Redis 上
redis 内存建议16G,或者32G,少食多餐,不然同步会很慢,实在不行多实例
目录
Redis 基础
什么是 NoSQL
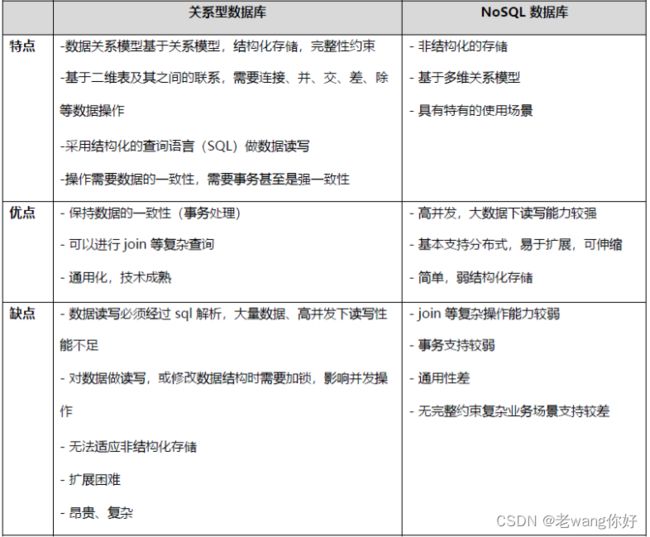
RDBMS和NOSQL对比
NoSQL的优点/缺点
CAP定理(CAP theorem)
编辑 NoSQL 数据库分类
Redis 特性、
注意事项:
Redis 对比 Memcached
编辑 Redis 常见应用场景
缓存的实现流程
缓存穿透,缓存击穿和缓存雪崩
包安装 Redis
消除启动时的三个Warning提示信息(可选)
脚本编译安装
创建 Redis 用户和设置数据目录权限
创建 Redis 服务 Service 文件
Redis 通过Service方式启动
Redis 的多实例
客户端程序 redis-cli
程序连接 Redis
Shell 脚本访问 Redis
Python 程序连接 Redis
图形工具
Redis 配置文件说明
config 命令实现动态修改配置
设置客户端连接密码
获取当前所有参数配置
设置 Redis 使用的最大内存量
慢查询
keys命令
常用命令
Redis 持久化
实现 RDB 方法
RDB 模式的优缺点
AOF 工作原理
手动执行AOF重写 BGREWRITEAOF 命令 #误删除回复
rewrite 重写
AOF 模式优点
AOF 模式缺点
RDB和AOF 的选择、
Redis 常用命令
列表 list
集合间操作
有序集合 sorted set
Redis 基础
Redis用来做什么?
通常局限点来说,Redis也以消息队列的形式存在,作为内嵌的List存在,满足实时的高并发需求。而通常在一个电商类型的数据处理过程之中,有关商品,热销,推荐排序的队列,通常存放在Redis之中,期间也包扩Storm对于Redis列表的读取和更新。
什么是 NoSQL
数据库主要分为两大类:关系型数据库与 NoSQL 数据库。
关系型数据库,是建立在关系模型基础上的数据库,其借助于集合代数等数学概念和方法来处理数据库中的数据。主流的 MySQL、Oracle、MS SQL Server 和 DB2 都属于这类传统数据库。
NoSQL 数据库,全称为 Not Only SQL,意思就是适用关系型数据库的时候就使用关系型数据库,不适用的时候可以考虑使用更加合适的数据存储。NoSQL 是对不同于传统的关系型数据库的数据库管理系统的统称。
NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
RDBMS和NOSQL对比
RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL)
- 数据和关系都存储在单独的表中。数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
NoSQL
- 代表着不仅仅是SQL, 没有声明性查询语言
- 没有预定义的模式
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性
NoSQL的优点/缺点
CAP定理(CAP theorem)
在计算机科学中, CAP定理(CAP theorem), 又被称为布鲁尔定理(Brewer's theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency) :所有节点在同一时间具有相同的数据
- 可用性(Availability) :保证每个请求不管成功或者失败都有响应
- 分区容忍(Partition tolerance) :系统中任意信息的丢失或失败不会影响系统的继续运作
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
- CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
- CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。
- AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。09 9v=-得到的房地产想 关闭jlopuigbn吧
 NoSQL 数据库分类
NoSQL 数据库分类

Redis 特性、
- 速度快: 10W QPS,基于内存,C语言实现
- 单线程
- 持久化
- 支持多种数据结构
- 支持多种编程语言
- 功能丰富: 支持Lua脚本,发布订阅,事务,pipeline等功能
- 简单: 代码短小精悍(单机核心代码只有23000行左右),单线程开发容易,不依赖外部库,使用简单
- 主从复制
- 支持高可用和分布式
单线程
Redis 6.0版本前一直是单线程方式处理用户的请求
单线程为何如此快?
