response里面的数据和数据库里面的数据不一致也是后端开发的bug
4.从response里面取数据呈现到页面上,如果有误,就是前端bug
还可以从响应码:
以2开头:
200 – 请求成功,服务器也返回了响应信息
以3开头:请求重定向了,请求的位置转移了
301 – 永久性定向,请求的资源被分配了新的URL地址,而且以后请求的时候都是用新的URL地址
302 – 临时性定向,请求的资源被分配了新的URL地址,这次访问是这个新的URL地址,下次访问可能就是另外的URL地址
303 –
临时性定向,请求的资源被分配了新的URL地址,请求的时候使用GET方法定向获取资源(与302的区别就是303要求客户端使用GET请求方式)
以4开头:
401 – 表示访问的页面没有授权
403 – 表示没有权限访问这个页面
404 – 表示没有这个页面,服务器上无法找到请求的资源(也可以是服务器拒绝请求但是不想给拒绝原因)
以5开头:
500 – 表示服务器内部异常
503 – 表示服务器正处于超负载或者正在进行停机维护,无法处理请求
504 – 表示服务器请求超时,没有返回结果
jmeter接口测试用到的组件
1、测试计划:Jmeter的起点和容器
2、线程组:代表一定的虚拟用户
3、取样器:发送请求的最小单元
4、逻辑控制器:控制组件的执行顺序
5、前置处理器:在请求之前的操作
6、后置处理器:在请求之后的操作
7、断言:判断请求是否成功
8、定时器:是否延迟或者间隔发送请求
9、配置元件:请求期的配置信息
10、监听器:负责收集测试结果
执行顺序
测试计划→线程组→配置元件→前置处理器→定时器→取样器→后置处理器→断言→监听器
常用控制器
jmeter提供了17种逻辑控制器,它们各个功能都不尽相同,大概可以分为2种使用类型:
1.控制测试计划执行过程中节点的逻辑执行顺序,如:Loop Controller(循环控制器)、If Controller(如果if控制器)等;
2.对测试计划中的脚本进行分组,方便JMeter统计执行结果以及进行脚本的运行时控制等,如:Throughput Controller(吞吐量控制器)、Transaction Controller(事务控制器)等
1、循环控制器:
可以设置该控制器内的sampler执行的次数,循环次数与线程的循环次数各自独立
2、if控制器:
根据判断条件决定是否执行该控制器内的请求,如果是字符串比较条件,参数和字符串都需要加引 号 条件格式: j e x l 3 ( 条件表达式 ) 如: { jexl3(条件表达式)} 如: jexl3(条件表达式)如:{ jexl3(${num} > 10)}、 KaTeX parse error: Expected '}', got 'EOF' at end of input: { jexl3(“{num}” == “10”)}
3、仅一次控制器:
该控制器内的请求只执行一次,无论线程循环多少次
4、foreach控制器:
可以遍历某个参数数组,循环获取数组中的参数。 注意:空格
5、事务控制器:
一般不勾选Generate parent sample,查看结果树以及聚合报告。 Include duration of timer and pre-post processors in generated sample:是否包括定时器、预处理和后期 处理延迟的时间
业务闭环案例
比如用Jmeter自带的逻辑控制器,将登录接口放在仅一次控制器里,使用正则表达式或Json提取器获取到Token值后,后面的所有业务接口的请求头都带上这个Token值,然后实现后台管理系统里的增、查、改、删的业务闭环场景,因为自动化场景经常被运行,所以一定要做成业务闭环,不然只做新增的话,会堆积大量的测试数据,给服务器造成没必要的压力。
然后我做新增操作一般会应用上循环控制器,同时新增多条数据,查询接口查询出一个列表,然后在做改、删除操作等循环时,还需要用上计数器、定时器(模拟思考时间)等来辅助。
设计好脚本,在本地调通之后,我会把脚本上传到服务器上,然后使用Jenkins工具设置每天定时执行,如有问题就会给我发邮件,这样子就能及时发现问题,也省下了很多的手工回归测试的时间。
Jmeter:基本用法
“测试计划”右键 —> 添加 —> 线程(用户) —> 线程组
“线程组”右键 —> 添加 —> 取样器 —> HTTP请求(以HTTP请求为例)
线程组相当于一个业务(多个接口、几个接口就相当于几个HTTP请求) HTTP请求相当于一个接口
HTTP请求标签中需要 协议 IP/域名 端口号 方法(get、post)
“线程组”右键 —> 添加 —> 监听器 —> 察看结果树
选择接口(HTTP请求)右键–添加–断言–响应断言
线程组 右键 ->配置元件—》HTTP请求默认值(别填写上协议、服务器地址、编码、端口号,后续的请求就不用)
参数化的两种方式:
CSV:线程组右键–添加–配置元件–CSV Data Set Config
通过计数器做参数化
1、添加计数器 :线程组右键–配置元件–计数器
业务闭环、使用Jmeter中的控制器进行、控制器能实现判断、循环的功能。从实现业务闭环
python+request+pytest ?
