语雀宕机8小时,是否说明现在高可用架构很脆弱?
系列文章目录
高并发架构去重难?架构必备技能 - 布隆过滤器
当Dubbo遇到高并发:探究流量控制解决方案
主从选举机制,架构高可用性的不二选择
面试Dubbo ,却问我和Springcloud有什么区别?
消息队列选型——为什么选择RabbitMQ
语雀宕机8小时,是否说明现在高可用架构很脆弱?
- 系列文章目录
- 一、语雀宕机事件
- 二、高可用架构很脆弱?
- 三、高可用思路与判定
-
- 1. 梳理高可用思路
- 2. 高可用度量指标
- 四、常用高可用方案

最近IT圈又发生了一次P0级事故,就是蚂蚁旗下协同工具 —— 语雀宕机了8小时,导致不少人无法使用,怨声载道。虽然事情最后解决了,语雀也赔偿了我们半年的VIP,但是也让很多人有了疑问,我们天天说高可用,工作谈,面试问,为什么大企业仍然还会出现这种重大事故?是否说明现在高可用架构是花架子,实际不堪一击?本期我们加更一篇,就是细细和大家分析下目前的高可用状况
作者简介:战斧,从事金融IT行业,有着多年一线开发、架构经验;爱好广泛,乐于分享,致力于创作更多高质量内容
本文收录于 架构 专栏,有需要者,可直接订阅专栏实时获取更新
高质量专栏 云原生、RabbitMQ、Spring全家桶 等仍在更新,欢迎指导
Zookeeper Redis dubbo docker netty等诸多框架,以及架构与分布式专题即将上线,敬请期待
一、语雀宕机事件
就在几天前,也就是10/23日,知名在线文档编辑与协同工具——语雀,发生P0级事件,所谓P0级事件,其实就是最高级别的事故,通常出现了系统崩溃、无法使用或严重功能故障的情况。我们先来看一下官方的说明:
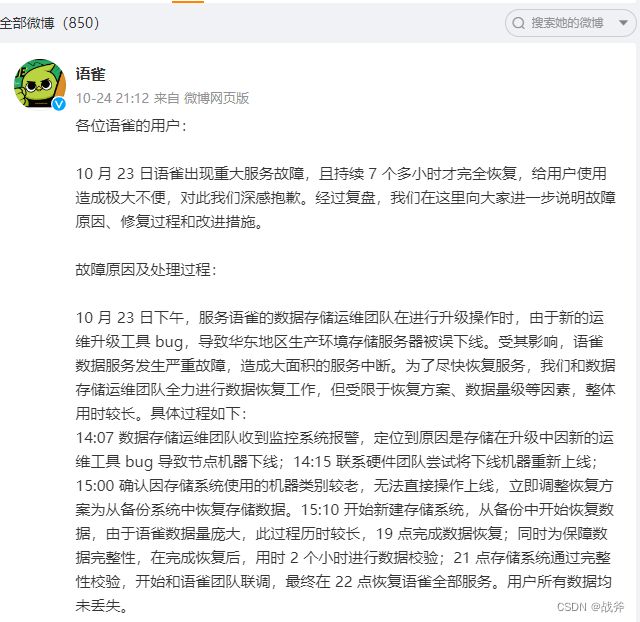
我们来捋一下时间轴:
- 14:07 数据存储运维团队收到监控系统报警,定位到原因是存储在升级中因新的运维工具 bug 导致节点机器下线;
- 14:15 联系硬件团队尝试将下线机器重新上线;
- 15:00 确认因存储系统使用的机器类别较老,无法直接操作上线,立即调整恢复方案为从备份系统中恢复存储数据。
- 15:10 开始新建存储系统,从备份中开始恢复数据,由于语雀数据量庞大,此过程历时较长,
- 19 点完成数据恢复;同时为保障数据完整性,在完成恢复后,用时 2 个小时进行数据校验;
- 21 点存储系统通过完整性校验,开始和语雀团队联调
- 22 点恢复语雀全部服务。用户所有数据均未丢失。
虽然还没有具体披露是什么Bug导致的,但是从处置手段来看语雀确实是比较及时了,并没有什么浪费什么时间,但因为数据量的原因,恢复备份和数据校验非常耗时,导致最终恢复还是用了8小时之久。
二、高可用架构很脆弱?