- 纯内存
- 非阻塞
- 避免线程切换和竞态消耗
注意事项:
- 一次只运行一条命令
- 避免执行长(慢)命令:keys *, flushall, flushdb, slow lua script, mutil/exec, operate bigvalue(collection)
- 其实不是单线程: 早期版本是单进程单线程,3.0 版本后实际还有其它的线程, 实现特定功能,如: fysncfile descriptor,close file descriptor
Redis 对比 Memcached
 Redis 常见应用场景
Redis 常见应用场景
- 缓存:缓存RDBMS中数据,比如网站的查询结果、商品信息、微博、新闻、消息
- Session 共享:实现Web集群中的多服务器间的session共享
- 计数器:商品访问排行榜、浏览数、粉丝数、关注、点赞、评论等和次数相关的数值统计场景
- 社交:朋友圈、共同好友、可能认识他们等
- 地理位置: 基于地理信息系统GIS(Geographic Information System)实现摇一摇、附近的人、外卖等功能
- 消息队列:ELK等日志系统缓存、业务的订阅/发布系统
缓存的实现流程
数据更新操作流程:
数据读操作流程: 
缓存穿透,缓存击穿和缓存雪崩
缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,比如: 发起为id为 “-1” 的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方法:
- 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效
- 时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据,比如:热点数据的缓存时间到期后,这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力解决方法:
- 设置热点数据永远不过期。
缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方法:
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中
- 设置热点数据永远不过期
包安装 Redis
官方下载地址:
Index of /releases/
apt -y install gcc make libjemalloc-dev libsystemd-dev #安装相关依赖包
遇到错误
正在等待缓存锁:无法获得锁 /var/lib/dpkg/lock-frontend。锁正由进程 19571(unattended-upgr
解决
sudo rm /var/chche/apt/archives/lock
sudo rm /var/lib/dpkg/lock
make -j 2 USE_SYSTEMD=yes PREFIX=/apps/redis install #编译
ln -s /apps/redis/bin/* /usr/bin/ #创建软连接redis-server #配置文件默认启动的 打开之后会看到 WARNING问题
消除启动时的三个Warning提示信息(可选)
前面直接启动Redis时有三个Waring信息,可以用下面方法消除告警,但非强制消除
Tcp backlog
WARNING: The TCP backlog setting of 511 cannot be enforced because/proc/sys/net/core/somaxconn is set to the lower value of 128.
Tcp backlog 是指TCP的第三次握手服务器端收到客户端 ack确认号之后到服务器用Accept函数处理请求前的队列长度,即全连接队列
#vim /etc/sysctl.conf
net.core.somaxconn = 1024
#sysctl -p
overcommit_memory
WARNING overcommit_memory is set to 0! Background save may fail under low memorycondition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to
take effect.
内核参数说明:
- 内核参数overcommit_memory 实现内存分配策略,可选值有三个:0、1、2
- 0 表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则内存申请失败,并把错误返回给应用进程
- 1 表示内核允许分配所有的物理内存,而不管当前的内存状态如何
- 2 表示内核允许分配超过所有物理内存和交换空间总和的内存
范例:
#vim /etc/sysctl.conf
vm.overcommit_memory = 1
#sysctl -p
transparent hugepage
WARNING you have Transparent Huge Pages (THP) support enabled in your kernel.This will create latency and memory usage issues with Redis. To fix this issuerun the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' asroot, and add it to your /etc/rc.local in order to retain the setting after areboot. Redis must be restarted after THP is disabled.
警告:您在内核中启用了透明大页面(THP,不同于一般4k内存页,而为2M)支持。 这将在Redis中造成延迟和内存使用问题。 要解决此问题,请以root 用户身份运行命令“echo never>/sys/kernel/mm/transparent_hugepage/enabled”,并将其添加到您的/etc/rc.local中,以便在重启后保留设置。禁用THP后,必须重新启动Redis。
范例:
#查看默认值
[root@ubuntu2004 ~]#cat /sys/kernel/mm/transparent_hugepage/enabled
always [madvise] never
[root@rocky8 ~]#cat /sys/kernel/mm/transparent_hugepage/enabled
[always] madvise never
[root@centos7 ~]#cat /sys/kernel/mm/transparent_hugepage/enabled
[always] madvise never
#ubuntu开机配置
[root@ubuntu2004 ~]#cat /etc/rc.local
#!/bin/bash
echo never > /sys/kernel/mm/transparent_hugepage/enabled
[root@ubuntu2004 ~]#chmod +x /etc/rc.local
#CentOS开机配置
[root@centos8 ~]#echo 'echo never > /sys/kernel/mm/transparent_hugepage/enabled'
