Node快速入门
一. Node概述
1 Node是什么
Node是一个基于Chrome V8引擎的JavaScript代码运行环境
运行环境
- 浏览器(软件)能够运行JavaScript代码,浏览器就是JavaScript代码的运行环境
- Node(软件)能够运行JavaScript代码,Node就是JavaScript代码的运行环境
2 Node的安装
Node官网:https://nodejs.org/en/
Node中文官网: http://nodejs.cn/
在官网安装下载
win+R打开cmd

在cmd中输入node -v查看

输入node, 进入到node的命令行, 执行js代码
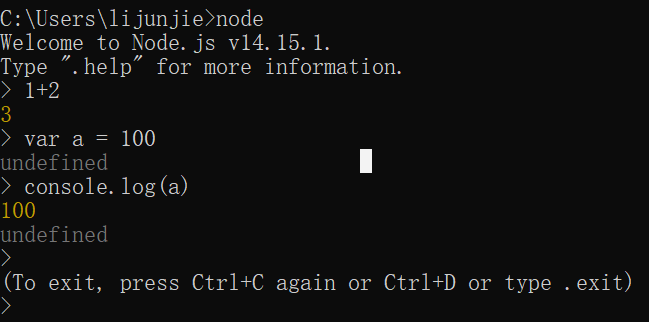
按两次ctrl+C退出node命令行
3 Node的组成
一开始, 几乎没有人把js当成一门真正的编程语言, 认为它只是运行在浏览器上小脚本而已. 事实上也如此, js的作者用10天写出的这个小玩意最开始仅仅只是为了做表单的验证, 节省一点带宽. 后来经过不断的发展, 慢慢完善, 但是依然存在一个缺陷: 没有模块的概念. 这对做大型项目是非常不利的
网景 liveScript->JavaScript
IE: JScript
js的官方规范(ECMAScript)主要是规定: 词法, 语法, 表达式, 函数, 对象这些东西.
W3C组织主要推进HTML5和web标准化, 这些过程基本上都是发生在前端.
服务端的规范相当落后. 主要集中在这些方面:
- 没有模块系统
- 标准库较少(比如I/O操作, 文件系统)
- 没有标准接口(比如几乎没有如何操作数据库的统一接口)
- 缺乏包管理系统
这个时候, CommonJS规范出现, 定义和完善了js的这些功能, Node可以被认为是对CommonJS规范的代码实现

这张图, 很好的说明了Node与浏览器, W3C, CommonJS组织, ECMAScript之间的关系
二. 模块化开发
1 为什么需要模块化开发
问题一: 文件依赖关系不明确
一般认为,后加载的文件可能需要依赖于先加载的文件,比如
01-依赖关系.html
<script src="js/jquery.js">script>
<script src="js/scroll.js">script>
<script src="js/swiper.jquery.js">script>
现在我们在01-依赖关系.html使用了一个方法
$('#fade').swiper({
type: 'fade',
src: scr,
arrow: true,
})
如果仅仅从代码上看. 很难分析出$()方法是在jquery.js还是在scroll.js中
如果代码越来越复杂, 这种依赖关系更加难以维护, 在大型工程项目中尤为明显
问题二: 命名冲突
js还存在一个问题, 就是命名冲突, 后定义的变量会覆盖之前定义的变量
02-命名冲突.html
<script src="a.js">script>
<script src="b.js">script>
<script>
console.log(str) // b文件中的str
script>
a.js
var str = 'a文件中的str'
b.js
var str = 'b文件中的str'
如果在a.js和b.js中同时定义了str变量, 由于b.js后加载, 会覆盖a.js中定义的str变量
这在大项目中是非常危险的, 一旦你在自己的代码中改写了一个变量的值, 而这个变量恰好其他人也使用了, 会引用程序的崩溃, 并且无从查起
扩展
当然, 早期人们可以通过自执行匿名函数解决这个问题, 但是这种方案现在已经被CommonJS规范取代了.
当然, 如果仔细深入的研究Node, 你会发现Node的实现也仅仅是在每个文件的最外层包裹一层自执行匿名函数
2 Node中的模块规范
1) 模块
每个文件被看成一个单独的模块,模块与模块之间是独立的
如何理解呢?
在一个文件(模块)中定义的变量, 在另一个文件(模块)中无法直接使用
示例
定义a.js
var str = '模块a中的str'
定义b.js
// 通过require, 表示引用a.js
require('./a.js')
console.log(str)
演示

2) 导出
如果希望外部能使用当前模块中的变量/函数, 需要使用exports导出
- exports是一个对象
- 将希望导出的变量/函数挂载到exports对象上, 表示导出
- 所谓挂载就是给exports对象添加属性或者方法
示例
04-导出
a.js
var str = 'a模块中的str变量'
function add(x, y) {
return x + y
}
// 在exports对象上挂载str属性
exports.str = str
// 在exports对象上挂载add方法
exports.add = add
b.js
// 导入a模块, a是一个对象, 相当于a模块中的exports对象
var a = require('./a.js')
console.log(a)
演示

思考
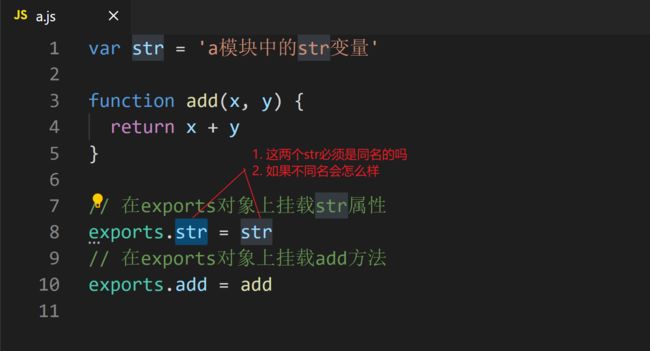
从上面的案例可知, 如果向外暴露(导出)属性或者方法, 可以使用exports. 但是如果想导出整个对象怎么办
尝试
a_obj.js
var str = 'a_obj模块中的str'
function add(x, y) {
return x + y
}
exports = {
str: str,
add: add,
}
b_obj.js
var a_obj = require('./a_obj.js')
console.log(a_obj) // {}
演示

