redis 集群配置
1 . 存在的问题
- 单台redis容量限制,如何进行扩容?继续加内存、加硬件么?
- 单台redis并发写量太大有性能瓶颈,如何解决?
- redis3.0中提供了集群可以解决这些问题。
2 . 什么是集群
redis集群是对redis的水平扩容,即启动N个redis节点,将整个数据分布存储在这个N个节点中,每个节 点存储总数据的1/N。
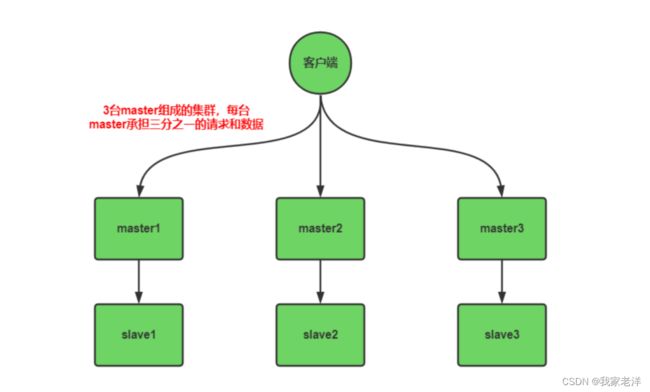
如下图:由3台master和3台slave组成的redis集群,每台master承接客户端三分之一请求和写入的数
据,当master挂掉后,slave会自动替代master,做到高可用。
3 . 集群如何配置?
3.1 需求:
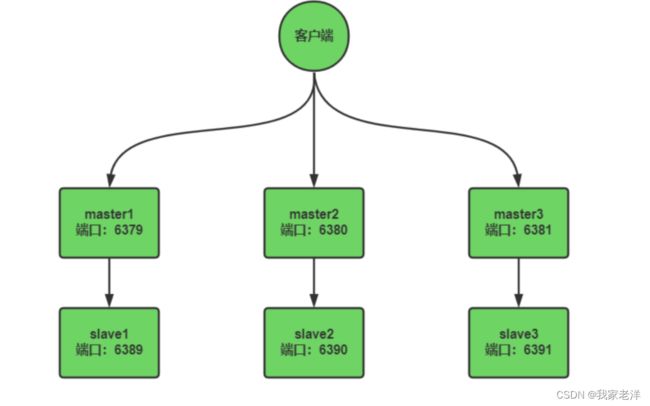
配置3主3从集群 下面我们来配置一个3主3从的集群,每个主下面挂一个slave,master挂掉后,slave会被提升为 master。
为了方便,我们在一台机器上进行模拟,我的机器ip是:192.168.200.129,通过端口来区分6个不同的 节点,配置信息如下
3.2 创建案例工作目录:cluster
执行下面命令创建 /opt/cluster 目录,本次所有操作,均在 cluster 目录进行。
# 方便演示,停止所有的redis
ps -ef | grep redis | awk -F" " '{print $2;}' | xargs kill -9
mkdir /opt/cluster
cd /opt/cluster/
3.3 将redis.conf复制到cluster目录
redis.conf 是redis默认配置文件
cp /opt/redis-6.2.1/redis.conf /opt/cluster/
3.4 创建master1的配置文件:redis-6379.conf
在/opt/cluster目录创建 redis-6379.conf 文件,内容如下,注192.168.200.129 是这个测试机器的 ip,大家需要替换为自己的
include /opt/cluster/redis.conf
daemonize yes
bind 192.168.200.129
dir /opt/cluster/
port 6379
dbfilename dump_6379.rdb
pidfile /var/run/redis_6379.pid
logfile "./6379.log"
#开启集群设置
cluster-enabled yes
#设置节点配置文件
cluster-config-file node-6379.conf
#设置节点失联时间,超过该时间(毫秒),集群自动进行主从切换
cluster-node-timeout 15000
// An highlighted block
var foo = 'bar';
3.5 创建master2的配置文件:redis-6380.conf
在/opt/cluster目录创建 redis-6380.conf 文件,内容如下,和上面master的类似,只是将6379换成 6380了
include /opt/cluster/redis.conf
daemonize yes
bind 192.168.200.129
dir /opt/cluster/
port 6380
dbfilename dump_6380.rdb
pidfile /var/run/redis_6380.pid
logfile "./6380.log"
# 开启集群设置
cluster-enabled yes
# 设置节点配置文件
cluster-config-file node-6380.conf
# 设置节点失联时间,超过该时间(毫秒),集群自动进行主从切换
cluster-node-timeout 15000
3.6 创建master3的配置文件:redis-6381.conf
在/opt/cluster目录创建 redis-6381.conf 文件,内容如下
include /opt/cluster/redis.conf
daemonize yes
bind 192.168.200.129
dir /opt/cluster/
port 6381
dbfilename dump_6381.rdb
pidfile /var/run/redis_6381.pid
logfile "./6381.log"
# 开启集群设置
cluster-enabled yes
# 设置节点配置文件
cluster-config-file node-6381.conf
# 设置节点失联时间,超过该时间(毫秒),集群自动进行主从切换
cluster-node-timeout 15000
3.7 创建slave1的配置文件:redis-6389.conf
在/opt/cluster目录创建 redis-6389.conf 文件,内容如下
include /opt/cluster/redis.conf
daemonize yes
bind 192.168.200.129
dir /opt/cluster/
port 6389
dbfilename dump_6389.rdb
pidfile /var/run/redis_6389.pid
logfile "./6389.log"
# 开启集群设置
cluster-enabled yes
# 设置节点配置文件
cluster-config-file node-6389.conf
# 设置节点失联时间,超过该时间(毫秒),集群自动进行主从切换
cluster-node-timeout 15000
3.8 创建slave2的配置文件:redis-6390.conf
在/opt/cluster目录创建 redis-6390.conf 文件,内容如下
// An highlighted block
include /opt/cluster/redis.conf
daemonize yes
bind 192.168.200.129
dir /opt/cluster/
port 6390
dbfilename dump_6390.rdb
