linux环境下Elasticsearch安装教程
linux环境下Elasticsearch安装教程
- 一、Elasticsearch简介
-
- 1、什么是全文检索
- 2、倒排索引
- 3、Elasticsearch的诞生与起源
- 4、ElasticSearch版本特性
- 5、ElasticSearch快速安装
- 6、客户端Kibana安装
- 7、Elasticsearch安装分词插件
一、Elasticsearch简介
ElasticSearch(简称ES)是一个分布式、RESTful 风格的搜索和数据分析引擎,是用Java
开发并且是当前最流行的开源的企业级搜索引擎,能够达到近实时搜索,稳定,可靠,快
速,安装使用方便。
客户端支持Java、.NET(C#)、PHP、Python、Ruby等多种语言。
官方网站: https://www.elastic.co/
下载地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
ElasticSearch应用场景
- 站内搜索
- 日志管理与分析
- 大数据分析
- 应用性能监控
- 机器学习
1、什么是全文检索
全文检索是指通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置、以及出现的次数;用户查询时可以通过之前建立好的索引找到单词对应的文本位置、出现的次数,从而读取到具体的内容。因此市面上常见的搜索引擎的实现简单概括的话可以分为如下几步:
- 内容爬取,停顿词过滤;
- 内容分词,提取关键词;
- 根据关键词建立倒排索引;
- 用户输入关键词进行搜索;
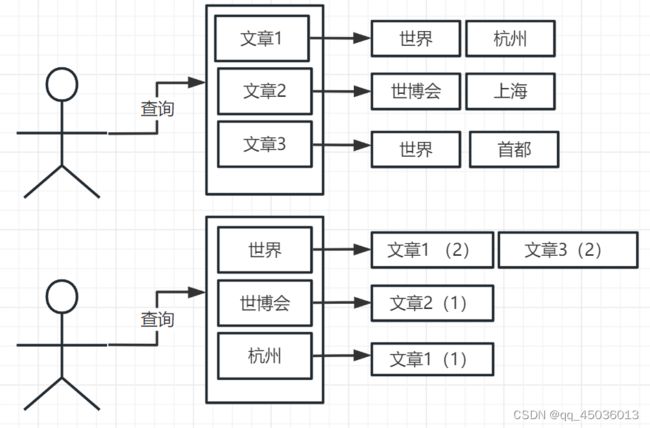
2、倒排索引
平时我们使用的都是索引,都是通过主键定位到某条数据,那么倒排索引呢,刚好相反,是数据对应到主键
简单理解,正向索引是通过key找value,反向索引则是通过value找key。ES底层在检索时
底层使用的就是倒排索引。

3、Elasticsearch的诞生与起源
Elasticsearch是构建在Apache Lucene之上的开源分布式搜索引擎。而Lucene是一个基于Java语言开发的搜索引擎库类,创建于1999年,2005年成为Apache 顶级开源项目,具有高性能、易扩展的优点。但是因为它只能基于java语言开发、类库的接口没有进一步封装,学习成本高,除此之外原生的Lucene并不支持水平扩展,因此当今的主搜索引擎框架以Elasticsearch为主。
- 2004年 Shay Banon 基于Lucene开发了Compass
- 2010年 ShayBanon重写了Compass,取名Elasticsearch
优点如下:
- 支持分布式,可水平扩展
- 降低全文检索的学习曲线,可以被任何编程语言调用
4、ElasticSearch版本特性
5.x新特性
- Lucene 6.x, 性能提升,默认打分机制从TF-IDF改为BM 25
- 支持Ingest节点/ Painless Scripting / Completion suggested支持/原生的 Java REST客户端
- Type标记成deprecated,支持了Keyword的类型
- 性能优化 内部引擎移除了避免同一文档并发更新的竞争锁,带来15% - 20%的性能提升
- Instant aggregation,支持分片上聚合的缓存 新增了Profile API
6.x新特性
- 集成了Lucene 7.x的新功能,如跨集群复制(CCR) 、索引生命周期管理 、SQL的支持 。
- 更友好的的升级及数据迁移,在主要版本之间的迁移更为简化,体验升级 ;全新的基于操作的数据复制框架,可加快恢复数据 。
- 性能上的优化,有效存储稀疏字段的新方法,降低了存储成本;在索引时进行排序,可加快排序的查询性能。
7.x新特性
-
集成Lucene 8.0 ,正式废除单个索引下多Type的支持;从7.1开始,Security 功能可以免费使用 ,ECK - Elasticseach Operator on Kubernetes 框架的广泛应用。
-
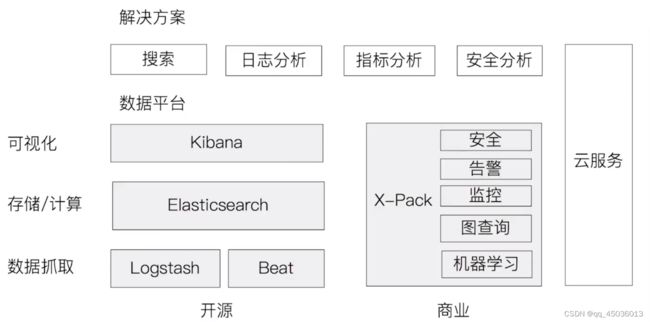
-
新功能,如 New Cluster coordination、 Feature——Complete High Level REST Client、Script Score Query 等。
-
性能优化 默认的Primary Shard数从5改为1,避免Over Sharding, 以及更快的Top K
8.x新特性
- Rest API相比较7.x而言做了比较大的改动(比如彻底删除_type)
- 默认开启安全配置
- 存储空间优化:对倒排文件使用新的编码集,对于keyword、match_only_text、text类型字段有效,有3.5%的空间优化提升,对于新建索引和segment自动生效。
- 优化geo_point,geo_shape类型的索引(写入)效率:15%的提升。
- 技术预览版KNNAPI发布,(K邻近算法),跟推荐系统、自然语言排名相关。