因为pytest难以维护,接口经常迭代修改,如果用pytest需要花费大量时间去维护,维护成本高。我自己学过,我会用这个,但是公司规范用jmeter。
4.熟练掌握自动化测试:熟悉Selenium等自动化框架,能够独立完成自动化测试任务,编写元素定位,断言,封装工具类以及数据驱动等脚本,配合Jekins实现CI
数据驱动
使用数据驱动的模式,可以根据业务分解测试数据,只需定义变量,使用外部或者自定义的数据使其参数化,从而避免了使用之前测试脚本中固定的数据。可以将测试脚本与测试数据分离,使得测试脚本在不同数据集合下高度复用。不仅可以增加复杂条件场景的测试覆盖,还可以极大减少测试脚本的编写与维护工作。
POM
POM模式封装思路
(1)POM模式将页面分成三层
表现层
页面中可见的元素,都属于表现层。(元素定位器的编写)
操作层
对页面可见元素的操作。点击、输入、拖拽等。
业务层
在页面中对若干元素操作后所实现的功能。(就是测试用例)
(2)POM模式的核心要素(重点)
在POM模式中将公共方法统一封装成到一个BasePage 类中,换句话说该基类对Selenium的常用操作做二次封装。
每个页面对应一个page类,page类都需要继承 BasePage,通过 driver 来管理本page类中的元素,并将page类中的操作封装成一个个的方法。换句话说,就是page类中封装页面表现层和操作层。
TestCase继承 unittest.Testcase类,并且依赖 page 类,从而实现相应的测试步骤。
POM案例(原文链接)
添加商品到购物车的测试
---普通模式
输入url-->点击登录-->输入账号-->输入密码
-->点击登录按钮-->搜索商品-->选择商品-->
选择商品属性-->点击加入购物车
---PO模式
进入登录页,执行登录操作
进入商品详情页,执行添加商品到购物车操作
进入购物车页面,执行校验添加是否成功操作
项目结构
基类(base_page):封装各类行为操作,便于测试页面对象类进行调用,是整个PO模式体系的底层实现
页面对象类(obj_page):提取系统中的关键页面,封装成页面对象;主要页面的元素封装为页面对象类的属性,将页面的操作行为封装为页面对象类的方法
测试数据类(case_data):管理测试数据
测试用例类(test_cases):组装各页面对象类的行为,形成完成的业务流程进行测试

4.2 工程代码
下面以ecshop项目为例演绎整体的框架设计思路
a.基类的包下创建一个basepage.py文件,里面封装底层的基础操作及公共方法,详细代码如下:
from selenium import webdriver
from time import sleep
class BasePage:
#初始化
def __init__(self,brow_type):
try:
driver = getattr(webdriver, brow_type)()
except:
driver = getattr(webdriver, 'Chrome')()
driver.maximize_window()
self.driver = driver
#封装get方法
def get(self,url):
self.driver.get(url)
#封装定位页面元素的方法
def locator(self,locator):
return self.driver.find_element(*locator)
#封装input方法
def input(self,locator,input_value):
self.locator(locator).send_keys(input_value)
#封装close方法
def close(self):
self.driver.close()
#封装quit方法
def quit(self):
self.driver.quit()
#封装click方法
def click(self,locator):
self.locator(locator).click()
#封装强制等待方法
def sleep(self,sec):
sleep(sec)
b.页面对象类的包下为每个页面对象创建一个页面对象的.py文件,这里我们举例创建一个login_page.py文件,详细代码如下:
from base_page.basepage import BasePage
class LoginPage(BasePage):
'''
页面对象类继承于基类
页面元素类对象
1.页面url:封装为页面对象类的属性
2.页面元素:封装为页面对象类的属性
3.页面功能:封装页面对象类的方法
'''
#1.页面url
default_url = r'http://192.168.53.213/ecshop'
login_url = r'/user.php'
url = default_url + login_url
#2.页面元素
username = ('name','username')
password = ('name','password')
click_locator = ('name','submit')
#3.页面功能
def login(self,user,pwd):
self.get(self.url)
self.input(self.username,user)
self.input(self.password,pwd)
self.click(self.click_locator)
c.在测试数据类的包下面使用yaml格式数据管理测试用例数据,数据具体内容如下:
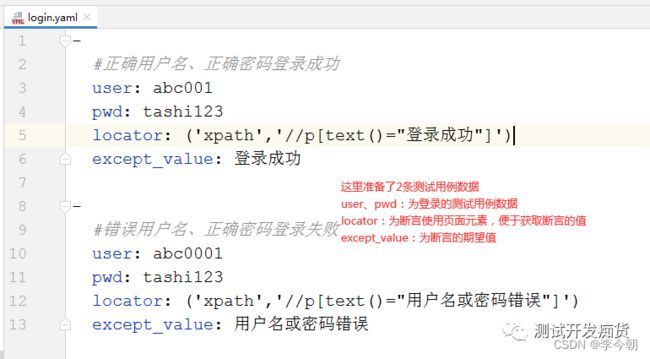
d.测试用例类的包下创建test_开头的测试用例.py文件,这里我们举例创建一个test_login.py文件,详细代码如下:
**import unittest
from ddt import ddt,file_data
from obj_page.login_page import LoginPage
@ddt
class TestLogin(unittest.TestCase):
#前置处理:创建登录页面对象
def setUp(self) -> None:
self.loginpage = LoginPage('Chrome')
#后置处理:退出浏览器
def tearDown(self) -> None:
self.loginpage.quit()
#测试登录,结合ddt+yaml进行数据驱动处理
@file_data('../case_data/login.yaml')
def test_login(self,user,pwd,locator,except_value):
self.loginpage.login(user,pwd)#登录
