YOLOv5 - yolov5s.yaml 文件

基于深度学习的目标检测模型的结构:输入->主干->脖子->头->输出。主干网络提取特征,脖子提取一些更复杂的特征,然后头部计算预测输出。
YOLOv5网络结构主要由以下几部分组成:
骨干网络(Backbone) :Backbone:骨干网络,主要指用于特征提取的,已在大型数据集(例如ImageNet|COCO等)_上完成预训练,拥有预训练参数的卷积神经网络,例如: ResNet-50、 Darknet53等
颈部网络(Neck):Neck:颈部网络,在Backone和Head之间, 会添加一-些用于收集不同阶段中特征图的网络层。
头部网络(Head):主要用于预测目标的种类和位置(bounding boxes)
YOLOv5的配置文件(通常是`.yaml`文件)包含了用于训练和测试YOLOv5模型的各种参数和超参数设置。
# YOLOv5 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple- nc 表示 "number of classes",即目标检测任务中的类别数量。
- depth_multiple 是模型深度的倍数,它用于调整YOLOv5的网络深度。在这里,它被设置为0.33,意味着模型的深度将是标准深度的1/3。
- width_multiple 是模型通道宽度的倍数,它用于调整YOLOv5的通道宽度。
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32anchors 参数包含了一组锚框(anchor boxes),每个锚框是一个宽度和高度的列表。这些锚框通常是在不同尺度的特征图上使用的,以便模型可以检测不同大小的目标。
每行对应一个不同尺度的特征图。在这个示例中,有三个不同尺度的特征图,分别是P3/8、P4/16和P5/32。每个特征图使用两个锚框,因此每个特征图有两行,每行包含了两个锚框。
每个锚框的宽度和高度的值是按顺序排列的,这些值通常是根据目标数据集和任务来选择的。
-
作用:
-
提供不同尺度的预定义边界框,以适应不同大小的目标。这些锚框有助于模型精确地定位目标的位置。
-
通过使用不同比例的锚框,模型可以更好地处理大尺寸和小尺寸的目标。
-
-
如何使用:
-
在训练YOLOv5模型时,
anchors参数会被用于计算目标检测框的损失函数。模型会预测每个锚框的位置和类别,然后使用这些预测值与真实目标框进行比较,从而计算损失。 -
模型会根据训练数据自动调整锚框,以便更好地适应目标的大小和形状。训练过程中,模型会学习如何根据预测值来调整锚框,以提高检测准确性。
-
在推理(测试)阶段,模型使用这些锚框来生成目标检测框。它会使用预测的坐标偏移量和锚框的宽度、高度来确定目标框的位置。模型会使用类别预测来确定目标的类别。
-
锚框的选择和调整通常会影响模型的性能和准确性。如果数据集包含特定尺寸和比例的目标,可以根据数据集的特点来选择或优化锚框的值,以获得更好的检测性能。
-
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]-
[[from, number, module, args]]:这个部分包含了一系列的网络模块,每个模块由一个列表表示。每个模块描述了一个阶段或层的配置。 -
[-1, 1, Conv, [64, 6, 2, 2]]:这是第一个模块,它执行卷积操作。具体来说,它执行了以下操作:from:-1 表示从上一个阶段继承特征图。number:1 表示只有一个卷积层。module:Conv 表示卷积层。args:[64, 6, 2, 2] 包含了卷积层的参数,包括输出通道数(64)、卷积核大小(3x3),步幅(2),和填充(2)等。
-
[-1, 1, Conv, [128, 3, 2]]:这是第二个模块,它也是一个卷积层,输出通道数为128,卷积核大小为3x3,步幅为2。 -
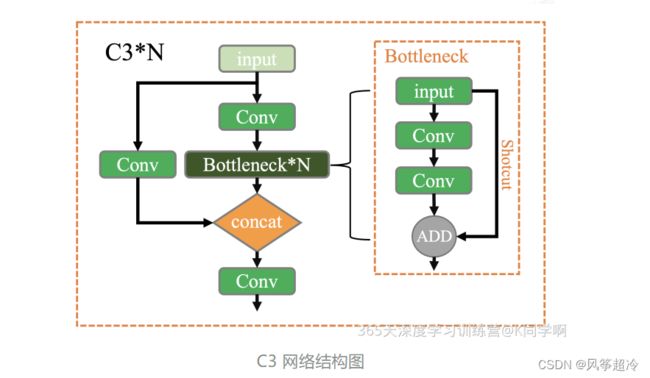
[-1, 3, C3, [128]]:这是一个C3模块,它执行一系列的卷积操作以提取特征。[-1, 3, C3, [128]]中的3表示它包含3个卷积层,[128]表示输出通道数。 -
类似地,接下来的模块定义了主干网络中的其他阶段,每个阶段包括不同数量的卷积层和特定的配置。
-
[-1, 1, SPPF, [1024, 5]]:最后一个模块是SPPF(Spatial Pyramid Pooling with Fused),它执行空间金字塔池化操作。这个操作用于捕获不同尺度的上下文信息,以提高模型的感知能力。
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
-
[[from, number, module, args]]:这个部分包含了一系列的网络模块,每个模块由一个列表表示。每个模块描述了一个阶段或层的配置。 -
[-1, 1, Conv, [512, 1, 1]]:这是第一个模块,它执行一个卷积操作。具体来说,它执行了以下操作:from:-1 表示从上一个阶段继承特征图。number:1 表示只有一个卷积层。module:Conv 表示卷积层。args:[512, 1, 1] 包含了卷积层的参数,包括输出通道数(512)、卷积核大小(1x1),步幅(1)等。
-
[-1, 1, nn.Upsample, [None, 2, 'nearest']]:这个模块执行上采样操作,将特征图的分辨率增加两倍。 -
[[-1, 6], 1, Concat, [1]]:这个模块使用Concat操作,将来自主干网络的P4特征图与当前特征图进行连接。 -
[-1, 3, C3, [512, False]]:这是一个C3模块,它包含了一系列卷积操作,用于处理特征。[512, False]表示输出通道数为512。 -
类似地,接下来的模块定义了头部网络中的其他阶段,每个阶段包括不同数量的卷积层和特定的配置。
-
[[17, 20, 23], 1, Detect, [nc, anchors]]:最后一个模块是Detect模块,用于执行目标检测。它将来自不同尺度的特征图(P3、P4、P5)进行连接,以便进行目标检测。nc表示类别的数量,anchors表示锚框的配置。