pidfile /var/run/redis_6390.pid
logfile "./6390.log"
# 开启集群设置
cluster-enabled yes
# 设置节点配置文件
cluster-config-file node-6390.conf
# 设置节点失联时间,超过该时间(毫秒),集群自动进行主从切换
cluster-node-timeout 15000
3.9 创建slave3的配置文件:redis-6391.conf
在/opt/cluster目录创建 redis-6391.conf 文件,内容如下
include /opt/cluster/redis.conf
daemonize yes
bind 192.168.200.129
dir /opt/cluster/
port 6391
dbfilename dump_6391.rdb
pidfile /var/run/redis_6391.pid
logfile "./6391.log"
# 开启集群设置
cluster-enabled yes
# 设置节点配置文件
cluster-config-file node-6391.conf
# 设置节点失联时间,超过该时间(毫秒),集群自动进行主从切换
cluster-node-timeout 15000
4 . 启动master、slave1、slave2
# 方便演示,停止所有的redis
ps -ef | grep redis | awk -F" " '{print $2;}' | xargs kill -9
# 下面启动6个redis
redis-server /opt/cluster/redis-6379.conf
redis-server /opt/cluster/redis-6380.conf
redis-server /opt/cluster/redis-6381.conf
redis-server /opt/cluster/redis-6389.conf
redis-server /opt/cluster/redis-6390.conf
redis-server /opt/cluster/redis-6391.conf
5 . 查看6个redis的启动情况
ps -ef | grep redis

6 . 确保node-xxxx.conf文件已正常生成
稍后我们会将6个实例合并到一个集群,在组合之前,我们要确保6个redis实例启动后,nodesxxxx.conf文件都生成正常,如下,
/opt/cluster 目录中确实都生成成功了

7 . 将6个节点合成一个集群
执行下面命令,将6个redis合体
/opt/redis-6.2.1/src/redis-cli --cluster create --cluster-replicas 1
192.168.200.129:6379 192.168.200.129:6380 192.168.200.129:6381
192.168.200.129:6389 192.168.200.129:6390 192.168.200.129:6391
- 合体的命令后面会跟上所有节点的ip:port列表,多个之间用空格隔开,注意ip不要写
127.0.0.1,要写真实ip- –cluster-replicas 1:表示采用最简单的方式配置集群,即每个master配1个slave,6个节点 就形成了3主3从
执行过程如下,期间会让我们确定是否同样这样的分配方式,输入:yes,然后等几秒,集群合体成功
[root@hspEdu01 src]# redis-cli --cluster create --cluster-replicas 1
192.168.200.129:6379 192.168.200.129:6380 192.168.200.129:6381
192.168.200.129:6389 192.168.200.129:6390 192.168.200.129:6391
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.200.129:6390 to 192.168.200.129:6379
Adding replica 192.168.200.129:6391 to 192.168.200.129:6380
Adding replica 192.168.200.129:6389 to 192.168.200.129:6381
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: ccf3abb791e026380ad3ad2a166aa788df738437 192.168.200.129:6379
slots:[0-5460] (5461 slots) master
M: 3c372392d5a91dad64a6febadfe9524ea2cbd8c0 192.168.200.129:6380
slots:[5461-10922] (5462 slots) master
M: 2c905be9c975be367bd66c962167beca1ef66af3 192.168.200.129:6381
slots:[10923-16383] (5461 slots) master
S: 4a0f860081b969162767aac26801994de54d80a5 192.168.200.129:6389
replicates ccf3abb791e026380ad3ad2a166aa788df738437
S: 62c9f37a362459c212e8af6dd744b6562f5fe6a7 192.168.200.129:6390
replicates 3c372392d5a91dad64a6febadfe9524ea2cbd8c0
S: a2f89efc09681520f9d9502707b18e1f46a40b90 192.168.200.129:6391
replicates 2c905be9c975be367bd66c962167beca1ef66af3
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.