self.assertEqual(self.loginpage.locator(eval(locator)).text,except_value)#断言
if __name__ == '__main__':
unittest.main()
4.3 执行测试用例查看结果
封装:Common目录 :
登录,登出,元素定位(python描述符),颜色识别,日期转换,文件上传;滑动函数的封装。
我自己的理解:
强调POM模式
1.创建项目目录文件,一般有log(日志),data(存放参数化数据),base(存放所有Page页面公共方法),page(将页面封装为对象),script(存放测试脚本)等
2.base实现(common公共函数),分析要实现页面公共方法,如查找元素、输入方法、点击方法、获取文本值方法等
3.page实现(元素定位页面),首先集成base中的类,然后整理相关的元素信息,如username = (By.CSS_SELECTOR, “#username”),自动化测试当前页面要操作哪些元素,就封装哪些方法,然后可以根据业务去组合这些方法
4.script实现(测试用例脚本),初始化对象(实例webdriver、窗口最大化等等),调用page中的业务执行测试,调用之前封装的函数如获取文本值做断言
5.完成自动化后,使用git将代码合并到上面,再通过jenkins持续集成
八大定位
driver.find_element(by=“id”, value=“kw”).send_keys(“手机”)
driver.find_element(by=“name”, value=“wd”).send_keys(“手机”)
driver.find_element(by=“class name”, value=“s_ipt”).send_keys(“手机”)
find_element_by_tag_name()
driver.find_element(by=“link text”, value=“hao123”).click()#它专门用来定位超链接文本(文本值/)
partial_link_text定位
说明:partial_link_text定位是link_text定位的补充,partial_link_text为模糊匹配,link_text是全部匹配。
driver.find_element(by=“partial link text”,value=“hao”).click()
5.熟悉压力性能测试,对系统接口,数据库等做压力性能测试,并且输出测试报告和知识传承文档;
配置测试:改变软硬件配置(架构配置、参数配置),观测不同配置条件下的性能状态
基准测试:在一定的软硬件、网络条件下,模拟单用户操作系统,检测系统各项性能指标。为后面深入的性能测试做一个数据对比。
并发测试:测试同一模块、同一应用在高并发的情况下,接口工作是否正常。目的是主要检查应用或者接口在多用户情况下,是否存在缺陷(比如死锁等)
容量测试:在一定的软硬件、网络条件下,改变数据库的容量,模拟多用户,监测各项性能指标的过程。寻找数据容量的极限值
稳定性测试:主要强调长时间、正常负载情况下,观测系统各项指标的稳定性,不会出现致命的问题。7*24小时。8小时、24小时、48小时。目的是检测系统长时间运行,系统的稳定性、是否有异常表现(宕机、出现致命问题等)
性能测试的指标
响应时间:用户发出请求到服务器处理完成请求返回给客户端的这段时间
吞吐量:衡量系统的业务处理能力。TPS:每秒事务数。QPS:每秒请求数
资源利用率:cpu、内存、网络、磁盘读写io。一般资源的利用率不高于70%-80%,如果某项高于这个值,则可能是性能瓶颈
错误率:系统在负载情况下,失败请求的概率。错误率=(失败请求数/总请求数)*100。和功能测试的错误相区别,在性能测试中,所谓的错误一般是指由系统超时引起的错误,而不是指功能错误。不同的系统错误容错率不同。普通的业务系统,错误率不超过万分之一就可以了,有的大型系统,亿分之一。
性能测试工具:
6.了解单元测试:使用Junit,Powermock,Pytest单元测试框架,能够对后端业务逻辑做调试,优化项目结构和代码逻辑;
Junit
不用 Junit ,只能把测试的代码写到java类的 main()方法中,通过运行结果来判断测试结果是否正确。如果有很多方法,那么测试代码就会变得很混乱。
@Test: 测试方法
a)(expected=XXException.class)如果程序的异常和XXException.class一样,则测试通过
b)(timeout=100)如果程序的执行能在100毫秒之内完成,则测试通过
@Ignore: 被忽略的测试方法:加上之后,暂时不运行此段代码
@Before: 每一个测试方法之前运行
@After: 每一个测试方法之后运行
@BeforeClass: 方法必须必须要是静态方法(static 声明),所有测试开始之前运行,注意区分before,是所有测试方法
@AfterClass: 方法必须要是静态方法(static 声明),所有测试结束之后运行,注意区分 @After
参数化就是尽可能的通过一个用例,多组参数来模拟用户的行为
在使用参数化注解之前需要先用@ParameterizedTest声明该方法为参数化方法,然后再通过注解提供数据来源。
多参数:
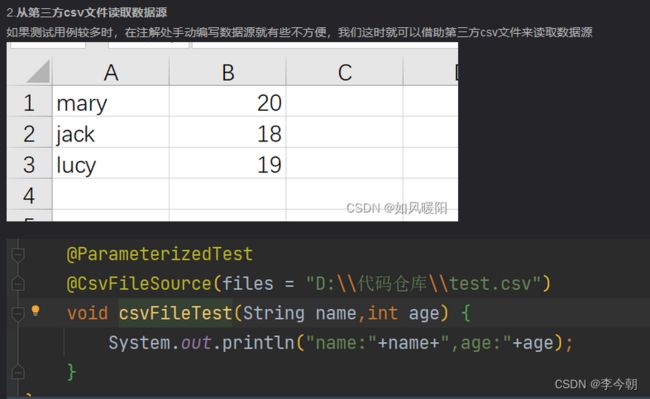
1.从注解中手动编写数据源
@CsvSource({“数据组合1”,“数据组合2”…}),每个双引号是一组参数(测试用例)
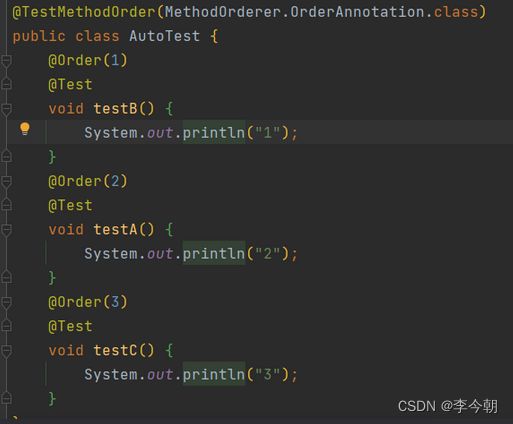
如果在实际测试中,我们需要完成连贯的多个步骤的测试,是需要规定测试用例执行的顺序的,可以通过@order注解来实现排序:
先使用注解说明当前类下所有的用例需要使用@Order注解来进行排序(注意:该注解必须要用在类上)
然后通过@Order来指定用例的具体顺序
5.测试套件
当我们一个类中有多个测试用例时,我们不可能挨个去运行,那样将会很耗费时间,这时我们就需要测试套件来指定类或者指定包名来运行类下或者包下的所有测试用例。
如果要使用测试套件,首先我们需要先创建一个类,通过@Suite注解标识该类为测试套件类(而不是测试类)
PowerMock
PowerMock是一个Java模拟框架,用于解决测试问题。
PowerMock 由Mockito和EasyMock两部分API构成,它必须要依赖测试框架。
当前PowerMock支持Junit和TestNG.两种测试框架。
Mock测试
Mock 测试就是在测试过程中,对于某些不容易构造(如 HttpServletRequest 必须在Servlet 容器中才能构造出来)或者不容易获取比较复杂的对象(如 JDBC 中的ResultSet 对象),用一个虚拟的对象(Mock 对象)来创建以便测试的测试方法。
