酷克数据的数据仓库(olap数据库)架构变迁学习笔记
原文:数据仓库架构的变迁
主要疑问是,如何解决OLAP低延迟、高并发以及扩展性问题。
postgresql
酷客数据的数据库均是基于postgresql数据库进行开发的,Greenplum Database(大规模并行处理(MPP)数据库),Apache HAWQ(SQL on Hadoop解决方案)以及HashData云端数据仓库,都是基于单机版关系型数据库PostgreSQL的。
每个PostgreSQL数据库的实例包含一个PostMaster的damon进程和多个子进程,包括负责写出脏数据的BG Writer进程,收集统计信息的Stats Collector进程,写事务日志的WAL Writer进程,等等。Postgres Server进程的功能组件可以分成两大类:查询执行和存储管理。查询执行组件包括解析器、分析器、优化器以及执行器。在查询执行过程中,需要访问和更新系统状态和数据,包括缓存,锁,文件和页面等等。
关于pg的主进程和各个子进程的功能,我去搜了一下相关的文章介绍:PostgreSQL进程和内存结构

Greenplum,大规模并行处理(MPP)数据库

随着数据量的增大,基于单机PostgreSQL构建的数据仓库就无法满足企业用户对查询响应时间的要求:低延迟。为了解决这个问题,MPP架构就被引入了。MPP数据库通过将数据切片分布到各个计算节点后并行处理来解决海量数据分析的难题。
MPP一个主节点,多个计算节点。计算节点负责数据的存储以及查询计划的执行。计算节点之间是没有任何共享依赖的(shared nothing)。查询在每个计算节点上面并行执行,大大提升了查询的效率。
Greenplum Database是如何执行一条查询的

这是一条简单的两表等值连接语句。在这个例子中,我们可以认为它的表数据是round-robin的方式随机分布的,不影响查询的执行。每个查询执行是一个由操作符组成的树。我们首先会将两表的数据分别扫描出来,然后基于维度表customer建立hash桶。对于每一条从sales表扫描出来的纪录,我们都会到hash桶去查。如果满足匹配条件,数据连接结果;否则,直接pass。
对于这样一个并行的查询计划,我们会根据数据重分布的操作将整棵查询执行树切割成不同的子树。每个子树对应查询计划的一个阶段,我们称为slice。查询计划和slice是逻辑上的概念。在物理层面,对应的是并行执行计划和gang。gang指的是执行同一个slice操作的一组进程。

