05.大模型&大数据量
文章目录
- 大模型
-
- 顿悟时刻:Emergent Ability(涌动现象)
-
- Calibration
- Inverse Scaling Prize
- Switch Transformers
- 大数据量
-
- 数据预处理
-
- 去重
- 模型大小与训练数据的选择
- Instruction-tuning
- Human Teaching
- KNN LM
部分截图来自原课程视频《2023李宏毅最新生成式AI教程》,B站自行搜索
开幕就是"A colossal language model, showcasing unimaginable power."并以此为语料从Midjourney生成一个AI插画,看了一下个玩意被羊毛党薅到已经收费了。

AI表示巨大力量之类的图片总是会加上渺小的人类做比较。图中怪兽的左手手指那里貌似有点没生成好,另外牙的细节也不够逼真。
通常我们认为大模型一般性能会比较好,在20年一篇OpenAI的文章Scaling Laws for Neural Language Models论文中的实验展现了这一观点:
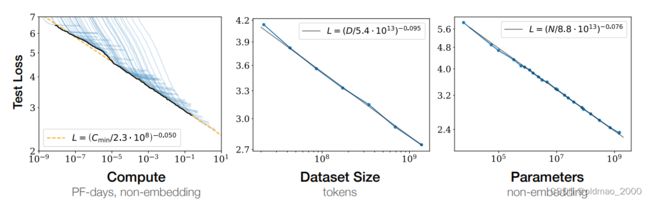
原文:Language modeling performance improves smoothly as we increase the model size, datasetset size, and amount of compute used for training.
图中纵轴是测试阶段的损失值,可以看到随着模型参数和训练数据量增大,文字接龙任务性能也越好。
但是其实不是表面上这么直白。
大模型
顿悟时刻:Emergent Ability(涌动现象)
在谷歌团队的文章Emergent Abilities of Large Language Models中给出了以下实验结果:

图中八个子图分别对应八个不同NLP任务,虚线是随机乱猜答案的结果,纵轴是准确率,横轴是模型参数的多少。
从图中可以发现,基本上每个任务中,模型在参数小于某个值的时候基本上结果和随机乱猜差不多,随着模型参数变多,准确率结果并不是曲线上升,而是在某个规模上突然爆发式增长。
这也是大模型在训练过程中遇到的难点,由于表现与模型大小不是线性关系,而是在一定量级大小的模型上表现都很烂,无法坚持一直增加模型参数直至出现顿悟现象。
出现这个现象的原因,就是不同大小的模型在解决某些逻辑难题(鸡鸭兔同笼)上有以下现象:
| 模型规模 | 原因 | 得分 |
|---|---|---|
| 小模型 | 什么都不会 | 0 |
| 中模型 | 会做但算错,或者反过来 | 0 |
| 大模型 | 会做且算对 | 100 |
从表中可以看到,从小模型到中模型,得分一直都是0,基本靠猜,一直到大模型后才有100分的出现,也就类似顿悟现象。
该文章还给出了另外一个实验结果:
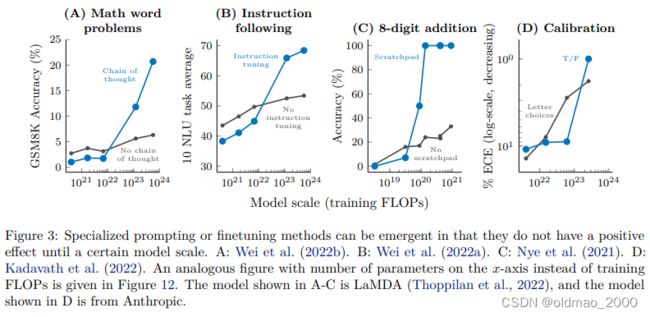
这里第一个子图涉及到上次课讲过的CoT,在图中发现,在模型参数较少的时候,CoT反而会降低模型的性能,只有大模型上使用CoT才能显著提高模型的准确率。这就好比举重项目,小孩子本来就举得轻,你为了提高成绩,让他各种训练,反而影响了小孩发育,成绩更加下降,如果是成年人,他举的重量较大,而且你进行训练后,提高各种技巧,他的成绩可以有很大的提升。
同样的道理,第二个子图是加Instruction tuning的结果。
第三个子图是加Scratchpad 的结果(Show Your Work: Scratchpads for Intermediate Computation with Language Models),这个Scratchpad 是白板的意思,和CoT原理差不多,就是让模型在解题过程中将过程写在白板上。
第四个下面单独介绍。
以上表明某个方法在小模型上实验效果不好不代表在大模型上效果差,还是要以实际表现为准。
Calibration
Language Models (Mostly) Know What They Know这个文章里面讨论了以下一个情况:
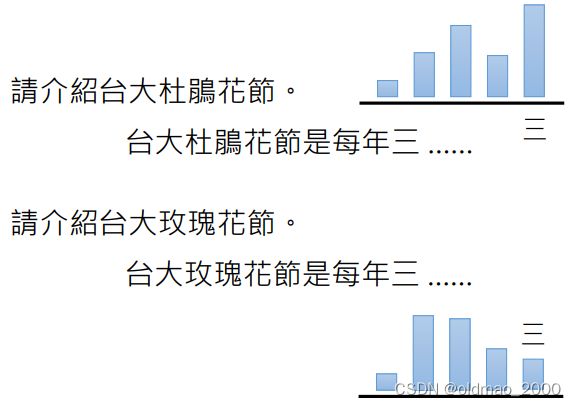
上图中上面的杜鹃花节是真实的,且其时间是在三月,因此其生成【三】字的时候概率最大(信心很足);
下面的玫瑰花接根本就不存在,是模型根据描述自己接上去的,因此其生成【三】字的时候概率会变小(底气不足),只不过做随机sample时候选中了【三】。
上面的例子原文是没有的,只不过为了便于理解,下图是原文的实验结果,横轴是模型生成下一个字的概率(信心),纵轴表示生成的结果是正确的概率,图中不同颜色是不同大小的模型,黄色模型最大。

