miniconda安装及环境创建(Linux)
参考链接:https://discuss.gluon.ai/t/topic/13576?u=bigbigwolf-ai
1 安装miniconda
1、创建文件夹:mkdir miniconda(文件夹名)
2、下载软件安装包:cd miniconda(转到当前文件夹)
3、下载miniconda软件
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh
4、执行程序:bash Miniconda3-latest-Linux-x86_64.sh
会弹出一个软件协议条款让你阅读,这时候直接按下Ctrl+C便可以跳过阅读过程,直接按照提示,输入yes,然后按回车键,同意软件协议条款。接下来继续按回车,将miniconda安装到电脑上。安装好之后,提示如下:
这一步一定要输入yes,不然安装好后没办法在终端中使用miniconda。输入yes,按下回车键,miniconda便成功安装到你电脑上了。重启终端之后,你便可以使用miniconda了。
5、重启终端,然后分别执行如下命令,将conda和pip的软件源修改成清华的源,这样的话,下载安装软件会快很多:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
6、再次重启终端之后,你会发现每次打开终端默认都会自动进入到miniconda的base环境中,终端中多了“base”字样。这样会拖慢终端打开速度,并且有可能干扰到其它软件的安装。要退出的话,必须每次打开终端之后先执行conda deactivate命令,让人很难受。执行如下命令,便可以解决终端每次打开都进入conda的base环境的问题:
conda config --set auto_activate_base false
2 查看cuda等版本
1、查看Ubuntu版本号:cat /etc/issue

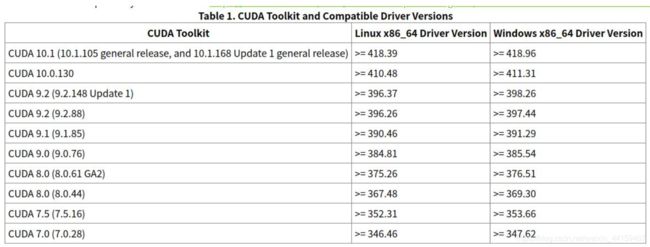
2、安装比较新的显卡驱动,显卡驱动应该安装哪个版本,其实取决于你想使用哪个版本的cuda。如果想用最新的cuda 10或者cuda 10.1,那么驱动版本号不能低于某个版本。NVIDIA官方给的数据如下图所示:
注:这里将要说的安装方法,适用于Ubuntu 16.04和Ubuntu 18.04。其它的Ubuntu版本没测试过。
为Ubuntu安装NVIDIA驱动主要有两种方式,一种是到NVIDIA官网下载对应显卡型号的驱动的.run文件,然后按照NVIDIA官网的说明安装即可。这种安装方法失败率很高,并且安装过程十分繁琐,不推荐使用这种方式。另外一种是通过添加Ubuntu官方维护的NVIDIA显卡驱动源,然后使用apt来安装即可,推荐使用这种方法。注意,采用第二种方法时,由于Ubuntu官方维护的NVIDIA显卡驱动源在国外,因此下载速度十分缓慢,安装显卡驱动需要几个小时都有可能,而且80%的概率会因为网速问题导致显卡驱动安装失败。建议安装显卡驱动这个步骤在北京时间早上7点到9点之间进行,那个时候在国内访问该软件源的网速是最快的,几分钟就能安装好。下面是采用第二种方法来安装显卡驱动的具体的步骤。
3、查看显卡型号,如果知道是NVIDIA显卡,可直接用命令nvidia-smi即可显示具体显卡型号。
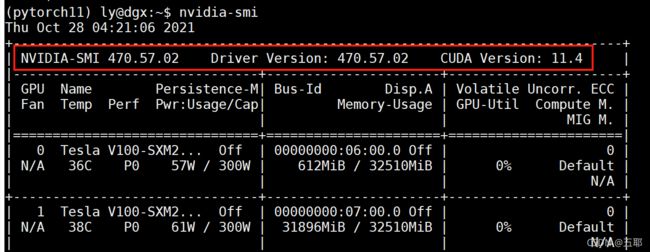
4、查看NVIDIA显卡驱动版本:cat /proc/driver/nvidia/version。
3 虚拟环境
3.1 创建环境并安装pytorch
列出当前已经创建的python虚拟环境
conda env list
1、创建环境
conda create --name myenv python==版本号
myenv是自定义环境名称。
2、进入环境
conda activate myenv
3、退出环境
conda deactivate
4、安装pytorch
pytorch官网:https://pytorch.org/get-started/locally/
参考链接:https://blog.csdn.net/jorg_zhao/article/details/106883420
5、删除环境
conda remove -n myenv --all
3.2 安装其他包
添加其他包,可指定版本号
pip install 包裹名(==版本号)
pip install numpy
pip install pandas
...