通过尝试, 我们发现打印出来是一个空对象, 说明不能通过exports导出一个对象
实际上, 每个模块都存在一个内置对象module表示当前模块
在导出时, 实际导出的是module.exports. exports是它的引用
上述代码相当于
var str = 'a_obj模块中的str'
function add(x, y) {
return x + y
}
// 给exports重新赋值一个对象, 并不影响module.exports
exports = {
str: str,
add: add,
}
module.exports = {}
图解
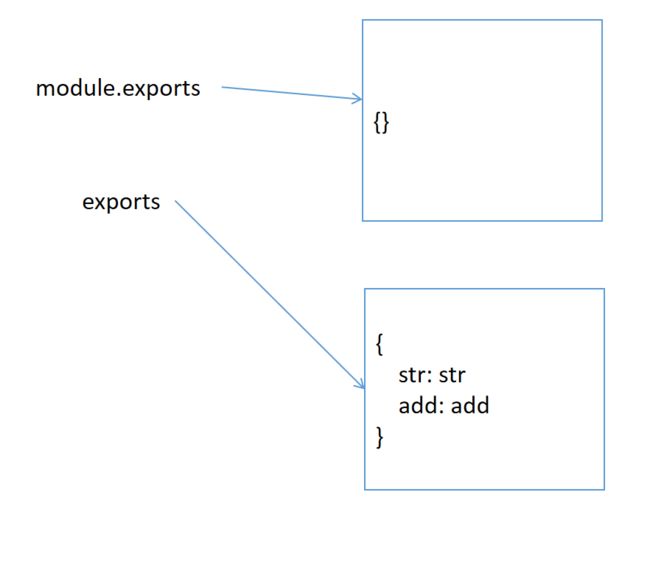
结论
- expots通过挂载属性向外暴露变量或者函数, 但是不能暴露对象
- 一般情况下使用module.exports
面试题
该模块导出的是什么?
var str = 'str'
function add(x, y) {
return x + y
}
exports.str = str
exports.add = add
exports = {
a: 'a',
b: 'b',
}
答案: { str: 'str', add: [Function: add] }
图解
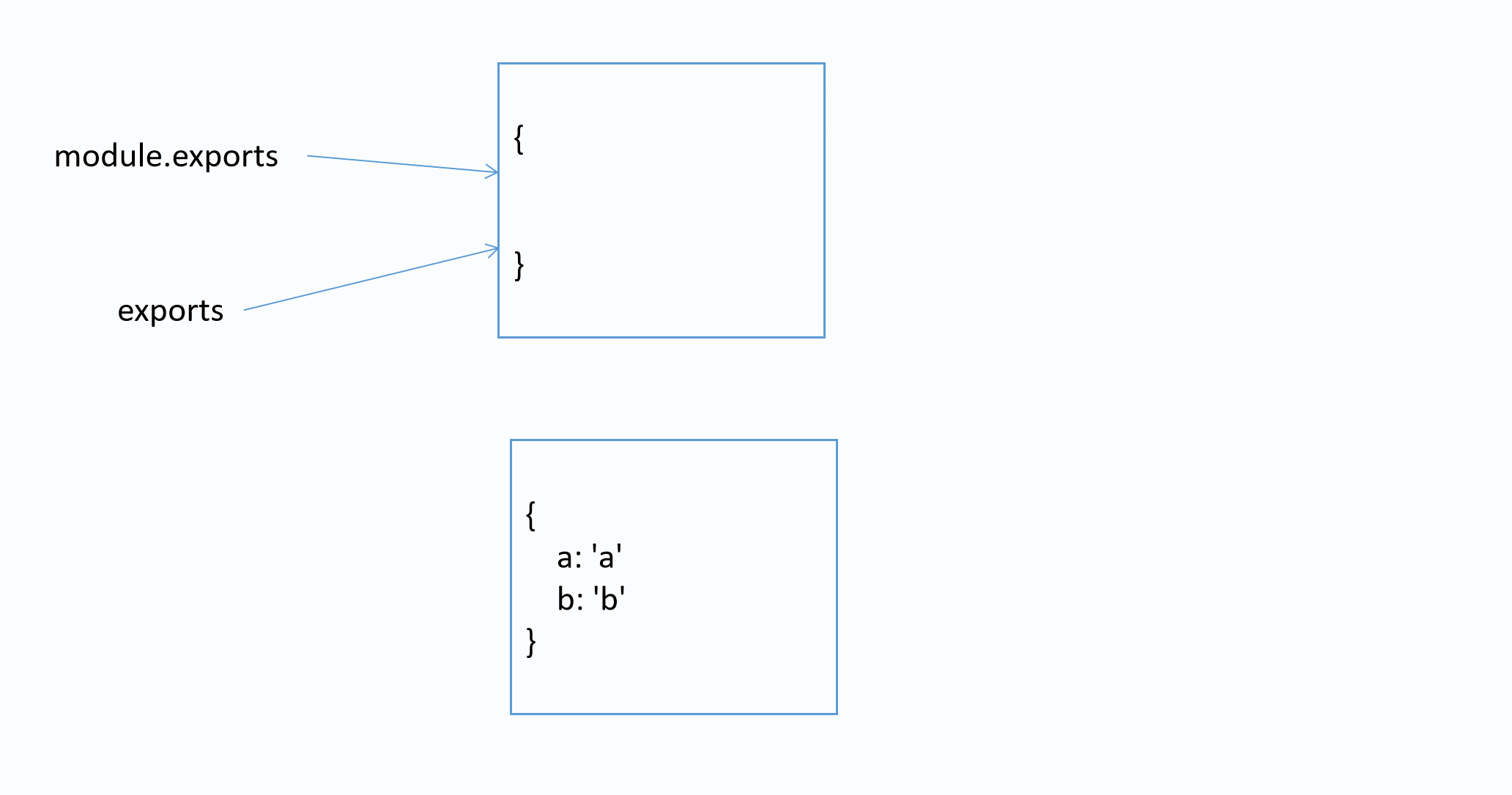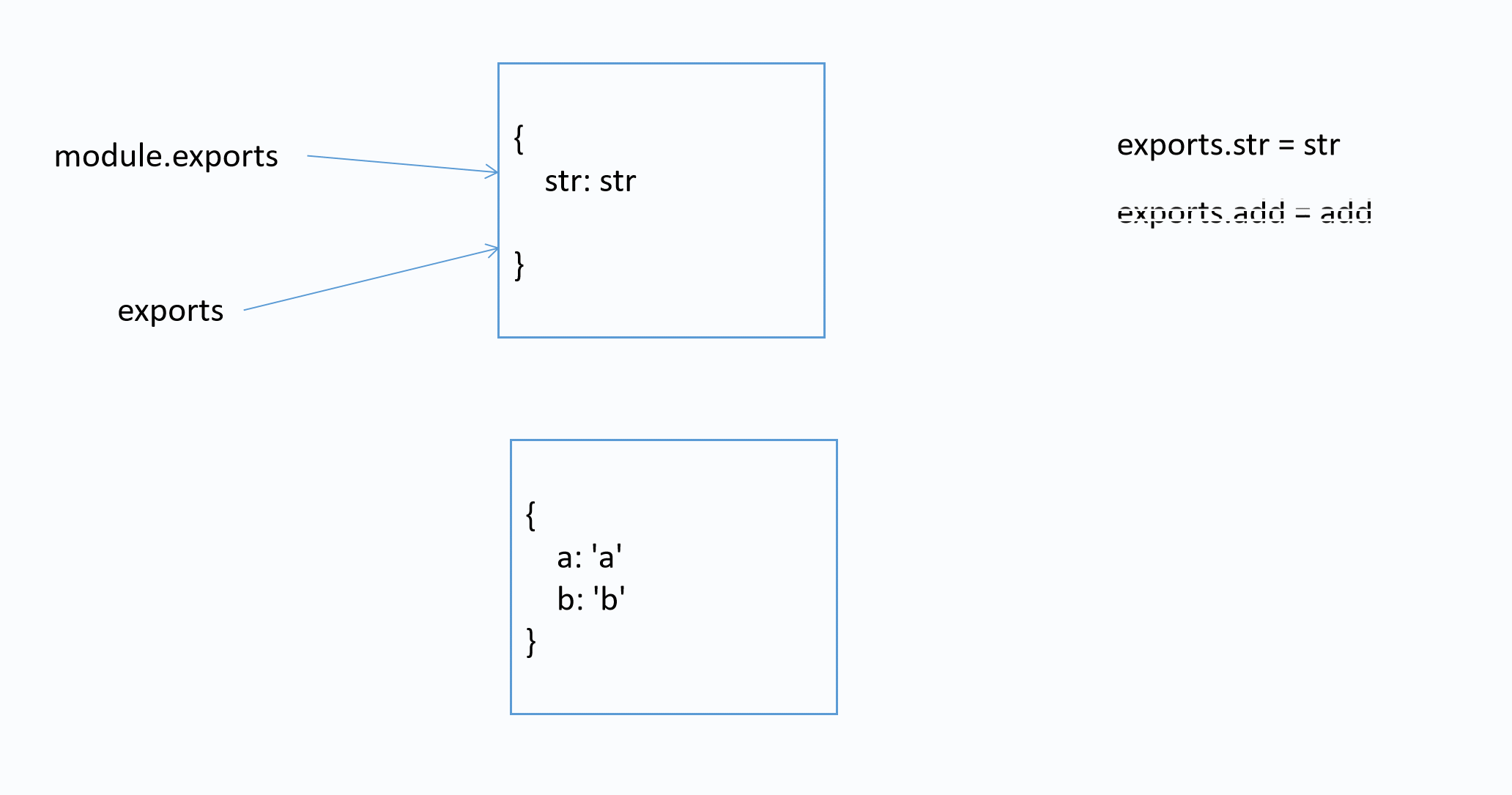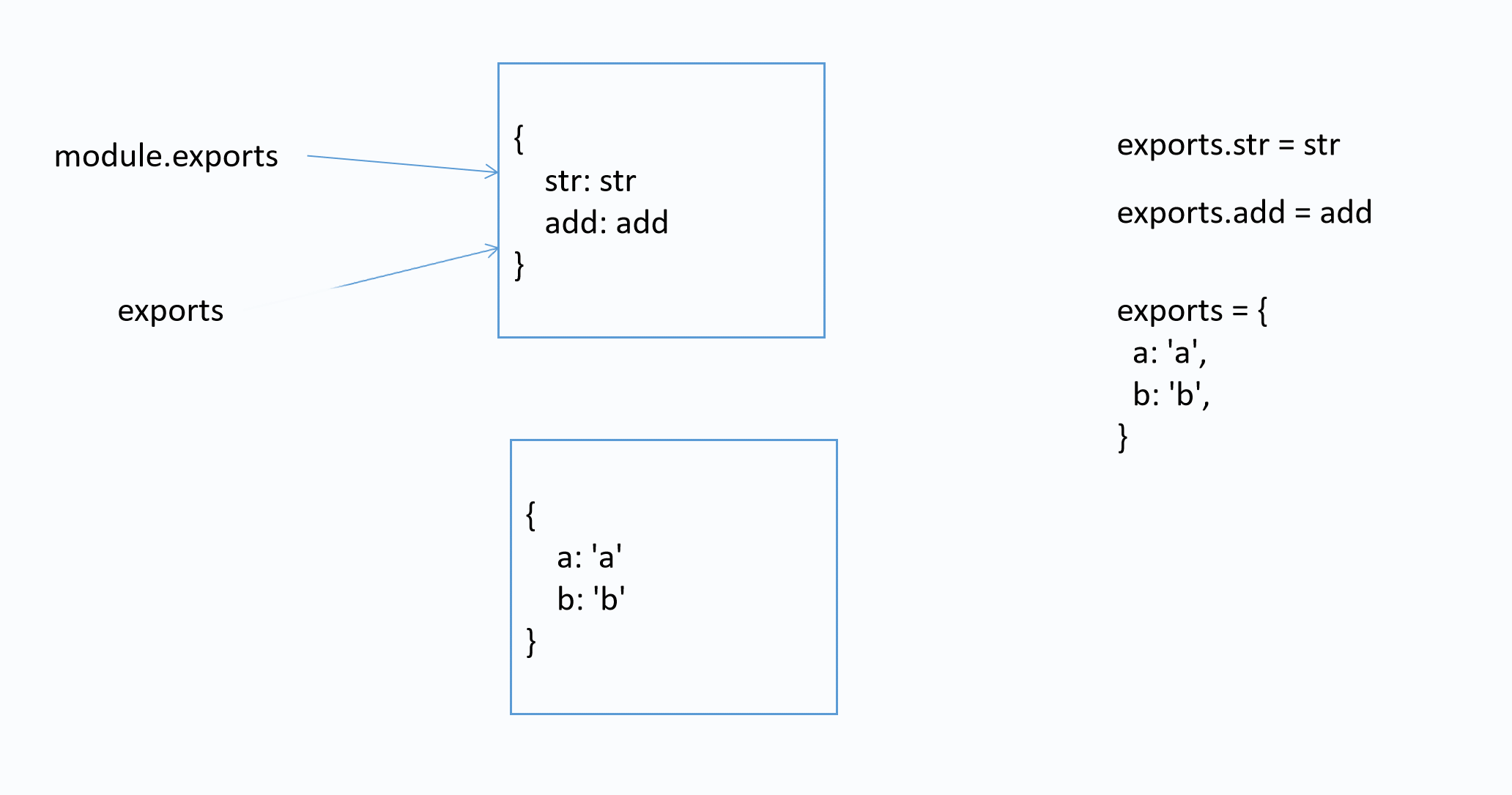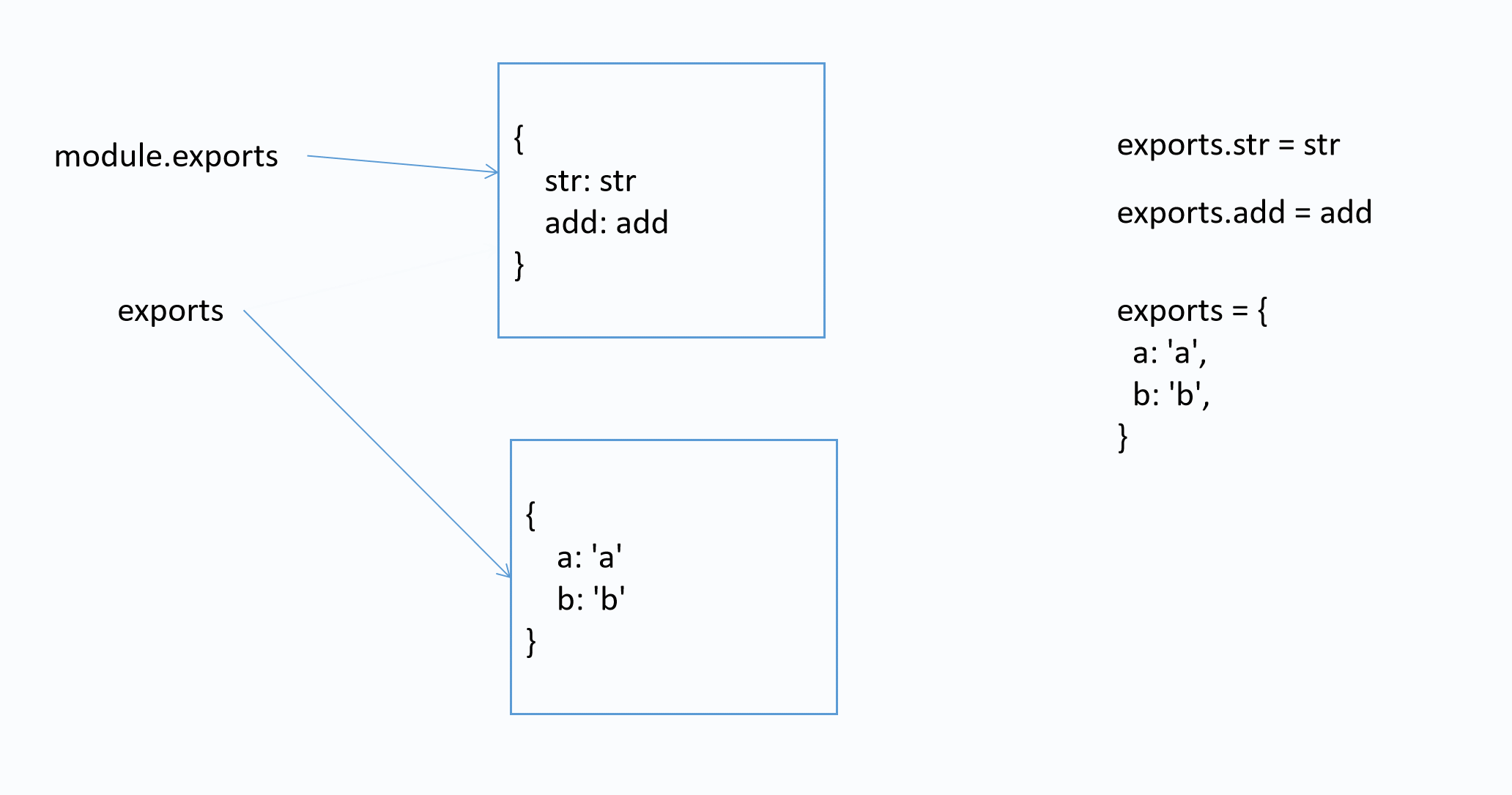
3) 导入
在Node中导入模块, 需要经历3个步骤
- 路径分析
- 文件定位
- 编译执行
Node中的模块可以分为两类:
- Node提供的模块, 称为核心模块
- 用户编写的模块, 称为文件模块(或者: 包package)
核心模块
对于核心模块的导入, 如fs, http, path等, 直接使用模块名
