python实现词云及导出词频到excel
python实现词云及导出词频到excel
文章目录
- python实现词云及导出词频到excel
-
- 需要用到的几个包
- 停顿词的更新
- 词频的汇总及排序
- 将词频打出到excel
- 词云部分
- 完整代码
- 输入的文字
- 结果展示
- 文件结构
需要用到的几个包
import wordcloud as wc
import jieba
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from xlwt import *
其中,PIL包可能因为不知名的原因无法导入,可直接导入pillow包(pillow包含PIL)。
停顿词的更新
emp=[ '和', '在', ',', '。', '‘', '’', '“', '”', '为', '是', '、', ':', '!','(',')']#停顿词
wc.STOPWORDS.update(emp)#更新停顿词(不在词云里面出现)
emp列表为停顿词列表,将不希望在词云中出现的词语写入其中。
词频的汇总及排序
dict={}#空字典,将词语及其出现次数以键值对形式存入
rep={}#查看所遍历分词是否重复
num=0#不同的分词的个数
for word in words:
if word not in rep:
if word not in emp:#停顿词也不加入到统计中
dict[word]=0#加入字典
rep[word]=0
dict[word] += 1
num+=1
else:
dict[word]+=1
dict1 = sorted(dict.items(), key=lambda x: x[1],reverse=True)#按键值从大到小排列
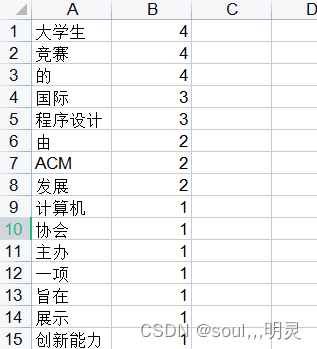
将词频打出到excel
row1=0#打出到第几行
file = Workbook(encoding='utf-8')
table = file.add_sheet('data')
i=0
for i in range(0,num):#分别打出词语和出现频数
table.write(row1,0,dict1[i][0])
table.write(row1,1,dict1[i][1])
row1+=1
i+=1
file.save('data1.xlsx')
词云部分
with open("text.txt",mode="r",encoding="utf-8")as fp:
contents=fp.read();
words=jieba.lcut(contents,cut_all=False,HMM=True)#要切分的语句,全模式(所有可能的词,可能存在冗余)关闭,采用HMM(隐马尔科夫)模型
text=" ".join(words)#使用空格分离
ima=Image.open("1.png")#词云图片
mask=np.array(ima)
word_cloud=wc.WordCloud(font_path="msyh.ttc",mask=mask)#字体路径(微软雅黑),词云形状
word_cloud.generate(text)#创建词云
plt.imshow(word_cloud)
word_cloud.to_file("wordcloud.png")#打入文件
plt.show()
完整代码
import wordcloud as wc
import jieba
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from xlwt import *
def main():
with open("text.txt",mode="r",encoding="utf-8")as fp:
contents=fp.read();
emp=[ '和', '在', ',', '。', '‘', '’', '“', '”', '为', '是', '、', ':', '!','(',')'] # 停顿词
wc.STOPWORDS.update(emp)#更新停顿词(不在词云里面出现)
words=jieba.lcut(contents,cut_all=False,HMM=True)#要切分的语句,全模式(所有可能的词,可能存在冗余)关闭,采用HMM(隐马尔科夫)模型
dict={}#空字典,将词语及其出现次数以键值对形式存入
rep={}#查看所遍历分词是否重复
num=0#不同的分词的个数
for word in words:
if word not in rep:
if word not in emp:#停顿词也不加入到统计中
dict[word]=0#加入字典
rep[word]=0
dict[word] += 1
num+=1
else:
dict[word]+=1
dict1 = sorted(dict.items(), key=lambda x: x[1],reverse=True)#按键值从大到小排列
row1=0#打出到第几行
file = Workbook(encoding='utf-8')
table = file.add_sheet('data')
i=0
for i in range(0,num):#分别打出词语和出现频数
table.write(row1,0,dict1[i][0])
table.write(row1,1,dict1[i][1])
row1+=1
i+=1
file.save('data1.xlsx')
text=" ".join(words)#使用空格分离
ima=Image.open("1.png")#词云图片
mask=np.array(ima)
word_cloud=wc.WordCloud(font_path="msyh.ttc",mask=mask)#字体路径(微软雅黑),词云形状
word_cloud.generate(text)#创建词云
plt.imshow(word_cloud)
word_cloud.to_file("wordcloud.png")#打入文件
plt.show()
if __name__ == '__main__':
main()
输入的文字
国际大学生程序设计竞赛是由国际计算机协会(ACM)主办的,一项旨在展示大学生创新能力、团队精神和在压力下编写程序、分析和解决问题能力的年度竞赛。经过近40年的发展,ACM国际大学生程序设计竞赛已经发展成为全球最具影响力的大学生程序设计竞赛,赛事由AWS、华为和Jetbrains赞助,在北京大学设有ICPC北京总部,用于组织东亚区域赛。
结果展示

文件结构