好处-- 模拟数据
在使用Junit进行单元测试时,不想让测试数据进入数据库,可以使用PowerMock,拦截数据库操作,并模拟返回参数。
好处–减少依赖
当需要测试A类的时候,如果没有Mock,则需要把整个依赖树都构建出来,而使用Mock的话就可以将结构分解开
Mock框架使用流程
创建 外部依赖 的Mock 对象, 然后将Mock 对象注入到 测试类 中;
执行 测试代码;
校验 测试代码 是否执行正确。
when().thenReturn()
when().thenThrow()
when().thenCallRealMethod()
when(file.exists()).thenThrow(Exception.class);
whenNew(File.class).withArguments(“bbb”).thenReturn(file);
当使用PowerMockito.whenNew方法时,必须加注解@PrepareForTest和@RunWith。注解@PrepareForTest里写的类是需要mock的new对象代码所在的类。
当需要mock final方法的时候,必须加注解@PrepareForTest和@RunWith。注解@PrepareForTest里写的类是final方法所在的类。
当需要mock静态方法的时候,必须加注解@PrepareForTest和@RunWith。注解@PrepareForTest里写的类是静态方法所在的类。
当需要mock私有方法的时候, 只是需要加注解@PrepareForTest,注解里写的类是私有方法所在的类
当需要mock系统类的静态方法的时候,必须加注解@PrepareForTest和@RunWith。注解里写的类是需要调用系统方法所在的类
@RunWith(PowerMockRunner.class)
public class RectangleServiceTest {
@InjectMocks //将其他用@Mock(或@Spy)注解创建的对象设置到下面对象中
RectangleService rectangleService;//创建bean(类似new RectangleService)
@Mock
RectangleDao rectangleDao;
@Before
public void setUp() {
MockitoAnnotations.initMocks(this);//初始化上面@Mock和@InjectMocks标注对象
}
@Test
public void testRectangleService() throws Exception{
//打桩
PowerMockito.when(rectangleDao.getRectangleById("1")).thenReturn(new MyRectangle(2,3));
//构造期望数据,计算实际数据,比对两者
MyRectangle myRectangle = new MyRectangle(2,3);
int expectedArea = myRectangl`在这里插入代码片`e.getArea();
//调用实际数据并对比
int actualArea = rectangleService.getRectangleAreaById("1");
Assert.assertEquals(expectedArea, actualArea);
}
}
Pytest
1.定义:
pytest 是 python 的第三方单元测试框架,比自带 unittest 更简洁和高效,支持315种以上的插件,同时兼容 unittest 框架。这就使得我们在 unittest 框架迁移到 pytest 框架的时候不需要重写代码。
2.作用:
单元测试框架,比unittest测试框架更灵活;
入门难度低,第三方库丰富;
通用性;
与allure生成的报告非常美观;
定制性强;
编写代码注意事项
模块名称(即py文件名称)必须以test_开头或以_test结尾;
测试的类名(即Class Testxxx)必须以Test开头,且在类中不能含有init;
测试方法(即def testxxx)必须以test开头;
7.了解其他专项测试:不仅限于黑盒、白盒等,在迭代任务中皆有部分涉及;
埋点其实就是在程序中的某个位置加一个标记,当用户触发到某个行为的时候,就采集一下数据,然后将数据上报到某个位置进行存储,埋点的最终目的是收集到相关的数据,用于给运营人员提供数据支撑等。
确认实际入库字段与任务中要求的字段一致
8.熟悉Linux基本命令,熟练使用Linux搭建测试环境,比如部署前后端服务器,例如tomcat,nginx,数据库、以及Android测试环境等;
命令
MySQL nginx
启动mysql服务
== 每次开机都要手动启动mysql ==
systemctl start mysqld
== 开机时自动开启mysql ==
systemctl enable mysqld
== 停止mysql服务器==
service mysqld stop
==启动mysql服务器==
service mysqld start
== 查看mysql是否启动==
service mysqld status
登录mysql
是因为第一次登录mysql需要使用mysql的临时密码,该密码存放在mysql日志文件中。
在 /var/log/mysqld.log 文件中
cd /var/log
查询临时密码
grep -n password mysqld.log

nginx
第一步、去查一下相关资料、看看目前有没有遗漏的地方
第二部、准备工作,确定相关依赖有没有准备好、比如安装nginx之前需要确保linux上安装了gcc、PCRE、zlib、OpenSSL等依赖。安装MySQL之前确保JDK已经安装好。
第三步、官网下载压缩包,然后创建目录,使用tar命令将安装包解压到新目录下面
第四部:nginx:进入到nginx目录下。执行./configure脚本,进行配置,nginx
使用 make && make install 命令进行编译安装
第五步、检查安装是否成功
./nginx -v,查看nginx的版本号
第六步、检查防火墙的状态、开放端口号(Linux防火墙默认情况下,会拦截我们访问的端口号,所以我们需要去放行我们要访问的端口号)
android 环境
9、熟悉关系型数据库MySQL以及了解非关系型数据库Redis和Mongodb,结合实际项目对中间件做测试和数据库做测试。熟练编写数据库SQL增删改查,以及嵌套子查询,多表查询语句等,了解存储过程,能够使用图形化界面管理数据库;
面试问题预测
1、自我介绍
