- 【精准解析】pdfplumber完全指南:从PDF中提取文本、表格与元数据的Python利器
Is code
技术技巧#文档处理扩展pythonpdf开发语言
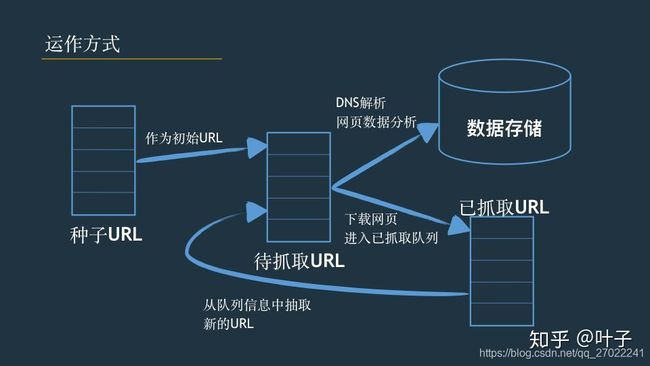
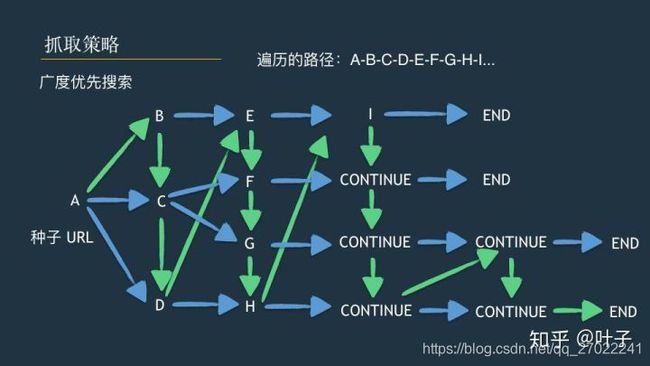
【精准解析】pdfplumber完全指南:从PDF中提取文本、表格与元数据的Python利器前言:为什么PDF内容提取如此重要?在数字化转型的浪潮中,海量信息被封存在PDF文档中-从金融报表到政府文件,从学术论文到商业合同。虽然PDF格式保证了文档的一致性展示,但同时也给数据提取带来了挑战。手动从PDF复制数据不仅耗时低效,还容易出错。企业和研究机构每年在PDF数据提取上花费数千小时,这一痛点催生
- ubuntu,linux下屏蔽坏块方法-240625-240702封存
张文君
python
在windows下的屏蔽坏道的方法机械硬盘坏道的文件系统级别的屏蔽方法_硬盘如何屏蔽坏扇区-CSDN博客https://blog.csdn.net/cyuyan112233/article/details/139408503?spm=1001.2014.3001.5502【免费】磁盘坏道屏蔽工具磁盘坏道屏蔽工具_机械硬盘屏蔽坏扇区资源-CSDN文库https://download.csdn.net
- 为什么TCP/IP协议栈要进行分层?
哈喽锋文~
网络知识网络协议
目录一、总结二、术语定义二、封存1、简介2、TCP/IPLayering(TCP/IP分层)1)TCP(TransmissionControlProtocol)传输控制协议2)UDP(UserDatagramProtocol)用户数据报协议3)IP(InternetProtocol)网际互连协议4)ARP(AddressResolutionProtocol)5)InternetAddress(IP
- Python学习第九天
Leo来编程
Python学习学习
序列化和反序列概念在Python中,序列化是将对象转换为可存储或传输的格式(如字节流或字符串),而反序列化则是将序列化后的数据重新转换为对象(官网序列化)。序列化:就是将不能存储的对象转为可存储的对象(封存pickling)。发序列化:序列化的对象返回成原来的对象(解封unpickling)。方式序列化和反序列化有下面五种方式pickle模块官网概念:pickle模块实现了对一个Python对象结
- 心语
萍飘夭涯
心情抑郁得很,心口似乎被堵住,不能呼吸。网络与现实,同样,荒凉。有一种熟悉,似乎近在咫尺,本能,习惯地一伸手,抓了一把空气。这才明白,熟悉,已远成冰凉。这里有一扇窗,封存了太多的疑问,那飞驰的地铁上,念有几重,关于朝霞与露珠的期会?心中有婉约成字,成伤,成了昨日黄昏的绝唱。坚硬,不该因为遇见而柔软,不该让南风空手而归。图片发自App
- 头号玩家(ready player one)
何必说太多
没有吸引我们的店铺,离饭点还有那么久,于是乎,淘票票下单了这部电影。同学说斯皮尔伯格怎么还在拍?他到底多大了?是呀,七十几岁的老爷子了,这次又站上了前沿-AI虚拟游戏。绿洲是哈利迪自我逃避的一项去处,可能现实中他的极度内向反而促使他更淋漓尽致地在游戏中释放自我。他渴望被爱、爱人,他将自己所有的一切记忆都封存到他游戏中的博物馆,他渴望被人了解。但是关于他所暗恋的女生,他只提到一次。我想,他是不是悔恨
- 出差去义乌的路上新作一首:《冬至千寻》!
