机器学习中val_讲透机器学习中的梯度下降
在之前的文章当中,我们一起推导了线性回归的公式,今天我们继续来学习上次没有结束的内容。
上次我们推导完了公式的时候,曾经说过由于有许多的问题,比如最主要的复杂度问题。随着样本和特征数量的增大,通过公式求解的时间会急剧增大,并且如果特征为空,还会出现公式无法计算的情况。所以和直接公式求解相比,实际当中更倾向于使用另外一种方法来代替,它就是今天这篇文章的主角——梯度下降法。
梯度下降法可以说是机器学习和深度学习当中最重要的方法,可以说是没有之一。尤其是在深度学习当中,几乎清一色所有的神经网络都是使用梯度下降法来训练的。那么,梯度下降法究竟是一种什么样的方法呢,让我们先从梯度的定义开始。
梯度的定义
我们先来看看维基百科当中的定义:梯度(gradient)是一种关于多元导数的概括。平常的一元(单变量)函数的导数是标量值函数,而多元函数的梯度是向量值函数。多元可微函数 f 在点 P 上的梯度,是以 f 在 P 上的偏导数为分量的向量。
这句话很精炼,但是不一定容易理解,我们一点一点来看。我们之前高中学过导数,但是高中时候计算的求导往往针对的是一元函数。也就是说只有一个变量x,求导的结果是一个具体的值,它是一个标量。而多元函数在某个点求导的结果是一个向量,n元函数的求导的结果分量就是n,导数的每个分量是对应的变量在该点的偏导数。这个偏导数组成的向量,就是这个函数在该点的梯度。
那么,根据上面的定义,我们可以明确一点,梯度是一个向量,它既有方向,也有大小。
梯度的解释
维基百科当中还列举了两个关于梯度的例子,帮助我们更好的理解。
第一个例子是最经典的山坡模型,假设我们当下站在一个凹凸不平的山坡上,我们想要以最快的速度下山,那么我们应该该从什么方向出发呢?很简单,我们应该计算一下脚下点的梯度,梯度的方向告诉我们下山最快的方向,梯度的大小代表这点的坡度。
第二个例子是房间温度模型,假设我们对房间建立坐标系,那么房间里的每一个点都可以表示成 (x, y, z) ,该点的温度是 f(x, y, z)。如果假设房间的温度不随时间变化,那么房间里每个点的梯度表示温度变热最快的方向,梯度的大小代表温度变化的速率。
通过这两个例子,应该很容易理解梯度的方向和大小这两个概念。
举例
假设f是一个定义在三维空间里的函数,那么,f在某一点的梯度,可以写成:

这里的 i, j, k 都是标准单位向量,表示坐标轴 x, y, z的方向。
我们举个例子:

套入刚才的梯度公式,可以得到:

如果我们知道 x, y, z的坐标,代入其中,就可以知道对应的梯度了。
梯度下降法
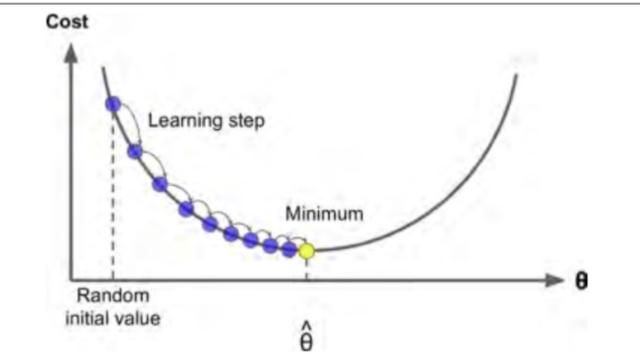
理解了梯度的概念之后,再来看梯度下降法其实就是一张图的事。请看下面这张图。

这里的黑色的曲线表示我们损失函数的函数曲线,我们要做的,就是找到这个最佳的参数x,使得损失函数的值最小。损失函数的值达到最小,也就说明了模型的效果达到了极限,这也就是我们预期的。
我们一开始的时候显然是不知道最佳的x是多少的(废话,知道了还求啥),所以我们假设一开始的时候在一个随机的位置。就假设是图中的x1的位置。接着我们对x1求梯度。
我们之前说了,梯度就是该点下降最陡峭的方向,梯度的大小就是它的陡峭程度。我们既然知道了梯度的方向之后,其实就很简单了,我们要做的就是朝着梯度下降,也就是最陡峭的方向向前走一小步。
我们假设,x1 处的梯度是 s1,那么我们根据 s1 通过迭代的方法优化损失函数。说起来有些空洞,我写出来就明白了。
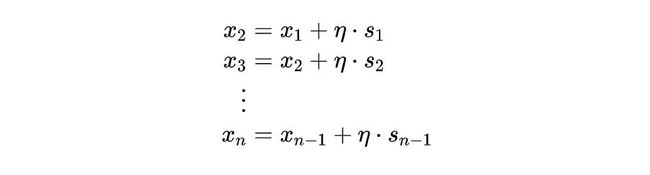
从上面这个公式可以看出来,这是一个迭代公式。也就是说我们通过不停地迭代,来优化参数。理论上来说,这样的迭代是没有穷尽的,我们需要手动终止迭代。什么时候可以停止呢?我们可以判断每一次迭代的梯度,当梯度已经小到逼近于0的时候,就说明模型的训练已经收敛了,这个时候可以停止训练了。
这里的 η 是一个固定的参数,称为学习率,它表示梯度对于迭代的影响程度。学习率越大,说明梯度对于参数变化的影响越大。如果学习率越小,自然每一次迭代参数的变化也就越小,说明到收敛需要的迭代次数也就越多,也可以单纯理解成,收敛需要的时间也就越长。
那么是不是学习率越大越好呢?显然也不是的。因为如果学习率过大,很有可能会导致在迭代的过程当中错过最优点。就好像油门踩猛了,一下子就过头了,于是可能会出现永远也无法收敛的情况。比如我们可以参考下面这张图:

从这张图上可以看到,变量一直在最值附近震荡,永远也达不成收敛状态。
如果学习率设置得小一些是不是就没事了?也不是,如果设置的学习率过小,除了会导致迭代的次数非常庞大以至于训练花费的时间过久之外,还有可能由于小数的部分过大,导致超出了浮点数精度的范围,以至于出现非法值Nan这种情况出现。同样,我们可以参考一下下图:

这张图画的是学习率过小,导致一直在迭代,迟迟不能收敛的情况。
从上面这两张图,我们可以看得出来,在机器学习领域学习率的设置非常重要。一个好的参数不仅可以缩短模型训练的时间,也可以使模型的效果更好。但是设置学习率业内虽然有种种方法,但是不同的问题场景,不同的模型的学习率设置方法都略有差别,也正因此,很多人才会调侃自己是调参工程师。
我们来看一下一个合适的学习率的迭代曲线是什么样的。
到这里还没有结束,好的学习率并不能解决所有的问题。在有些问题有些模型当中,很有可能最优解本身就是无法达到的,即使用非常科学的方法,设置非常好的参数。我们再来看一张图:

这张图有不止一个极值点,如果我们一开始的时候,参数落在了区间的左侧,那么很快模型就会收敛到一个极值,但是它并不是全局最优解,只是一个局部最优解。这时候无论我们如何设置学习率,都不可能找到右侧的那个全局最优解。同样,如果我们一开始参数落在了区间右侧,那里的曲线非常平坦,使得每次迭代的梯度都非常小,非常接近0.那么虽然最终可以到达全局最优解,但是需要经过漫长的迭代过程。
所以,模型训练、梯度下降虽然方法简单,但是真实的使用场景也是非常复杂的。我们不可以掉以轻心,不过好在,对于线性回归的最小二乘法来说,损失函数是一个凸函数,意味着它一定有全局最优解,并且只有一个。随着我们的迭代,一定可以达到收敛。
代码实战
Talk is cheap, show me the code.
光说不练假把式,既然我们已经学习到了梯度下降的精髓,也该亲身用代码体验一下了。我们还是用之前线性回归的问题。如果有遗忘的同学可以点击下方的链接回顾一下之前的内容:
机器学习基础——线性回归公式推导(附代码和演示图)
还是和之前一样,我们先生成一批点:
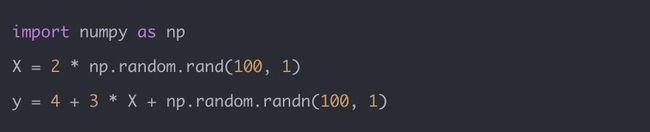
这是根据函数 y = 3x + 4 随机出来的,我们接下来就要通过梯度下降的方法来做线性回归。首先,我们来推导一下梯度公式:
在使用梯度下降算法的时候,我们其实计算当前 θ 下的梯度。这个量反应的是当我们的 θ 发生变化的时候,整个的损失函数MSE(mean square error 均方差)会变化多少。而梯度,可以通过对变量求偏导得到。
我们单独计算 θj 的损失函数偏导,带入之前的损失函数公式,计算化简可以得到:
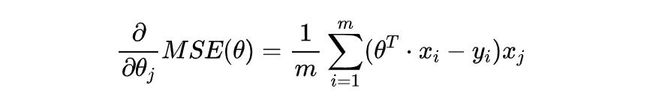
这只是 θj 的偏导数,我们可以把向量 θ 中每一个变量的偏导数合在一起计算。标记为:

我们不难看出,在这个公式当中,我们涉及了全量的训练样本X。因此这种方法被称为批量梯度下降。因此,当我们的训练样本非常大的时候,会使得我们的算法非常缓慢。但是使用梯度下降算法,和特征的数量成正比,当特征数量很大的时候,梯度下降要比方程直接求解快得多。
需要注意一点,我们推导得到的梯度是向上的方向。我们要下降,所以需要加一个负号,最后再乘上学习率,得到的公式如下:
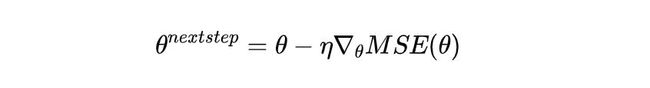
根据公式,写出代码就不复杂了:

我们调用一下这段代码,来查看一下结果:

和我们设置的参数非常接近,效果算是很不错了。如果我们调整学习率和迭代次数,最后的效果可能会更好。
观察一下代码可以发现,我们在实现梯度下降的时候,用到了全部的样本。显然,随着样本的数量增大,梯度下降会变得非常慢。为了解决这个问题,专家们后续推出了许多优化的方法。不过由于篇幅的限制,我们会在下一篇文章当中和大家分享,感兴趣的同学可以小小地期待一下。
梯度下降非常重要,可以说是机器学习领域至关重要的基础之一,希望大家都能学会。
今天的文章就到这里,如果觉得有所收获,请顺手点个关注或转发吧,你们的支持是我最大的动力。