个人理解他的查询,就是所有计算节点上的表数据先合并成各自的大表,然后在最后在合并成一个结果表,不是很明白为什么要这么做,感觉二叉树来弄需要的次数会更少?
一般来说,对于N张表的关联操作,执行计划中会包含2N个gang,其中1个1-gang,对应主节点上面的进程;2N-1个N-gang,对应每个计算节点上面启动的2N-1个QE进程。在这2N-1个gang中,其中N个用于扫描N张表,中间N-1个gang用于两表关联。也就是说,对于一条涉及到N表关联操作的查询语句,我们需要在每个计算节点上面启动2N-1个QE进程。
从资源使用的角度看,计算节点会首先成为瓶颈。因为在执行涉及多表关联的复杂查询时,计算节点上面启动的进程数量会远多于主节点。所以,Greenplum Database系统架构决定了它不能支持非常高的并发访问。
Greenplum Database的重要组件
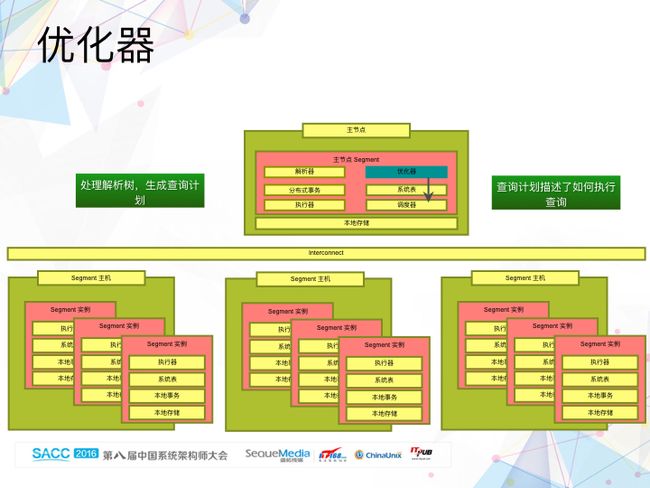
首先是解析器。
从使用者的角度看,Greenplum Database跟PostgreSQL没有明显差别。对于每一条进来的查询语句,QD进程(Postgres Server)中的解析器执行语法分析和词法分析,生成解析树。
然后是优化器。
优化器根据解析器生成的解析树,生成查询计划。从PostgreSQL到MPP架构的Greenplum Database,优化器做了重大改动。虽然两者都是基于代价来生成最优的查询计划,但是Greenplum Database除了需要常规的表扫描代价、连接和聚合的执行方式外,还需要考虑数据的分布式状态、数据重分布的代价,以及集群计算节点数量对执行效率的影响,因为它最终是要生成一个分布式的查询计划。
调度器。
调度器是Greenplum Database在PostgreSQL上新增的一个组件,负责分配处理查询需要的计算资源,将查询计划发送到每个计算节点。调度器根据优化器生成的查询计划确定执行计划需要的计算资源,然后通过libpg(修改过的libpg协议)协议给每个Segment实例(计算节点)发送连接请求,通过Segment实例(计算节点)上的PostMaster进程fork出QE进程(Postgres Server进程)。调度器同时负责这些fork出来的QE进程的整个生命周期。
执行器。
计算节点接收到从调度器发送过来的查询计划之后,通过执行器执行分配给自己的任务。除了增加一个新的称谓Motion的操作节点(负责不同QE进程间的数据交换)之外,总体上看,Greenplum Database的执行器跟PostgreSQL的执行器差别不大。
数据交换组件Interconnect。
在Greenplum Database系统架构中,我们引入了Interconnect组件负责数据交换,作用类似于MapReduce中的shuffling阶段。不过与MapReduce基于HTTP协议不一样,Greenplum Database出于数据传输效率和系统扩展性方面的考虑,实现了基于UDP协议的数据交换组件。前面在解析执行器的时候提到,Greenplum Database引入了一个叫Motion的操作节点。Motion操作节点就是通过Interconnect组件在不同的计算节点之间实现数据的重分布。
跟系统状态相关的组件,系统表。
系统表负责存储和管理数据库、表、字段等元数据。主节点上面的系统表是全局数据库对象的元数据,称为全局系统表;每个Segment实例上也有一份本地数据库对象的元数据,称为本地系统表。由于系统表分布式地存储在不同的节点中,如何保持系统表中信息的一致性是极具挑战的任务。一旦出现系统表不一致的情况,整个分布式数据库系统是无法正常工作的。
分布式事务。
跟很多分布式系统一样,Greenplum Database是通过分布式事务来确保系统信息一致的,更确切地说,通过两阶段提交来确保系统元数据的一致性。主节点上的分布式事务管理器协调Segment节点上的提交和回滚操作。每个Segment实例有自己的事务日志,确定何时提交和回滚自己的事务。本地事务状态保存在本地的事务日志中。
Greenplum Database如何提供高可用性