你们测的产品是什么,测都是什么
产品
整个android手机系统、我之前所在的产品线:主要是将谷歌的开源的android系统代码根据用户的需求进行修改定制,开发初步
(公司会在谷歌一开始发布新版源码的时候、开发会在第一时间把源码拉下来,做一个初步的版本、后续的项目可能都是基于这个分支开发出来的)所以速度比较快。
一般五个开发和测试阶段(一个阶段都在两周左右)每个阶段都有具体的一些指标。
(但是设备并未获得谷歌认证。如果用户使用的是国产手机,所使用的安卓系统可能并不需要谷歌授权,但如果手机销往国外则需要谷歌授权GMS服务,否则产品国外无法销售。但GMS认证并不是想象的那么容易,谷歌要根据厂商的实力和地区因素来考虑是否认证。)
测什么
测的产品基本上都是android手机操作系统,测试需要去测手机各个方面功能、比如,相机、无线网络、lcd屏幕
相机:
(各种分辨率下拍照会不会出现花屏、水波纹,相机的各个功能是否已经实现了,前后摄拍照录像功能是否正常,Camera功耗电流是否符合标准、和影像三方APK是否兼容。
LCD:
LCD 显示是否正常,是否存在斑点、阴影等
LCD各种颜色能否正常显示,
LCD分辨率、色素、响应时间等性能指标是否符合要求
(功能测试、Camera专项测试、稳定性测试、兼容性测试、性能功耗测试、器件专项测试、无线专项测试、生产相关测试、资料测试等测试活动的测试计划、测试设计及测试执行策略。
)
Camera功耗电流测试 Xcover 6 pro 1 南京、宜宾
影像功能响应时间专项测试 Xcover 6 pro
性能重负载测试报告 Xcover 6 pro
影像Apk第三方兼容性专项 Xcover 6 pro
相机功能 Xcover 6 pro
需求核对 Xcover 6 pro
WISL Test(BT/WIFI) 蓝牙设备兼容性、WiFi设备兼容性
GPS 静态测试+动态测试
NFC 读写测试、传输测试、设备感应测试
Modem 搜网、速率测试、网络稳定性、modem冲突
Dedicated SIM-Card HotSwap(SIM卡热插拔专项) 多场景交互读取测试、PIN锁
SIM Card 兼容性 识卡测试、交互测试
工作内容
我的工作:我负责手机SystemUI、其中包括解锁、状态栏、下拉状态栏、壁纸、通知栏这些模块。(下拉状态栏又会涉及到通讯功能、蓝牙、wifi等)
某个负责的模块有bug,就需要去分析代码、主要看得就是app层的代码以及应用程序层的代码去,定位BUG出现的具体位置()。
问题比较小、可以修改的话
部分了是对应用程架构层(以上的功能基本上都要调用应用架构层的接口来实现,如果某一个功能出现问题就需要去定位相关的代码、)
Framework层(Java API Framework,应用程序架构层),用Java语言编写。
项目阶段
EVB阶段(Pre test):针对已经调试完成的器件执行基本功能测试
EVT阶段(Feature Complete):启动第一轮需求测试、全功能测试
DVT阶段:启动第二轮需求测试、全功能测试
PVT阶段(Code Freeze):执行优先级高的完整测试、完整需求测试、专项测试回归测试
搭建环境
搭建环境之前要去一般回去网上查查一点资料、看看目前的思路是否完整、需要补充。
android环境配置环境大概分四步
1、
第一步:下载Ubuntu的相关依赖(一个基本的库、到android的官网、会提示你根据Ubuntu的版本去选择依赖版本)
2、
准备java运行环境 除了JDK外,android还需要SDK,去官网下载后、使用tar 命令解压 ,在(gedit ~/.bashrc)配置环境变量。
通过命令打开环境变量配置文件 gedit ~/.bashrc
1、在.bashrc文件末尾添加JDK的环境变量,JDK8默认如下
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
2、在.bashrc文件末尾Android SDK的环境变量,根据本地指定SDK的位置# android sdk
export PATH=${PATH}:~/Android/Sdk/platform-tools:~/androidSdk/Sdk/tools # android aapt
export PATH=${PATH}:~/Android/Sdk/build-tools/30.0.2 # android adb
export PATH=/home/android/Android/Sdk/platform-tools/:$PATH
3、添加完成回到终端输入命令让配置生效 source ~/.bashrc
3、准备repo(rui pou)和git
Android代码,通常使用的是repo工具和git工具进行分布式管理
3、准备分布式版本控制功工具Git的配置、
使用apt (sudo apt-get install git)命令安装,
安装后(使用命令:git config --global user.name “Your Name” $ git config --global user.email “[email protected]” )
配置自己的用户名以及邮箱
4、android 涉及到几个git库,需要去下载谷歌的一个python脚本 rope,使用rope对git 仓库进行管理,公司内部的、直接把repo放到usr/bin 目录下、修改一下权限
android的代码是放在多个git仓库中,需要一个全局的命令repo进行统一的管理,repo是谷歌提供的用于管理多个git仓库的工具。它其实就是一个python脚本,所以使用它就很简单了,只需要将它配置到环境变量中就OK了。具体操作如下:
官方的定义:Repo是谷歌用Python脚本写的调用git的一个脚本,可以实现管理多个git库。
repo init -u
repo sync
个人理解:repo这个工具,是一个脚本。这个脚本是对git库的管理。
类似什么呢,类似makfile。功能是使你简单一敲make,就ok了。repo 呢,简单一敲,repo init -u 。url 指的是 manifest仓库地址,option 一般是所在分支,比如-b 你的分支,就行了。再执行一句,repo sync 。刷刷刷,等待个几十个小 时,(网速好的,时间相对短一点)。就把你需要的安卓整个源码同步在本地了(几十个G这么大吧)。
repo呢,其实说来,就是很多个git clone 的集成,如果有一个工程,有一百个git,你下载下来,按逻辑是敲一百次git clone xxxx,下载下来。但是使用repo呢,只需要敲一次,喝喝茶,等待下载完成就可以了。
4、第四部 需要安装远程登录与远程的文件传输工具SHH安装
光是git和repo还是不能愉快的进行代码下载,因为repo脚本中使用了ssh相关的密文校验,因此我们还需要执行如下命令:
sudo apt-get install sshpass encfs cifs-utils ccache python
SSH协议有两种访问方式:使用对应机器的用户密码;通过密匙对进行本地与远程机器的访问。SSH 是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议,我们用公钥配置后才能提交代码到gerrit上进行代码审查。可通过如下步骤:
配置ssh服务器:SSH协议使用通过~/.ssh/config文件里面信息进行获取,因此还需要在该文件中配置对应的服务器(repo解析命令在该文件中寻找对应的服务器并进行代码下载)。如下:
host scm
user git
hostname gitcode.tinno.com
identityFile ~/.ssh/id_rsa
host gerritXXX #服务器标识 repo init -u后面参数
KexAlgorithms +diffie-hellman-group14-sha1
KexAlgorithms +diffie-hellman-group1-sha1
user pengcheng.ding #用户名 git config --global user.name配置用户名
port 29418 #服务器端口号
hostname gitcode.tinno.com #服务器地址或者域名
identityFile ~/.ssh/id_rsa #秘钥
# 例如下载某个项目代码需要执行如下repo init命令:
# repo init -u gerritXXX:mt6762r/platform/manifest -b sw -m MT67R_DEV_EXP2.0_V1.0.xml
# repo 解析第四个参数gerritXXX,会从~/.ssh/config文件中寻找适合有该服务器标识,如果有就得到具体的服务器地址和端口,使用~/.ssh/id_rsa秘钥中的信息与该服务器的公钥信息进行配对,配对成功就可用开始愉快的下载代码了
第五部 安装adb工具
adb工具(通过USB接口直接管理调试测试机)
sudo apt-get install android-tools-adb
Linux命令
1.1.1你常使用的基本命令:
例如目录操作相关的命令,Mkdir 创建目录、rm -rf 删除目录、mv 移动目录或者重命名、cp 复制目录或者移动目录、find 查找目录。
以及文件操作命令 touch 新建文件 vim/vi编辑文件内容。
chmod修改文件的权限。
tar对文件打包或者解压。
Grep对输入到终端的内容进行过滤。
service 对防火墙网络状态进行管理 chkconfig 设置后台服务的自启配置
ps -ef查看运行中的进程,kill杀死进程 netstat 查看端口号
crontab 编写定时任务。
free 显示内存的使用情况
df 查看磁盘的使用
du查看文件的大小
top实时显示单个进程的动态
tar -zcvf ab.tar * 将当前目录下全部打包成ab.tar
tar -xvf ab.tar -C /usr -C代表指定解压的位置
1.1.2vim/vi编辑器
修改文件i或vim/vi编辑器的3种模式
基本上vi可以分为三种状态,分别是命令模式、插入模式和底行模式,
命令行模式 :控制屏幕光标的移动,字符或行的删除(dd删除当前行),查找(/匹配字符),移动复制某区段及进入插入模式下,或者到 底行模式。
编辑模式: 只有在编辑下,才可以做文字输入(点击i按键),按「ESC」键可回到命令行模式。(编辑模式只有回到命令行模式才可以进入底行模式进行退出)
底行模式:将文件保存或退出vi,也可以设置编辑环境,如寻找字符串、列出行号……等。
【1】退出编辑: :q
【2】强制退出: :q!
【3】保存并退出: :wq
打开文件
命令:vi 文件名
示例:打开当前目录下的aa.txt文件 vi aa.txt 或者 vim aa.txt
注意:使用vi编辑器打开文件后,并不能编辑,因为此时处于命令模式,点击键盘i/a/o进入编辑模式。
编辑文件
使用vi编辑器打开文件后点击按键:i ,a或者o即可进入编辑模式。
i:在光标所在字符前开始插入
a:在光标所在字符后开始插入
o:在光标所在行的下面另起一新行插入
保存或者取消编辑
保存文件:
第一步:ESC 进入命令行模式
第二步:: 进入底行模式
第三步:wq 保存并退出编辑(熟读)
1.1.3chmod
用法:chmod + 设置模式 + 文件名
在 linux 中的每个用户必须属于一个组,不能独立于组外。文件所有者,同组用户、其他用户,所有者一般是文件的创建者。所有者可以允许同组用户有权访问文件,还可以将文件的访问权限赋予系统中的其他用户。在这种情况下,系统中每一位用户都能访问该用户拥有的文件或目录(理解就好不用背)
chmod 600 aaa.txt
421 421 421
- rw- — —
d rw- — — 目录的权限
用户 用户所在组 其他用户
遇到过的最大困难
答:困难到没有遇到过,遇到过一个有挑战性的事情,cypress,晚上加班看视频,两三天上手开始写自动化脚本,顺利的完成任务。
最开始熟悉业务的阶段,刚入职没多久就开始做迭代任务了,在写测试点的时候需要去查看之前的测试用例,熟悉功能逻辑和测试要点,这个阶段需要花费很多时间,自己都是下班之之后加班去熟悉功能,为了任务能够有质量的完成以及不延期。
四方协作:比如我发现开发做的功能和产品需求文档上的功能不一致,我去提了bug,开发说交互稿上没有这样设计,然后我又去找了产品,产品说交互遗漏这个细节,交互加上这个细节之后,开发又不愿意改了,因为需要花很多时间去修改代码,并且测试的影响面也很多,这种情况,如果这个功能不重要就留到下一个迭代去做,然后备注好是交互的遗漏,如果重要的话,我就需要去做协调,和开发好好交流沟通,让他先改代码,如果要延期,我就去申请,如果能快速改好,但是影响面 比较大的话,我就加班去测试,最后经过我的努力,这个任务还是按时上线了,我加班测,还好没有测出bug,所以就没有延期
1.公司的组织架构,人员配比
非关系型数据库
CI/CD,是指持续集成(Continuous Integration,CI)和持续交付(Continuous Delivery持续测试(Continuous Testing,CT)
DevOps 常用的工具
Git
Jenkins
Docker
Kubernetes
4.1. Jenkins
Jenkins(读:[ˈdʒɛŋkɪnz])是很多软件开发团队在走向 DevOps 时会用的自动化工具。它是开源的 CI/CD 服务器,帮助用户自动化交付流水线的不同阶段。Jenkins 之所以流行的主要原因是其巨大的插件生态系统。目前,它提供 1000 多个插件,因此它可以和几乎所有 DevOps 工具集成