>> /etc/rc.d/rc.local
[root@centos8 ~]#cat /etc/rc.d/rc.local
#!/bin/bash
# THIS FILE IS ADDED FOR COMPATIBILITY PURPOSES
#
# It is highly advisable to create own systemd services or udev rules
# to run scripts during boot instead of using this file.
#
# In contrast to previous versions due to parallel execution during boot
# this script will NOT be run after all other services.
#
# Please note that you must run 'chmod +x /etc/rc.d/rc.local' to ensure
# that this script will be executed during boot.
touch /var/lock/subsys/local
echo never > /sys/kernel/mm/transparent_hugepage/enabled
[root@centos8 ~]#chmod +x /etc/rc.d/rc.local证是否消除 Warning
重新启动redis 服务不再有前面的三个Waring信息
[root@centos8 ~]#redis-server /apps/redis/etc/redis.conf
脚本编译安装
密码; auth 123456
#REDIS_VERSION=redis-7.0.5
#REDIS_VERSION=redis-7.0.3
#REDIS_VERSION=redis-6.2.6
REDIS_VERSION=redis-5.0.14
REDIS_URL=http://download.redis.io/releases
PASSWORD=123456
INSTALL_DIR=/apps/redis
CPUS=`lscpu |awk '/^CPU\(s\)/{print $2}'`
. /etc/os-release
color () {
RES_COL=60
MOVE_TO_COL="echo -en \\033[${RES_COL}G"
SETCOLOR_SUCCESS="echo -en \\033[1;32m"
SETCOLOR_FAILURE="echo -en \\033[1;31m"
SETCOLOR_WARNING="echo -en \\033[1;33m"
SETCOLOR_NORMAL="echo -en \E[0m"
echo -n "$1" && $MOVE_TO_COL
echo -n "["
if [ $2 = "success" -o $2 = "0" ] ;then
${SETCOLOR_SUCCESS}
echo -n $" OK "
elif [ $2 = "failure" -o $2 = "1" ] ;then
${SETCOLOR_FAILURE}
echo -n $"FAILED"
else
${SETCOLOR_WARNING}
echo -n $"WARNING"
fi
${SETCOLOR_NORMAL}
echo -n "]"
echo
}
prepare(){
if [ $ID = "centos" -o $ID = "rocky" ];then
yum -y install gcc make jemalloc-devel systemd-devel
else
apt update
apt -y install gcc make libjemalloc-dev libsystemd-dev
fi
if [ $? -eq 0 ];then
color "安装软件包成功" 0
else
color "安装软件包失败,请检查网络配置" 1
exit
fi
}
install() {
if [ ! -f ${REDIS_VERSION}.tar.gz ];then
wget ${REDIS_URL}/${REDIS_VERSION}.tar.gz || { color "Redis 源码下载失败" 1 ; exit; }
fi
tar xf ${REDIS_VERSION}.tar.gz -C /usr/local/src
cd /usr/local/src/${REDIS_VERSION}
make -j $CUPS USE_SYSTEMD=yes PREFIX=${INSTALL_DIR} install && color "Redis 编译安装完成" 0 || { color "Redis 编译安装失败" 1 ;exit ; }
ln -s ${INSTALL_DIR}/bin/redis-* /usr/bin/
mkdir -p ${INSTALL_DIR}/{etc,log,data,run}
cp redis.conf ${INSTALL_DIR}/etc/
sed -i -e 's/bind 127.0.0.1/bind 0.0.0.0/' -e "/# requirepass/a requirepass $PASSWORD" -e "/^dir .*/c dir ${INSTALL_DIR}/data/" -e "/logfile .*/c logfile ${INSTALL_DIR}/log/redis-6379.log" -e "/^pidfile .*/c pidfile ${INSTALL_DIR}/run/redis_6379.pid" ${INSTALL_DIR}/etc/redis.conf
if id redis &> /dev/null ;then
color "Redis 用户已存在" 1
else
useradd -r -s /sbin/nologin redis
color "Redis 用户创建成功" 0
fi
chown -R redis.redis ${INSTALL_DIR}
cat >> /etc/sysctl.conf < /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.d/rc.local
chmod +x /etc/rc.d/rc.local
/etc/rc.d/rc.local
else
echo -e '#!/bin/bash\necho never > /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.local
chmod +x /etc/rc.local
/etc/rc.local
fi
cat > /lib/systemd/system/redis.service < /dev/null
if [ $? -eq 0 ];then
color "Redis 服务启动成功,Redis信息如下:" 0
else
color "Redis 启动失败" 1
exit
fi
sleep 2
redis-cli -a $PASSWORD INFO Server 2> /dev/null
}
prepare
install 创建 Redis 用户和设置数据目录权限
[root@centos8 ~]#useradd -r -s /sbin/nologin redis
#设置目录权限
[root@centos8 ~]#chown -R redis.redis /apps/redis/创建 Redis 服务 Service 文件
#可以复制CentOS8利用yum安装Redis生成的redis.service文件,进行修改
[root@centos8 ~]#scp 10.0.0.8:/lib/systemd/system/redis.service
/lib/systemd/system/
[root@centos8 ~]#cp redis-stable/utils/systemd-redis_server.service
/lib/systemd/system/redis.service
[root@centos8 ~]#vim /lib/systemd/system/redis.service
[root@centos8 ~]#cat /lib/systemd/system/redis.service
[Unit]
Description=Redis persistent key-value database
After=network.target
[Service]
ExecStart=/apps/redis/bin/redis-server /apps/redis/etc/redis.conf --supervised
systemd
ExecStop=/bin/kill -s QUIT $MAINPID
Type=notify #如果支持systemd可以启用此行
User=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
LimitNOFILE=1000000 #指定此值才支持更大的maxclients值
[Install]
WantedBy=multi-user.targetRedis 通过Service方式启动
[root@centos8 ~]#systemctl daemon-reload
[root@centos8 ~]#systemctl start redis
[root@centos8 ~]#systemctl status redis
● redis.service - Redis persistent key-value database
Loaded: loaded (/usr/lib/systemd/system/redis.service; enabled; vendor preset:
disabled) Active: active (running) since Sun 2020-02-16 23:08:08 CST; 2s agoRedis 的多实例
1.2.3 Redis 的多实例
测试环境中经常使用多实例,需要指定不同实例的相应的端口,配置文件,日志文件等相关配置
范例: 以编译安装为例实现 redis 多实例
#创建端口文件
[root@ubuntu2004 etc]#sed 's/6379/6380/g' redis6379.conf > redis6380.conf
[root@ubuntu2004 etc]#sed 's/6379/6381/g' redis6379.conf > redis6381.conf
#修改权限
root@ubuntu2004 etc]#chown -R redis.redis .
