自定义类型【结构体】详详详详解!
文章目录
- 结构体 - 前言
-
- 结构体的基础知识
-
- 结构体的声明
-
- 结构体变量的定义与初始化
- 结构体的特殊声明
- 结构体的自引用
- 结构体内存对齐
- 修改默认对齐数
- 结构体传参
- 总结
结构体 - 前言
如题目所言,本章介绍结构体;
结构体是一种集合,集合内的各个元素被亲切的称为结构体成员;
同时,结构体成员都可以是不同类型的变量。
除了结构体,数组也是一种集合,与之不同的是,
结构体这个集合内的成员可以是不同类型的变量,而数组是相同数据的集合。
结构体的基础知识
正如前言所介绍,结构体是一种存放不同类型变量的集合,且集合内的各个变量被亲切的称为“结构体成员”。
结构体的声明
在使用结构体前,必须对结构体进行声明。
//<创建一个学生的结构体类型>
#include如上,即为结构体的声明。
在语法中规定,结构体的声明为:
struct tag
{
member - list;
}varible -list;
只要细心就会发现在结构体声明时末尾都会跟着一个 " ; " 作为结束。
该处为类型的声明,与函数的函数体与之相异;
我们可以将 int ; 与结构体的声明作为比较就能找到其规律;
结构体在声明时,既可声明在主函数内部,也可声明在主函数外部;
而大部分的习惯而言,一般声明在主函数外部。
当然,在结构体声明的末尾处可以再定义变量,如:
#include结构体变量的定义与初始化
结构体只是一个类型,既然为一个类型,可以创建该类型相应的变量吗?
答案是可以,对应的,该变量就被称为结构体变量;
结构体变量可定义在主函数的内部(局部变量),也可定义在主函数外部(全局变量);
同时,声明结构体时定义的结构体变量也为全局变量。
通常,结构体的类型名会比较长,为了方便使用,也可利用typedef进行类型重命名;
#include结构体的特殊声明
在结构体的声明中,除了结构体的声明以外,我们还需要了解一个结构体的特殊声明;
即匿名结构体声明:
struct
{
int a;
char c;
}c1,c2,c3;
int main()
{
return 0
}
在上述的结构体声明中,与普通结构体不同的是,他与普通结构体之间少了结构体的标签名,顾名思义,为匿名结构体类型;
该类型的结构体,往往可以当作一次性用品,若是想创建一个只能用一次的结构体类型,即可使用匿名结构体;
为什么为“一次性用品”?
因为该结构体因为没有明确的标签名,故不能作为变量的类型名;
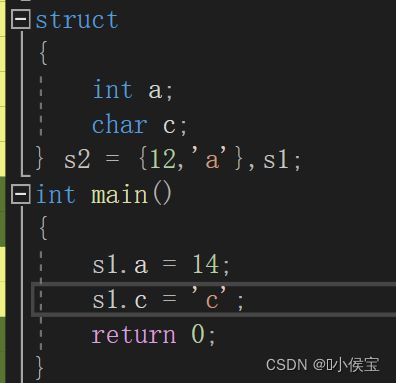
为了避免创建匿名结构体后不能继续使用,可以使用 typedef 关键字将匿名结构体进行类型名重定义。
typedef struct
{
int a;
char c;
} CC;
typedef struct
{
int s;
char b;
} DD;
int main()
{
CC c1 = { 12,'c' };//重定义后的匿名结构体可以继续使用
DD d1 = { 11,'s' };
return 0;
}
下面的代码是否能成功运行?
struct
{
int i;
char c;
}p;
struct
{
int i;
char c;
}*py;
int main()
{
py = &p;
return 0;
}
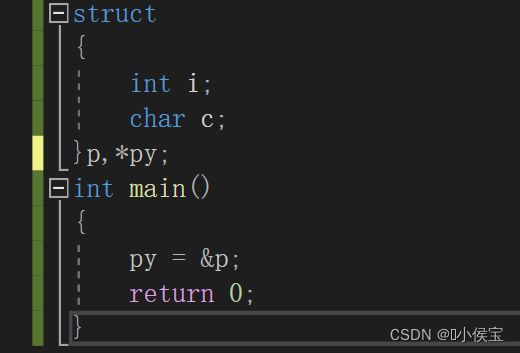
创建一个匿名结构体,再创建一个相同构造的匿名结构体指针,将该结构体的地址存放至结构体指针变量内是否可行,或者换另一种说法,他们的类型是否相同?
