【联邦学习论文阅读】(AAAI-2021)Secure Bilevel Asynchronous Vertical Federated Learning with Backward Updating
论文链接:https://ojs.aaai.org/index.php/AAAI/article/view/17301
摘要
提出一种新颖的融合了反向更新和双层异步并行的垂直联邦学习框架(VFB2),以及在此框架下的 VFB2-SGD,VFB2-SVRG,VFB2-SAGA 三种新算法,助力多方协同训练模型并且不泄漏数据隐私,并在一定程度上破解垂直联邦学习算法不够高效的难点。
一、介绍
纵向联邦学习存在的问题:
- 通常只有一方或部分方持有标签 -> 所有各方都很难在不泄露隐私的情况下协作学习模型
- 大多数现有的VFL算法都受困于同步计算 -> 实际应用效率低下(特别是VFL系统的计算资源不平衡时)
目前有两种主流的VFL方法:基于同态加密(HE) 的方法;基于交换原始计算结果(ERCR) 的方法
- 前者利用同态加密技术对原始数据进行加密,然后使用加密数据(密码文本)进行隐私保护的训练模型。有两个主要缺点:首先,其复杂性高,因此HE建模非常耗时;其次,HE需要近似来支持非线性函数的操作,会导致模型的精度损失。
- 后者利用标签和其他各方传输的原始中间计算结果来计算随机梯度,从而使用分布式随机梯度下降(SGD)方法来有效地训练VFL模型。规避了上述基于HE的方法的缺点,但现有方法只考虑了各方都有标签的情况。而在现实的VFL应用中,通常只有一个或部分方拥有标签(主动参与方),其他被动参与方只能提供额外的特征数据,没有标签。这使得此类算法甚至不能保证收敛,因为只有主动方可以根据标签更新损失函数的梯度,而被动方不能,即模型参数在训练过程中不能被优化。
本文贡献如下:
- 首次为基于ERCR的VFL算法提出反向更新机制(BUM) ,使所有参与方都能够安全地协作更新模型,并使最终模型无损
- 设计了一个双层异步并行架构(BAPA),允许各方都能通过反向更新来异步更新模型,该架构是高效且可扩展的
- 考虑到SGD型算法在优化机器学习模型方面的优势,在此框架下提出三种新的SGD型算法。并从理论上证明它们在强凸和非凸问题上的收敛速度。
二、问题的提出
所给数据集可能应用于二分类任务模型、回归任务模型。这两个模型都可看作以下 正则化经验风险最小化问题 的例子(问题P):
m i n w ∈ R d f ( w ) : = 1 n ∑ i = 1 n L ( w T x i , y i ) + λ ∑ ℓ = 1 q g ( w G ℓ ) ⏟ f i ( w ) \underset{w\in \mathbb{R}^d}{min}f(w):=\frac{1}{n}\sum_{i=1}^{n} \underbrace{\mathcal{L}(w^{T}x_{i},y_{i})+\lambda \sum_{\ell=1}^{q}g(w_{\mathcal{G}\ell})}_{f_{i}(w)} w∈Rdminf(w):=n1i=1∑nfi(w) L(wTxi,yi)+λℓ=1∑qg(wGℓ)
其中,q为参与方数量, w T x i = ∑ ℓ = 1 q w G ℓ T ( x i ) G ℓ w^{T}x_{i}=\sum_{\ell=1}^{q}w_{\mathcal{G}\ell}^{T}(x_i)_{\mathcal{G}\ell} wTxi=∑ℓ=1qwGℓT(xi)Gℓ , L \mathcal{L} L 为损失函数, ∑ ℓ = 1 q g ( w G ℓ ) \sum_{\ell=1}^{q}g(w_{\mathcal{G}\ell}) ∑ℓ=1qg(wGℓ) 为正则项, f i : R d → R f_i:\mathbb{R}^d\to \mathbb{R} fi:Rd→R 光滑且可能非凸