#在里面创建出相应的文件
[root@ubuntu2004 etc]#cp /lib/systemd/system/redis6379.service/lib/systemd/system/redis6380.service
[root@ubuntu2004 etc]#cp /lib/systemd/system/redis6379.service/lib/systemd/system/redis6381.service
#在里面加端口号 同理三个文件都改成对应的数字
vim /lib/systemd/system/redis6379.service
ExecStart=/apps/redis/bin/redis-server /apps/redis/etc/redis6379.conf --supervised systemd
[root@ubuntu2004 etc]#vim /lib/systemd/system/redis6380.service
[root@ubuntu2004 etc]#vim /lib/systemd/system/redis6381.service
systemctl daemon-reload
[root@ubuntu2004 etc]#systemctl restart redis6379.service redis6380.service redis6381.service
[root@ubuntu2004 etc]#systemctl status redis6379.service redis6380.service redis6381.service
[root@ubuntu2004 ~]#redis-cli -h 10.0.0.100 -a 123456 -p 6380 #可以在别的机器上测试一下
#在里面把dump.rdb 这串内存备份文件后面加上数字 三个都做
vim /apps/redis/etc/redis6379.conf
dbfilename dump6379.rdb
客户端程序 redis-cli
#默认为本机无密码连接
redis-cli
#远程客户端连接,注意:Redis没有用户的概念
redis-cli -h-p -a
程序连接 Redis
Redis 支持多种开发语言访问
https://redis.io/docs/clients/
Shell 脚本访问 Redis
for i in {0..9999} ;do
redis-cli -h 10.0.0.100 -a 123456 --no-auth-warning set k$i v$i
redis-cli -h 10.0.0.100 -a 123456 --no-auth-warning get k$i
done
Python 程序连接 Redis
[root@ubuntu2004 ~]#apt -y install python3-pip python3-redis
[root@centos8 ~]#yum -y install python3 python3-redis
#!/usr/bin/python3
import redis
pool = redis.ConnectionPool(host="10.0.0.100",port=6379,password="123456",decode_responses=True)
r = redis.Redis(connection_pool=pool)
for i in range(100000):
r.set("k%d" % i,"v%d" % i)
data=r.get("k%d" % i)
print(data)
图形工具
有一些第三方开发的图形工具也可以连接redis, 比如: RedisDesktopManage



Redis 配置文件说明
bind 0.0.0.0 #指定监听地址,支持用空格隔开的多个监听IP
protected-mode yes #redis3.2之后加入的新特性,在没有设置bind IP和密码的时候,redis只允许访
问127.0.0.1:6379,可以远程连接,但当访问将提示警告信息并拒绝远程访问
port 6379 #监听端口,默认6379/tcp
tcp-backlog 511 #三次握手的时候server端收到client ack确认号之后的队列值,即全连接队列长度
timeout 0 #客户端和Redis服务端的连接超时时间,默认是0,表示永不超时
tcp-keepalive 300 #tcp 会话保持时间300s
daemonize no #默认no,即直接运行redis-server程序时,不作为守护进程运行,而是以前台方式运行,
如果想在后台运行需改成yes,当redis作为守护进程运行的时候,它会写一个 pid 到
/var/run/redis.pid 文件
supervised no #和OS相关参数,可设置通过upstart和systemd管理Redis守护进程,centos7后都使
用systemd
pidfile /var/run/redis_6379.pid #pid文件路径,可以修改
为/apps/redis/run/redis_6379.pid
loglevel notice #日志级别
logfile "/path/redis.log" #日志路径,示例:logfile "/apps/redis/log/redis_6379.log"
databases 16 #设置数据库数量,默认:0-15,共16个库
always-show-logo yes #在启动redis 时是否显示或在日志中记录记录redis的logo
save 900 1 #在900秒内有1个key内容发生更改,就执行快照机制