https://www.elastic.co/guide/en/elasticstack/current/elasticsearchbreakingchanges.html
5、ElasticSearch快速安装
下载地址: https://www.elastic.co/cn/downloads/past-releases#elasticsearch
选择版本:7.17.3

注意,如果是初学者也可以直接下载windows的版本,解压后无需配置直接启动,然后在浏览器中输入http://localhost:9200如下图所示即安装成功。

下载完以后登录Linux服务器将对应安装包放到特定位置。
Linux单机版安装:
1、打开SecureCRT,选择File->Connection SFTP Session->将下载好的jar包上传到对应目录
#如果当前用户是root用户,需要创建一个新用户来启动es
useradd es
passwd es 输入两次密码
#切换到es用户下
su es
#进入到es的家目录
cd /home/es
pwd
#回到root用户并将jar包复制
exit
cp /root/elasticsearch-7.17.3-linux-x86_64.tar.gz /home/es
sudo chown es:es elasticsearch-7.17.3-linux-x86_64.tar.gz
tar -zxvf elasticsearch-7.17.3-linux-x86_64.tar.gz
cd elasticsearch-7.17.3/config
vi elasticsearch.yml
vi jvm.options
2、修改对应的配置文件
elasticsearch.yml
- cluster.name:当前节点所属集群名称,多个节点如果要组成同一个集群,那么集群名称一定要配置成相同
- node.name:当前节点名称 path.data:配置数据存储目录,比如索引数据等
- path.logs:配置日志存储目录,比如运行日志和集群健康信息等
- bootstrap.memory_lock:配置ES启动时是否进行内存锁定检查,默认值true
- network.host:配置能够访问当前节点的主机,默认值为当前节点所在机器的本机回环地址127.0.0.1,可以配置为0.0.0.0,表示所有主机均可访问
- http.port:配置当前ES节点对外提供服务的http端口,默认值 9200 discovery.seed_hosts:配置参与集群节点发现过程的主机列表
- cluster.initial_master_nodes:配置ES集群初始化时参与master选举的节点名称列表,必须与node.name配置的一致
jvm.options调整jvm堆大小,如果当前虚机内核比较小,以1核1G为例建议配成512m
‐Xms4g
‐Xmx4g
3、启动ElasticSearch服务
Windows可直接运行elasticsearch.bat
cd ../bin
./elasticsearch #-d 后台启动
4、常见启动错误解决方案
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at
least [65536]
ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系
统当中打开文件最大数目的限制,不然ES启动就会抛错
#切换到root用户
vim /etc/security/limits.conf
#末尾添加如下配置:
soft nofile 65536
hard nofile 65536
soft nproc 4096
hard nproc 4096
[2]: max number of threads [1024] for user [es] is too low, increase to at least [4096]无法创建本地线程问题,用户最大可创建线程数太小
vim /etc/security/limits.d/20‐nproc.conf
#改为如下配置
soft nproc 4096
[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at
least [262144]
vim /etc/sysctl.conf
#追加以下内容
vm.max_map_count=262144
#保存退出之后执行如下命令:
sysctl ‐p
[4]: the default discovery settings are unsuitable for production use; at least one of
[discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must
be configured
缺少默认配置,至少需要配置
discovery.seed_hosts/discovery.seed_providers/cluster.initial_master_nodes中的一个
参数.