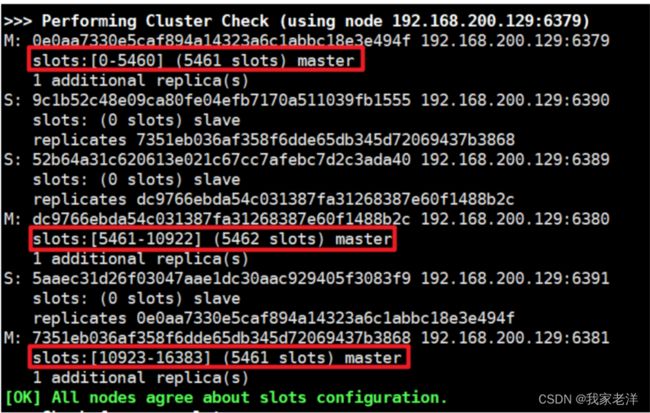
>>> Performing Cluster Check (using node 192.168.200.129:6379)
M: ccf3abb791e026380ad3ad2a166aa788df738437 192.168.200.129:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 2c905be9c975be367bd66c962167beca1ef66af3 192.168.200.129:6381
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 62c9f37a362459c212e8af6dd744b6562f5fe6a7 192.168.200.129:6390
slots: (0 slots) slave
replicates 3c372392d5a91dad64a6febadfe9524ea2cbd8c0
M: 3c372392d5a91dad64a6febadfe9524ea2cbd8c0 192.168.200.129:6380
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 4a0f860081b969162767aac26801994de54d80a5 192.168.200.129:6389
slots: (0 slots) slave
replicates ccf3abb791e026380ad3ad2a166aa788df738437
S: a2f89efc09681520f9d9502707b18e1f46a40b90 192.168.200.129:6391
slots: (0 slots) slave
replicates 2c905be9c975be367bd66c962167beca1ef66af3
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
8 . 连接集群节点,查看集群信息:cluster nodes
需要使用 redis-cli -c 命令连接集群中6个节点中任何一个节点都可以,注意和之前的连接参数有点不 同 redis-cli
命令后面多了一个 -c 参数,表示采用集群的方式连接,连上以后,然后使用 cluster nodes 可以查看集群节点信息,如下
192.168.200.129:6379> cluster nodes
2c905be9c975be367bd66c962167beca1ef66af3 192.168.200.129:6381@16381 master - 0
1650194157604 3 connected 10923-16383
62c9f37a362459c212e8af6dd744b6562f5fe6a7 192.168.200.129:6390@16390 slave
3c372392d5a91dad64a6febadfe9524ea2cbd8c0 0 1650194158611 2 connected
3c372392d5a91dad64a6febadfe9524ea2cbd8c0 192.168.200.129:6380@16380 master - 0
1650194158000 2 connected 5461-10922
4a0f860081b969162767aac26801994de54d80a5 192.168.200.129:6389@16389 slave
ccf3abb791e026380ad3ad2a166aa788df738437 0 1650194156000 1 connected
ccf3abb791e026380ad3ad2a166aa788df738437 192.168.200.129:6379@16379
myself,master - 0 1650194157000 1 connected 0-5460
a2f89efc09681520f9d9502707b18e1f46a40b90 192.168.200.129:6391@16391 slave
2c905be9c975be367bd66c962167beca1ef66af3 0 1650194159617 3 connected
192.168.200.129:6379>
如下图,对 cluster nodes 的结果做下解释,先看下红字的注释,集群中的每个节点都会生成一个ID,
这个ID信息会被写到node-xxxx.conf文件中,为什么要生成id呢?
因为节点的ip和端口可能会发生变化,但是节点的ID是不会变的,其他节点可以通过其他节点的ID来认 识各个节点

9 . 验证集群数据的读写操作
如下,我们连接 6379 这个节点,然后执行一个set操作,效果如下,写入成功
[root@hspEdu01 cluster]# redis-cli -c -h 192.168.200.129 -p 6379
192.168.200.129:6379> set name ready
-> Redirected to slot [5798] located at 192.168.200.129:6380
OK
192.168.200.129:6380>
大家可能注意到了,我们明明在 6379 上操作的,但是请求被转发到了6380这个节点去处理了,这里就
是我们后面要说的slot的知识了,先向后看。
10 . redis集群如何分配这6个节点?