save 300 10 #在300秒内有10个key内容发生更改,就执行快照机制
save 60 10000 #60秒内如果有10000个key以上的变化,就自动快照备份
stop-writes-on-bgsave-error yes #默认为yes时,可能会因空间满等原因快照无法保存出错时,会禁
止redis写入操作,生产建议为no
#此项只针对配置文件中的自动save有效
rdbcompression yes #持久化到RDB文件时,是否压缩,"yes"为压缩,"no"则反之
rdbchecksum yes #是否对备份文件开启RC64校验,默认是开启
dbfilename dump.rdb #快照文件名
dir ./ #快照文件保存路径,示例:dir "/apps/redis/data"
#主从复制相关
# replicaof #指定复制的master主机地址和端口,5.0版之前的指令为
slaveof
# masterauth #指定复制的master主机的密码
replica-serve-stale-data yes #当从库同主库失去连接或者复制正在进行,从机库有两种运行方式:
1、设置为yes(默认设置),从库会继续响应客户端的读请求,此为建议值
2、设置为no,除去特定命令外的任何请求都会返回一个错误"SYNC with master in progress"。
replica-read-only yes #是否设置从库只读,建议值为yes,否则主库同步从库时可能会覆盖数据,造成
数据丢失
repl-diskless-sync no #是否使用socket方式复制数据(无盘同步),新slave第一次连接master时需
要做数据的全量同步,redis server就要从内存dump出新的RDB文件,然后从master传到slave,有两种
方式把RDB文件传输给客户端:
1、基于硬盘(disk-backed):为no时,master创建一个新进程dump生成RDB磁盘文件,RDB完成之后由
父进程(即主进程)将RDB文件发送给slaves,此为默认值
2、基于socket(diskless):master创建一个新进程直接dump RDB至slave的网络socket,不经过主
进程和硬盘
#推荐使用基于硬盘(为no),是因为RDB文件创建后,可以同时传输给更多的slave,但是基于socket(为
yes), 新slave连接到master之后得逐个同步数据。只有当磁盘I/O较慢且网络较快时,可用
diskless(yes),否则一般建议使用磁盘(no)
repl-diskless-sync-delay 5 #diskless时复制的服务器等待的延迟时间,设置0为关闭,在延迟时间
内到达的客户端,会一起通过diskless方式同步数据,但是一旦复制开始,master节点不会再接收新slave
的复制请求,直到下一次同步开始才再接收新请求。即无法为延迟时间后到达的新副本提供服务,新副本将排
队等待下一次RDB传输,因此服务器会等待一段时间才能让更多副本到达。推荐值:30-60
repl-ping-replica-period 10 #slave根据master指定的时间进行周期性的PING master,用于监测
master状态,默认10s
repl-timeout 60 #复制连接的超时时间,需要大于repl-ping-slave-period,否则会经常报超时
repl-disable-tcp-nodelay no #是否在slave套接字发送SYNC之后禁用 TCP_NODELAY,如果选
择"yes",Redis将合并多个报文为一个大的报文,从而使用更少数量的包向slaves发送数据,但是将使数据
传输到slave上有延迟,Linux内核的默认配置会达到40毫秒,如果 "no" ,数据传输到slave的延迟将会
减少,但要使用更多的带宽
repl-backlog-size 512mb #复制缓冲区内存大小,当slave断开连接一段时间后,该缓冲区会累积复制
副本数据,因此当slave 重新连接时,通常不需要完全重新同步,只需传递在副本中的断开连接后没有同步的
部分数据即可。只有在至少有一个slave连接之后才分配此内存空间,建议建立主从时此值要调大一些或在低峰
期配置,否则会导致同步到slave失败
repl-backlog-ttl 3600 #多长时间内master没有slave连接,就清空backlog缓冲区
replica-priority 100 #当master不可用,哨兵Sentinel会根据slave的优先级选举一个master,此
值最低的slave会优先当选master,而配置成0,永远不会被选举,一般多个slave都设为一样的值,让其自
动选择
#min-replicas-to-write 3 #至少有3个可连接的slave,mater才接受写操作
#min-replicas-max-lag 10 #和上面至少3个slave的ping延迟不能超过10秒,否则master也将停止写操作
requirepass foobared #设置redis连接密码,之后需要AUTH pass,如果有特殊符号,用" "引起来,生
产建议设置
rename-command #重命名一些高危命令,示例:rename-command FLUSHALL "" 禁用命令
#示例: rename-command del wang
maxclients 10000 #Redis最大连接客户端
maxmemory #redis使用的最大内存,单位为bytes字节,0为不限制,建议设为物理内存一半,
8G内存的计算方式8(G)*1024(MB)1024(KB)*1024(Kbyte),需要注意的是缓冲区是不计算在maxmemory