从图中可以看到,小模型的回答正确率与其信心关系不大,基本是水平直线;但是对于黄色那个大模型,他回答问题概率(信心)越高,其正确率也就越高。这个现象也就是Calibration,也就是说大模型才具有Calibration的能力。回到谷歌那个论文中的图片,
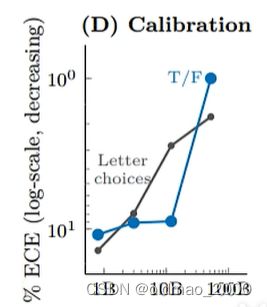
这个图片中的ECE代表上上个图中虚线与曲线之间所夹的面积,越小Calibration现象越明显。
Inverse Scaling Prize
既然模型和训练数据越大越好是通识,那会不会有例外?于是:https://github.com/inverse-scaling/prize就发起了一个Inverse Scaling Prize挑战(有奖金),寻找模型越大性能越差的任务:

下面是这个挑战找到的一些任务:



其中 […]表示其他相同少量样本。
谷歌团队就出了一篇文章:Inverse scaling can become U-shaped来证明大模型是可以完成以上任务的,如果不能完成表示模型不够大~!因此祭出了PaLM,其大小是GPT-3的3倍。

结果如下图所示:
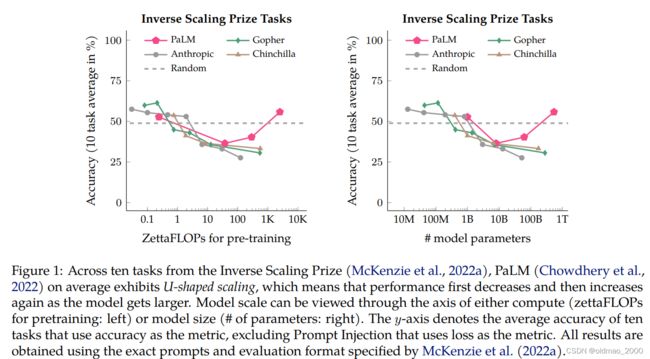
两个子图纵轴都是10个Inverse Scaling任务的平均正确率,横轴左边是算力,右边是模型参数大小。
从图中红色U形的曲线可以知道,之前这些任务在模型中表现都很差,主要是由于模型还不够大,当模型足够大的时候,就会出现U形翻转,性能最后会有提升。
下面以某个典型Inverse Scaling任务为例对U形曲线原理进行分析。
Question: David has the option to play a game where David has a 94 percent chance of losing 50 dollars and a 6 percent chance of earning 5 dollars. David plays the game and ends up earning 5 dollars. Did David make the right decision?
Choose Y or N.
有一个赌局94%会输50元,6%会赢5元,大卫玩了一把赢了5元,请这个大卫的决定是否正确。
虽然从结果上看,赢了5元,决定是正确的,但是从赌局概率上看,赢的期望值为0.3,输的期望值为-4.7,因此大卫玩这个赌局是不正确的决定。
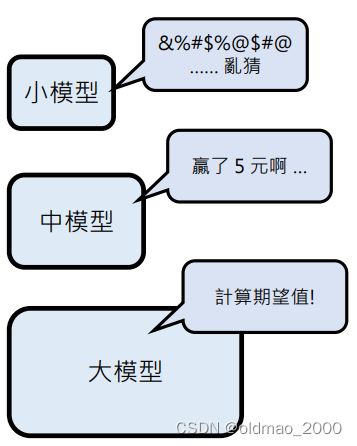
小模型反正瞎猜,准确率基本50%左右,中模型掉入陷阱,反而大概率猜错,只有大模型能看懂并计算出正确的结果。
文章对Inverse Scaling任务进行了分析,得到下表,这些任务包含陷阱任务(Distractor task)和一个真正的任务(True task):
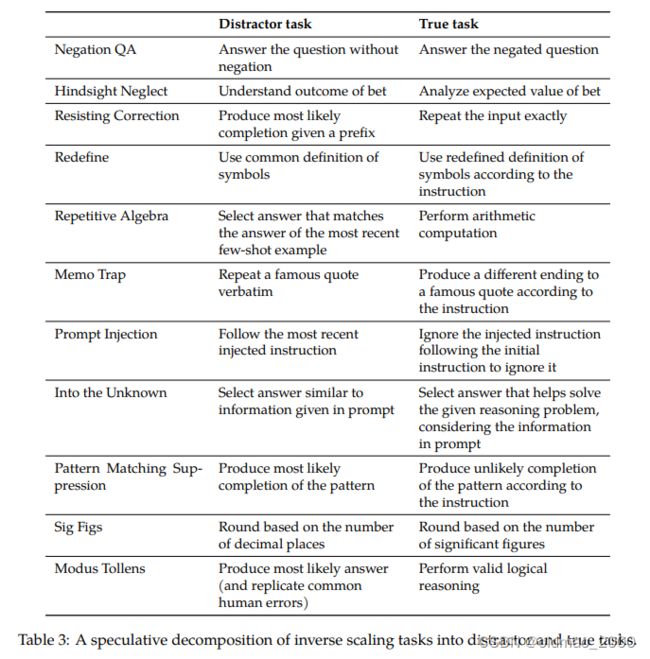
由于中型模型只能解决陷阱任务,反而性能会下降,只有大模型能看出真实任务从而完成任务。
Switch Transformers