在pytorch环境下安装tensorflow或者paddle,直接pip即可。
pip install tensorflow
pip install paddlepaddle
pip install paddlepaddle-tiny
3.3 win下安装crf++0.58并测试
下载地址:
1、官网:CRFPP工具:https://taku910.github.io/crfpp/
2、知乎网友网盘:
linux:https://zhuanlan.zhihu.com/p/61968920
或者https://zhuanlan.zhihu.com/p/39695509
win:https://zhuanlan.zhihu.com/p/397378991
版本选择:Windows选择zip压缩包,Linux选择tar.gz压缩包。
Windows安装:直接解压。
实例测试:选中如图所示的三个文件,复制到“CRF+±0.58examplechunking”(一个有训练数据和测试数据的实例)。(如果提示已存在,可忽略此步骤)


- doc文件夹:官方主页
- example/chunking文件夹:四个训练示例,训练数据(train.data),测试数据(test.data)和模板文件(template),执行脚本文件exec.sh
- sdk文件夹:CRF++的头文件和静态链接库
- clr_learn.exe:CRF++的训练程序
- crl_test.exe:CRF++的测试程序
- libcrffpp.dll:训练程序和测试程序需要使用的静态链接
3.3.1 example/chunking/train.data
训练集格式:第一列为文本特征,第二列为词性特征,第三列是标签。
Confidence NN B-NP
in IN B-PP
the DT B-NP
pound NN I-NP
is VBZ B-VP
widely RB I-VP
expected VBN I-VP
to TO I-VP
take VB I-VP
another DT B-NP
sharp JJ I-NP
dive NN I-NP
if IN B-SBAR
...
3.3.2 example/chunking/template
CRF关键是状态特征函数与转移特征函数,二者都是通过特征模板来实现。CRF++是一种通用工具,需要提前指定特征模板。该文件描述了在训练和测试中使用了哪些特征。
# Unigram
U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
U05:%x[-1,0]/%x[0,0]
U06:%x[0,0]/%x[1,0]
U10:%x[-2,1]
U11:%x[-1,1]
U12:%x[0,1]
U13:%x[1,1]
U14:%x[2,1]
U15:%x[-2,1]/%x[-1,1]
U16:%x[-1,1]/%x[0,1]
U17:%x[0,1]/%x[1,1]
U18:%x[1,1]/%x[2,1]
U20:%x[-2,1]/%x[-1,1]/%x[0,1]
U21:%x[-1,1]/%x[0,1]/%x[1,1]
U22:%x[0,1]/%x[1,1]/%x[2,1]
# Bigram
B
状态特征模板
模板基本和宏(Template basic and macro)
模板文件中的每一行表示一个模板。在每个模板中,特殊宏 %x[row,col] 将用于指定输入数据中的标记。row 指定与当前聚焦标记的相对位置,col 指定列的绝对位置。
第一列为文本特征,第二列为词性特征,第三列是标签。
Input: Data
He PRP B-NP
reckons VBZ B-VP
the DT B-NP << CURRENT TOKEN
current JJ I-NP
account NN I-NP
template
expanded feature
%x[0,0]
the
%x[0,1]
DT
%x[-1,0]
reckons
%x[-2,1]
PRP
%x[0,0]/%x[0,1]
the/DT
ABC%x[0,1]123
ABCDT123
说明:以the为原点,向上为正,向下为负。%x[0,0]表示第零行,第零列,即the。%x[0,1]表示第零行,第一列,即DT。%x[-1,0]表示负一行,第零列,即reckons。%x[0,0]/%x[0,1]表示the和DT联合对the的标签B-NP产生作用。人为特征构造。注意只有文本和词性特征,没有标签。
状态特征模板表示使用当前观测及其上下文能对当前状态造成影响。这里the的标签是B-NP。%x[0,1]表示DT对the的标签B-NP产生作用,其它依次类推。
模板分类(Template type)