各主动参与方(假设有m个)主动发起更新,在模型更新中起主导作用;其余各方被动更新(被动参与方和其余主动参与方)为合作者;为保证模型安全,只有主动参与方知道损失函数的形式,且只有主动参与方知道标签。
将本文的问题概括为:
- 给定: 存储在q方的垂直分区数据 { x G ℓ } ℓ = 1 q \left\{ {x_{\mathcal{G}\ell}}\right\}_{\ell=1}^{q} {xGℓ}ℓ=1q ,只有主动参与方知道标签;
- 学习: 主动参与方与被动参与方在不泄露隐私的情况下,共同学习一个机器学习模型M;
- 无损约束: M与非联邦学习条件下学习的模型M’精确度相当。
三、VFB2框架
该框架结构如下图所示,由三部分组成
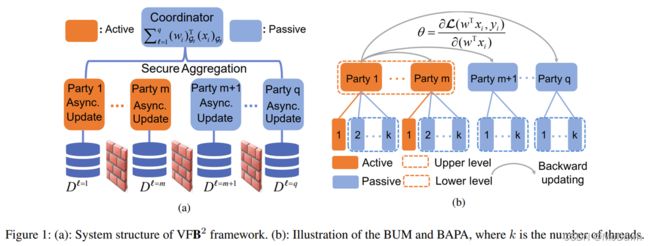
- 反向更新机制(BUM):为了使被动参与方能够使用主动参与方的标签信息且不造成隐私泄露,让被动参与方在计算随机梯度时,间接使用标签而不直接访问原始标签数据,将标签 y i y^i yi 嵌入到一个中间值 ϑ : = ∂ L ( w T x i , y i ) ∂ ( w T x i ) \vartheta:=\frac{\partial \mathcal{L}(w^{T}x_{i},y_{i})}{\partial (w^{T}x_{i})} ϑ:=∂(wTxi)∂L(wTxi,yi)
- 双层异步并行架构(BAPA):不同主动参与方的主导更新在分布式内存中并行执行,而一方的协作更新在共享内存中并行执行,为了应对这种并行方式差异,设计两层并行体系结构,上层为各方间并行,下层为各方内并行(如图1(b)所示)
各方间并行是指各方之间的分布式内存并行,它使所有活动方能够异步进行发挥主导作用的更新;各方内并行则是指各方内协作更新的共享内存并行,即其多个线程能够异步地执行协作更新 - 安全聚合策略:各方为了获得其他参与方的特征数据,需要获得 w T x i = ∑ ℓ = 1 q w G ℓ T ( x i ) G ℓ w^{T}x_{i}=\sum_{\ell=1}^{q}w_{\mathcal{G}\ell}^{T}(x_i)_{\mathcal{G}\ell} wTxi=∑ℓ=1qwGℓT(xi)Gℓ,本文实用高效的树形结构通信方法进行安全聚合。如算法1所示,先在各方进行本地计算,增加随机数 δ ℓ \delta _{\ell} δℓ (2:);然后利用不同的树形结构 T 1 T_1 T1 和 T 2 T_2 T2 聚合得到 ξ 1 \xi_1 ξ1 和 ξ 2 \xi_2 ξ2 (4: 5:);最后输出两者之差

四、带有反向更新的安全双层异步VFL算法
SGD是机器学习模型中常用的方法,但由于随机梯度的固有方差,其收敛速度较差。SVRG和SAGA对此进行了改进,能够减少方差,是SGD类型中很流行两种的算法。如下的算法2为VFB2框架下SGD的实现步骤;算法3为此框架下SVRG和SAGA算法的实现步骤(SVRG和SAGA仅更新规则不同)


在算法2中,每个主导方更新,主导方会将 ϑ \vartheta ϑ 和 i i i 发送给协作者;在算法3中,参与方收到 ϑ \vartheta ϑ 和 i i i 后会发起异步协作更新。主导方计算本地随机梯度;协作方使用收到的参数进行算法3中(3:)的计算;主导方自身也需完成算法3与其他协作方进行协作,确保各方的模型参数得到更新。
五、理论分析
本节提供了收敛性分析。
首先提出强凸和非凸问题的准备工作:
假设1:关于 f i ( w ) f_i(w) fi(w)
假设2:关于正则项 g g g
假设3:(有界时延) 主导方和它的协同方间,不一致读取和通信的时延
强凸问题的收敛性分析:
假设4:每个 f i f_i fi 函数为 µ-强凸
定义1:epoch 数 v ( t ) v(t) v(t)