- discovery.seed_hosts: 集群主机列表
- discovery.seed_providers: 基于配置文件配置集群主机列表
- cluster.initial_master_nodes: 启动时初始化的参与选主的node,生产环境必填
vim ../config/elasticsearch.yml
#添加配置
discovery.seed_hosts: ["127.0.0.1"]
cluster.initial_master_nodes: ["node‐1"]
#或者单节点
discovery.type: node‐single
6、客户端Kibana安装
Kibana是一个开源分析和可视化平台,旨在与Elasticsearch协同工作
1)下载并解压缩Kibana
下载地址:https://www.elastic.co/cn/downloads/past-releases#kibana
选择版本:7.17.3

可以选择windows版本或linux版本。
2)修改Kibana.yml
tar -zxvf kibana-7.17.3-linux-x86_64.tar.gz
vim kibana-7.17.3-linux-x86_64/config/kibana.yml
server.port: 5601
server.host: 0.0.0.0 #服务器ip,如果是本地运行可以直接改成localhost,线上推荐这样改
elasticsearch.hosts: ["http://服务器公网ip:9200"]
i18n.locale: "zh‐CN" #Kibana汉化
3)运行Kibana:注意:kibana也需要非root用户启动
cd ../bin
./kibana
#后台启动
nohup ./kibana &
4、访问Kibana: http://localhost:5601/后输入GET /_cat/nodes 输出如下即为配置成功
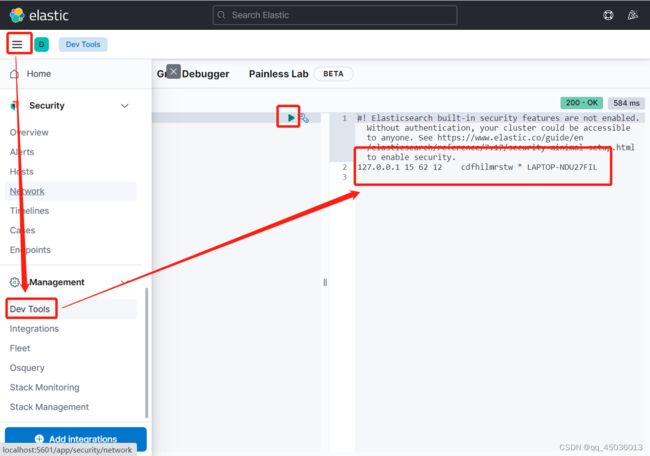
7、Elasticsearch安装分词插件
Elasticsearch提供插件机制对系统进行扩展
以安装analysis-icu这个分词插件为例
#查看已安装插件
cd /home/es/elasticsearch-7.17.3
bin/elasticsearch‐plugin list
#安装插件
./elasticsearch‐plugin install analysis‐icu
#删除插件
./elasticsearch‐plugin remove analysis‐icu
注意:安装和删除完插件后,需要重启ES服务才能生效。