const fs = require('fs')
const http = require('http')
const path = require('path')
文件模块
对于文件模块的导入, 情况比较复杂, 放在稍后一点讲解
练习
有一个模块(calc.js),
- 定义一个函数 add实现两数相加, 将这个add函数向外暴露
- 定义一个函数 sub实现两数相减, 将这个sub函数向外暴露
再定义一个模块(test.js), 依赖于calc.js, 使用add函数
示例
三. 核心模块
Node的核心模块比较多, 这里我们重点介绍跟文件操作相关的path和fs
更多的使用, 参考Node官网 API部分: http://nodejs.cn/api/
1 path模块
path模块, 主要功能是对路径进行操作
1) 使用步骤
- 导入核心模块
- 调用相关API
示例
// 1.导入path模块
const path = require('path')
// 2.调用API
// 当前文件的完整路径
console.log(__filename)
// 当前文件所在目录
console.log(path.dirname(__filename))
2) 常用API
path.join()
path.join() 方法会将所有给定的 path 片段连接到一起
示例
// 1.导入path模块
const path = require('path')
// 2.调用API
// 当前文件所有目录
console.log(__dirname)
//当前目录下的fs子目录
let fs_path = path.join(__dirname, 'fs')
console.log(fs_path)
2 fs模块
fs模块(file system)文件操作系统, 主要功能是对目录/文件进行操作
读文件
fs.readFile(path, [options], callback)