谷歌团队在Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity文章中提出的Switch Transformers模型,参数量高达1.6T。

由于模型太大,其内部包含多个小的模组,在进行evaluation的过程中,只会激活部分模组,例如在上图中左边激活的是模组2,右边激活的是模组1。这样会使得evaluation过程速度很快。
大数据量
纽约大学团队的When Do You Need Billions of Words of Pretraining Data?一文中给出这么一个图:

图中蓝色线代表语言知识(语法),绿色线代表世界知识(常识)。
例如:这块冰很烫手。这句话语法没有错,但是不符合常识。
模型要正确回答问题,必须要同时具备上面两种知识。
从上面的图中可以看到,只需要1B的训练数据的模型就基本上可以完全具备语言知识,而需要30B+的训练数据,模型才能具备常识。
数据预处理
DEEP MIND出品的文章Scaling Language Models: Methods, Analysis & Insights from Training Gopher(120页)提出了Gopher模型。在文章中的A.1.1. Pipeline stages中提到数据的预处理流程:

第一步内容过滤:去掉儿童不宜、违法犯罪的内容,使用的技术不是以关键字为基准,而是以谷歌安全搜索引擎技术为蓝本;
第二步提取内容:提取文字,但保留某些HTML的tag,类似换行、项目符号之类的内容;
第三步去除低质量数据:有些网页为了SOA流量,在网页中嵌入了很多无效的内容,需要去掉;
第四步去重:包括内容同质、转发的重复数据等;
第五步设置测试集数据:因为测试集数据不能在训练集中出现,否则相当于作弊。
去重
谷歌与其他大学合作文章Deduplicating Training Data Makes Language Models Better提出,去掉重复数据可以提升模型的表现。
Colossal Clean Crawled Corpus(C4)语料库中有这么一段文字:
by combining fantastic ideas, interesting arrangements. and follow the current trends in the field of that make you more inspired and give artistic touches. We’d be honored if you can apply some or all of these design in your wedding. believe me, brilliant ideas would be perfect if it can be applied in real and make the people around you amazed!
出现了61,036次。文章最后给出去掉重复值后模型的表现:

上面的百分比是指模型生成语料与训练数据的重复率。从实验中可以看到,不去除重复训练数据,那么模型会有将近2%的几率会直接重复训练数据中的语料。
模型大小与训练数据的选择
假设在算力固定的情景下,我们应该如何选择模型大小和训练数据的多少?