千岛油菜子
图片发自App《冬至千寻》地球骑着太阳神的马在南回归线的来信下到达它的最南端趁着企鹅成群上岸的时候把白昼凝固成一块封存记忆的琥珀——千岛油菜子写于2019.12.22上午九点半多,出差去义乌的路上
- 散步小感
烟汀迷兮
故地,渐渐沦为虚无缥缈的记忆。所谓的新,已经以压倒性优势驱赶走了所谓的旧,甚至连楼下那块坑洼的地面,如今也用红砖砌得平整。可我,宁愿在这“旧”中苟活一生。柏油马路旁的公园,如今也已被拆的面目全非。在满纸荒唐面前,一切都显得脆弱不堪。透过隔离板的缝隙向内张望,徒留下遍地起伏的土丘,和着刺耳的风声,在苍白无力地叙述着昔日的景象。岁月的阿房宫,连一处颓圮的篱墙都不曾剩下。音乐声,欢笑声,被永远地封存于地
- 珍惜现在,不负相遇,告别过去的日子,迎接美好的未来
生活记录小胜
人生也不必因蹉跎而感伤。生命每天都在,悄无声息地流逝,轻盈而安靜,日子卻在岁月的年轮中渐次厚重。缘分,相信所有的经历,都是安排,顺其自然,无需强求,与文字为伴,将往事封存,寻一份安然,随遇而安。真正的幸福不是一个人的挽留,而是两个人的坚守,真情,不是一颗心单方面的付出,而是两颗心共同的呵护。告别过去,迎接未来,执念美好,无畏无惧,愿此生有人懂,有人爱,失去的都将释怀。人心不是走远的,感情不是变淡的
- 艺术市场如何从区块链中受益?
九卿逸墨
《中国美术报》第115期艺术财富艺术市场如何从区块链中受益?□ 永琰什么是区块链?“神通广大”的区块链到底是什么?其实,区块链技术是一种分散式数据库,它通过对等网络存储使用者的资产登记和交易信息,而且交易记录是通过密码被安全保护的,时间一过,交易记录会被封存在数据库里。这就创建了一个不可改变也不会丢失的记录。2008年,日裔美国人中本聪首次提出区块链的概念,其本质是一个去中心化的数据库。2009年
- 我有相思一壶酒
沐阳年华
图片来自网络我有相思一壶酒,存放在光阴的角落里,独自酝酿绵清幽香。酒入喉烧心头,醉眼看花影重重,踩风踏浪步跄跄。欲牵故人衣袖,握一手凉风微微颤抖。怎一个无情的错过,春深寒依旧。我有相思一壶酒,封存在岁月红尘万丈中,落款就是“慎启”。封印着前世今生的爱恨情痴。最怕一杯封喉,心醉后轻狂成疾,斩风月惊天地。怎奈悲欢痴嗔笑哭滚滚红尘。我有相思一壶酒,斟一杯酣醉了凡尘人间,再斟一杯思念溢满为谁醉?两杯三盏饮
- 微信红包封面序列号大全免费(新版微信红包封面序列号)
全网优惠分享
微信红包封面序列号,有一天,你突然收到了一个微信红包,点击进去,你会惊喜地发现,这个红包居然是一个序列号,而不是实际的现金。你有些许失望,但也充满了好奇心,纷纷猜测这个序列号究竟代表着什么。微.信搜索:「封面院」关注公众号可领取红包封面或许,这个序列号不仅仅是个数字的组合,它承载着一段无形的旅程。或许,它是一份心灵的红包,封存着我们内心最深处的渴望和希望。或许,它是一扇通向未知世界的大门,等待着我
- 女儿出嫁,那伟大的父爱满眼泪水
伊的家护肤师芬芬
没有人会想到,女儿出嫁时,是父亲最落寞的季节。噼里啪啦的一场热闹,唯留空荡荡的屋子,记忆中的银铃般的笑声被暂时封存,有的时候,时间比人更落寞。这个冬天会很冷吧?因为我的小棉袄被人穿走了……摄影师留下了动人的瞬间,父亲留下了真情的告白。看完瞬间泪点被狂戳。这是一段爸爸对女儿真情的告白......你小时候,不敢抱你怕胡渣弄疼你你长大了......只愿和妈妈交心,我只能在一边呵护你;你成年了,我天天盼你
- 南风追影
蜀宵泽
在胶卷上刻印下的时光于一帧帧画面中呈现,在回忆中存留着的画面于一个个故事中演绎。在光与影中,将那些封存于心的记忆慢慢拾起,细细品味。夜幕降临的时候,电影这位耐心的叙述者将为我们诉说一段段曲折的人生,带我们感受一场场悲欢离合。青春就是一件乐在其中却不知情,离开了满是感伤,回想起来又满是想法的事情。对于泰国的青春片我承认我一点抵抗力都没有。《初恋这件小事》在很多人的并不期待中汹涌袭来,校园味的海报,言
- 读书摘抄分享|《橘子不是唯一的水果》1
僭客