其实不止语雀,我们盘点下最近几年一些知名的事故:
-
2021年2月25日,
滴滴出行发生了一次服务器宕机事件,导致大量用户无法提示“服务器异常,请稍后重试”。该事件的原因疑似是是服务器负载过大,导致崩溃。 -
2022年12月18日,
阿里云香港发生了一次大规模的宕机事故,影响了众多用户的使用。经过调查,事故原因是阿里云香港的数据中心因制冷设备故障导致服务器过热,触发消防系统喷淋,电源柜和多列机柜进水宕机。 -
2023年3月5日,
B站发生大规模故障,无法观看视频和刷新推荐内容;部分用户能看见繁体内容,疑似是负责视频的部分微服务宕机导致。

不难发现,一些上热搜的事故往往都是巨头企业,而往往这些企业也非常强调高可用,它们频频出现大事故,这是不是意味着我们现在的高可用架构很脆弱?
答案其实是否定的,我们必须要明白一点:完全的可用性保证并不存在,而且事故发生的原因总是不同:硬件故障、运维事故、程序BUG。任何一点出现问题,都可能导致严重后果。也就是我们说的总会有百密一疏;而且企业运行需要考虑成本,很多高可用设计都会导致过高的成本,企业并不会采用的。
所以凭良心说,对高可用的追求颇有些 “尽人事,听天命”的悲壮。
三、高可用思路与判定
1. 梳理高可用思路
对于架构来说,高可用(High Availability,简称 HA)指的就是在系统出现故障或异常情况时,系统能够继续保持持续性、稳定性、可用性的能力。具体来说,我认为 高可用架构在设计时,其核心思想就是冗余,冗余包括以下三个方面:
-
硬件冗余
通过增加硬件冗余来保证系统的可用性。硬件冗余可以包括:RAID磁盘阵列、双机热备等。 -
应用程序冗余
通过复制多个应用程序实例来保证系统的可用性。应用程序冗余可以包括:负载均衡、冗余服务器*等。 -
数据冗余
通过备份和复制来保证系统的可用性。数据冗余可以包括:数据备份、主从复制、分布式存储系统等。
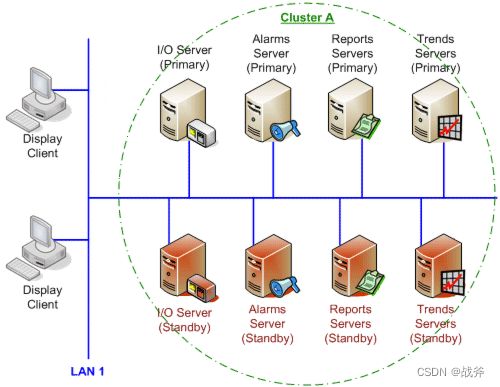
如上图,我们就是给每个服务都去做备份设计,在有了足够的冗余设计之后,高可用的下一个关键词就是自动化。系统最好能进行 请求自动分流、数据自动备份、故障自动切换 ,我们前面介绍了很多框架,其中不少中间件的集群都支持自动选主、主从复制等功能,自动化场景下,数据处理无疑更快。而且即使出现问题,它也会比人工发现更早,处理也更及时。
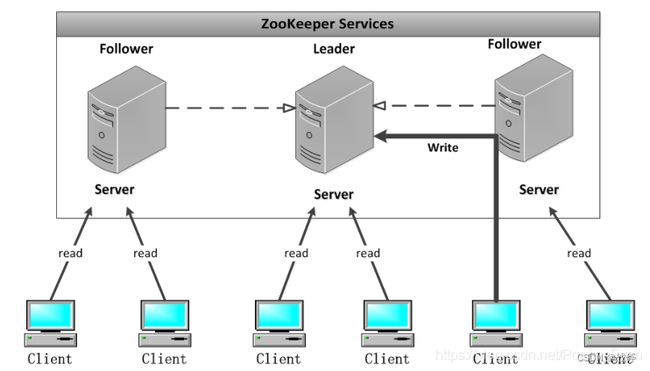
当然,对于一些一直在运行的古早项目,想要做它们的高可用还是比较困难的,因为很多服务最开始并没有设计冗余,也没有自动化设施。那么为了保障高可用,至少需要一个系统监控与告警系统。对服务的运行情况进行实时监控,一旦发现异常情况及时报警,由系统的工程师进行快速、及时的处理,以提高服务的高可用性
2. 高可用度量指标
目前,衡量高可用性的标准主要有几个方面:
可用性:可用性指标用百分比表示,例如,99.9%的可用性表示系统每年最多只出现8.7小时的停机时间。可恢复性:衡量系统在发生故障后,能够快速恢复到正常运行状态的能力。可恢复性指标包括故障恢复时间(MTTR)、故障恢复点(RPO)和恢复性能(RTO)容错性:容错性指标用于衡量系统在发生故障时,能够继续提供服务的能力。容错性指标包括可冗余性、容错机制和故障转移能力等
比如我们常说的可用性几个9,它代表的含义其实就是如下表所示
| 指标 | 计算结果 | 备注说明 |
|---|---|---|
| 1个9 | 90% (1-90%)* 365 =36.5天 | 系统在1年内服务中断的时间≤36.5d |
| 2个9 | 99% (1-99%)* 365 =3.65天 | 系统在1年内服务中断的时间≤3.65d |
| 3个9 | 99.9% (1-99.9%)* 365* 24 =8.76小时 | 系统在1年内服务中断的时间≤8.76H |
| 4个9 | 99.99% (1-99.99%)* 365* 24 =52.6分钟 | 系统在1年内服务中断的时间≤52.6min |
| 5个9 | 99.999% (1-99.999%)* 365* 24* 60 =5.26分钟 | 系统在1年内服务中断的时间≤5.26min |
| 6个9 | 99.9999% (1-99.9999%)* 365* 24* 60* 60 =32秒 | 系统在1年内服务中断的时间≤32s |
就目前来说,5个9的可用性对于绝大部分场景都够用了,当然了,它的实现难度其实也是很大的。而对于 MTTR 、 RPO 、 RTO,我们这里使用网上的一张图做简单解释:
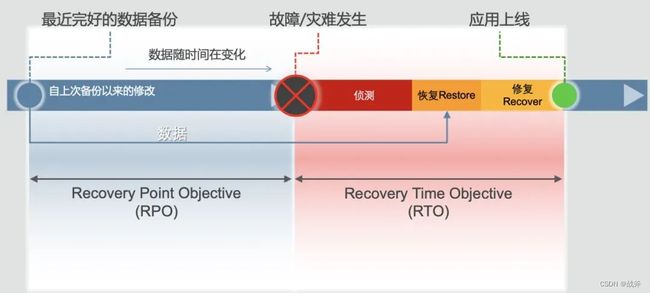
RPO(Recovery Point Objective) 是允许的故障后数据丢失的最大时间,其实可以理解为备份的时间间隔,例如,如果某个公司的RPO为1小时,则恢复系统后最多可以损失1小时的数据;
RTO(Recovery Time Objective) 是指在一个系统故障发生后,系统需要多长时间才能恢复到正常运行状态。例如,如果某个公司的RTO为2小时,则该公司需要在2小时内将系统恢复到正常运行状态
MTTR(Mean Time to Repair) 与 RTO 类似,但是是指修复恢复正常运行所需时间的平均值,所以对于运维来说,这个指标比较重要,考验的整个系统的恢复能力
我也给大家列举下如今金融行业对于IT系统容灾的标准,以供参考
| 容灾标准 | RTO | RPO | 适用对象 |
|---|---|---|---|
| 一级容灾标准 | 2小时内 | 15分钟内 | 重要性最高的金融机构,如大型银行、证券公司、保险公司等 |
| 二级容灾标准 | 4小时内 | 1小时内 | 对业务连续性和数据安全有较高要求的金融机构,如中型银行、金融服务公司 |