- path: 需要读取文件的路径
- options: 编码格式, 一般为’utf8’
- callback: 回调函数
- err: 错误对象
- data: 数据
示例
// 1.导入fs核心模块
const fs = require('fs')
// 2.读取文件
fs.readFile('1.txt', 'utf8', (err, data) => {
// 如果文件读取出错 err 是一个对象 包含错误信息
// 如果文件读取正确 err 是 null
if (err) throw err
console.log(data)
})
写文件
fs.writeFile(file, data[, options], callback)
- file: 需要写入的文件
- data: 需要写入的数据
- options: 编码格式等, 一般为’utf8’
- callback: 回调函数
- err: 出错对象
示例
// 1.导入fs核心模块
const fs = require('fs')
// 2.写文件
fs.writeFile('index.html', 'Hello
', 'utf8', err => {
if (err) throw err
console.log('写入成功')
})
四. 文件模块
文件模块是由程序员基于Node环境编写并发布的代码, 通过由多个文件组成放在一个文件夹中, 所以也叫做包
在编程界, 有一句经典的名言: ‘不要重复造轮子’, 文件模块就相当于已经造好的轮子, 我们需要一个功能时直接拿来使用就可以了. 因此, 文件模块最大的作用是: 代码复用
1 npm包管理工具
由于包太多了不好查找和维护, 自然会出现管理工具, npm(node package manager)就是其中非常出色的一个
1) npm基本使用
npm在安装node时, 会被自动安装, 首先通过命令查看npm是否已经安装
在cmd命令行执行npm -v, 查看npm的版本信息

