【pod详解】
pod详解
Pod生命周期
我们一般将pod对象从创建至终的这段时间范围称为pod的生命周期,
它主要包含下面的过程:
pod创建过程
运行初始化容器(init container)过程
运行主容器(main container)
容器启动后钩子(post start)、容器终止前钩子(pre stop)
容器的存活性探测(liveness probe)、就绪性探测(readiness probe)
pod终止过程

在整个生命周期中,Pod会出现5种状态(相位),分别如下:
挂起(Pending):apiserver已经创建了pod资源对象,但它尚未被调度完成或者仍处于下载镜像的过程中
运行中(Running):pod已经被调度至某节点,并且所有容器都已经被kubelet创建完成
成功(Succeeded):pod中的所有容器都已经成功终止并且不会被重启
失败(Failed):所有容器都已经终止,但至少有一个容器终止失败,即容器返回了非0值的退出状态
未知(Unknown):apiserver无法正常获取到pod对象的状态信息,通常由网络通信失败所导致
一、创建和终止
pod的创建过程
1、用户通过kubectl或其他api客户端提交需要创建的pod信息给apiServer
2、apiServer开始生成pod对象的信息,并将信息存入etcd,然后返回确认信息至客户端
3、apiServer开始反映etcd中的pod对象的变化, 其它组件使用watch机制来跟踪检查apiServer上的变动
4、scheduler发现有新的pod对象要创建,开始为Pod分配主机并将结果信息更新至apiServer
5、node节点上的kubelet发现有pod调度过来,尝试调用docker启动容器,并将结果回送至apiServer
6、apiServer将接收到的pod状态信息存入etcd中
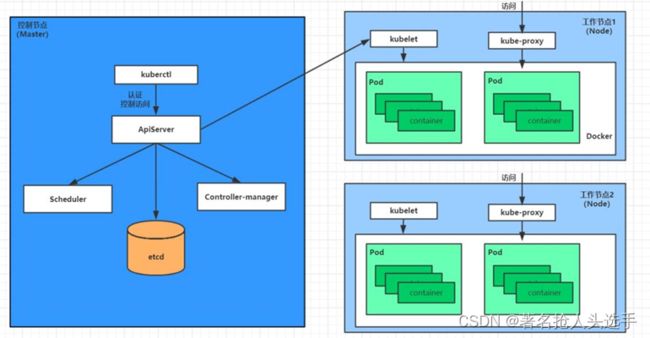
pod的终止过程
1.用户向apiServer发送删除pod对象的命令
2.apiServcer中的pod对象信息会随着时间的推移而更新,在宽限期内(默认30s),pod被视为dead
3.将pod标记为terminating状态
4. kubelet在监控到pod对象转为terminating状态的同时启动pod关闭过程
5.节点控制器监控到pod对象的关闭行为时将其从所有匹配到此节点的service资源的节点列表中移除
6.如果当前pod对象定义了preStop钩子处理器, 则在其标记为terminating后即会以同步的方式启动执行
7.pod对象中的容器进程收到停止信号
8.宽限期结束后,若pod中还存在仍在运行的进程,那么pod对象会收到立即终止的信号
9. kubelet请求apiServer将此pod资源的宽限期设置为0从而完成删除操作,此时pod对于用户已不可见
二、 初始化容器
初始化容器是在pod的主容器启动之前要运行的容器,主要是做一些主容器的前置工作,它具有两大特征:
初始化容器必须运行完成直至结束,若某初始化容器运行失败,那么kubernetes需要重启它直到成功完成
初始化容器必须按照定义的顺序执行,当且仅当前一个成功之后,后面的一个才能运行
初始化容器有很多的应用场景,下面列出的是最常见的几个:
提供主容器镜像中不具备的工具程序或自定义代码
初始化容器要先于应用容器串行启动并运行完成,因此可用于延后应用容器的启动直至其依赖的条件得到满足
接下来做一个案例,模拟下面这个需求:
假设要以主容器来运行nginx,但是要求在运行nginx之前先要能够连接上mysql和redis所在服务器
创建pod-initcontainer.yaml,内容如下:
[root@master ~]# vim pod-initcontainer.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-initcontainer
namespace: laj
spec:
containers:
- name: main-container
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
initContainers:
- name: test-mysql
image: busybox:1.30
command: ['sh', '-c', 'until ping 192.168.148.149 -c 1 ; do echo waiting for mysql...; sleep 2; done;']
- name: test-redis
image: busybox:1.30
command: ['sh', '-c', 'until ping 192.168.148.150-c 1 ; do echo waiting for reids...; sleep 2; done;']
# 创建pod
[root@master ~]# kubectl create -f pod-initcontainer.yaml
pod/pod-initcontainer created
# 查看pod状态# 发现pod卡在启动第一个初始化容器过程中,后面的容器不会运行
[root@master ~]# kubectl describe pod pod-initcontainer -n laj
.... node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Pulled 16s kubelet Container image "busybox:1.30" already present on machine
Normal Created 16s kubelet Created container test-mysql
Normal Scheduled 16s default-scheduler Successfully assigned laj/pod-initcontainer to node2
Normal Started 16s kubelet Started container test-mysql
Normal Pulled 15s kubelet Container image "busybox:1.30" already present on machine