橘子不是唯一的水果时间能抹杀一切。人们遗忘,厌倦,变老,离去。当然,这并非事情的全貌,但故事就是这样讲的;我们随心所欲地编造故事。不把宇宙解释透彻,这是解释宇宙的好办法,也是让一切保持鲜活生动,而非封存在时间中的好办法。历史,常常是否认过去的一种办法。否认过去,就是拒绝承认它的完整和真实。修正它,强迫它,让它运转,榨出它的灵魂,直到如你所愿,你觉得它该什么样,它就什么样。在某种程度上我们都是历史学
- 你代表着尘世的希望
青灯先生
你承载着整个世界的开心姑娘,你不知道你自身所带的光芒如果前路被一团迷雾遮隐你潺湲的脚步在原地打转忍不住回头看过去美好的时光甚至向消逝的过往寻找前路请相信你自身就是个美丽的梦所有人都在未来迎接你的坚强你是自我发光照亮黑暗的太阳姑娘,你不知道作为女神你真正的力量如果你甘愿封存法力来承受苦难你一定要勇敢摈弃丑陋与肮脏果断与不如意的纠缠决裂洗尽铅华,始终保持最纯洁的模样请相信你代表着尘世的希望所有人都因你
- 《长安的荔枝》读书笔记
辛原
上林属小吏李善德和妻儿定居长安,找招福寺典座贷了香积贷,尽管功德(本金)深厚,福报(利息)连绵,他们还是买了房子,想着以后辛勤劳作早日还贷。刚到官署,李善德发现自己的领导刘属令准备了丰盛酒菜款待他,他在酒鼾饭饱后接下了为皇帝进贡荔枝煎的活。心想这活好啊,荔枝煎是用蜜蜡封存好的荔枝,东市就能买到,圣人怎么还特地设了个荔枝使?这个任务时间宽裕,内容轻松,关键是油水丰厚!这样一来,升职加薪,还清房贷,走
- 我的归宿
阶花雨过
我想乘着风来,要一个归宿!要一个归宿!重重的深门里,封存着月升花落的回忆,一阵阵急雨。长河上开着黑色的花,土地上弥漫着狂妄的烟。踱着轻步,揽月亭里长长的叹息。我要叩开你的心门,懂你走过岁月的无痕。我欢迎着你,夕阳里一片花开静谧的美妙,我的心语。翻飞的鸟鸣,御园里流转着风的软,你的热泪。我走过一座桥,合拢着手指,放生池是你诉说的眼睛,我的热泪。
- 我爱夏日黄昏,最是轻松辰光
jianfan
晚饭后的黄昏,是一天中最为轻松的辰光~我爱夏日黄昏,正好散发乘凉~脱去一日的琐碎,无所顾忌我享受。。。出门前,天空还大片的蓝天,转眼就乌云覆盖,蓝,只剩了一点点~风吹了一天,傍晚时候风力加大,要落雨了~以防万一,出门我带了伞,暗暗希望,雨儿雨儿你莫下,且等了我走路回来吧~云彩在天空任意涂抹,有种莫测的美~此刻云莫测,拍下且封存,闲来自怡悦,自我寻喜欢~任云彩簇拥,也难阻止太阳的光芒,痴恋着凡尘的太
- 知错就改善莫大焉
盺郡
封存又铭记,教训终不忘,重新再开始,为迟也不晚,——————任何一个领域赚的都是专业的钱,由此延伸隔行如隔山一样的说法,任何侥幸的心里都是一种暂时的,只有务实而踏实才是最好的出路。改邪归正终不悔,前方终将是大道,小道曲径又通幽,何似大道更光明。
- 过年
写作者红红
图片发自App文/冯无知一、进入腊月,就如同进入另一种神秘的意境那熟悉的年味,呼之欲出年猪,蠢蠢欲动即将释放,积蓄了一年的能量母亲熏的腊肉,腌的辣椒酱罐子里,封存着的,全是浓浓的亲情腊月的风,夹着家的味道在坊间奔走相告不经意间,触及外乡游子敏感的神经打此起,人们掰着手指数归期二、不知什么时起,人们口中挂着最多的一句是什么时候回去那张票根的事,成了人们心头的痛那是回家的通行证浸透了人们为之奋斗的汗水
- 草原的汉子广东妹儿第二十九篇
升戈
横舟根据伯父的介绍生哥和兰儿才明白,这片纯净的大陆在南极冰层下方,是冰河时期被故意封存保留下来的。整片大陆面积是现在地表陆地面积的一半还要多,在这个世界里没有动物只有植物。整个空间里既没有氧气也没有二氧化碳,完全是气化的能量。伯父带领众人极速穿行过一大片低矮彩色植被区域,眼前出现一座蔚蓝色水晶山丘。伯父伸手隔空在水晶山上轻轻一推就显出一座宫殿的大门,进入宫殿里面只有座椅床铺等简单摆设。伯父在一张宽
- 2022-08-09
勿拾心语
外婆家的小河我小时候网鱼的经历,一直封存在我的记忆深处,不曾遗忘过。小时候的乡下,无论是小河还在稻田里,到处都有小鱼小虾,泥鳅和黄鳝更是无穷无尽似的。那时的大自然就像一座生命的宝库,取之不尽,用之不竭。一到夏天的雨水季节,随便在任何一条小沟里都可以弄到这些东西:拿一个簸箕,放在沟口处,等个一二个小时去取,保证能有一顿鲜美、丰盛的菜肴。小时候最喜欢的事情就是:上山掏鸟蛋采蘑菇,下河摸鱼捉虾。山上和小