安装包
npm install 包名称
示例
如果我们想安装jquery, 执行npm install jquery即可
演示
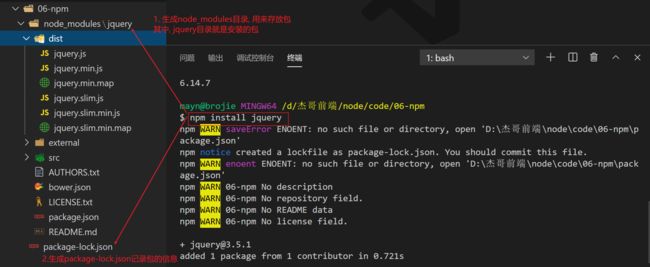
删除包
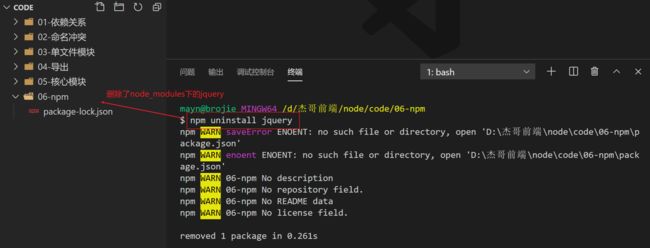
npm uninstall 包名称
示例
执行npm uninstall jquery
演示
2) 镜像与nrm
由于npm是国外的网站, 包的下载速度比较慢, 有时不稳定会导致安装出错. 为了解决这个问题, 我们可以使用国内镜像, 镜像源就是一个和npm官网一样的网站(像镜子一样), 只不过在国内, 这样更加稳定, 并且速度也很快.
nrm是一个镜像管理工具
执行命令
npm install nrm -g
- -g: 表示全局安装
全局安装会在C:\Users\mayn\AppData\Roaming\npm路径下生成一个可执行命令, 这样就可以在命令行执行了