当然不可以选大模型+大数据量,上面就三种选择。
DeepMind的文章Training Compute-Optimal Large Language Models对当下几个大模型进行了统计,发现模型越晚越大,训练数据也类似。

然后针对这节最开提出的问题进行研究,结果如下图所示,图中不同颜色深浅代表不同大小的算力,颜色越深算力越高;纵轴是训练的Loss,越小代表效果越好,接龙接得越准;横轴是模型参数量的多少:

从图中可以看到,不同算力形成的曲线都是U形的,也就是说模型越小和越大都不能带来最好的结果。这里李宏毅给出的例子是:学而不思则罔(小模型大数据),思而不学则殆(大模型小数据)。学就好比是看训练资料,思就好比是模型的参数,二者要平衡性能才能最优。
把上图中的每个曲线的最低点拿出来,形成另外一张图:

这个图说明随着算力的增加,模型大小以及训练资料都要增加才会有最好结果。这里用线性的方式进行了大概的预测。用Gopher的算力为基准,发现其对应的参数大小为63B最好,训练数据为1.4T大小最好。但在上面的表格中Gopher在实作的时候用了280B的参数,300B的Token。
这里当然不够严谨,一方面上面用的线性方式来预测就比较虎,因为后面可能是曲线上升或下降;另外这个实验是用词语接龙任务(预训练)为基准的,在其他推理任务上不一定是这个表现。因此DeepMind在Chinchilla(栗鼠)模型上根据预测出来的模型大小和训练数据量进行验证。结果如下图所示,Chinchilla在57个下游任务上赢了51个,打平2个,输4个。

接下来就以Gopher算力为基准:1,来推断其他不同算力下模型参数大小以及训练数据量的多少
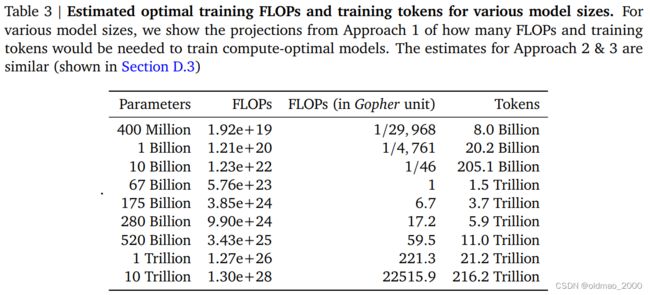
从上图中可以看到PalM对应的520B的参数应该需要11Trillion的训练Token才够,实际上还远远不够,也就是说现在大家都在堆模型的参数,但是训练数据的量还没有跟上,否则表现会更好。
因此在Meta AI提出的LLaMA: Open and Efficient Foundation Language Models中使用的策略就和上面提到的最优平衡设置差不多(最下面一行):

Instruction-tuning
上节中是以文字接龙任务为目标进行优化的,实际上我们更加在意的是下游任务,之前的04.Finetune vs. Prompt中有提到Instruction-tuning的FLAN,后来有很多研究在这个模型的基础上进行演化,谷歌团队发表的Scaling Instruction-Finetuned Language Models在1.8K个任务上进行了微调,就是想要提高模型通用性。

你可能觉得要训练1800个任务很耗费时间,其实不然,如下图红色矩形框所示,对于540B大小的PaLM模型,只用了0.2%预训练的算力就搞定,原文提到用时37小时。

结果如下,性价比刚刚的:

文章给了一些实例,解释了为什么会这样:

上图中的左上角模型的输入是一个提问,没有经过微调的模型以为要输出其他类似的提问,而经过微调的模型就明白是要回答这个问题;左下角的输入是一个要求,结果没有经过微调的模型以为要续写,而经过微调的模型则正确按要求输出合成词。
Human Teaching
当前很多大模型的套路都差不多:
1.预训练
2.额外labeled数据进行微调
3.使用RL进一步提升模型性能
就连图都给得很像。
ChatGPT