内,生产中如果不设置此项,可能会导致OOM
#maxmemory-policy noeviction 此为默认值
# MAXMEMORY POLICY:当达到最大内存时,Redis 将如何选择要删除的内容。您可以从以下行为中选择一
种:
#
# volatile-lru -> Evict 使用近似 LRU,只有设置了过期时间的键。
# allkeys-lru -> 使用近似 LRU 驱逐任何键。
# volatile-lfu -> 使用近似 LFU 驱逐,只有设置了过期时间的键。
# allkeys-lfu -> 使用近似 LFU 驱逐任何键。
# volatile-random -> 删除设置了过期时间的随机密钥。
# allkeys-random -> 删除一个随机密钥,任何密钥。
# volatile-ttl -> 删除过期时间最近的key(次TTL)
# noeviction -> 不要驱逐任何东西,只是在写操作时返回一个错误。
#
# LRU 表示最近最少使用
# LFU 表示最不常用
#
# LRU、LFU 和 volatile-ttl 都是使用近似随机算法实现的。
#
# 注意:使用上述任何一种策略,当没有合适的键用于驱逐时,Redis 将在需要更多内存的写操作时返回错
误。这些通常是创建新密钥、添加数据或修改现有密钥的命令。一些示例是:SET、INCR、HSET、LPUSH、
SUNIONSTORE、SORT(由于 STORE 参数)和 EXEC(如果事务包括任何需要内存的命令)。
#MAXMEMORY POLICY:当达到最大内存时,Redis 将如何选择要删除的内容。可以从下面行为中进行选
择:
# volatile-lru -> 在具有过期集的键中使用近似 LRU 驱逐。
# allkeys-lru -> 使用近似 LRU 驱逐任何键。
# volatile-lfu -> 在具有过期集的键中使用近似 LFU 驱逐。
# allkeys-lfu -> 使用近似 LFU 驱逐任何键。
# volatile-random -> 从具有过期设置的密钥中删除一个随机密钥。
# allkeys-random -> 删除一个随机密钥,任何密钥。
# volatile-ttl -> 删除过期时间最近的key(次TTL)
# noeviction -> 不要驱逐任何东西,只是在写操作时返回一个错误。
#
# LRU 表示最近最少使用
# LFU 表示最不常用
#
# LRU、LFU 和 volatile-ttl 均使用近似实现随机算法。
#
# 注意:使用上述任何一种策略,Redis 都会在写入时返回错误操作,当没有合适的键用于驱逐时。
appendonly no #是否开启AOF日志记录,默认redis使用的是rdb方式持久化,这种方式在许多应用中已经
足够用了,但是redis如果中途宕机,会导致可能有几分钟的数据丢失(取决于dump数据的间隔时间),根据
save来策略进行持久化,Append Only File是另一种持久化方式,可以提供更好的持久化特性,Redis会
把每次写入的数据在接收后都写入 appendonly.aof 文件,每次启动时Redis都会先把这个文件的数据读入
内存里,先忽略RDB文件。默认不启用此功能
appendfilename "appendonly.aof" #文本文件AOF的文件名,存放在dir指令指定的目录中
appendfsync everysec #aof持久化策略的配置
#no表示由操作系统保证数据同步到磁盘,Linux的默认fsync策略是30秒,最多会丢失30s的数据
#always表示每次写入都执行fsync,以保证数据同步到磁盘,安全性高,性能较差
#everysec表示每秒执行一次fsync,可能会导致丢失这1s数据,此为默认值,也生产建议值
#同时在执行bgrewriteaof操作和主进程写aof文件的操作,两者都会操作磁盘,而bgrewriteaof往往会
涉及大量磁盘操作,这样就会造成主进程在写aof文件的时候出现阻塞的情形,以下参数实现控制
no-appendfsync-on-rewrite no #在aof rewrite期间,是否对aof新记录的append暂缓使用文件同步
策略,主要考虑磁盘IO开支和请求阻塞时间。
#默认为no,表示"不暂缓",新的aof记录仍然会被立即同步到磁盘,是最安全的方式,不会丢失数据,但是要
忍受阻塞的问题
#为yes,相当于将appendfsync设置为no,这说明并没有执行磁盘操作,只是写入了缓冲区,因此这样并不
会造成阻塞(因为没有竞争磁盘),但是如果这个时候redis挂掉,就会丢失数据。丢失多少数据呢?Linux
的默认fsync策略是30秒,最多会丢失30s的数据,但由于yes性能较好而且会避免出现阻塞因此比较推荐
#rewrite 即对aof文件进行整理,将空闲空间回收,从而可以减少恢复数据时间
auto-aof-rewrite-percentage 100 #当Aof log增长超过指定百分比例时,重写AOF文件,设置为0表
示不自动重写Aof日志,重写是为了使aof体积保持最小,但是还可以确保保存最完整的数据
auto-aof-rewrite-min-size 64mb #触发aof rewrite的最小文件大小
aof-load-truncated yes #是否加载由于某些原因导致的末尾异常的AOF文件(主进程被kill/断电等),
建议yes
aof-use-rdb-preamble no #redis4.0新增RDB-AOF混合持久化格式,在开启了这个功能之后,AOF重
写产生的文件将同时包含RDB格式的内容和AOF格式的内容,其中RDB格式的内容用于记录已有的数据,而AOF
