mysql:B+树/事务

B+树 : 为了数据库量身定做的数据结构
我们当前这里的讨论都是围绕 mysql 的 innodb 这个存储引擎来讨论的
其他存储引擎可能会用到hash 作为索引,此时就只能应对这种精准匹配的情况了
要了解 B+树 我们先了解 B树, B树 是 B+树 的改进
B树 有时候会写作 B-树 (这里的" - "是连接符)
B树 的核心思路和"二叉搜索树"差不多,一个节点上,可以保存多个 key ,N 个 key 就能延伸出 N+1 个分叉来,N 个 key 就划分出了 N+1 个区间(比如四个 key 就有五个分叉,三个 key 就有四个分叉)
B树 如下图所示

B树 查询元素的流程,拿着要查询的元素从根节点出发
比如我们要查询23,先看看23在不在根节点,如果不存在就看看23落在根节点的哪个区间,23<30,所以落在30左边的区间,再看看存不存在,不存在就看看又落在哪个区间,20<23<25,所以落在20~25中间这个区间,然后就在里面找到了23
此时每个节点上都可以保存多个元素,所以说当元素固定的时候,相较于二叉搜索树,涉及到的节点大大减少了,树的高度也大大降低了
B树 的高度是远远小于二叉搜索树的,于是进行查询的时候,硬盘 IO 的次数也就随之减少了(对于数据库来说每个节点都需要把数据从硬盘上读出来才能进行比较,B树 就能一次读取多个数据,每读取一次都是一次 IO,这下一次 IO 读取多个,次数就减少了)
一个节点上有多个 key 和一个节点上有一个key ,硬盘 IO 的开销是差不多的
对于 B树 来说,再进行插入元素和删除元素的时候,涉及到拆分和合并的操作
因为一个节点可以存多个 key,但是也不能无限存,当存储的 key 的数量达到一定程度的时候,就需要把这个节点给拆分,把这个节点中的一部分 key 以树的子节点的方式来进重新组织,这样就会衍生出新的叶子结点,当父节点被删了几个,叶子结点就会填补上
具体啥时候拆分,怎么拆分,具体啥时候合并,怎么合并,就看实际的视线了,不同场景下可以有不同的策略

B+树才是数据库索引的主角.在 B树 的基础上,又进一步地做出了一些改进(针对数据库的查询场景展开的)
1.B+树 也是N叉搜索树,但是N个 key 分出了N个区间,其中节点上的最后一个 key 就是最大值了(取最小值也行)
2.父节点的 key 会在子节点中重复出现(而且是以最大值的身份)
看起来有很多重复元素,但是包含了一个重要信息==>"叶子结点就是整个数据的全集"
3.把叶子节点按照类似于链表这样的方式,首尾相连,此时通过叶子节点之间的连接就可以快速找到"上一个""下一个"元素,也方便进行范围查询,比如我们要找<11的数据,先从根节点开始找,看11最后在叶子节点的哪个位置,然后从11开始到链表最左边的位置就是目标结果


上面三个是 B+树的特点,这些特点产生的优势是什么呢?
1.特别擅长范围查询
2.所有的查询操作,最终都会落到叶子节点上,比较次数是均衡的,查询时间稳定的
有的时候稳定比"快"更重要
3.由于叶子结点上是完整的数据全集,因此表的每一行数据都可以保存在叶子节点上,而非叶子节点值存储构建索引的 key 即可(只存简单的 Id 就行了)

其实在物理层面上不需要"表格"这样的数据结构,直接使用 B+ 树来存储这个表的数据,"表格"只是用户看起来这像是个表格而已
此时非叶子的存储空间消耗是非常小的,可以再内存中缓存一份,此时进行数据查询的时候,就可以通过内存来直接进行比较,从而更快地找到叶子节点上的记录,又进一步减少了键盘 IO 的次数
B树 如果也要把元素存储到每个节点上,非叶子节点就会占据较大的空间,从而无法再内存中缓存了
这里的面试题:介绍对数据库索引的认识,这里就包含该博客介绍的所有内容
事务
事务的基本情况
有的时候为了完成某个工作,需要多组 sql 操作