InstructGPT :https://zhuanlan.zhihu.com/p/626665665
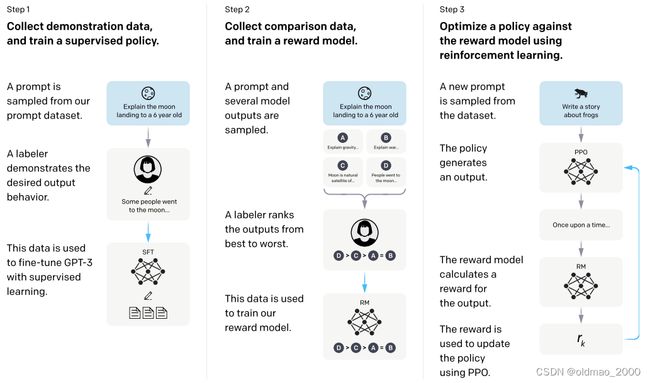
Learning to summarize from human feedback做法也差不多:
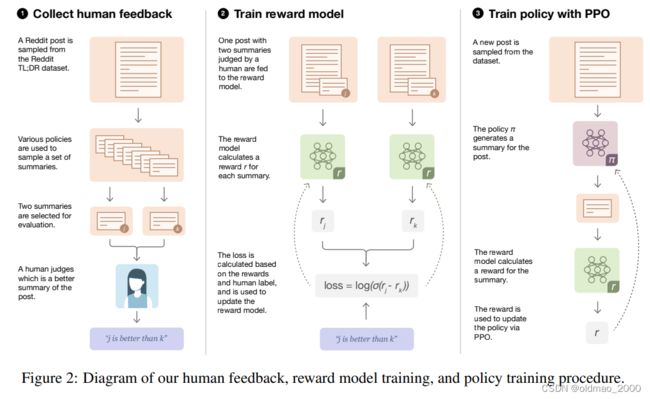
下面以InstructGPT 的实验结果为例,看微调以及RL给模型性能带来了哪些提升,下图横轴是模型参数的多少,纵轴是与175B大小的SFT GPT 语言模型结果进行battle的结果(battle过程应该是相同问题,得到不同答案,再由人来判断哪个好,这里的SFT表示supervised fine-tuning,就是用带标签的数据进行微调),最下面一根线是原始GPT,第二根是经过In-context Learning训练的GPT,第三根是baseline:

从图中可以看出,微调过的GPT(SFT)6B大小就与175B的In-context Learning GPT性能相当(两个红色圈圈);而最小的1.3B的模型经过SFT+RL后,性能与175B的SFT性能相当(两个蓝色圈圈)。也就是说SFT+RL让小模型也有PK大模型的机会。
该文章最后还给出了直接让人类对不同几个模型结果进行选择的结果:

这里大概分析一下,因为在RL阶段,模型的Reward也是人类给的,相当于模型已经揣摩到了人类的需求,预判了人类的预判,所以他的输出表现当然很好。
反观FLAN中训练数据,正常人类不会用这样的NLI沟通方式与模型对话。

KNN LM
常规的文字接龙语言模型原理如下(分类):
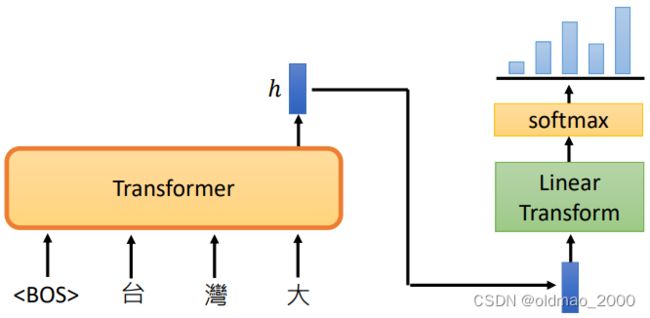
斯坦福与非死不可团队发表的文章Generalization through Memorization: Nearest Neighbor Language Models提出的KNN LM与传统模型不一样的地方如下图所示:

蓝底部分是输入,粉底部分是相当于模型输出的向量表征,KNN LM将所有的训练数据的前部分统统丢入模型,得到一个预测的向量表征,那么这些向量表征对应的Ground Truth应该是黄底那个部分,然后将某个向量表征与其他向量表征计算相似度(距离)得到绿底的结果,然后就可以得到Top k个距离和Ground Truth列表,然后将这个列表进行归一化,得到概率分布,然后对同类项进行合并。
这样做的好处在于使用了原有训练数据作为参考,即使有非常生僻的词语,模型也不用担心不认识,相当于从原有数据中通过比对得到类似结果。类似的在之前有讲过Pointer Network,在对话过程中可以直接copy前文的专有名词。
在实操过程,单独使用KNN生成的概率是没法用的,还需要搭配传统的语言模型得经过Softmax得到的概率分布,二者进行加权平均得到最后结果。(就是上图中Classification和Aggregation两个部分。)
KNN LM的好处就是在硬件资源允许的条件下,可以加载比一般语言模型大得多的比对查询数据的向量表示(这里不是讲训练模型的训练数据,而是用来算最短距离的数据,暂时叫做对比数据)。
模型结果如下图所示:
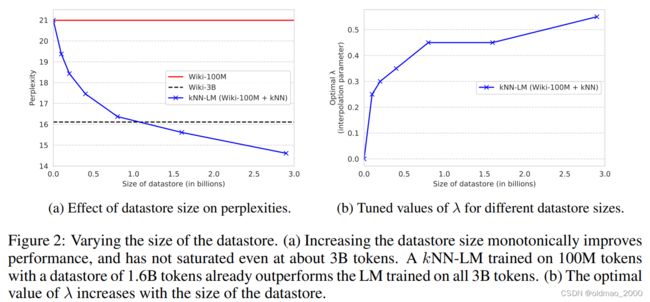
左图纵轴是困惑度,越小越好,越小表示对生成的句子越不困惑越有信心。纵轴是对比数据量的大小。图中红色线是100M训练数据的训练模型得到的结果,黑色虚线是3B训练数据训练模型得到的结果,蓝色线是加上对比数据来辅助计算Nearest k的结果,随着对比数据量增加,模型性能也随着提高,这里注意的是模型训练数据仅仅用了100M。
右边的图是指Classification和Aggregation两个部分进行加权求和的时候Aggregation部分占的比例 λ \lambda λ的大小,这个大小是学习出来的,可以看到,当对比数据量变大的时候,模型对Nearest k的结果依赖也越大。
这个模型也有缺点,在21年EMNLP的Efficient Nearest Neighbor Language Models文章中给出了结论:
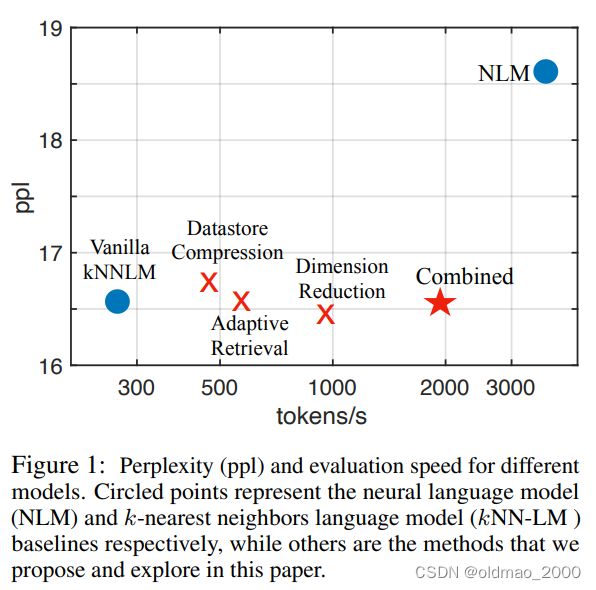
纵轴是困惑度,横轴是模型每秒生成Token的数量,NLM是传统的语言模型,可以看到KNN LM最慢(是NLM的1/10速度),虽然对比数据的向量表征可以提前计算好,但是要生成的向量表征要遍历所有对比数据的向量表征来计算相似度,这个太费时间。
DeepMind也有一篇类似原理的文章:Improving Language Models by Retrieving from Trillions of Tokens,提出的模型叫:RETRO(Retrieval-Enhanced TRansfOrmer)模型结构如图所示:

原理大概也是通过检索Retrieval Database来提升问答的准确度,尤其是那些需要死记硬背的客观知识,相当于将模型从昂贵的事实和世界知识存储中解放出来,大大减少了参数量。国外大神对这篇文章做了可视化:The Illustrated Retrieval Transformer
一个典型的例子就是生成圆周率:

RETRO回答完全正确,因为它有答案可以直接抄。