格式的内容则用于记录最近发生了变化的数据,这样Redis就可以同时兼有RDB持久化和AOF持久化的优点(既
能够快速地生成重写文件,也能够在出现问题时,快速地载入数据),默认为no,即不启用此功能
lua-time-limit 5000 #lua脚本的最大执行时间,单位为毫秒
cluster-enabled yes #是否开启集群模式,默认不开启,即单机模式
cluster-config-file nodes-6379.conf #由node节点自动生成的集群配置文件名称
cluster-node-timeout 15000 #集群中node节点连接超时时间,单位ms,超过此时间,会踢出集群
cluster-replica-validity-factor 10 #单位为次,在执行故障转移的时候可能有些节点和master断
开一段时间导致数据比较旧,这些节点就不适用于选举为master,超过这个时间的就不会被进行故障转移,不
能当选master,计算公式:(node-timeout * replica-validity-factor) + repl-ping-
replica-period
cluster-migration-barrier 1 #集群迁移屏障,一个主节点至少拥有1个正常工作的从节点,即如果主
节点的slave节点故障后会将多余的从节点分配到当前主节点成为其新的从节点。
cluster-require-full-coverage yes #集群请求槽位全部覆盖,如果一个主库宕机且没有备库就会出
现集群槽位不全,那么yes时redis集群槽位验证不全,就不再对外提供服务(对key赋值时,会出现
CLUSTERDOWN The cluster is down的提示,cluster_state:fail,但ping 仍PONG),而no则可以
继续使用,但是会出现查询数据查不到的情况(因为有数据丢失)。生产建议为no
#Slow log 是 Redis 用来记录超过指定执行时间的日志系统,执行时间不包括与客户端交谈,发送回复等
I/O操作,而是实际执行命令所需的时间(在该阶段线程被阻塞并且不能同时为其它请求提供服务),由于
slow log 保存在内存里面,读写速度非常快,因此可放心地使用,不必担心因为开启 slow log 而影响
Redis 的速度
slowlog-log-slower-than 10000 #以微秒为单位的慢日志记录,为负数会禁用慢日志,为0会记录每个
命令操作。默认值为10ms,一般一条命令执行都在微秒级,生产建议设为1ms-10ms之间
slowlog-max-len 128 #最多记录多少条慢日志的保存队列长度,达到此长度后,记录新命令会将最旧的命
令从命令队列中删除,以此滚动删除,即,先进先出,队列固定长度,默认128,值偏小,生产建议设为1000以上 config 命令实现动态修改配置
config 命令用于查看当前redis配置、以及不重启redis服务实现动态更改redis配置等
注意:不是所有配置都可以动态修改,且此方式无法持久保存
设置客户端连接密码
#设置连接密码
127.0.0.1:6379> CONFIG SET requirepass 123456
OK
#查看连接密码
127.0.0.1:6379> CONFIG GET requirepass
1) "requirepass"
2) "123456获取当前所有参数配置
2.2.2 获取当前配置
2.2.3 设置 Redis 使用的最大内存量
2.3 慢查询
#奇数行为键,偶数行为值
127.0.0.1:6379> CONFIG GET *
1) "dbfilename"
2) "dump.rdb"
3) "requirepas
。。。。。。。设置 Redis 使用的最大内存量
127.0.0.1:6379> CONFIG SET maxmemory 8589934592 或 1g|G
127.0.0.1:6379> CONFIG GET maxmemory
1) "maxmemory"
2) "8589934592"慢查询
网络慢,或者排队慢都不在慢的范围
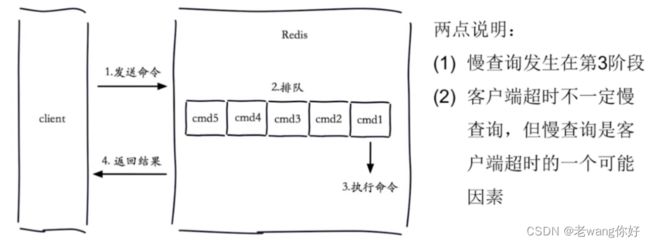
CONFIG sET slowlog-max-len 1024 set 改
CONFIG GET slowlog-max-len #get 查
[root@centos8 ~]#vim /etc/redis.conf
CONFIG SET slowlog-log-slower-than 1 #单位为us,指定超过1us即为慢的指令,默认值为10000us
CONFIG sET slowlog-max-len 1024 #指定只保存最近的1024条慢记录,默认值为128
127.0.0.1:6379> SLOWLOG LEN #查看慢日志的记录条数
(integer) 14
127.0.0.1:6379> SLOWLOG GET [n] #查看慢日志的最近n条记录,默认为10
1) 1) (integer) 14
2) (integer) 1544690617
3) (integer) 4 #第3)行表示每条指令的执行时长
4) 1) "slowlog"
127.0.0.1:6379> SLOWLOG RESET #清空慢日志
CONFIG sET slowlog-max-len 1024 set 改
CONFIG GET slowlog-max-len #get 查keys命令
Redis keys 命令用于查找所有符合给定模式 pattern 的 key
语法
keys patternpattern:
- *
- ?