使用 Jenkins 很容易,它在 Windows,Mac OS X 和 Linux 上开箱即用。很容易就可以使用 Docker 安装它。用户可以通过浏览器搭建并且配置 Jenkins 服务器。如果你是第一次使用它,可以选择安装最常用的插件。当然也可以创建自定义配置。使用 Jenkins 用户可以尽快迭代并部署新代码。它还帮助用户度量流水线里每一步是否成功
官网:https://jenkins.io/
4.2. Kubernetes
Kubernetes 又称 K8S,它是容器编排平台,将容器化推进到下一个层面。它可以使用 Docker 或者其他替代产品。使用 Kubernetes 用户可以将容器组织成逻辑单元。如果你只有几个容器,那么可能并不需要容器编排平台。但是,当系统达到一定级别的复杂度,需要扩展资源的时候,这就是合理的下一步。Kubernetes 让用户可以自动化管理上百个容器的过程
使用 Kubernetes 无需将容器化的应用程序绑定到某个单独的机器里。相反,你可以将它部署到一个机器集群里,Kubernetes 会自动化分发并在整个集群里调度容器
一个 Kubernetes 集群包含一个 master 和几个 worker 节点。master 节点实现预定义的规则,并且将容器部署到 worker 节点上。Kubernetes 负责所有一切。比如,它注意到某个 worker 节点下线了,就会将其上的容器重新分发到别的节点上
运维人员会在项目开发期间就介入到开发过程中,了解开发人员使用的系统架构和技术路线,从而制定适当的运维方案。而开发人员也会在运维的初期参与到系统部署中,并提供系统部署的优化建议
2.熟练掌握测试基础,能不断优化并规范测试流程,提高整体测试效率,熟练使用Jira来管理Bug,测试完成后编写测试报告;编写测试脚本来提高整体测试效率掌握 Web 项目完整部署流程;并致力于搭建基于 DevOps 的完整CI/CD 全路自动化。
测试用例的编写:
功能测试用例:
接口测试用例:
白盒测试用例:
UI测试用例:
性能测试用例:
Bug管理
jari
bug的管理流程 级别 重要参数
Web 项目完整部署流程
3.熟练Linux基本命令,熟练使用Liunx搭建测试环境,比如部署前后端服务器,例如tomcat,nginx,数据库,查看日志分析并定位Bug等;了解shell脚本编写,了解Liunx内核开发。
4.熟悉关系型数据库MySQL,Oracle、以及非关系型数据库Redis和Mongodb,结合实际项目对中间件做测试和数据库做测试。熟练编写数据库SQL增删改查,以及嵌套子查询,多表查询语句等,了解存储过程,熟练使用图形化界面管理数据库。
MongoDB(使用MSI包进行安装) 是一个基于分布式文件存储的数据库。由 C++ 语言编写,MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。使用javaScript语言编写
MongoDB 数据模型
启动服务: mongod --dbpath E:\MongoDB\data\db
一个MongoDB实例可以包含一组数据库,一个DataBase可以包含一组Collection(集合)(colletion相当于数据库的表、其中的一个文档就是一个数据),一个集合可以包含一组Document(文档)。
注意:文档都放在同一个集合中,无论对于开发者还是管理员,都很难对集合进行管理,而且这种情形下,对集合的查询等操作效率都不高。所以在实际使用中,往往将文档分类存放在不同的集合中。
一个Document包含一组field(字段),每一个字段都是一个key/value pair
key: 必须为字符串类型
value:可以包含如下类型
基本类型,例如,string,int,float,timestamp,binary 等类型
一个document
数组类型
mongodb会给每条数据增加一个全球唯一的_id键
增加:db.集合名.insert(JSON数据)
use test2 db.c1.insert({uname:“webopenfather”,age:18})
db.c1.insert([ {uname:“z3”, age:3}, {uname:“z4”, age:4}, {uname:“w5”, age:5} ])
for (var i=1; i<=10; i++) { db.c2.insert({uanme: “a”+i, age: i}) }
查询文档
db.集合名.find(条件[,查询的列])
db.集合名.find({
键:{运算符:值}
})
修改文档
db.集合名.update(条件,新数据[是否新增,是否修改多条,])
db.c3.update({uname:“zs30”},{$set:{age:30}},true)
删除文档
db.集合名.remove(条件[,是否删除一条])
MongoDB存储数据类型
rides
String(字符串)
①添加(set)、查询(get)、追加、获取长度,判断是否存在的操作
②自增(incr)、自减(decr)操作:一般用来做文章浏览量、点赞数、收藏数等功能// 一般用来做文章取消点赞、取消收藏等功能
INCRBY num 10 #后面跟上by 指定key为‘num’的数据自增‘参数(10)’
DECRBY num 3 #后面跟上by 指定key为‘num’的数据自减‘参数(3)’,
返回结果(integer) 14
③截取、替换字符串操作
GETRANGE key1 0 4 #截取字符串,相当于java中的subString,下标从0开始,不会改变原有数据"hello"
SETRANGE key2 5 888 #此语句跟java中replace有点类似,下标也是从0开始,但是有区别:java中是指定替换字符,Redis中是从指定位置开始替换,替换的数据根据你所需替换的长度一致,返回值是替换后的长度
④设置过期时间、不存在设置操作
⑤mset、mget操作
⑥添加获取对象、getset操作
List(列表)
①lpush(左插入)、lrange(查询集合)、rpush(右插入)操作
②lpop(左移除)、rpop(右移除)操作
③lindex(查询指定下标元素)、llen(获取集合长度) 操作
④lrem(根据value移除指定的值
⑥ltrim(截取元素)、rpoplpush(移除指定集合中最后一个元素到一个新的集合中)操作
⑦lset(更新)、linsert操作
实际上是一个链表,before Node after , left,right 都可以插入值
如果key 不存在,创建新的链表
如果key存在,新增内容
如果移除了所有值,空链表,也代表不存在!