在命令行执行
nrm ls
显示可用镜像

使用nrm use切换镜像
nrm use taobao
更多命令, 使用nrm -h查看
直接使用命令设置
npm config set registry http://registry.npm.taobao.org/
查看当前镜像
npm get registry
小结
如果安装工具类的包, 一般加-g, 全局安装
2 package规范
每个发布在npm上的包都遵循统一的规范, 这个规范也就被称为’package规范’. 以jquery为例
├─dist // 项目发布目录
├─external
│ └─sizzle
│ └─dist
└─src // 源代码
└─package.json // 包配置文件
└─README.md // 说明文件
其中, 最重要的是package.json文件
{
"name": "", // 包名称
"version": "1.0.0", // 版本
"description": "", // 描述
"main": "index.js", // 入口文件
"scripts": { // 脚本
"test": "echo \"Error: no test specified\" && exit 1"
},
"dependencies": {}, // 项目依赖
"devDependencies": {}, // 开发时依赖
"keywords": [],
"author": "", // 作者
"license": "ISC"
}
3 手写一个package
通过自己手写一个简单的包, 我们来了解package规范
1) 创建一个文件夹
在node_modules下创建一个文件夹calc, 这个文件夹也就是一个package

2) 初始化
打开calc, 执行命令
npm init -y
- -y: 表示使用默认值初始化
演示

会在calc里生成package.json配置文件, 如下
{
"name": "calc", // 包名称
"version": "1.0.0", // 版本
"description": "", // 描述
"main": "index.js", // 入口文件
"scripts": { // 脚本
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "", // 作者
"license": "ISC"
}
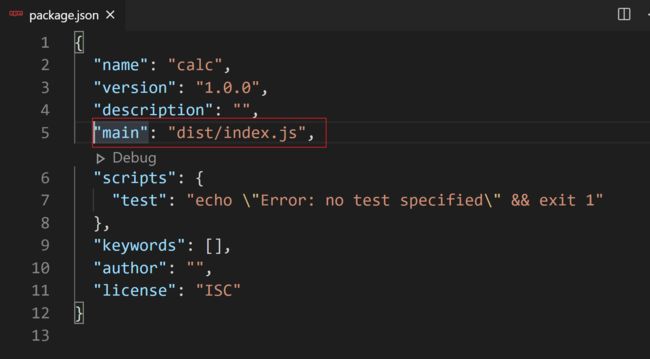
其中, 最重要的是main, 用来指定: 其他人加载这个package时, 实际引入的文件是哪一个
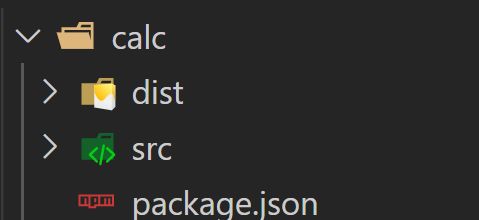
3) 创建目录结构
创建如图所示的目录结构
修改package.json的入口文件
在dist目录下创建index.js, 作为入口文件
4) 编写代码
src/add.js
function add (x, y) {
return x + y
}
module.exports = add
演示
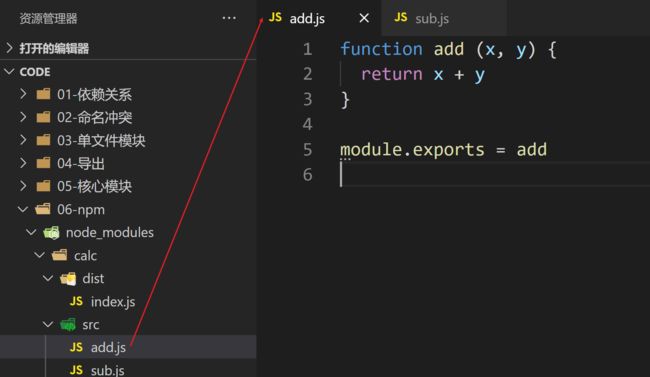
src/sub.js
module.exports = function (x, y) {
return x - y
}
dist/index.js
const add = require('../src/add.js')
const sub = require('../src/sub.js')
module.exports = {
add,
sub
}
演示
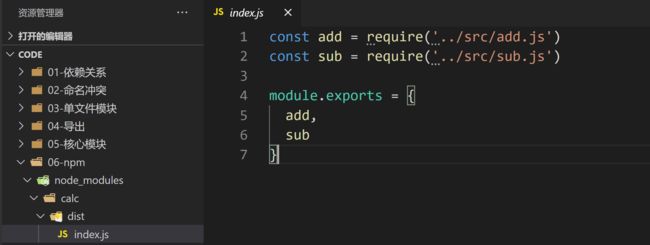
5) 使用package
在node_modules同级目录创建test.js测试文件
const calc = require('calc')
console.log(calc.add(1, 2))
演示
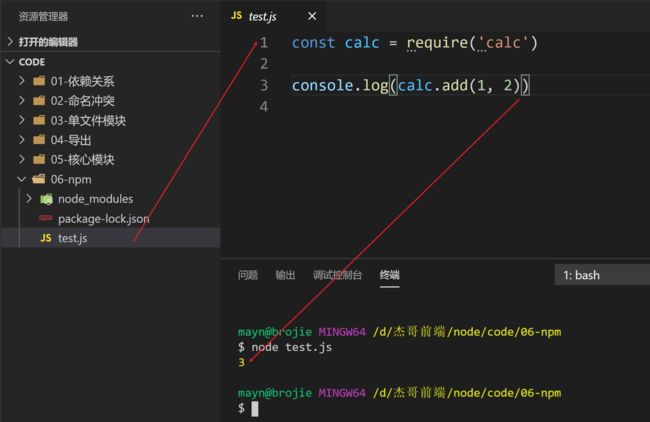
require加载的流程:
- 在
node_modules下找calc目录 - 解析package.json文件, 找到指定的入口文件:‘dist/index.js’
4 导入规则
1) 以名称开头
示例
require('fs')
require('calc')
- Node.js会假设它是核心模块
- 如果不是核心模块Node.js会去当前目录下的node_modules中查找
- 首先看是否有该名字的JS文件
- 再看是否有该名字的文件夹
- 查看该文件夹中的package.json中的main选项确定模块入口文件
- 如果没有package.json文件, 加载index.js
- 否则找不到报错
2) 以路径开头
示例
require('./find')
require('../add.js')
- 如果模块后缀省略,先找同名JS文件再找同名JS文件夹
- 如果找到了同名文件夹,找文件夹中的index.js
- 如果文件夹中没有index.js就会去当前文件夹中的package.json文件中查找main选项中的入口文件
- 如果找指定的入口文件不存在或者没有指定入口文件就会报错,模块没有被找到
五. 服务端编程
Node最显著的特点就是将js扩展到了服务端, 使得可以使用js编写服务端程序.
1 概念
1) 服务器
提供服务的机器, 也就是电脑, 跟普通的电脑相比, 服务器一般性能更好

服务器集群

- http服务器: 提供http服务的电脑
- 数据库服务器: 提供数据存储服务的电脑
2) 服务
所谓服务, 就是运行在电脑上的一个应用程序.
在生活中, 我们都有去食堂吃饭的经历, 在食堂里有不同的窗口, 每个窗口卖的食品不一样, 就像提供的服务不一样

在计算机网络中. 通过IP地址可以唯一的确定某一台电脑, 通过端口就可以唯一的确定这个电脑提供的服务
结论
服务 = IP + Port(socket)
3) 服务端程序
所谓服务端程序, 就是提供服务的程序, 通过运行在服务器上
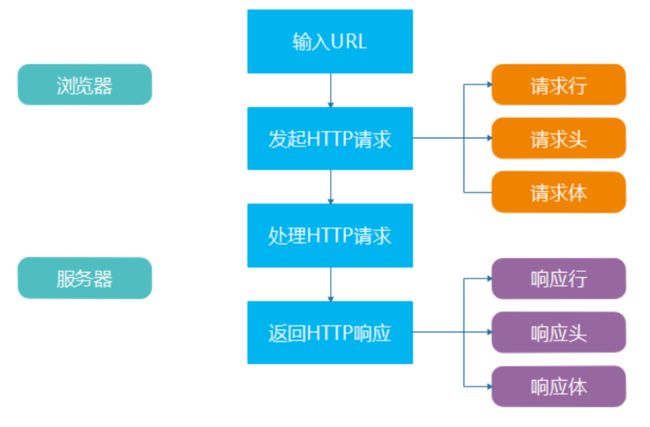
一般情况下, 服务端程序和客户端程序运行在不同的电脑上, 这两个程序要能通信(发送数据)就需要一个统一的标准, 这个标准就是协议, 在Web服务中使用的是Http协议
2 Http协议
Http是一种网络协议, 规定了web服务器与浏览器之前的交互语言, 是一种一问一答协议
- 由浏览器发起请求(request)
- 由web服务器针对请求生成响应(response)