Normal Created 15s kubelet Created container test-redis
Normal Started 15s kubelet Started container test-redis
# 动态查看pod
[root@master ~]# kubectl get pods pod-initcontainer -n laj -w
NAME READY STATUS RESTARTS AGE
pod-initcontainer 0/1 Init:1/2 0 6m27s
# 接下来新开一个shell,为当前服务器新增两个ip,观察pod的变化
[root@master ~]# ifconfig ens33:1 192.168.3.11 netmask 255.255.255.0 up
[root@master ~]# ifconfig ens33:1 192.168.3.12 netmask 255.255.255.0 up
5.3.3 钩子函数
钩子函数能够感知自身生命周期中的事件,并在相应的时刻到来时运行用户指定的程序代码。
kubernetes在主容器的启动之后和停止之前提供了两个钩子函数:
post start:容器创建之后执行,如果失败了会重启容器
pre stop :容器终止之前执行,执行完成之后容器将成功终止,在其完成之前会阻塞删除容器的操作
钩子处理器支持使用下面三种方式定义动作:
Exec命令:在容器内执行一次命令
lifecycle:
postStart:
exec:
command:
- cat
- /tmp/healthy
TCPSocket:在当前容器尝试访问指定的socket
lifecycle:
postStart:
tcpSocket:
port: 8080
HTTPGet:在当前容器中向某url发起http请求
lifecycle:
postStart:
httpGet:
path: / #URI地址
port: 80 #端口号
host: 192.168.5.3 #主机地址
scheme: HTTP #支持的协议,http或者https
接下来,以exec方式为例,演示下钩子函数的使用,创建pod-hook-exec.yaml文件,内容如下:
apiVersion: v1
kind: Pod
metadata:
name: pod-hook-exec
namespace: laj
spec:
containers:
- name: main-container
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
lifecycle:
postStart:
exec: # 在容器启动的时候执行一个命令,修改掉nginx的默认首页内容
command: ["/bin/sh", "-c", "echo postStart... > /usr/share/nginx/html/index.html"]
preStop:
exec: # 在容器停止之前停止nginx服务
command: ["/usr/sbin/nginx","-s","quit"]
5.3.4 容器探测
容器探测用于检测容器中的应用实例是否正常工作,是保障业务可用性的一种传统机制。 如果经过探测,实例的状态不符合预期,那么kubernetes就会把该问题实例" 摘除 ",不承担业务流量。 kubernetes提供了两种探针来实现容器探测,分别是:
liveness probes:存活性探针,用于检测应用实例当前是否处于正常运行状态,如果不是,k8s会重启容器
readiness probes:就绪性探针,用于检测应用实例当前是否可以接收请求,如果不能,k8s不会转发流量
livenessProbe 决定是否重启容器,readinessProbe 决定是否将请求转发给容器。
上面两种探针目前均支持三种探测方式:
Exec命令:在容器内执行一次命令,如果命令执行的退出码为0,则认为程序正常,否则不正常
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
TCPSocket:将会尝试访问一个用户容器的端口,如果能够建立这条连接,则认为程序正常,否则不正常
livenessProbe:
tcpSocket:
port: 8080
HTTPGet:调用容器内Web应用的URL,如果返回的状态码在200和399之间,则认为程序正常,否则不正常
livenessProbe:
httpGet:
path: / #URI地址
port: 80 #端口号
host: 127.0.0.1 #主机地址
scheme: HTTP #支持的协议,http或者https
方式一:Exec
创建pod-liveness-exec.yaml
[root@master ~]# vim pod-liveness-exec.yaml
apiVersion: v14
kind: Pod
metadata:
name: pod-liveness-exec
namespace: laj
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
exec:
command: ["/bin/cat","/tmp/hello.txt"] # 执行一个查看文件的命令
创建pod,观察效果
# 创建Pod
[root@master ~]# kubectl create -f pod-liveness-exec.yaml
pod/pod-liveness-exec created
# 查看Pod详情
[root@master ~]# kubectl describe pods pod-liveness-exec -n dev
# 查看Pod详情
[root@master ~]# kubectl describe pods pod-liveness-exec -n laj
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 10s default-scheduler Successfully assigned ww/pod-liveness-exec to node2
Normal Pulled 9s kubelet Container image "nginx:1.17.1" already present on machine