- 审视生死
栖居川上
听到你体检异样的消息,彻夜难眠,整天惴惴不安,思绪万千,好的,不好的,都涌上心头,几天没有你的消息,担心的茶饭不思,夜不能寐,嗨,就是这样的小心眼,悲观的人,怎么办?舌头长泡了,嘴角也起泡了,浑身都难受……两个星期过去了,终于没事啦!谢天谢地,好人好报!由此我重新审视生死:即使此刻无法相见,但我们曾经在一起的那些岁月,永远封存在心里。《小王子》中说:“重要的东西,眼睛是看不见的,就像花一样,如果你
- 你是我念念不忘的心酸
不渡璐璐
01始于心动,终于了解。只有小朋友才会问你为什么不理我,成年人的离开都是悄无声息、蓄谋已久的。王我却开口问你为什么不理我?你说,没有。从此以后存在于列表里,真正的名存实亡。静寂的、悄悄的、无论你什么时候翻开手机,都不会有你想要的消息。有时,就想眼不见心为净。可是,真正的心静却并非如此。倘若没有一见钟情,倘若没有懵懂的心动,是不是就会更快乐一些?图片发自App那些无法言说的想念封存在心底,明明知道答
- 男神 女神断舍离清单
晓云1
打开你的衣柜、抽屉、杂物盒、化妆包,和里面的无效物品说拜拜吧!迎接新生活就从现在开始,就从这100条“断舍离”开始。1戴了会过敏的耳钉和劣质、不喜欢的饰品。2有裂痕的杯子。3丢了瓶盖后一直没有好好封存的化妆水。4淘宝的赠品。5曾经喜欢过偶像的杂志和关于TA的一切。6旧款式的太阳镜,旧眼镜。7存钱罐,零钱尽快兑换。8破洞、单只、失去松紧的袜子。9微信或QQ上所有不愉快的聊天记录。(除了别人找你借钱的
- 当我尝试把它锁上
一只狮子
人这一辈子要想成点不一样的事就得熬把不喜欢的熬成喜欢把喜欢的熬成不喜欢把虚无的快意锁上封存自己然后重生
- 夜已深
许静许静静
时光悠悠,犹如白驹过隙!都道初心不曾负,而初心是何物?万丈红尘无人和,三千夜色我独歌......怀揣着初心,晕开往事的影集一幕幕幻化出思念的涟漪,泛黄褐斑的一方格,若隐若现青涩的容颜,微笑相依,静默不语,慢温一壶深清,与韶光对饮.......很多时候将一份情,沏成一壶淡淡香浓的清茶,缕缕茶香薰蒸着往事旧情,我想这一刻又跌入思念的漩涡了吧!手捧一杯清茶,细品慢咽,翼翼浅尝,重温那段封存已久的深情,浅
- 让初中生去高考?他们不是梅西
鹰瞳世界
空难事件、沪上疫情已经够愁心了,本想一场足球赛事能够给四月烦心诸多“封楼封存“躺平在家的人们打一折强心剂,没想到4月15日晚,在2022赛季亚冠联赛(AFCChampionsLeague)小组赛第一轮比赛中,以“青年军”出战的山东泰山队和广州队,分别以0:7和0:5的比分输给了韩国大邱队和马来西亚柔佛队。两场惨败当头浇了一盆冷水!男足没有醒,球迷真醒了.......一、主力无法参赛,何必让青年军去
- 岁月
如是如如是
图片发自App时光搁浅夕阳失忆还在一天一天撩动生长不老的潮汐依然一遍遍地潮起潮落一艘停泊在沙滩上饱经风霜的旧船图片发自App灯光昏暗雨还在窗前滴滴答答,敲碎心中思念的灯塔一把少年忘却了但依然在角落里等待故人的木吉他落满的灰尘封存青葱的伤疤图片发自App海角天涯落日下坐着的老人,想起了当年那个俊俏的姑娘,美的让人心伤文字/峻岭
- 矩阵求逆(JAVA)初等行变换
qiuwanchi
矩阵求逆(JAVA)
package gaodai.matrix;
import gaodai.determinant.DeterminantCalculation;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
/**
* 矩阵求逆(初等行变换)
* @author 邱万迟
*
- JDK timer
antlove
javajdkschedulecodetimer
1.java.util.Timer.schedule(TimerTask task, long delay):多长时间(毫秒)后执行任务
2.java.util.Timer.schedule(TimerTask task, Date time):设定某个时间执行任务