| 三级容灾标准 | 8小时内 | 2小时内 | 对业务连续性和数据安全有一定要求的金融机构,如小型银行、信用合作社 |
| 四级容灾标准 | 12小时内 | 4小时内 | 对业务连续性和数据安全有较低要求的金融机构,如金融科技公司、支付机构 |
| 五级容灾标准 | 24小时内 | 8小时内 | 对业务连续性和数据安全有一定要求但相对较低的金融机构,如小型金融科技公司、第三方支付平台 |
| 六级容灾标准 | 48小时内 | 24小时内 | 对业务连续性和数据安全要求相对较低的金融机构,如小型金融服务提供商 |
所以我们不难发现,高可用的指标本质上就是围绕着恢复速度、数据丢失来提出的
四、常用高可用方案
高可用方案有很多,遵循我们的思路,主打的就是 冗余 与 自动化,当然实现的方案种类也有很多,我们可以列举些常用的高可用方案:
-
负载均衡
负载均衡可以分为硬件负载均衡和软件负载均衡,硬件负载均衡需要额外的设备支持,而软件负载均衡可以通过配置软件实现。负载均衡可以分发请求到多个服务器上,将负载分散,提高系统的可用性。常用的负载均衡软件有:Nginx、LVS、HAProxy等。 -
双机热备
双机热备是指两台服务器之间实现相互备份,当一台服务器出现故障时,另一台服务器就能够自动顶替并继续工作。双机热备需要通过心跳机制来实现,常用的双机热备软件有:Keepalived、VRRP等。 -
分布式存储系统
分布式文件系统可以将数据存储在多个服务器上,通过数据切割和分发实现高可用和可扩展性。常见的分布式文件系统包括HDFS、GlusterFS、Ceph等。 -
多节点与容器化
多个节点作为一个整体提供服务,其中任意一个节点故障,其他节点可以接管它的工作,以保证系统的可用性。而容器化技术可以将应用程序打包成容器,在多个节点上部署,以实现高可用性和可扩展性。常见的容器化技术包括Docker、Kubernetes等。 -
数据中心容灾
数据中心容灾是通过在多个数据中心(通常是异地)建立冗余设备和系统,当一个数据中心发生故障时,其他数据中心可以接管它的工作,以保证业务的高可用性和可恢复性。
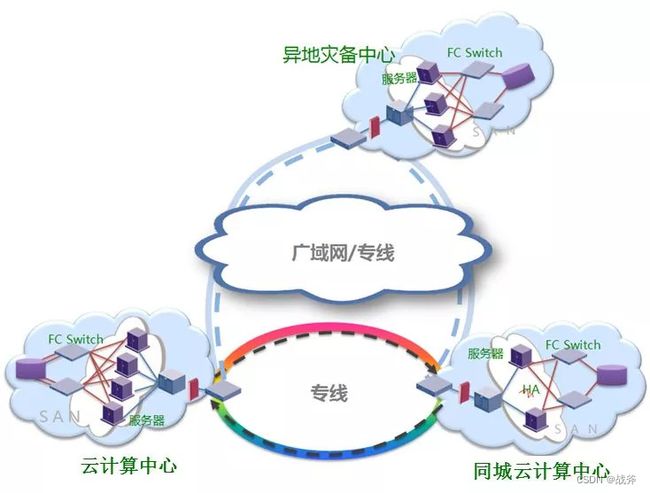
一般方案的取舍还是取决于业务和成本,实事求是的说,很多业务并不需要那么高的高可用,所以大可不必盲目追求要几个9,还是要考虑自己和公司的钱袋子是否支持。
当然,除了上面的技术,还有智能路由,虚拟化等技术来提高可用,而且在云时代,你也可以直接选择云计算平台:云计算平台本身就能将应用程序和数据存储在分布式网络上的多个服务器上,而且还提供多种技术和工具,如负载均衡、自动扩展、容错等。相当于把很多工作交给平台来处理了。
不过必须强调,云也不是打保票,正如我们前面所说的阿里云香港机房进水事故,发生的也是让人瞠目结舌。所以还是那句话——完全的可用性保证并不存在,我们只能利用现有的技术,在有限的成本中尽量做到最好