模板有两种类型。每个类型用模板的第一个字符指定。
-
Unigram 模板:第一个字符,‘U’ 。表示状态特征模板。给定一个模板,CRF++会自动生成一组特征函数。
-
Bigram 模板:第一个字符,‘B’。转移特征模板。
3.3.3 CRF训练
通过Anaconda Powershell Prompt(minicaonda)运行CRF程序:
进入文件夹
cd D:crfpp0.58CRF++-0.58examplechunking
CRF训练语法:crf_learn 模板文件 训练数据集 保存的模型名称
crf_learn template train.data model
方法一:
1、如果直接运行下述代码,打开的model是二进制文件。
crf_learn template train.data model
生成“model”文件,模型训练成功。
2、打印控制台的信息:
crf_learn template train.data model >> model_out.txt
即可生成model_out.txt文件。
方法二:(推荐)
可添加下述参数得到model文件及其txt文件:
# 示例1,-t表示生成txt的model文件
crf_learn -f 2 -c 2 -t template train.data model
# 示例2
crf_learn -f 2 -c 2 -t data/template.txt data/train_data.txt model/crf-seg.model
示例1输出得到model.txt文件,控制台输出结果:
CRF++: Yet Another CRF Tool Kit
Copyright (C) 2005-2013 Taku Kudo, All rights reserved.
reading training data:
Done!0.04 s
Number of sentences: 77 # 句子个数
Number of features: 48314 #
Number of thread(s): 8
Freq: 2
eta: 0.00010
C: 2.00000
shrinking size: 20
iter=0 terr=0.98629 serr=1.00000 act=48314 obj=5003.65270 diff=1.00000
iter=1 terr=0.38660 serr=1.00000 act=48314 obj=4086.08372 diff=0.18338
...
iter=30 terr=0.00000 serr=0.00000 act=48314 obj=188.14848 diff=0.00009
Done!1.58 s
输出参数:
- iter:迭代次数。当前迭代次数达到maxiter时,迭代终止。
- terr:标签错误率(错误标签的数量/所有标签的数量)
- serr:句子的错误率(错误句子的数量/所有句子的数量)
- obj:当前对象的值。当这个值收敛到一个确定的值的时候,训练完成。
- diff:与上一个对象之间的相对差。当此值低于eta时,训练完成。
控制训练条件的四个主要参数:
1)选择正则化算法。默认是CRF-L2。一般来说L2算法效果要比L1算法稍微好一点,但是L1 中非零特征的数量远小于 L2。
-a CRF-L2 or CRF-L1
2)这个参数设置CRF的超参数。c的数值越大,CRF越过度拟合训练数据。该参数在过拟合和欠拟合之间进行权衡。这个参数可以通过保留数据或模型选择方法(例如交叉验证)等寻找较优的参数。类似于正则化的参数。
-c float
3)这个参数设置特征频数的截止阈值(cut-off threshold)。CRF++使用训练数据中出现至少NUM次的特征函数。默认值为1。当使用CRF++训练大规模数据时,只出现一次的特征可能会有几百万。此选项在这种情况下很有用。
-f NUM
特征函数:
func1 = if (output = B-NP and feature="U01:DT") return 1 else return 0
func2 = if (output = I-NP and feature="U01:DT") return 1 else return 0
func3 = if (output = O and feature="U01:DT") return 1 else return 0
....
funcXX = if (output = B-NP and feature="U01:NN") return 1 else return 0
funcXY = if (output = O and feature="U01:NN") return 1 else return 0
...