Normal Created 9s kubelet Created container nginx
Normal Started 9s kubelet Started container nginx
[root@master ~]# kubectl get pods pod-liveness-exec -n laj
NAME READY STATUS RESTARTS AGE
pod-liveness-exec 1/1 Running 4 (23s ago) 3m23s
方式二:TCPSocket
[root@master ~]# vim pod-liveness-tcpsocket.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-tcpsocket
namespace: laj
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
tcpSocket:
port: 8080 # 尝试访问8080端口
[root@master ~]# kubectl create -f pod-liveness-tcpsocket.yaml
pod/pod-liveness-tcpsocket created
[root@master ~]# kubectl describe pods pod-liveness-tcpsocket -n laj
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Pulled 12s kubelet Container image "nginx:1.17.1" already present on machine
Normal Created 12s kubelet Created container nginx
Normal Started 12s kubelet Started container nginx
Normal Scheduled 10s default-scheduler Successfully assigned ww/pod-liveness-tcpsocket to node2
Warning Unhealthy 2s kubelet Liveness probe failed: dial tcp 10.244.2.24:8080: connect: connection refused
# 观察上面的信息,发现尝试访问8080端口,但是失败了# 稍等一会之后,再观察pod信息,就可以看到RESTARTS不再是0,而是一直增长
[root@master ~]# kubectl get pods pod-liveness-tcpsocket -n laj
NAME READY STATUS RESTARTS AGE
pod-liveness-tcpsocket 1/1 Running 3 (16s ago) 124s
方式三:HTTPGet
[root@master ~]# vim pod-liveness-httpget.yaml
[root@master ~]# cat pod-liveness-httpget.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-httpget
namespace: laj
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
httpGet:
scheme: HTTP
port: 80
path: /hello
创建pod,观察效果
[root@master ~]# kubectl create -f pod-liveness-httpget.yaml
pod/pod-liveness-httpget created
[root@master ~]# kubectl describe pod pod-liveness-httpget -n laj
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Pulling 16s kubelet Pulling image "nginx:1.17.1"
Normal Scheduled 15s default-scheduler Successfully assigned ww/pod-liveness-httpget to node1
[root@master ~]# kubectl get pod pod-liveness-httpget -n laj
NAME READY STATUS RESTARTS AGE
pod-liveness-httpget 0/1 ContainerCreating 0 96s
至此,已经使用liveness Probe演示了三种探测方式,但是查看livenessProbe的子属性,会发现除了这三种方式,还有一些其他的配置,在这里一并解释下:
[root@k8s-master01 ~]# kubectl explain pod.spec.containers.livenessProbe
FIELDS:
exec 5.3.5 重启策略
在上一节中,一旦容器探测出现了问题,kubernetes就会对容器所在的Pod进行重启,其实这是由pod的重启策略决定的,pod的重启策略有 3 种,分别如下:
Always :容器失效时,自动重启该容器,这也是默认值。
OnFailure : 容器终止运行且退出码不为0时重启
Never : 不论状态为何,都不重启该容器
重启策略适用于pod对象中的所有容器,首次需要重启的容器,将在其需要时立即进行重启,随后再次需要重启的操作将由kubelet延迟一段时间后进行,且反复的重启操作的延迟时长以此为10s、20s、40s、80s、160s和300s,300s是最大延迟时长。
创建pod-restartpolicy.yaml:
''api版本: v1
种类: Pod
元数据:名称: pod-restartpolicy
命名空间: laj
spec:containers:
名称: nginx 图片: nginx
:1.17.1
端口:
name: nginx-port
containerPort: 80
livenessProbe:
httpGet:
scheme: HTTP
port: 80
path: /hello
restartPolicy: Never # 设置重启策略为Never`cpp
运行Pod测试
```cpp
[root@master ~]# kubectl create -f pod-restartpolicy.yaml
pod/pod-restartpolicy created
[root@master ~]# kubectl describe pods pod-restartpolicy -n laj
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Pulling 7s kubelet Pulling image "nginx:1.17.1"
Normal Scheduled 6s default-scheduler Successfully assigned laj/pod-restartpolicy to node1
5.4 Pod调度
在默认情况下,一个Pod在哪个Node节点上运行,是由Scheduler组件采用相应的算法计算出来的,这个过程是不受人工控制的。 但是在实际使用中,这并不满足的需求,因为很多情况下,我们想控制某些Pod到达某些节点上,那么应该怎么做呢? 这就要求了解kubernetes对Pod的调度规则,
kubernetes提供了四大类调度方式:
自动调度:运行在哪个节点上完全由Scheduler经过一系列的算法计算得出
定向调度:NodeName、NodeSelector
亲和性调度:NodeAffinity、PodAffinity、PodAntiAffinity
污点(容忍)调度:Taints、Toleration
5.4.1 定向调度
定向调度,指的是利用在pod上声明nodeName或者nodeSelector,以此将Pod调度到期望的node节点上。 注意,这里的调度是强制的,这就意味着即使要调度的目标Node不存在,也会向上面进行调度,只不过pod运行失败而已。
NodeName
NodeName用于强制约束将Pod调度到指定的Name的Node节点上。 这种方式,其实是直接跳过Scheduler的调度逻辑,直接将Pod调度到指定名称的节点。
接下来,实验一下:创建一个pod-nodename.yaml文件
apiVersion: v1
kind: Pod
metadata:
name: pod-nodename
namespace: laj
spec:
containers:
- name: nginx
image: nginx:1.17.1
nodeName: node1 # 指定调度到node1节点上
#创建Pod
[root@master ~]# kubectl create -f pod-nodename.yaml
pod/pod-nodename created
#查看Pod调度到NODE属性,确实是调度到了node1节点上
[root@master ~]# kubectl get pods pod-nodename -n laj -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pod-nodename 1/1 Running 0 46s 10.244.2.24 node1
# 接下来,删除pod,修改nodeName的值为node3(并没有node3节点)
[root@master ~]# kubectl delete -f pod-nodename.yaml
pod "pod-nodename" deleted
[root@master ~]# vim pod-nodename.yaml
[root@master ~]# kubectl create -f pod-nodename.yaml
pod/pod-nodename created
#再次查看,发现已经向Node3节点调度,但是由于不存在node3节点,所以pod无法正常运行
[root@master ~]# kubectl get pods pod-nodename -n laj -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pod-nodename 0/1 Pending 0 10s node3
节点选择器
NodeSelector用于将pod调度到添加了指定标签的node节点上。 它是通过kubernetes的label-selector机制实现的,也就是说,在pod创建之前,会由scheduler使用MatchNodeSelector调度策略进行label匹配,找出目标node,然后将pod调度到目标节点,该匹配规则是强制约束。
接下来,实验一下:
1 首先分别为node节点添加标签
[root@master ~]# kubectl label nodes node1 nodeenv=pro
node/node2 labeled
[root@master ~]# kubectl label nodes node2 nodeenv=test
node/node2 labeled
2 创建一个pod-nodeselector.yaml文件,并使用它创建Pod
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeselector
namespace: laj
spec:
containers:
- name: ngin-*11
image: nginx:1.17.1
nodeSelector:
nodeenv: pro # 指定调度到具有nodeenv=pro标签的节点上
#创建Pod
[root@master ~]# kubectl create -f pod-nodeselector.yaml
pod/pod-nodeselector created
#查看Pod调度到NODE属性,确实是调度到了node1节点上
[root@master ~]# kubectl get pods pod-nodeselector -n laj -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodeselector 1/1 Running 0 45s 10.244.2.24 node1 ......