定理1:对 VFB2-SGD 达到问题P的 准确性
定理2:对 VFB2-SVRG 达到问题P的 准确性
定理3:对 VFB2-SAGA 达到问题P的 准确性
备注1:三种算法的收敛速度
非凸问题的收敛性分析:
假设5:非凸函数 f ( w ) f(w) f(w) 有界
定义2:epoch 数 v ′ ( t ) v'(t) v′(t)
定理4:对 VFB2-SGD 的问题P的 一阶平稳点
定理5:VFB2-SVRG
定理6:VFB2-SAGA
备注2:三种算法的收敛速度
六、安全分析
在安全分析中常用的两种半诚实威胁模型下,讨论VFB的数据安全和模型安全。
两种威胁模型的威胁能力不同:威胁模型2允许各方串通,而威胁模型1不允许。
- 诚实但好奇(威胁模式1):各方都会按照算法进行正确的计算。然而,他们可能会使用自己保留的中间计算结果的记录来推断其他方的数据和模型。
- 诚实但串通一气(威胁模型2):各方都会按照算法进行正确的计算。然而,一些工作者可能会串通起来,通过分享他们保留的中间计算结果的记录来推断其他方的数据和模型。
定义3:推理攻击
引理1:根据所用的中间结果,能够推出无穷多个不同的解。
定理7:特征和模型的安全性;标签的安全性 -> 在两种半诚实威胁模型下,VFB2可以防止推理攻击。
七、实验
进行大量实验,以证明算法是高效的、可扩展的和无损的
1 实验设置
2 数据集:UCICreditCard、GiveMeSomeCredit、news20、webspam
3 问题:µ-强凸情况下的 ℓ 2 \ell_2 ℓ2-范式正则化逻辑回归问题 和 非凸逻辑回归模型
m i n w ∈ R d f ( w ) : = 1 n ∑ i = 1 n l o g ( 1 + e − y i w T x i ) + λ 2 ∥ w ∥ 2 \underset{w\in \mathbb{R}^d}{min}f(w):=\frac{1}{n}\sum_{i=1}^{n}log(1+e^{-y_iw^Tx_i})+\frac{\lambda }{2}\left\| w\right\|^2 w∈Rdminf(w):=n1i=1∑nlog(1+e−yiwTxi)+2λ∥w∥2 m i n w ∈ R d f ( w ) : = 1 n ∑ i = 1 n l o g ( 1 + e − y i w T x i ) + λ 2 ∑ i = 1 d w i 2 1 + w i 2 \underset{w\in \mathbb{R}^d}{min}f(w):=\frac{1}{n}\sum_{i=1}^{n}log(1+e^{-y_iw^Tx_i})+\frac{\lambda }{2}\sum_{i=1}^{d}\frac{w_i^2}{1+w_i^2} w∈Rdminf(w):=n1i=1∑nlog(1+e−yiwTxi)+2λi=1∑d1+wi2wi2
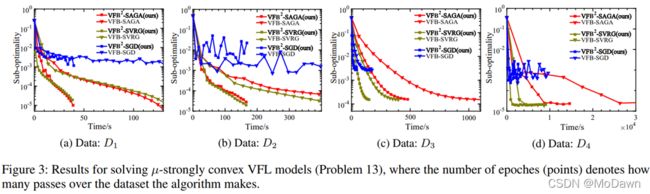
对异步效率和可扩展性的评估
1 异步效率
VFB:有BUM的同步VFL算法;设置1个比最快方慢30%-50%的掉队方,以模拟资源不平衡的真实应用场景。
设置 q=8,m=3(参与方与主动参与方数量)。
从图中可以看出,我们的算法在效率上始终优于同步算法;基于SVRG和SAGA的算法比基于SGD的算法收敛速度更快。
 2 异步可扩展性
2 异步可扩展性
固定m,变换q,设置如下定义(运行时间指达到一定精度时所用的时间):
![]()
从图中可以看出,我们的异步算法比同步算法有更好的可扩展性,可以实现接近线性的加速。

对无损的评估
比较了 VFB2-SVRG、其非联邦版本 NonF (所有数据集合在一起训练)、基于ERCR的算法 AFSVRG-VP (他人提出的,也使用了分布式SGD方法;但是没有BUM,只能优化主动参与方的参数,这里假设有标签的参与方有一半)