4)如果电脑有多个CPU,可以通过多线程加快训练速度。NUM是线程数量。
-p NUM
5)设置最大的迭代次数(默认为10k)
-m -maxiter=int
6)设置终止标准(默认为0.0001)
-e -eta=float
7)模板,表示生成txt的model文件
-t 模板位置
-t data/template.txt
3.3.3 example/chunking/model.txt
version: 100 # 版本号
cost-factor: 1
maxid: 48314 # 特征个数,即特征函数个数
xsize: 2 # 两列,表示用了两列特征,文本 词性
B-ADJP # 标签
B-ADVP
B-NP
B-PP
B-PRT
B-SBAR
B-VP
I-ADJP
I-ADVP
I-NP
I-PP
I-SBAR
I-VP
O
U00:%x[-2,0] # 特征模板,与examle/template相同
...
U22:%x[0,1]/%x[1,1]/%x[2,1]
B
# 具体的特征函数
0 B # 有0到196个,B表示转移特征函数,即转移矩阵,从BEMS到BEMS,所以是14×14=196个,下面的权重第0到195就是转移矩阵的每一个权重,第一个是B-ADJP到B-ADJP
196 U00:# # 状态特征函数,由U00:%x[-2,0]模板生成的具体特征函数,权重对应196到210。有14个,分别对应状态特征函数公式上述14个标签的情况
48272 U22:VBZ/RB/VBN
48286 U22:VBZ/VBN/DT
48300 U22:VBZ/VBN/TO
-0.4317051898712497 # 特征函数对应的权重
-0.3631466223489143
...
-0.0032693938643956
3.3.4 测试参数
crf_test -m model test.data
crf_test -m model/crf-seg.model data/train_data.txt
1)-v可以显示预测标签的概率值;
2)-n可以显示不同可能序列的概率值
第一列是文本特征,第二列是词性特征,第三列是真实标签,第四列是预测标签。
change NN I-NP I-NP
. . O O
This DT B-NP B-NP
leads VBZ B-VP B-VP
to TO B-PP B-PP
a DT B-NP B-NP
very RB I-NP I-NP
special JJ I-NP I-NP
sense NN I-NP I-NP
of IN B-PP B-PP
urgency NN B-NP B-NP
. . O O
If IN B-SBAR B-PP
the DT B-NP B-NP
...
4 linux常用操作
4.1 查看文件大小
查看所有文件包括隐藏文件,每个文件的大小(推荐)
du -h --max-depth=1
12K ./.config
5.5M ./siege-4.0.7
551M ./.cache
35M ./.pycharm_helpers
8.0K ./.nv
8.0K ./.conda
8.0K ./.keras
6.3G ./miniconda3
6.9G
查看内存使用情况,不包含隐藏文件
du -sh *
6.3G miniconda3
5.5M siege-4.0.7
516K siege-4.0.7.tar.gz
查看所有文件包括隐藏文件,总大小
du -sh
6.9G
4.2 删除文件
ubuntu删除文件,快速,不保存在垃圾桶中:
rm -Rvf 文件名
例如:删除垃圾桶内无法删除的文件
sudo rm -Rvf /home/用户名/.local/share/Trash
rm -Rvf /home/用户名/.local/share/Trash
4.3 查看文件目录
显示所有文件
tree
查看文件目录结构,3为深度
tree -L 3