# 接下来,删除pod,修改nodeSelector的值为nodeenv: xxxx(不存在打有此标签的节点)
[root@master ~]# kubectl delete -f pod-nodeselector.yaml
pod "pod-nodeselector" deleted
[root@master ~]# vim pod-nodeselector.yaml
[root@master ~]# kubectl create -f pod-nodeselector.yaml
pod/pod-nodeselector created
#再次查看,发现pod无法正常运行,Node的值为none
[root@master ~]# kubectl get pods -n laj -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pod-nodeselector 0/1 Pending 0 2m20s
# 查看详情,发现node selector匹配失败的提示
[root@master ~]# kubectl describe pods pod-nodeselector -n laj
.......Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
5.4.2 亲和性调度
上一节,介绍了两种定向调度的方式,使用起来非常方便,但是也有一定的问题,那就是如果没有满足条件的Node,那么Pod将不会被运行,即使在集群中还有可用Node列表也不行,这就限制了它的使用场景。
基于上面的问题,kubernetes还提供了一种亲和性调度(Affinity)。 它在NodeSelector的基础之上的进行了扩展,可以通过配置的形式,实现优先选择满足条件的Node进行调度,如果没有,也可以调度到不满足条件的节点上,使调度更加灵活。
Affinity主要分为三类:
nodeAffinity(node亲和性): 以node为目标,解决pod可以调度到哪些node的问题
podAffinity(pod亲和性) : 以pod为目标,解决pod可以和哪些已存在的pod部署在同一个拓扑域中的问题
podAntiAffinity(pod反亲和性) : 以pod为目标,解决pod不能和哪些已存在pod部署在同一个拓扑域中的问题
关于亲和性(反亲和性)使用场景的说明:
亲和性:如果两个应用频繁交互,那就有必要利用亲和性让两个应用的尽可能的靠近,这样可以减少因网络通信而带来的性能损耗。
反亲和性:当应用的采用多副本部署时,有必要采用反亲和性让各个应用实例打散分布在各个node上,这样可以提高服务的高可用性。
节点亲和力
首先来看一下NodeAffinity的可配置项:
pod.spec.affinity.nodeAffinity
requiredDuringSchedulingIgnoredDuringExecution Node节点必须满足指定的所有规则才可以,相当于硬限制
nodeSelectorTerms 节点选择列表
matchFields 按节点字段列出的节点选择器要求列表
matchExpressions 按节点标签列出的节点选择器要求列表(推荐)
key 键
values 值
operator 关系符 支持Exists, DoesNotExist, In, NotIn, Gt, Lt
preferredDuringSchedulingIgnoredDuringExecution 优先调度到满足指定的规则的Node,相当于软限制 (倾向)
preference 一个节点选择器项,与相应的权重相关联
matchFields 按节点字段列出的节点选择器要求列表
matchExpressions 按节点标签列出的节点选择器要求列表(推荐)
key 键
values 值
operator 关系符 支持In, NotIn, Exists, DoesNotExist, Gt, Lt
weight 倾向权重,在范围1-100。
关系符的使用说明:
- matchExpressions:
- key: nodeenv # 匹配存在标签的key为nodeenv的节点
operator: Exists
- key: nodeenv # 匹配标签的key为nodeenv,且value是"xxx"或"yyy"的节点
operator: In
values: ["xxx","yyy"]
- key: nodeenv # 匹配标签的key为nodeenv,且value大于"xxx"的节点
operator: Gt
values: "xxx"
接下来再演示一下requiredDuringSchedulingIgnoredDuringExecution ,
创建pod-nodeaffinity-preferred.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeaffinity-required
namespace: laj
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #亲和性设置
nodeAffinity: #设置node亲和性
requiredDuringSchedulingIgnoredDuringExecution: # 硬限制
nodeSelectorTerms:
- matchExpressions: # 匹配env的值在["xxx","yyy"]中的标签
- key: nodeenv
operator: In
values: ["xxx","yyy"]
# 创建pod
[root@master ~]# kubectl create -f pod-nodeaffinity-required.yaml
pod/pod-nodeaffinity-required created
# 查看pod状态 (运行失败)
[root@master ~]# kubectl get pods pod-nodeaffinity-required -n laj -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodeaffinity-required 0/1 Pending 0 12s ......
# 查看Pod的详情# 发现调度失败,提示node选择失败
[root@master ~]# kubectl describe pod pod-nodeaffinity-required -n laj
......