首先是管理节点的高可用。
启动一个称为Standby的从主节点作为主节点的备份,通过同步进程同步主节点和Standby节点两者的事务日志,在Standby节点上重做系统表的更新操作,从而实现两者在全局系统表上面的信息同步。当主节点出故障的时候,我们能够切换到Standby节点,系统继续正常工作,从而实现管理节点的高可用。
计算节点高可用性的实现类似于管理节点 。
每个Segment实例(计算节点)都会有另外一个Segment实例作为备份。处于正常工作状态的Segment实例我们称为Primary,它的备份称为Mirror。不同于管理节点日志重放方式,计算节点的高可用是通过文件复制。对于每一个Segment实例,它的状态以文件的形式保存在本地存储介质中。这些本地状态可以分成三大类:本地系统表、本地事务日志和本地表分区数据。通过以文件复制的方式保证Primary和Mirror之间的状态一致,我们能够实现计算节点的高可用。
HAWQ
随着Hadoop的兴起,特别是HDFS的成熟,越来越多的数据被保存在HDFS上面。我们怎样才能高效地分析保存在HDFS上面的数据,挖掘其中的价值?我们希望让HDFS,而不是本地存储,成为MPP数据库的数据持久层。这就是后来的Apache HAWQ项目。
当时的想法非常简单,就是将Greenplum Database和HDFS部署在同一个物理机器集群中,同时将Greenplum Database中的Append-only表的数据放到HDFS上面。Append-only表指的是只能追加,不能更新和删除的表,这是因为HDFS本身只能Append的属性决定的。
Greenplum Database的本地存储分成四大类:系统表、日志、Append-only表分区数据和非Append-only表分区数据。我们将其中的Append-only表分区数据放到了HDFS上面。每个Segment实例对应一个HDFS的目录,非常直观。其它三类数据还是保存在本地的磁盘中。
Greenplum on HDFS作为一个原型系统,验证了MPP数据库和HDFS是可以很好地整合起来工作的。基于这个原型系统,我们开始将它当成一个真正的产品来打造,也就是后来的HAWQ。
HAWQ希望将计算节点的本地状态彻底去掉。本地状态除了前面提到的系统表(系统表又可以细分成只读系统表(系统完成初始化后不会再发生更改的元数据,主要是数据库内置的数据类型和函数)和可写系统表(主要是通过DDL语句对元数据的修改,如创建新的数据库和表))、事务日志、Append-only表分区数据和非Append-only表分区数据,同时还有系统在执行查询过程中产生的临时数据,如外部排序时用到的临时文件。其中临时数据和本地只读系统表的数据都是不需要持久化的。我们需要考虑的是如何在Segment节点上面移除另外四类状态数据。
通过修改DDL,HAWQ彻底禁止用户创建Heap表,因为Heap表支持更新和删除。通过为每个Append-only表文件对应的元数据增加一列,逻辑EoF,即有效的文件结尾。只要能够保证EoF的正确性,我们就能够保证事务的正确性。为了清理Append-only表文件在追加新数据时事务abort造成的脏数据,我们实现了HDFS Truncate功能。
对于本地可写系统表,我们的做法是将Segment实例上面的本地可写系统表放到主节点的全局系统表中。这样主节点就拥有了全局唯一的一份系统表数据。查询执行过程中需要用到的系统元数据,我们通过Metadata Dispatch的方式和查询计划一起分发给每个Segment实例。
在HAWQ 1.x的阶段,我们做到了计算和存储物理上的分离,但是逻辑上两者还是集成的。HDFS数据跟计算节点逻辑上的集成关系,使得HAWQ 1.x版本依然没有摆脱传统MPP数据库刚性的并发执行策略:无论查询的复杂度如何,所有的计算节点都需要参与到每条查询的执行中。这种刚性的并行执行策略,极大地约束了系统的扩展性和吞吐量,同时与Hadoop基于查询复杂度来调度计算资源的弹性策略也是相违背的。
HAWQ 2.0 计算和存储不仅物理上分离,逻辑上也是分离。数据库中的用户表数据在HDFS上不再按照每个Segment单独来组织,而是按照全局的数据库对象来组织。

左边展现的是HAWQ 1.x在同时处理三个查询(分别来自三个不同的会话)时的资源调度情况。一个4个节点的HAWQ集群能够支持的并发查询数量和一个400个节点的集群是一样的。
右边展现的是HAWQ 2.0在同样并发查询下的资源调度情况。能够根据查询的复杂度决定需要调度多少计算资源参与到每条查询的执行中。计算资源的数量可变和计算资源的位置可变,正是HAWQ 2.0弹性执行引擎的核心。 在这种情况下,系统能够支持的并发查询数量,跟集群的计算节点数量呈线性关系:计算节点越多,系统能够支持的并发查询数量越多。
云端数据仓库

通过将计算和存储彻底分离成功解决了计算节点成为系统吞吐量瓶颈的问题后,现在系统的唯一瓶颈就剩下主节点。
主节点的功能主要分成两类:元数据管理,包括系统表存储和管理、锁管理和分布式事务等等,和计算资源调度管理和执行。
前者我们可以看成是状态管理,后者是没有状态的组件。通过将状态管理提取出来成为单独一个功能层,我们让主节点跟计算节点一样变得没有状态。这样,我们能够根据系统并发查询的变化,动态增加或者减少主节点的数量。
在这个系统架构中,我们将管理即元数据、计算和存储三者分离了,每一层都能单独动态伸缩,在解决系统吞吐量和扩展性问题的同时,提供了多维度的弹性。
云平台的对象存储服务在可扩展性、稳定性和高可用性等方面远胜于我们自己维护的分布式文件系统(如HDFS)。虽然对象存储的访问延迟远高于本地磁盘访问,但是我们可以通过本地缓存的策略很大程度减轻延迟问题。
同样的,我们利用云平台提供的虚拟机作为我们的计算资源,也能够一定程度上实现资源的隔离,从而保证不同的工作负载之间没有相互影响。
云平台提供的近乎无限的计算和存储资源(相对于数据仓库应用来说),使得云端数据仓库能够存储和处理的数据达到一个全新的高度。
总结

当参与到查询执行的QE进程达到一定数量的时候,QE进程出错将是必然的,特别是在一个资源共享的环境中。这时候,即使是重新提交查询重跑,失败还是必然的。换句话说,我们几乎无法成功执行需要调度大量计算资源的查询。
展望未来,我们希望实现带检查点的流水式执行引擎,从而使得系统能够处理任意大的查询(单个查询需要同时调度成千上万的计算资源)。