1) URL
URL(Uniform Resource Locator), 统一资源定位符
在计算机网络中, 可以通过统一资源定位符(URL)请求对应的服务器资源(Resource)
Schema://host[:port]/path[?query-string]
- Schema: 使用的协议类型, 如http/https/ftp等
- host: 主机域名或IP
- port: 端口号(可选)
- path: 路径
- query-string: 查询参数(可选)
示例
http://api.local.com/movies
https://api.local.com:8080/articles?id=100
资源
- 狭义上讲, 所有在服务器保存的数据(如:音乐/视频/文章/个人信息…)都是服务器端资源.
- 广义上讲, 任何服务器端的对象(如:应用程序/数据库记录/算法…)都可以看作资源.
2) Http请求
HTTP请求由三部分组成, 分别是:
- 请求行
- 请求头
- 请求体
如下图所示
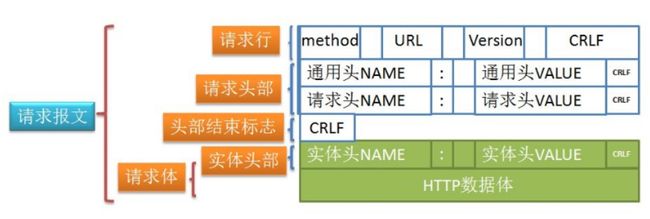
请求行
请求行的格式如下:
Method Request-URL HTTP-Version CRLF
- Method: HTTP请求的类型, 如:GET/POST/PUT/DELETE
- Request-URL: HTTP请求的唯一标识符, 如: /test.hmtl
- HTTP-Version: HTTP协议版本, 如HTTP/1.1
- CRLF: 回车换行 CR(回车\n) LF(换行\r)
例子: GET /test.html HTTP/1.1 (CRLF)
请求行以”空格”分割, 除结尾的外CR和LF外, 不允许出现单独的CR或LF字符
请求头
请求头包含许多有关的前端环境和请求正文的有用信息.
请求体
请求体主要包含前端发送给后端的数据
对于GET请求, 一般不需要请求体, 因为GET参数直接体现在URL上
对于POST请求, 需要请求体, 请求体里保存POST参数
3) Http响应
同样, HTTP响应也是由三部分组成, 分别是:
- 响应行
- 响应头
- 响应体
响应报文如下图所示:
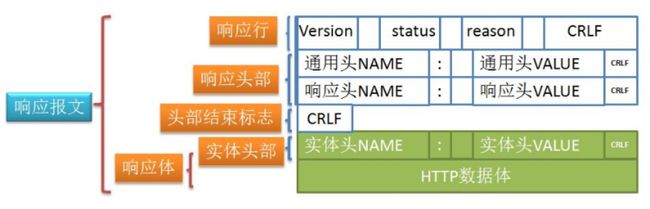
响应行
响应行的格式如下:
HTTP-Version Status-Code Reason-Phrase CRLF
- HTTP-Version: HTTP协议版本, 如HTTP/1.1
- Status-Code: 响应状态码, 如200/401/500
- Reason-Phrase: 描述信息
- CRLF: 回车换行 CR(回车\n) LF(换行\r)
示例
HTTP/1.1 200 OK
状态码
- 1xx:指示信息–表示请求已接收,继续处理。
- 2xx:成功–表示请求已被成功接收、理解、接受。
- 3xx:重定向–要完成请求必须进行更进一步的操作。
- 4xx:客户端错误–请求有语法错误或请求无法实现。
- 5xx:服务器端错误–服务器未能实现合法的请求。
常见的状态码
- 200 OK:客户端请求成功。
- 400 Bad Request:客户端请求有语法错误,不能被服务器所理解。
- 401 Unauthorized:请求未经授权,这个状态代码必须和WWW-Authenticate一起使用。
- 403 Forbidden:服务器收到请求,但是拒绝提供服务。
- 404 Not Found:请求资源不存在,举个例子:输入了错误的URL。
- 500 Internal Server Error:服务器发生不可预期的错误。
响应头
响应头是后端(服务器)返回给前端(客户端)的信息.
响应体
响应体是后端(服务器)返回给前端(客户端)的数据.
比如: 一个html页面代码, 一张图片, 一个json数据…
3 手写http服务程序
Node提供了Http核心模块, 方便我们快速构建一个http服务程序
1) 最简单的http服务程序
示例
// 引入http核心模块
const http = require('http')
// 创建web服务器
const server = http.createServer()
// 处理请求
server.on('request', (req, res) => {
res.end('hello
')
})
// 监听3000端口
server.listen(3000)
演示

2) 处理中文字符
示例
如果响应里包含中文会怎样?
注意, 修改代码后要重启服务
res.end('这是一个web服务器
')
演示

我们发现会出现乱码. 我们需要在响应头里添加编码格式
server.on('request', (req, res) => {
// 设置响应头
res.writeHead(200, {
'content-type': 'text/html;charset=utf-8',
})
res.end('这是一个web服务器
')
})
演示