事务的本质就是为了把多个操作打包成一个操作来完成(让多个操作要么全都执行成功,要么就一个都不执行)
注意一个要点,"一个都不执行"不是真的没执行,执行成不成功得执行了之后才知道,真正执行之前是不知道哪一步会失败的,如果是执行到中间出错了,就需要自动地把前面已经成功执行的操作进行还原,还原回最初没执行的模样(给还原这个操作起了个名字叫做回滚 rollback)
回滚是怎么实现的? 只要把事务中执行的每个操作都记录下来(通过特定的日志),如果需要回滚,就直接按照之前的操作的"逆操作"来执行就可以了(比如插入的逆操作就是删除,删除的逆操作就是插入,修改的逆操作就是修改回去)
下面举个例子


start transaction 开启事务
开启事务后就可以输入多个 sql 语句了
commit 提交事务,把这些 sql 按照原子的方式来进行执行(带有回滚机制)
rollback 手动触发回滚
一个事物务必要以 commit 或者 rollback 这两个操作结尾,如果没有这俩操作,接下来的各种 sql 操作都会被认为是事务的一部分
上述操作不做演示,因为实际开发中往往使用程序代码来操作事务,不太会用命令操作事务 ,代码中操作事务和这几个命令差别较大
事务的基本特性(面试必考):
1.原子性: 保证多个操作被打包成一个整体,要么能够全部执行正确,要么就一个都不执行
2.一致性:事务执行之前和事务执行之后,数据能对得上,数据不能不靠谱
回滚机制不光支持了原子性,还支持了一致性
3.持久性: 事务这里执行的各种操作,都是持久生效的(最终写入硬盘中的),一旦事务执行成功,这里的所有操作产生的修改,都是写到硬盘里的(即使重启服务器,重启主机,它们也不会失效)
4.隔离性: 并发执行事务的时候 ,隔离性会在执行效率和数据可靠之间做出权衡,可以让程序员在使用的时候,根据实际需要来决定我们是要隔离性高一些数据可靠一些,还是要隔离性低一些效率高一些
"隔离"描述的是同时执行的事务之间相互的影响
隔离性越高,并发性就越低,数据越可靠,性能就越低
啥是并发? 简单理解为同时执行.
数据库是一个客户端服务器结构的程序,既然是服务器,服务器就可以同一时刻给多个客户端提供服务,这多个客户端就都能给服务器提交事务,如果提交的两个事务,是修改不同的数据库,修改不同的表,相互之间就没啥影响,但是修改的是同一个表的话,这个时候就可能存在麻烦
下面举个例子,两个客户端都去修改同一个余额表

假设 客户端1 有两个操作,客户端2 有一个操作,两个客户端的操作必然有先后区别,造成的结果也就会不一样
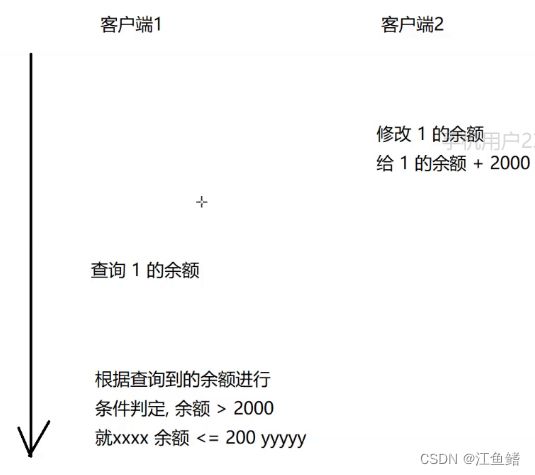

所以最后的判定到底是根据1000还是3000?这是存在歧义的
这就是并发执行事务所带来的问题
脏读是我们并发执行事务中非常典型也非常常见的问题:

如何解决脏读问题? 给写操作加锁即可,事务A 写的时候,其他事务不能读了,直到事务A 写完数据,提交了事务,其他事务才能读取数据
引入了写加锁,降低了两个事务之间的并发性,提高了隔离性,降低了效率,使数据更准确了
不可重复读是我们并发执行事务中常见的问题:

如何应对不可重复读? 给读操作也加锁,别人读的时候就不能写了, 此时并发程度又进一步降低了,隔离性进一步提高了,执行效率变低了,数据可靠性更高了

解决幻读: 办法只有一个,串行化.彻底放弃并发执行事务,所有的事务都是一个挨一个的串行执行,执行完一个事物,再执行下一个事务,并发性最低,隔离性最高,效率是最低的,数据是最可靠的

Mysql 提供了四种事务的隔离级别
mysql 可以配置自己的隔离级别是哪个,咱们可以根据实际的需求场景来决定使用哪个隔离级别,找到一个效率和可靠性都能接受的情况,但是大部分情况下使用默认的隔离级别就够用了(repeatable read)
