[迁移学习]UniDAformer域自适应全景分割网络
原文的标题为:UniDAformer: Unified Domain Adaptive Panoptic Segmentation Transformer
via Hierarchical Mask Calibration,发表于CVPR2023。
一、概述
域自适应全景分割是指利用一个或多个相关域中的现成标注数据来缓解语义分割数据标注复杂的问题。本文提出了一种UniDAformer域自适应全景分割网络,其基于Transformer,可以用一个统一的架构同时实现域自适应实例分割和语义分割。
通过引入分层掩膜校准(HMC),UniDAformer可以实现在线自我训练。本网络具有以下几个特点:
①使用一个统一架构实现域自适应全景分割
②减少了错误预测
③可以实现端到端的训练和推理
相较于传统的域自适应网络(二分支,下图(a)),UniDAformer(单一分支,下图(b))仅需要一个单一网络即可实现域自适应分割的任务,极大的减少了训练和推理的难度(减少了一个分支的参数量)。
![[迁移学习]UniDAformer域自适应全景分割网络_第1张图片](http://img.e-com-net.com/image/info8/119cceb1309648339715206f83f80c92.jpg)
本文涉及到三个领域:
①Panoptic Segmentation(全景分割):为每一个像素分配语义类别和唯一标识。
②Unsupervised Domain Adaptation(无监督域自适应,UDA):利用已标记的源于数据来学习未标记的目标域数据。
③Self-training(自训练):一种主流的无监督域自适应技术,具体做法是利用伪标签重新训练网络。
二、模型&方法
1.损失函数
源域记作:![]() ;目标域记作
;目标域记作![]() ;交叉熵损失函数可以定义为:
;交叉熵损失函数可以定义为:![]() (仅使用源域进行训练)
(仅使用源域进行训练)
2.无监督训练
![[迁移学习]UniDAformer域自适应全景分割网络_第2张图片](http://img.e-com-net.com/image/info8/48592775d50d42c3bcdcc0e2844742ae.jpg)
整个无监督训练分为两个数据流:使用动量模型![]() 校准伪模板;使用校准后的模型G进行无监督训练(使用自训练损失函数
校准伪模板;使用校准后的模型G进行无监督训练(使用自训练损失函数![]() )。
)。
具体做法为:
①将未标记的图片 输入动量模型
输入动量模型![]() 中,生成一组伪掩码
中,生成一组伪掩码![]() ;
;
②将伪掩码![]() 发送到HMC模块(分层掩码校准模块,Hierarchical Mask Calibration)中,生成校准后的伪掩码
发送到HMC模块(分层掩码校准模块,Hierarchical Mask Calibration)中,生成校准后的伪掩码![]() ,HMC模块会由粗到精校准伪掩码;
,HMC模块会由粗到精校准伪掩码;
③将图像和校准后的伪掩码![]() 进行扩充(变形、裁切、缩放等),得到
进行扩充(变形、裁切、缩放等),得到![]() 和
和![]() ;
;
④使用自训练损失函数![]() 来训练模型
来训练模型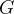
其中动量模型![]() 为
为![]() ,
, 为动量系数。
为动量系数。
3.分层掩码校准(HMC)
HMC将物体和其预测(things and stuff predictions)统一视为掩码,并由粗到细对每层的掩码进行校正。校准分为三个阶段:区域、超像素、像素。
①区域校准(Region-wise Calibration)
通过重新加权类别概率来调整掩码类别;其使用的公式为:
![]() ;其中
;其中![]() 为类别概率,
为类别概率, 为逐元素乘,
为逐元素乘,![]() 表示每个伪掩膜的概率的校准权重(对应第c类),权重
表示每个伪掩膜的概率的校准权重(对应第c类),权重 的计算公式为:
的计算公式为:
![]() ;其中,
;其中,![]() 为区域特征向量,
为区域特征向量,![]() 为特征向量第
为特征向量第 个质心
个质心![]() 的距离,
的距离,![]() 为L1距离。
为L1距离。
其中区域特征向量![]() 使用全局平均池化GAP,将特征掩码
使用全局平均池化GAP,将特征掩码 内的特征汇聚成区域向量
内的特征汇聚成区域向量![]() ,公式如下:
,公式如下:
![]() ,其中
,其中![]()
其中质心![]() 的计算公式为:
的计算公式为:
![]() ;其中
;其中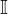 为指示函数,当向量
为指示函数,当向量![]() 属于类时返回1,不属于时返回0;
属于类时返回1,不属于时返回0;
可以使用动量模型更新质心:
![]() ;其中
;其中![]() 为更新系数。
为更新系数。
②超像素校准(Superpixel-wise Calibration)
利用超像素黏附周围物体的边界特征来调整掩码性状;首先计算图片的超像素图![]() (其中包含
(其中包含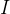 个超像素
个超像素![]() ),然后选择原始掩码
),然后选择原始掩码![]() 中的超像素来生成修正后的掩码
中的超像素来生成修正后的掩码![]() ,可以表述为公式:
,可以表述为公式:
![]() ;该公式会选出与掩码模型重叠的超像素,工作模式如下图的(b)、(c)所示:
;该公式会选出与掩码模型重叠的超像素,工作模式如下图的(b)、(c)所示:
![[迁移学习]UniDAformer域自适应全景分割网络_第3张图片](http://img.e-com-net.com/image/info8/0bbb5725043346738cd76c2c5445c0a2.jpg)
③像素校准(Pixel-wise Calibration)
引入像素级分类信息,使用像素级投票机制调整掩膜边界;如上图中的(d)所示,当超像素![]() 中多数像素的特征向量与伪掩码总体类别不一致时,抛弃该超像素。可以表述为公式:
中多数像素的特征向量与伪掩码总体类别不一致时,抛弃该超像素。可以表述为公式:
![]()
三、网络优化
自训练损失函数![]() 可以表示为:
可以表示为:![]() ;其中
;其中 为匈牙利损失函数。
为匈牙利损失函数。
总体损失函数由最小化监督损失函数![]() 和非监督损失函数
和非监督损失函数![]() 共同决定。可以表述为:
共同决定。可以表述为:
![]()