nodemon
每次修改代码都需要手动重启服务. 这并不友好, 而且容易忘记. 这里, 大家可以安装nodemon工具
npm install nodemon -g
然后, 使用nodemon来执行js文件, nodemon会监听文件的变化, 并且重新执行
3) 处理路由
分析URL
不论是get请求还是post请求, 作为服务端而言, 首先要知道请求的URL
在Node中, 可以通过url核心模块进行分析, 参考 官方文档
示例
// 导入url模块
const url = require('url')
// 通过url.parse方法, 返回url对象
const str = 'http://localhost:3000/index'
const obj = url.parse(str, true)
console.dir(obj)
输出
Url {
protocol: 'http:',
slashes: true,
auth: null,
host: 'localhost:3000',
port: '3000',
hostname: 'localhost',
hash: null,
search: null,
query: [Object: null prototype] {},
pathname: '/index',
path: '/index',
href: 'http://localhost:3000/index'
}
这里我们最关心的是
- pathname: 请求的路由
通过路由, 服务端可以区分具体的资源, 比如
- /和index.html: 首页
- list.html: 列表页
- detail.html: 详情页
示例
// 引入http核心模块
const http = require('http')
// 引入url核心模块
const url = require('url')
// 创建web服务器
const server = http.createServer()
// 处理请求
server.on('request', (req, res) => {
// 设置响应头
res.writeHead('200', {
'content-type': 'text/html;charset=utf-8',
})
// 分析路由
const { pathname } = url.parse(req.url, true)
if (pathname == '/' || pathname == '/index') {
res.end('首页')
} else if (pathname == '/list') {
res.end('列表页')
} else {
res.writeHead('404')
res.end('Not Found')
}
})
// 监听3000端口
server.listen(3000)
console.log('server is running on localhost:3000')
示例
const http = require('http')
const server = http.createServer()
server.on('request', (req, res) => {
res.writeHead(200, {
'Content-Type': 'text/html;charset=utf-8',
})
// 判断req中的请求
console.log(req.url)
const url = new URL(req.url, 'http://127.0.0.1/')
console.log(url)
if (url.pathname == '/' || url.pathname == '/index.html') {
// 读取index.html的文件内容, 返回
res.end('首页')
} else if (url.pathname == '/list.html') {
res.end('列表')
} else if (url.pathname == '/detail.html') {
res.end('详情')
} else {
res.writeHead(404, 'Not Found').end('Not Found')
}
})
server.listen(3002)
4) 处理GET请求
对于同一个URL, 可以发起不同类型的请求, 处理请求, 主要是分析请求的参数
由于GET参数直接在URL中, 在处理URL时, 通过query就可以得到
示例
// 导入url模块
const url = require('url')
// 通过url.parse方法, 返回url对象
const str = 'http://localhost:3000/index?username=xiaopang'
const obj = url.parse(str, true)
console.dir(obj)
输出
Url {
protocol: 'http:',
slashes: true,
auth: null,
host: 'localhost:3000',
port: '3000',
hostname: 'localhost',
hash: null,
search: '?username=xiaopang',
query: [Object: null prototype] { username: 'xiaopang' },
pathname: '/users/index',
path: '/users/index?username=xiaopang',
href: 'http://localhost:3000/users/index?username=xiaopang'
}
处理get请求
// 引入http核心模块
const http = require('http')
// 引入url核心模块
const url = require('url')
// 创建web服务器
const server = http.createServer()
// 处理请求
server.on('request', (req, res) => {
// 设置响应头
res.writeHead('200', {
'content-type': 'text/html;charset=utf-8',
})
// 分析路由
const { query, pathname } = url.parse(req.url, true)
if (pathname == '/' || pathname == '/index') {
// 处理get请求
if (req.method == 'GET') {
// 打印在后端控制台
console.log(query)
// 返回给浏览器
res.end(query.username)
}
} else if (pathname == '/list') {
res.end('列表页')
} else {
res.writeHead('404')
res.end('Not Found')
}
})
// 监听3000端口
server.listen(3000)
console.log('server is running on localhost:3000')
5) 处理POST请求
对于POST请求, 由于参数在数据报文中, 只有等数据传输完成才可以进行处理.
主要使用request提供的data和end事件来处理
示例
// 引入http核心模块
const http = require('http')
// 引入url核心模块
const url = require('url')
// 创建web服务器
const server = http.createServer()
// 处理请求
server.on('request', (req, res) => {
// 设置响应头
res.writeHead('200', {
'content-type': 'text/html;charset=utf-8',
})
// 分析路由
const { query, pathname } = url.parse(req.url, true)
if (pathname == '/' || pathname == '/index') {
// 处理get请求
if (req.method == 'GET') {
// 显示页面
console.log(query)
} else if (req.method == 'POST') {
let post_data = ''
// post数据传递
req.on('data', (data) => (post_data += data))
// post数据传输完成
req.on('end', () => {
console.log(post_data)
res.end(post_data)
})
}
} else if (pathname == '/list') {
res.end('列表页')
} else {
res.writeHead('404')
res.end('Not Found')
}
})
// 监听3000端口
server.listen(3000)
console.log('server is running on localhost:3000')
监听request的两个事件
- data: 当服务端收到post数据时调用
- end: 当服务端收集完post数据时调用
6) 处理静态资源
静态资源
像html, js, css, 图片这些数据都属于静态资源
如果我们直接在end方法里通过字符串返回html, 显然不够友好.
最好是能以文件的形式保存, 通过读取文件的方式返回
示例
// 引入http核心模块
const http = require('http')
// 引入url核心模块
const url = require('url')
// 引入path核心模块
const path = require('path')
// 引入fs核心模块
const fs = require('fs')
// 创建web服务器
const server = http.createServer()
// 读取静态资源
function resolveStatic(file) {
// 将网络路由转换成服务器端真实路径
const realPath = path.join(__dirname, 'public/' + file)
// 同步读取文件
return fs.readFileSync(realPath)
}
// 处理请求
server.on('request', (req, res) => {
// 设置响应头
res.writeHead('200', {
'content-type': 'text/html;charset=utf-8',
})
// 分析路由
const { pathname } = url.parse(req.url, true)
if (pathname == '/' || pathname == '/index') {
const html = resolveStatic('index.html')
res.end(html)
} else if (pathname == '/list') {
res.end('列表页')
} else {
res.writeHead('404')
res.end('Not Found')
}
})
// 监听3000端口
server.listen(3000)
console.log('server is running on localhost:3000')
ound’)
}
})
// 监听3000端口
server.listen(3000)
console.log(‘server is running on localhost:3000’)
监听request的两个事件
- data: 当服务端收到post数据时调用
- end: 当服务端收集完post数据时调用
### 6) 处理静态资源
> 静态资源
像html, js, css, 图片这些数据都属于静态资源
如果我们直接在`end`方法里通过字符串返回html, 显然不够友好.
最好是能以文件的形式保存, 通过读取文件的方式返回
> 示例
```js
// 引入http核心模块
const http = require('http')
// 引入url核心模块
const url = require('url')
// 引入path核心模块
const path = require('path')
// 引入fs核心模块
const fs = require('fs')
// 创建web服务器
const server = http.createServer()
// 读取静态资源
function resolveStatic(file) {
// 将网络路由转换成服务器端真实路径
const realPath = path.join(__dirname, 'public/' + file)
// 同步读取文件
return fs.readFileSync(realPath)
}
// 处理请求
server.on('request', (req, res) => {
// 设置响应头
res.writeHead('200', {
'content-type': 'text/html;charset=utf-8',
})
// 分析路由
const { pathname } = url.parse(req.url, true)
if (pathname == '/' || pathname == '/index') {
const html = resolveStatic('index.html')
res.end(html)
} else if (pathname == '/list') {
res.end('列表页')
} else {
res.writeHead('404')
res.end('Not Found')
}
})
// 监听3000端口
server.listen(3000)
console.log('server is running on localhost:3000')