Warning FailedScheduling default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
Warning FailedScheduling default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
#接下来,停止pod
[root@master ~]# kubectl delete -f pod-nodeaffinity-required.yaml
pod "pod-nodeaffinity-required" deleted
# 修改文件,将values: ["xxx","yyy"]------> ["pro","yyy"]
[root@master ~]# vim pod-nodeaffinity-required.yaml
# 再次启动
[root@master ~]# kubectl create -f pod-nodeaffinity-required.yaml
pod/pod-nodeaffinity-required created
# 此时查看,发现调度成功,已经将pod调度到了node1上
[root@master ~]# kubectl get pods pod-nodeaffinity-required -n ww -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodeaffinity-required 1/1 Running 0 11s 10.244.2.26 node1 ......
豆荚亲和力
PodAffinity主要实现以运行的Pod为参照,实现让新创建的Pod跟参照pod在一个区域的功能。
首先来看一下PodAffinity的可配置项
pod.spec.affinity.podAffinity
requiredDuringSchedulingIgnoredDuringExecution 硬限制
namespaces 指定参照pod的namespace
topologyKey 指定调度作用域
labelSelector 标签选择器
matchExpressions 按节点标签列出的节点选择器要求列表(推荐)
key 键
values 值
operator 关系符 支持In, NotIn, Exists, DoesNotExist.
matchLabels 指多个matchExpressions映射的内容
preferredDuringSchedulingIgnoredDuringExecution 软限制
podAffinityTerm 选项
namespaces
topologyKey
labelSelector
matchExpressions
key 键
values 值
operator
matchLabels
weight 倾向权重,在范围1-100
topologyKey用于指定调度时作用域,例如:
如果指定为kubernetes.io/hostname,那就是以Node节点为区分范围
如果指定为beta.kubernetes.io/os,则以Node节点的操作系统类型来区分
接下来,演示下requiredDuringSchedulingIgnoredDuringExecution,
1)首先创建一个参照Pod,pod-podaffinity-target.yaml:
apiVersion: v1
kind: Pod
metadata:
name: pod-podaffinity-target
namespace: laj
labels:
podenv: pro #设置标签
spec:
containers:
- name: nginx
image: nginx:1.17.1
nodeName: node1 # 将目标pod名确指定到node1上
# 启动目标pod
[root@master ~]# kubectl create -f pod-podaffinity-target.yaml
pod/pod-podaffinity-target created
# 查看pod状况
[root@master ~]# kubectl get pods pod-podaffinity-target -n laj
NAME READY STATUS RESTARTS AGE
pod-podaffinity-target 1/1 Running 0 12s
2)创建pod-podaffinity-required.yaml,内容如下:
apiVersion: v1
kind: Pod
metadata:
name: pod-podaffinity-required
namespace: laj
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #亲和性设置
podAffinity: #设置pod亲和性
requiredDuringSchedulingIgnoredDuringExecution: # 硬限制
- labelSelector:
matchExpressions: # 匹配env的值在["xxx","yyy"]中的标签
- key: podenv
operator: In
values: ["xxx","yyy"]
topologyKey: kubernetes.io/hostname
上面配置表达的意思是:新Pod必须要与拥有标签nodeenv=xxx或者nodeenv=yyy的pod在同一Node上,显然现在没有这样pod,接下来,运行测试一下。
# 启动pod
[root@master ~]# kubectl create -f pod-podaffinity-required.yaml
pod/pod-podaffinity-required created
# 查看pod状态,
[root@master ~]# kubectl get pods pod-podaffinity-required -n laj
NAME READY STATUS RESTARTS AGE
pod-podaffinity-required 0/1 Pending 0 8s
# 查看详细信息
[root@master ~]# kubectl describe pods pod-podaffinity-required -n laj
......Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling default-scheduler 0/3 nodes are available: 2 node(s) didn't match pod affinity rules, 1 node(s) had taints that the pod didn't tolerate.
# 接下来修改 values: ["xxx","yyy"]----->values:["pro","yyy"]# 意思是:新Pod必须要与拥有标签nodeenv=xxx或者nodeenv=yyy的pod在同一Node上
[root@master ~]# vim pod-podaffinity-required.yaml
# 然后重新创建pod,查看效果
[root@master ~]# kubectl delete -f pod-podaffinity-required.yaml
pod "pod-podaffinity-required" deleted
[root@master ~]# kubectl create -f pod-podaffinity-required.yaml
pod/pod-podaffinity-required created
# 发现此时Pod运行正常
[root@master ~]# kubectl get pods pod-podaffinity-required -n laj
NAME READY STATUS RESTARTS AGE LABELS
pod-podaffinity-required 1/1 Running 0 7s