当我们换在编译器里试着编译时会发现:

实际上两者类型并不相同,换句话来说,这两个匿名结构体是两个不同的结构体类型,所以是非法的。
若是需要创建一个匿名结构体指针变量来接收该结构体类型变量的地址时,只需在匿名结构体声明后定义指针变量即可;
结构体的自引用
在数据的存储中,可以使用顺序表的形式对数据进行存放;
顺序表,是计算机内存储存数据的一种方式;
即用一组地址连续的存储单元依次存储线性表中的各个元素;
而除了顺序表以外,还可以使用非顺序的形式的链表的方式对数据进行存储;
即使用不同的地址分别对数据进行存储,链表内的各个数据称为 “ 节点 ” ;
当需要使用或查找某个数据时,只需找到最初的节点即可访问需要访问的数据;
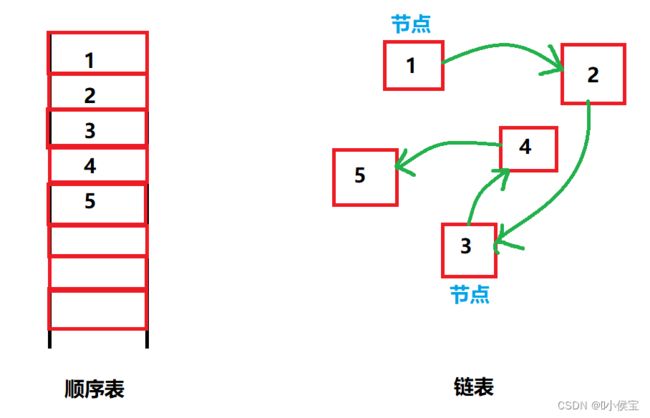
链表与顺序表都是以线性的方式对数据进行存储。
若是使用结构体,如何创建一个简单的链表?
struct Node
{
int date;
struct Node next;
};
上面的代码为创建一个结构体,并对结构体进行自引用达到通过一个数据访问下一个数据。
当使用该代码进行编译时,编译器将会报错✖️;
原因是无论是什么结构体,结构体都会有大小,而且结构体的大小根据结构体内的数据而变化;
若是如此进行编译,在结构体内部的结构体变量还存在着一个结构体,周而复始,程序将会像死递归一样不停调用该结构体;
故该段代码为错误示范✖️。
正确示范✔️:
struct Node
{
int date;
struct Node *next;
}p1 = {0}, p2 = { 0 }, p3 = { 0 };
int main()
{
p1.date = 1;
p2.date = 2;
p3.date = 3;
p1.next = &p2;
p2.next = &p3;
p3.next = NULL;
return 0;
}
若是在结构体内调用同类型的结构体指针则可以避免该问题;
原因是无论是什么类型的指针,大小也只有4/8个字节的大小,且不能通过指针直接访问下一个结构体的结构体变量。
那么使用匿名结构体能否创建链表:
匿名结构体没有明确的标签名,即声明不完全,
如果想试一下的话可以使用typedef对匿名结构体类型进行类型重命名:

答案很明确,当使用匿名结构体创建链表时,若是不使用typedef则没有标签名;
无法创建链表,而使用typedef时又存在一个先后顺序问题:
typedef在进行类型重命名时,首先的前提是被重命名的类型为一个完整的类型;
而该结构体并未完全声明时在结构体内部就已经存在了 Node*next ; 指针。
明显当若想使用匿名结构体创建链表时,请抛弃这个想法。

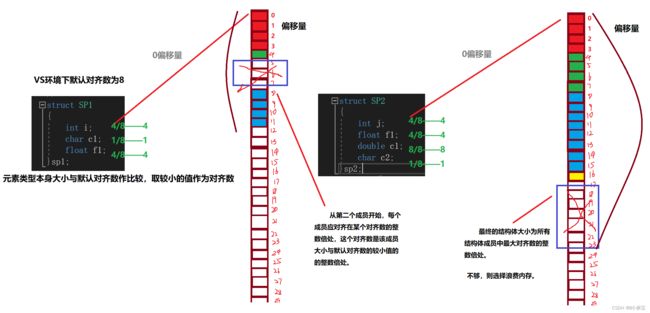
结构体内存对齐
在声明结构体的时候,往往不同结构体成员不同,结构体的大小也不同,若是存在以下结构体,相应的他们的大小是多少?