在两边插入或者改动值,效率最高! 中间元素,相对来说效率会低一点~
消息排队!消息队列 (Lpush Rpop), 栈( Lpush Lpop)!
Set(集合)元素唯一不重复
①sadd(添加)、smembers(查看所有元素)、sismember(判断是否存在)、scard(查看长度)、srem(移除指定元素)操作
Hash(哈希)
①hset(添加hash)、hget(查询)、hgetall(查询所有)、hdel(删除hash中指定的值)、hlen(获取hash的长度)、hexists(判断key是否存在)操作
zSet(有序集合)
①zadd(添加)、zrange(查询)、zrangebyscore(排序小-大)、zrevrange(排序大-小)、zrangebyscore withscores(查询所有值包含key)操作
三大特殊类型:地理位置\基数\位储存
5.熟悉接口测试和接口前后端概念,了解计算机网络的基本知识,能熟练使用Jmeter工具做断言,参数化,业务闭环。
关于计算机网络的一些基本知识:
5. 接口请求中常用的返回状态码
1XX:信息提示。
2XX:成功。
3XX:重定向。(发送一个请求时,这个请求多次请求了服务器的多个资源)
4XX:客户端错误。
5XX:服务器错误。
6. cookie,session,token有什么相同点,不同点?
相同点:都是用于存储信息,进行用户鉴权,并且都是服务器生成的。
不同点:
① cookie保存在客户端的浏览器上,cookie不安全,可以去分析存在在本地的cookie进行cookie欺骗。
② session保存在服务器的内存,默认保存30分钟,比cookie安全,缺点就是当登录的用户越多,比较占用服务器的资源。session一般会生成一个sesionid(服务器定义,定义后,服务器会把session id和会话有效时间发送到浏览器,浏览器接收到后,会根据会话的有效时间加上现在的时间生成会话到期时间,到期,浏览器就会删除这个session,以后每次再去请求这个服务器的时候都会吧session id 带上,服务器根据这这个id去核对用户信息,进行登录),sessionid可以通过cookie传输。
如果用户量特别的大,服务器就需要存储大量的session,很浪费服务器的存储空间,而且有多台服务器的话,也可能导致面临session id 分享到其他服务器
③JWT
服务器保存JWT的密文,发吧JWT发送给浏览器,浏览器可以使用cookie保存
token存储在服务器的数据库里面,通过一个接口或通过登录获取,然后后续所有的接口都必须要传token才可以请求成功。token也可以通过cookie传输。 (身份验证方法,在服务器端不需要存储用户的登录记录。)
cookie是客户端向服务器发送请求,服务器产生cookies,返回给客户端,存放于浏览器的缓存当中,session数据储存服务端的,他比cookies更安全,所以用来保存重要的数据,退出浏览器会清楚数据
token是身份令牌,一般保存在请求头当中,用户识别用户的身份
json是一种开发常用的数据报文格式,由键值对和数组两种格式构成
测试报告
五、测试报告模板
测试总结报告:
1)总结(如测试了什么、结论如何等等)
2)测试计划、测试用例的变化;
3)全面评估版本信息;
4)结果总结(度量、计数);
5)测试项未通过/未通过准则的评估;
6)活动的总结(资源的使用、效率等)
测试用例模板
用例编号、测试模块、用例标题、用例级别、前置条件、测试输入、执行输入、预期结果
世界结果、测试人员、结束时间
测试报告模板
测试目标、测试依据、测试范围、测试环境、测试进度、执行结果、缺陷分布、遗留缺陷、测试结论、建议、附录

![]()

计算机网络

 ## 灰盒测试
## 灰盒测试
输入的正确性,同时也关注程序内部的情况。灰盒测试不像白盒那样详细、完整,但又比黑盒测试更关注程序的内部逻辑,常常是通过一些表征性的现象、事件、标志来判断内部的运行状态。
软件测试是什么
在规定的条件下对程序进行操作,从而发现问题、对软件质量进行评估的过程。
软件产品质量模型(六大特性)
功能性(最基本的要求)适合性 准确性 互操作性 确保安全性 功能的依从性
可靠性:设备不要出问题,即使除了问题也不要影响主要的功能和业余,如果影响了,想听可以尽快的恢复
易用性:用户体验好(易懂、易学、易用、漂亮好看)
效率(即为性能):
可维持性:维护产品、以及升级产品以便跟好的适应用户的需求。
可移植性:软件产品可以从一个环境移植到另一个环境的能力。