3.java.util.Timer.schedule(TimerTask task, long delay,longperiod
- JVM调优总结 -Xms -Xmx -Xmn -Xss
coder_xpf
jvm应用服务器
堆大小设置JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统下,一般限制在1.5G~2G;64为操作系统对内存无限制。我在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。
典型设置:
java -Xmx
- JDBC连接数据库
Array_06
jdbc
package Util;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class JDBCUtil {
//完
- Unsupported major.minor version 51.0(jdk版本错误)
oloz
java
java.lang.UnsupportedClassVersionError: cn/support/cache/CacheType : Unsupported major.minor version 51.0 (unable to load class cn.support.cache.CacheType)
at org.apache.catalina.loader.WebappClassL
- 用多个线程处理1个List集合
362217990
多线程threadlist集合
昨天发了一个提问,启动5个线程将一个List中的内容,然后将5个线程的内容拼接起来,由于时间比较急迫,自己就写了一个Demo,希望对菜鸟有参考意义。。
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CountDownLatch;
public c
- JSP简单访问数据库
香水浓
sqlmysqljsp
学习使用javaBean,代码很烂,仅为留个脚印
public class DBHelper {
private String driverName;
private String url;
private String user;
private String password;
private Connection connection;
privat
- Flex4中使用组件添加柱状图、饼状图等图表
AdyZhang
Flex
1.添加一个最简单的柱状图
? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
<?xml version=
"1.0"&n
- Android 5.0 - ProgressBar 进度条无法展示到按钮的前面
aijuans
android
在低于SDK < 21 的版本中,ProgressBar 可以展示到按钮前面,并且为之在按钮的中间,但是切换到android 5.0后进度条ProgressBar 展示顺序变化了,按钮再前面,ProgressBar 在后面了我的xml配置文件如下:
[html]
view plain
copy
<RelativeLa
- 查询汇总的sql
baalwolf
sql
select list.listname, list.createtime,listcount from dream_list as list , (select listid,count(listid) as listcount from dream_list_user group by listid order by count(
- Linux du命令和df命令区别
BigBird2012
linux
1,两者区别
du,disk usage,是通过搜索文件来计算每个文件的大小然后累加,du能看到的文件只是一些当前存在的,没有被删除的。他计算的大小就是当前他认为存在的所有文件大小的累加和。
- AngularJS中的$apply,用还是不用?