struct SP1
{
int i;
char c1;
float f1;
}sp1;
struct SP2
{
int j;
float f1;
double c1;
char c2;
}sp2;
int main()
{
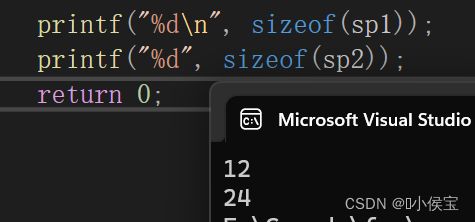
printf("%d\n", sizeof(sp1));
printf("%d\n", sizeof(sp2));
return 0;
}
答案会是什么?
9 17 ??
这里有一个疑惑,为什么与预想中的结果不太一样?
在这里就涉及到了一个问题,即结构体的内存对齐:
在结构体中数据是按照定义顺序一个一个放到内存中去的,但并不是紧密排列的。
每个数据都有对应的对齐数,这个对齐数是这个数据类型的大小,例如:
int类型的对齐数为4
folat类型的对齐数为4
char类型的对齐数为1
且在上面所述数据并不是紧密排列的。
内存对齐的规则:
-
结构体的第一个成员永远放在0偏移处;
-
从第二个成员开始,以后的每个成员要对齐到某个对齐数的整数倍处
而这个对齐数为,成员自身大小和默认对齐数之间的较小值(vs默认对齐
数为8,gcc环境下没有默认对齐数,没有默认对齐数时,对齐数就为成
员自身大小); -
当结构体成员全部存放进结构体时,结构体的总大小必须是所有成员
的对齐数中最大对齐数的整数倍,如果不够,则浪费空间进行对齐; -
当结构体内嵌套着一个结构体时,该结构体的存放位置为本身内部成
员中最大对齐数的整数倍处结构体总体大小为,所有的成员的对齐数
(包括被嵌套的结构体内部)的整数倍
根据上述规则则可以摸出为什么得数为12,24;
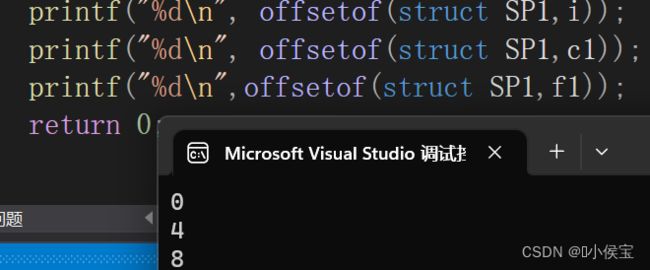
在这里可以使用offsetof宏来观察各个成员对于首地址的偏移量(当使用offsetof来求偏移量时,应包含stddef.h文件)。
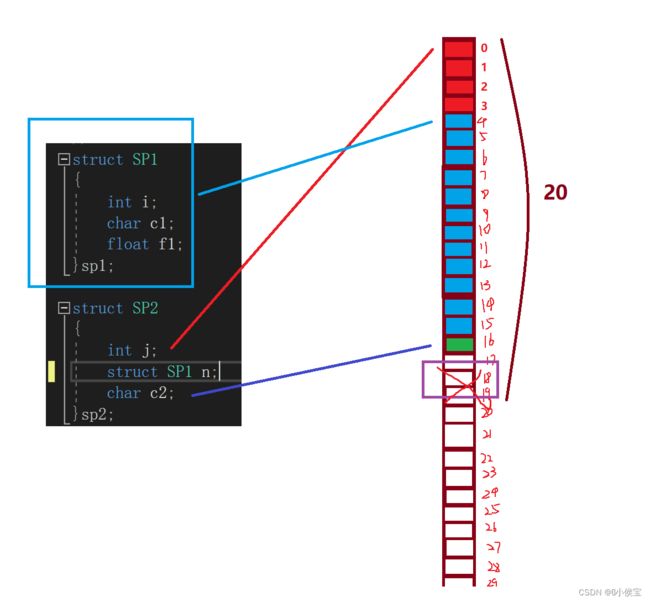
且当结构体内还嵌套着另一个结构体时,该结构体的偏移量为该结构体中内部最大对齐数的整数倍处;
用另一种解释即为,当需要确定该种结构体的起始位置时应将该结构体进行展开进行计算。
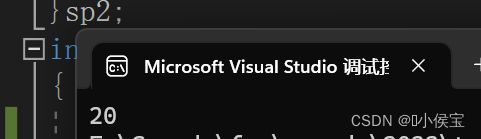
这里要插一嘴;
为什么存在内存对齐?
