一文搞懂 MySQL 索引数据结构
一、索引数据结构
MySQL官方对索引的定义: 索引(Index)是帮助MySQL高效获取数据的数据结构。
这里面有2个关键词:高效查找、数据结构。对于数据库来说,查询是我们最主要的使用功能,查询速度 肯定是越快越好。最基本的查找是顺序查找,更高效的查找我们很自然会想到二叉树、红黑树、Hash 表、BTree等等。
1.1 二叉树
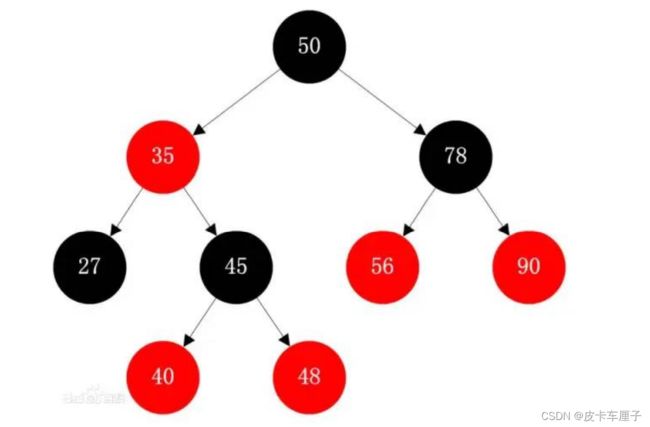
这个大家很熟悉了,他有一个很重要的特点:左边节点的键值小于根的键值,右边节点的键值大于根的 键值。比如图1,它确实能明显提高我们的搜索性能。但如果用来作为数据库的索引,明显存在很大的缺 陷,但对于图2这种递增的id,存储后索引近似于变成了单边的链表,肯定是不合适的。

1.2 红黑树
红黑树,也称平衡二叉树。在JDK1.8后,HashMap对底层的链表也优化成了红黑树。平衡二叉树的结构使树的结构较好,明显提高查找运算的速度。但是缺陷 也同样很明显,插入和删除运算变得复杂化,从而降低了他们的运算速度。对大数据量的支撑很不好, 当数据量很大时,树的高度太高,如果查找的数据是叶子节点,依然会超级慢。
1.3 BTree
B-Tree是为磁盘等外存储设备设计的一种平衡查找树。系统从磁盘读取数据到内存时是以磁盘块 (block)为基本单位的,位于同一个磁盘块中的数据会被一次性读取到内存中。在Mysql存储引擎中有 页(Page)的概念,页是其磁盘管理的最小单位。Mysql存储引擎中默认每个页的大小为16KB,查看方 式:
mysql> show variables like 'innodb_page_size';

我们也可以将它修改为4K、8K、16K。系统一个磁盘块的存储空间往往没有16K,因此Mysql每次申请 磁盘空间时都会将若干地址连续磁盘块来达到页的大小16KB。Mysql在把磁盘数据读入到磁盘时会以页 为基本单位,在查询数据时如果一个页中的每条数据都能有助于定位数据记录的位置,这将会减少磁盘 I/O次数,提高查询效率。
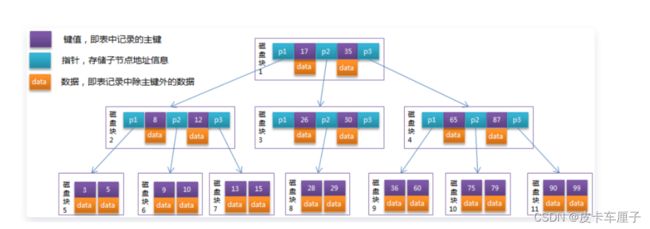
如上图所示,一棵B树包含有键值、存储子节点的指针信息、及除主键外的数据。相对于普通的树BTree 将横向节点的容量变大,从而存储更多的索引。
1.4 B+Tree
在B-Tree的基础上大牛们又研究出了许多变种,其中最常见的是B+Tree,MySQL就普遍使用B+Tree实 现其索引结构。

与B-Tree相比,B+Tree做了以下一些改进:
- 非叶子节点,只存储键值信息,这样极大增加了存放索引的数据量。
- 所有叶子节点之间都有一个链指针。对于区间查询时,不需要再从根节点开始,可直接定位到数 据。
- 数据记录都存放在叶子节点中。根据二叉树的特点,这个是顺序访问指针,提升了区间访问的性 能。 通过这样的设计,一张千万级的表最多只需要3次磁盘交互就可以找出数
Myisam和InnoDB的索引结构
1.Myisam
Myisam的数据文件是三个, 一个是原数据和结构, 一个是索引, 一个是数据,。索引和数据是分开,所以索引的上存的是地址值。
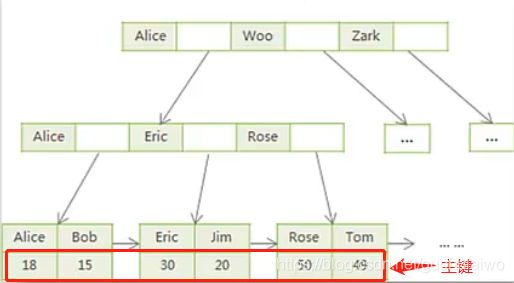
下图是主键的索引结构, B+Tree, 叶子节点(最下层)储存的是数据地址, 通过查询条件查询的时候, 查找的是数据地址, 通过数据地址拿到数据,

下图是普通索引的结构, 拿col2字段作为索引, 和主键查询是一样的, 查找的都是数据地址, 通过数据地址拿到数据

2.InnoDb
InnoDb的数据文件时一个, 所以, 表的索引和数据都是在一起的
主键索引, 索引和数据都是存放在一起的, 通过主键可以直接查询到数据。如果是普通索引,则通过普通索引查询到的数据是主键id, 通过主键id再去查询对应的数据, 这里就存在了一个回表的过程
补充:
为了满足MySQL的索引数据结构B+树的特性,必须要有索 引作为主键,可以有效提高查询效率。有的童鞋可能会说我创建表的时候可以没有主键啊,这个其实和 Oracle的rownum一样,如果不指定主键,InnoDB会从插入的数据中找出不重复的一列作为主键索引, 如果没找到不重复的一列,InnoDB会在后台增加一列rowId做为主键索引。所以不如我们自己创建一个主键。主键索引是聚簇索引,在物理磁盘上是顺序排列的,所以一个表最多只能有一个聚簇索引,因为物理存储只能有一个顺序。其他普通索引则是非聚簇的。
回表与索引覆盖和索引下推
- 索引覆盖:查询的所有【目标字段】都直接能从索引上拿到,不需回表就称为索引覆盖,即索引覆盖了所有目标字段。
如果旧查询中的目标字段没有索引,那将目标字段和条件字段建立联合索引,就能直接从索引拿到想要的数据。 - 回表:查询的目标字段A无索引,或A上有索引但未作为查询条件;查询条件B非聚簇索引,查询过程会先在B的索引树上扫描找到聚簇索引(通常是主键);然后再通过主键到聚簇索引树上找到整条记录,这个过程就叫回表。