bijian1013
JavaScriptAngularJS$apply
在AngularJS开发中,何时应该调用$scope.$apply(),何时不应该调用。下面我们透彻地解释这个问题。
但是首先,让我们把$apply转换成一种简化的形式。
scope.$apply就像一个懒惰的工人。它需要按照命
- [Zookeeper学习笔记十]Zookeeper源代码分析之ClientCnxn数据序列化和反序列化
bit1129
zookeeper
ClientCnxn是Zookeeper客户端和Zookeeper服务器端进行通信和事件通知处理的主要类,它内部包含两个类,1. SendThread 2. EventThread, SendThread负责客户端和服务器端的数据通信,也包括事件信息的传输,EventThread主要在客户端回调注册的Watchers进行通知处理
ClientCnxn构造方法
&
- 【Java命令一】jmap
bit1129
Java命令
jmap命令的用法:
[hadoop@hadoop sbin]$ jmap
Usage:
jmap [option] <pid>
(to connect to running process)
jmap [option] <executable <core>
(to connect to a
- Apache 服务器安全防护及实战
ronin47
此文转自IBM.
Apache 服务简介
Web 服务器也称为 WWW 服务器或 HTTP 服务器 (HTTP Server),它是 Internet 上最常见也是使用最频繁的服务器之一,Web 服务器能够为用户提供网页浏览、论坛访问等等服务。
由于用户在通过 Web 浏览器访问信息资源的过程中,无须再关心一些技术性的细节,而且界面非常友好,因而 Web 在 Internet 上一推出就得到
- unity 3d实例化位置出现布置?
brotherlamp
unity教程unityunity资料unity视频unity自学
问:unity 3d实例化位置出现布置?
答:实例化的同时就可以指定被实例化的物体的位置,即 position
Instantiate (original : Object, position : Vector3, rotation : Quaternion) : Object
这样你不需要再用Transform.Position了,
如果你省略了第二个参数(
- 《重构,改善现有代码的设计》第八章 Duplicate Observed Data
bylijinnan
java重构
import java.awt.Color;
import java.awt.Container;
import java.awt.FlowLayout;
import java.awt.Label;
import java.awt.TextField;
import java.awt.event.FocusAdapter;
import java.awt.event.FocusE
- struts2更改struts.xml配置目录
chiangfai
struts.xml
struts2默认是读取classes目录下的配置文件,要更改配置文件目录,比如放在WEB-INF下,路径应该写成../struts.xml(非/WEB-INF/struts.xml)
web.xml文件修改如下:
<filter>
<filter-name>struts2</filter-name>
<filter-class&g
- redis做缓存时的一点优化
chenchao051
redishadooppipeline
最近集群上有个job,其中需要短时间内频繁访问缓存,大概7亿多次。我这边的缓存是使用redis来做的,问题就来了。
首先,redis中存的是普通kv,没有考虑使用hash等解结构,那么以为着这个job需要访问7亿多次redis,导致效率低,且出现很多redi
- mysql导出数据不输出标题行
daizj
mysql数据导出去掉第一行去掉标题
当想使用数据库中的某些数据,想将其导入到文件中,而想去掉第一行的标题是可以加上-N参数
如通过下面命令导出数据:
mysql -uuserName -ppasswd -hhost -Pport -Ddatabase -e " select * from tableName" > exportResult.txt
结果为:
studentid
- phpexcel导出excel表简单入门示例
dcj3sjt126com
PHPExcelphpexcel
先下载PHPEXCEL类文件,放在class目录下面,然后新建一个index.php文件,内容如下
<?php
error_reporting(E_ALL);
ini_set('display_errors', TRUE);