存在两个原因:
- 平台原因
内存对齐的原因是因为不是所有的硬件平台都能访问任意地址上的数据。 - 性能原因
数据结构(尤其是栈)应尽可能的在自然边界上对齐,否则为了访问未对齐的内存,处理器需要作两次访问。
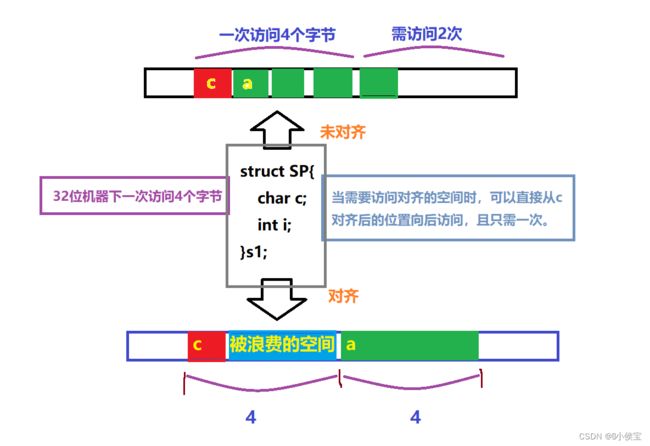
通俗的来说就是以空间来换时间(更高效的运行速度)。
修改默认对齐数
若是觉得在某些场景下,觉得使用默认对齐数依旧浪费空间太多不想进行内存对齐该怎么办?
当觉得默认对齐数不合理时,可以使用预处理指令#pragma修改默认对齐数;
#pragma - 预处理指令
改动当前环境的默认对齐数;
- #pragma pack( 1 )
将当前环境的默认对齐数改为1(不进行内存对齐);
- #pragma pack( )
取消设置的默认对齐数,即还原默认对齐数。
一般来说,设置默认对齐数时尽量选择2的次方进行设置。
#include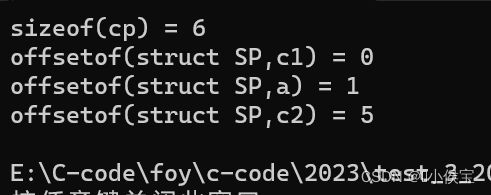
结构体传参
结构体变量既然为变量,那肯定能在函数内进行传参,若是存在以下两个函数;
哪个函数会好一些?
#include上段代码中存在两个函数
- void print1(struct SP ssp)
- void print2(struct SP* ssp)
print1函数为传值输入;
print2函数为传址输入;
在大部分情况下,应选择print2函数;
- 因为函数在传参时会出现压栈,会出现时间与空间上的开销;
- 若是传入的参数数值较大时,传值输入的时间与空间上的开销会变得更大;
- 而传址输入时,需要传输的数据最多为4或者8个字节;
- 故当需要进行结构体传参时,应尽量选择传输结构体的地址;
总结
以上即为自定义类型结构体的详详详详解!
各位佬佬若是觉得有帮助的话,就请给文章留个赞叭!
若有不足之处也希望各位佬佬能指点迷津!
