FPGA HLS 的机理
HLS (high-level synthesis)称为高级综合, 它的主要功能是用 C/C++为FPGA开发算法。这将提升FPGA 算法开发的生产力。
Xilinx最新的HLS是Vitis HLS。 在Vivado 2020版本中替代原先的Vivado HLS, 功能略有差异。
HLS 的机理
简单地讲,HLS采样类似C语言来设计FPGA 逻辑。但是要实现这个目标,还是不容易的。毕竟软件和硬件的功能实现存在非常大的差别。软件主要针对顺序程序执行。即便是平行程序执行,也是通过OS 的任务调度CPU 的资源。宏观上是并发执行,而微观上仍然是顺序占用CPU 执行的。另一方面,基于FPGA 硬件逻辑,如果没有上下文关联,完全可以并行运行。在没有特别语法规则下,讲C语言程序转换成为硬件逻辑,并且尽量实现硬件的并行执行是有难度的。人们为此研究了将近20年。
在这个领域的主要贡献者是康奈尔大学的张志如博士,他是康奈尔大学ECE学院助理教授,计算机系统实验室成员。他目前的研究重点是异构计算的高级设计自动化。他的作品获得了 TODAES 的最佳论文奖和 ICCAD 的最佳论文提名。2006 年,他与人共同创立了 AutoESL Design Technologies, Inc.,将他关于高层次综合的博士论文研究商业化。AutoESL 于 2011 年被 Xilinx 收购,收购后 AutoESL 工具更名为 Vivado HLS。
了解了HLS 的实现机理,有助于编写出高效率的HLS 逻辑。
软件编译器讲高级语言翻译成为机器语言。主要关注的语言的语法转换规则,相比之下,HLS 的翻译难度更大一些,模块中的语句形式上是前后顺序排列。但是HLS尽力转换成为并行执执行的硬件逻辑。并且通过数据流,管道等技术实现硬件优化。笔者看来,HLS 的编译技术是非常了不起的。
HLS的目标是根据用户提供的输入和限制自动替用户做出很多决定,HLS自动完成以下曾经需要手动完成的工作。
- HLS自动分析并利用一个算法中潜在的并发性
- HLS自动在需要的路径上插入寄存器,并自动选择最理想的时钟
- HLS自动产生控制数据在一个路径上出入方向的逻辑
- HLS自动完成设计的部分与系统中其他部分的接口
- HLS自动映射数据到储存单位以平衡资源使用与带宽
- HLS自动将程序中计算的部分对应到逻辑单位,在实现等效计算的前提下自动选取最有效的实施方式。
下面是一个简单的例子
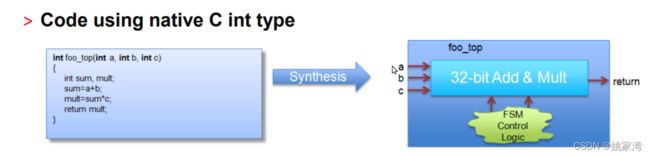
从图可见,为了在时钟脉冲下控制程序的执行,在转换后,添加了一个有限状态机。
下面是循环的机制:

由两个状态控制一个循环。

HLS 对循环语句实现多种优化
- unroll
- pipeline

看出缺省方式和PIPELINE的差比,速度提高了一倍。
任务的并行执行(Task Parallelism with HLS)
HLS 中将每一个语句看作为一个任务,它们可能是一个语句,或者是一个函数调用。例如一个函数中调用4个函数,A,B,C,D 。在C语言中,A,B,C,D是依次执行的。但是在HLS 的实现中,如果A,B,C,D四个模块没有数据的依赖关系的话,它们完全可以并行地执行。
我们假设, A 在两个不同的数组中为 B 和 C 生成数据,而 D 使用数据来自 B 和 C 生成的两个不同数组。让我们假设这种“钻石”通信模式将运行两次(两次调用),并且这两次运行是独立的。
void diamond (data_t vecIn[N],data_t vecOut[N]) {
data_t c1[N],c2[N],c3[N],c4[N];
funcA(vecIn,c1,c2);
funcB(c1,c3);
funcC(c2,c4);
funcD(c3,c4,vecOut);
}这是一种所谓“钻石”形链接(“diamond” shape connectivity.)。

全顺序执行对应于图 1 中的图,其中圆圈表示用于实现序列化的某种形式的同步。

在菱形示例中,B 和 C 是完全独立的:它们不通信,不访问共享内存资源,如果不需要共享计算资源,则可以期望它们并行执行。这导致了图 2 中的图表,在一次运行中具有一种 fork-join 并行性形式:B 和 C 在 A 结束后并行执行,D 等待 B 和 C,但下一次运行仍然是序列化的。

让我们走得更远一点。到目前为止,之前的执行模式在调用中利用了任务级并行性。重叠连续运行呢?如果它们是真正独立的,但如果每个函数(即 A、B、C 或 D)重用与之前运行相同的计算硬件,我们可能仍希望执行,例如,并行执行 A 的第二次调用B 和 C 的第一次调用。这是一种跨调用的任务级流水线形式,导致如图 3 所示的图表。吞吐量现在得到了提高,因为它受到所有任务之间的最大延迟的限制,而不是它们的延迟之和。每次运行的延迟不变,但多次运行的总延迟减少了。

这些看起来好复杂的样子,但是HLS 为我们实现了细节。我们只需了解这些机理就可以了。
C语言与硬件组件的区别
HLS 采用了C语言描述逻辑,它们的对应关系如下:

但是,HLS 对C语言又做出了一些限制:
- 不使用动态内存分配(不使用malloc(),free(),new和delete())
- 减少使用指针对指针的操作
- 不使用系统调用(例如abort(),exit(),printf()),我们可以在其他代码例如测试平台上使用这些指令,但是综合的时候这些指令会被无视(或直接删掉)
- 减少使用其他标准库里的内容(支持math.h里常用的内容,但还是有一些不兼容)
- 减少使用C++中的函数指针和虚拟函数
- 不使用递归方程
- 精准的表达我们的交互接口
结束语
HLS 采用C语言来描述FPGA 逻辑,这将全面提升FPGA 设计的生产力。但是HLS 的代码生成与C语言基于语法的编译要复杂的多。HLS 尽力实现并行操作和优化。不然就只是一个玩具。
尽管HLS 实现机制极为复杂,但是对于FPGA 算法设计者而言,了解内部机理就可以了,并不需要了解更多细节,这就是HLS的高级之处。