ini_set('display_startup_errors', TRUE);
if (PHP_SAPI == 'cli')
die('
- 爱情格言
dcj3sjt126com
格言
1) I love you not because of who you are, but because of who I am when I am with you. 我爱你,不是因为你是一个怎样的人,而是因为我喜欢与你在一起时的感觉。 2) No man or woman is worth your tears, and the one who is, won‘t
- 转 Activity 详解——Activity文档翻译
e200702084
androidUIsqlite配置管理网络应用
activity 展现在用户面前的经常是全屏窗口,你也可以将 activity 作为浮动窗口来使用(使用设置了 windowIsFloating 的主题),或者嵌入到其他的 activity (使用 ActivityGroup )中。 当用户离开 activity 时你可以在 onPause() 进行相应的操作 。更重要的是,用户做的任何改变都应该在该点上提交 ( 经常提交到 ContentPro
- win7安装MongoDB服务
geeksun
mongodb
1. 下载MongoDB的windows版本:mongodb-win32-x86_64-2008plus-ssl-3.0.4.zip,Linux版本也在这里下载,下载地址: http://www.mongodb.org/downloads
2. 解压MongoDB在D:\server\mongodb, 在D:\server\mongodb下创建d
- Javascript魔法方法:__defineGetter__,__defineSetter__
hongtoushizi
js
转载自: http://www.blackglory.me/javascript-magic-method-definegetter-definesetter/
在javascript的类中,可以用defineGetter和defineSetter_控制成员变量的Get和Set行为
例如,在一个图书类中,我们自动为Book加上书名符号:
function Book(name){
- 错误的日期格式可能导致走nginx proxy cache时不能进行304响应
jinnianshilongnian
cache
昨天在整合某些系统的nginx配置时,出现了当使用nginx cache时无法返回304响应的情况,出问题的响应头: Content-Type:text/html; charset=gb2312 Date:Mon, 05 Jan 2015 01:58:05 GMT Expires:Mon , 05 Jan 15 02:03:00 GMT Last-Modified:Mon, 05
- 数据源架构模式之行数据入口
home198979
PHP架构行数据入口
注:看不懂的请勿踩,此文章非针对java,java爱好者可直接略过。
一、概念
行数据入口(Row Data Gateway):充当数据源中单条记录入口的对象,每行一个实例。
二、简单实现行数据入口
为了方便理解,还是先简单实现:
<?php
/**
* 行数据入口类
*/
class OrderGateway {
/*定义元数
- Linux各个目录的作用及内容
pda158
linux脚本
1)根目录“/” 根目录位于目录结构的最顶层,用斜线(/)表示,类似于
Windows
操作系统的“C:\“,包含Fedora操作系统中所有的目录和文件。 2)/bin /bin 目录又称为二进制目录,包含了那些供系统管理员和普通用户使用的重要
linux命令的二进制映像。该目录存放的内容包括各种可执行文件,还有某些可执行文件的符号连接。常用的命令有:cp、d
- ubuntu12.04上编译openjdk7
ol_beta
HotSpotjvmjdkOpenJDK
获取源码
从openjdk代码仓库获取(比较慢)
安装mercurial Mercurial是一个版本管理工具。 sudo apt-get install mercurial
将以下内容添加到$HOME/.hgrc文件中,如果没有则自己创建一个: [extensions] forest=/home/lichengwu/hgforest-crew/forest.py fe
- 将数据库字段转换成设计文档所需的字段
vipbooks
设计模式工作正则表达式
哈哈,出差这么久终于回来了,回家的感觉真好!
PowerDesigner的物理数据库一出来,设计文档中要改的字段就多得不计其数,如果要把PowerDesigner中的字段一个个Copy到设计文档中,那将会是一件非常痛苦的事情。