多元数据时代,如何破解数据流转难题?

在数字化转型的推动下,数据作为重要的生产要素,其价值被重新定义,越来越多企业开始重视数据资源的价值。
但随着数据量的不断增多、数据类型的不断丰富以及应用系统的逐渐增加,数据整体通用性和数据一致性管理成本大大增加,进而影响到整个系统的使用。因此,如何通过简单的操作方式便可调用多种数据库的资源,尽量减少数据转换操作,成为当下最迫切的需求,尤其是利用湖仓一体架构解决多模数据的处理分析,就此成为一种新的趋势。
针对传统数据仓库管理存在的问题,HashData采用湖仓一体架构,能够实现数据仓库和数据湖的数据无缝打通和自由流动,减少重复建设,最大化降低数据转换和迁移成本。
背景及挑战
近年,随着互联网以及物联网等技术的不断发展,越来越多的数据被生产出来,数据管理工具也得到了飞速发展。这些数据类型多种多样,为了满足这些海量数据的存储、计算与分析,传统做法是同时应用十几个不同的数据库产品来分别满足相应的需求。
传统数据仓库对数据模型有严格的要求,在数据导入到数据仓库前,数据模型就必须事先定义好,数据必须按照模型设计存储。所以,数据规模和数据类型的限制,导致传统数据仓库无法支撑互联网时代的商业智能。
随着数字化进程加快,企业需要更完善的配套服务来减少数据迁移复杂度,降低成本、保障数据安全。多元数据库的格局,极大的促进了社会经济的发展,但同时也带来了数据库运维管理上的难题,如何更好的管理多元数据库,成为行业亟待解决的难题。
数据库多元化带来的管理难点
安装部署过程复杂
传统数据库环境准备,需要用户自行准备存储、网络、计算资源,协调系统、网络、数据库等各方专家,才能完成一套可用的数据库集群部署。
数据库管理难度大
传统数据库管理依赖于数据库厂商自带的管理工具,而今数据库越来越多样化,不同类型的数据库管理、监控、运维需要学习不同的管理工具,运维的学习成本和工具使用的切换成本提升使得运维难度极大。
容灾架构实现困难
数据库备份或高可用架构需自行手工搭建或编写脚本,实现难度极大,且出错概率较高。在生产数据库出现故障时,备份容灾平台无法快速接管业务。
对于数据库多元化带来的部署复杂、管理困难等问题,国内外的数据库行业相关厂商都提出了各自的解决方案。但这些解决方案都存在着一些不足,数据库高可用的安装部署依旧是企业的一大风险。
湖仓一体赋能数据流通
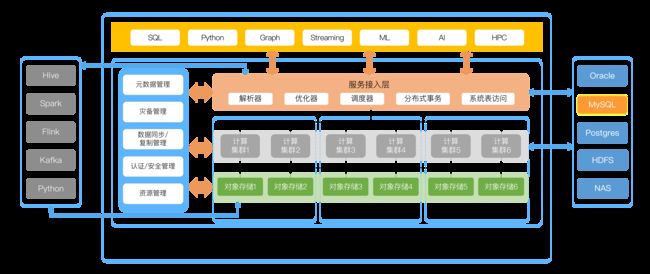
HashData云原生数据仓库系统架构
在一个多元数据的时代,我们致力于构建一个开放的数据存储、计算和连接平台。HashData内置表的数据持久化到对象存储,能够提供SQL、Python、图计算、流式计算、机器学习和人工智能等多种分析功能,同时还以连接器(connector)的方式让第三方开源计算框架能够非常方便和高效地访问HashData的数据,包括Hive、Spark、Flink、Kafka等。
针对目前多元数据库运维管理带来的痛点,HashData云数据仓库提供了多种灵活的数据入库方式,支持MySQL、ORACLE、Python、Postgres、NAS、HDFS等多种数据源的数据导入,并自动完成数据格式转换,助力用户轻松上云,帮助用户提高转换率、降低数据库迁移成本。
各种数据源导入方式具有不同的特点。以目前使用广泛的MySQL数据库为例,HashData兼容MySQL Data Wrapper(mysql_fdw)开源工具 。这个扩展工具可以将PostgreSQL数据库发起的对MySQL数据库的增删查改操作转为MySQL数据库可以解释执行的语句,在MySQL端运行并返回结果。
具体操作如下:
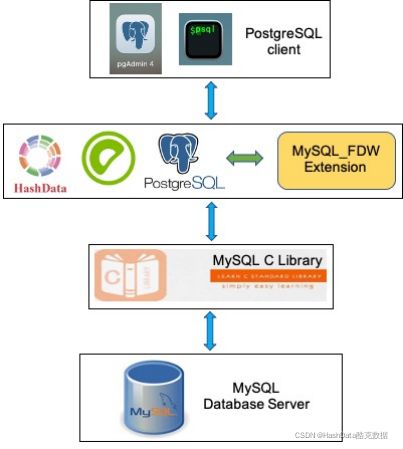
安装要求
HashData数据仓库3x版本
源码获得
PostgreSQL源码9.4.24
MySQL源码
MySQL 5.7.28
MySQL data wrapper
可以使用的是Greenplum 6x的兼容版本
环境准备
安装HashData数据库 (兼容GP6x)
下载的源代码解压缩到同一目录下
# ls
mysql-5 .7 .28-linux-glibc2 .12-x86_64 mysql_fdw_greenplum-master postgresql-9.4.24
编译安装
安装gcc
yum install gcc
编译安装PostgreSQL
# make
make[1]: 进入目录“/root/manual/postgresql-9.4.24/config”
make[1]: 对“all”无需做任何事。
make[1]: 离开目录“/root/manual/postgresql-9.4.24/config”
All of PostgreSQL successfully made.Ready to install .