- 一个集群至少有3个主节点,因为新master的选举需要大于半数的集群master节点同意才能选举成功,
- 如果只有两个master节点,当其中一个挂了,是达不到选举新master的条件的。
- 选项–cluster-replicas 1表示我们希望为集群中的每个主节点创建一个从节点。
- 分配原则尽量保证每个主库运行在不同的ip,每个主库和从库不在一个ip上,这样才能做到高可用。
11 . 什么是slots(槽)
如下图,咱们再来看看集群合并的过程中输出的一些信息
Redis集群内部划分了16384个slots(插槽),合并的时候,会将每个slots映射到一个master上面,比
如上面3个master和slots的关系如下:

而数据库中的每个key都属于16384个slots中的其中1个,当通过key读写数据的时候,redis需要先根据
key计算出key对应的slots,然后根据slots和master的映射关系找到对应的redis节点,key对应的数据 就在这个节点上面。
集群中使用公式 CRC16(key)%16384 计算key属于哪个槽
12 . 在集群中录入值
在 redis-cli 每次录入、查询键值,redis都会计算key对应的插槽,如果不是当前redis节点的插槽,
redis会报错,并告知应前往的redis实例地址和端口,效果如下,我们连接了6379这个实例来操作k1,
这个节点发现k1的槽位在6381上面,返回了错误信息,怎么办呢?
[root@hspEdu01 cluster]# redis-cli -h 192.168.200.129 -p 6379
192.168.200.129:6379> set k1 v1
(error) MOVED 12706 192.168.200.129:6381
使用redis-cli客户端提供了-c参数可以解决这个问题,表示以集群方式执行,执行命令的时候当前节点处
理不了的时候,会自动将请求重定向到目标节点,效果如下,被重定向到6381了
[root@hspEdu01 cluster]# redis-cli -c -h 192.168.200.129 -p 6379
192.168.200.129:6379> set k1 v1
-> Redirected to slot [12706] located at 192.168.200.129:6381
OK
192.168.200.129:6381>
同样,执行get会被重定向,效果如下
[root@hspEdu01 cluster]# redis-cli -c -h 192.168.200.129 -p 6379
192.168.200.129:6379> get k1
-> Redirected to slot [12706] located at 192.168.200.129:6381
"v1"
192.168.200.129:6381>
不在一个slot下面,不能使用mget、mset等多键操作,效果如
192.168.200.129:6381> mset k1 v1 k2 v2
(error) CROSSSLOT Keys in request don't hash to the same slot
192.168.200.129:6381> mget k1 k2
(error) CROSSSLOT Keys in request don't hash to the same slot
可以通过{}来定义组的概念,从而使key中{}内相同的键值放到一个slot中去,效果如下
192.168.200.129:6381> mset k1{g1} v1 k2{g1} v2 k3{g1} v3
OK
192.168.200.129:6381> mget k1{g1} k2{g1} k3{g1}
1) "v1"
2) "v2"
3) "v3"
13 . slot相关的一些命令
cluster keyslot :计算key对应的slot
cluster coutkeysinslot :获取slot槽位中key的个数
cluster getkeysinslot 返回count个slot槽中的键
192.168.200.129:6381> cluster keyslot k1{g1}
(integer) 13519
192.168.200.129:6381> cluster countkeysinslot 13519
(integer) 3
192.168.200.129:6381> cluster getkeysinslot 13519 3
1) "k1{g1}"
2) "k2{g1}"
3) "k3{g1}"
14 . 故障恢复
如果主节点下线,从节点是否能够提升为主节点?注意:要等15秒
下面我们来试试,如下,连接master1,然后将master1停掉
[root@hspEdu01 cluster]# redis-cli -c -h 192.168.200.129 -p 6379
192.168.200.129:6379> shutdown
not connected>
执行下面命令,连接master1,看下集群节点的信息
redis-cli -c -h 192.168.200.129 -p 6380
cluster nodes
输出如下,可以看到slave1(6389)确实变成master了,而它原来的master:master1(6379)下线 了

下面我们再来启动6379,然后再看看集群变成什么样了,命令如下
[root@hspEdu01 cluster]# redis-server /opt/cluster/redis-6379.conf
[root@hspEdu01 cluster]# redis-cli -c -h 192.168.200.129 -p 6379
192.168.200.129:6379> cluster nodes
执行结果如下,6379变成slave了,挂在了6389下面了

如果某一段插槽的主从都宕机了,redis服务是否还能继续?
这个时候要看 cluster-require-full-coverage 参数的值了
yes(默认值):整个集群都都无法提供服务了
no:宕机的这部分槽位数据全部不能使用,其他槽位正常