# make install
...
make -C config install
make[1]: 进入目录“/root/manual/postgresql-9.4.24/config”
/usr/bin/mkdir -p '/usr/local/pgsql/lib/pgxs/config'
/usr/bin/install -c -m 755 ./install-sh
'/usr/local/pgsql/lib/pgxs/config/install-sh'
/usr/bin/install -c -m 755 ./missing '/usr/local/pgsql/lib/pgxs/config/missing'
make[1]: 离开目录“/root/manual/postgresql-9.4.24/config”
PostgreSQL installation complete .
编译安装mysql_fdw
$ export PATH=/home/gpadmin/manual/postgresql-9.4.24/src/bin:$PATH
$ export PATH=/home/gpadmin/manual/mysql-5.7.28-linux-glibc2.12-x86_64/bin:$PATH
$ make USE_PGXS=1
$ make USE_PGXS=1 install
拷贝文件到指定目录
# cp mysql_fdw .so /opt/gpsql/lib/postgresql/
# cp mysql_fdw .control /opt/gpsql/share/postgresql/extension/
# cp * .sql /opt/gpsql/share/postgresql/extension/
# cp /usr/lib64/mysql/libmysqlclient .so /opt/gpsql/lib
PG创建插件
db395=# CREATE EXTENSION mysql_fdw;
CREATE EXTENSION
postgres=# \dx mysql_fdw
List of installed extensions
Name | Version | Schema | Description
-----------+---------+--------+-------------------------------------------------
mysql_fdw | 1.1 | public | Foreign data wrapper for querying a MySQL server
验证测试
1.创建链接server源
db395=# CREATE SERVER mysql_server FOREIGN DATA WRAPPER mysql_fdw OPTIONS (host'192.168.192.168 ', port '3306');
CREATE SERVER
2.添加用户的映射
db395=# CREATE USER MAPPING FOR gpadmin SERVER mysql_server OPTIONS (username 'duy', password 'duy');
CREATE USER MAPPING
3.创建映射外部表
db395=# CREATE FOREIGN TABLE test_fdw(a int,b text) SERVER mysql_server OPTIONS(dbname 'test', table_name 'test_dblink');
CREATE FOREIGN TABLE
4.查看访问MySQL表的执行计划
db395=# explain verbose select * from test_fdw;
QUERY PLAN
----------------------------------------------------
Foreign Scan on public .test_fdw (cost=25 .00 . .1025 .00 rows=1000 width=36)
Output: a, b
Remote server startup cost: 25
Remote query: SELECT `a`, `b` FROM `test` . `test_dblink`
Optimizer: Postgres query optimizer
(5 rows)
总结与展望
数字化进程不断提速,企业需要更完善的技术服务来减少数据迁移复杂度,降低成本。
HashData采用湖仓一体化架构,可以方便、快捷地将大量数据从数仓转移至成本更低廉的数据湖内,同时这些移到湖里的数据,仍然可以被数仓查询使用。
在实际业务场景中,数据的移动不只是存在于数据湖和数据仓库之间,湖仓一体不仅需要把数仓和数据湖集成起来,还要让数据在服务之间按需流动。
HashData通过多种领先性技术,实现海量数据自动化转换迁移,降低用户迁移难度与成本,为企业数字化转型保驾护航。
目前,HashData已广泛应用于金融、电信、交通等行业,服务超过50家行业客户。未来,HashData将携手更多合作伙伴联合创新,为客户持续打造管理省心、迁移放心的数据库服务。