- [ ]
例如:
- keys * 匹配数据库中所有 key
- keys h?llo 匹配 hello , hallo 和 hxllo 等
- keys h*llo 匹配 hllo 和 heeeeello 等
- keys h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
返回值
符合给定模式的 key 列表。
原文链接:https://blog.csdn.net/qq_32617703/article/details/103542532
常用命令
[root@ubuntu2004 data]#redis-cli -a 123456 dbsize #判断数据的存储量
FLUSHALL 删除所有
127.0.0.1:6379> DEL xxx 删除一个
127.0.0.1:6379> set class m5 写
10.0.0.102:6379> get class 看
127.0.0.1:6379> keys * 查看所有
Redis 持久化
Redis 是基于内存型的NoSQL, 和MySQL是不同的,使用内存进行数据保存
如果想实现数据的持久化,Redis也也可支持将内存数据保存到硬盘文件中
Redis支持两种数据持久化保存方法
- RDB:Redis DataBase
- AOF:AppendOnlyFile

Redis提供的持久化方式 ,快照(RDB),追加式文件(AOF)
Redis有两种持久化的方式,一种是快照(RDB)而另一种是追加式文件(AOF)
先来看看二者大概是如何工作的
RDB
RDB是 Redis默认采用的持久化方式
当符合一定条件时,Redis 会自动将内存中的数据进行快照并持久化到硬盘。
AOF
AOF相对于 RDB来说数据会更加的安全,也会更加的吃性能(这也就是为什么 Redis不将其设置为默认 策略的原因之一
但我们可以在 已经使用 RBD的同时打开 AOF,使我们的数据更加的安全(4.0版本以上)
AOF实现本质是基于Redis通讯协议,将命令以纯文本的方式写入到对应文件中。
RDB
RDB 工作原理
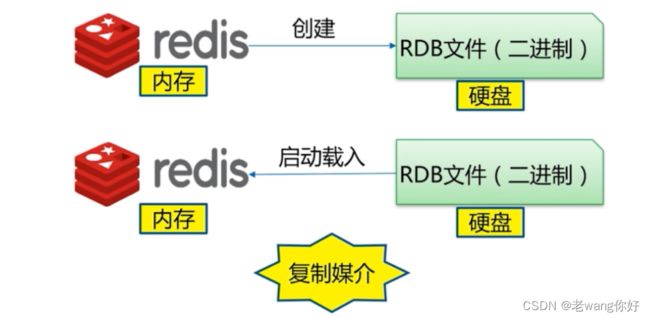
RDB(Redis DataBase):是基于某个时间点的快照,注意RDB只保留当前最新版本的一个快照
RDB 持久化功能所生成的 RDB 文件是一个经过压缩的二进制文件,通过该文件可以还原生成该 RDB 文件时数据库的状态。因为 RDB 文件是保存在磁盘中的,所以即便 Redis 服务进程甚至服务器宕机,只要磁盘中 RDB 文件存在,就能将数据恢复
RDB bgsave 实现快照的具体过程:
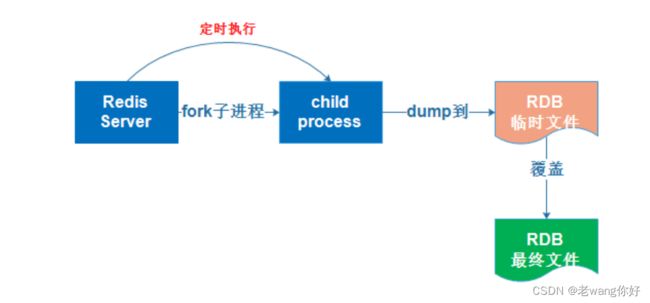
首先从redis 主进程先fork生成一个新的子进程,此子进程负责将Redis内存数据保存为一个临时文件tmp-<子进程pid>.rdb,当数据保存完成后,再将此临时文件改名为RDB文件,如果有前一次保存的会被替换,最后关闭此子进程
由于Redis只保留最后一个版本的RDB文件,如果想实现保存多个版本的数据,需要人为实现

范例: save 执行过程会使用主进程进行快照 save 是阻塞性的他不执行完,别的命令无法执行
[root@centos8 data]#redis-cli -a 123456 save& #保存的意思
[1] 28684
[root@centos8 data]#pstree -p |grep redis ;ll /apps/redis/data
|-redis-server(28650)-+-{redis-server}(28651)
| |-{redis-server}(28652)
| |-{redis-server}(28653)
| `-{redis-server}(28654)
| | `-redis-cli(28684)
| `-sshd(23494)---bash(23496)---redis-cli(28601)
total 251016
-rw-r--r-- 1 redis redis 189855682 Nov 17 15:02 dump.rdb
-rw-r--r-- 1 redis redis 45674498 Nov 17 15:02 temp-28650.rdb范例:RDB 相关配置 #自动保存
#在配置文件中的 save 选项设置多个保存条件,只有任何一个条件满足,服务器都会自动执行 BGSAVE 命
令
save 900 1 #900s内修改了1个key即触发保存RDB
save 300 10 #300s内修改了10个key即触发保存RDB
save 60 10000 #60s内修改了10000个key即触发保存RDB
dbfilename dump.rdb
dir ./ #编泽编译安装时默认RDB文件存放在Redis的工作目录,此配置可指定保存的数据目
录
stop-writes-on-bgsave-error yes #当快照失败是否仍允许写入,yes为出错后禁止写入,建议为no
rdbcompression yes
rdbchecksum yes
[root@ubuntu2004 ~]#grep save /apps/redis/etc/redis.conf
# save
# Redis will save the DB if both the given number of seconds and the given
# save ""
# Unless specified otherwise, by default Redis will save the DB:
# save 3600 1
# save 300 100
# save 60 10000
#以上是默认值
[root@ubuntu2004 ~]#redis-cli config get save
1) "save"
2) "3600 1 300 100 60 10000"
#禁用系统的自动快照
[root@ubuntu2004 ~]#vim /apps/redis/etc/redis.conf
save "" #加空
# save 3600 1
# save 300 100
# save 60 10000 实现 RDB 方法
- save: 同步,不推荐使用,使用主进程完成快照,因此会阻赛其它命令执行
- bgsave: 异步后台执行,不影响其它命令的执行,会开启独立的子进程,因此不会阻赛其它命令执行
- 配置文件实现自动保存: 在配置文件中制定规则,自动执行bgsave
RDB 模式的优缺点
1 RDB 模式优点
- RDB快照只保存某个时间点的数据,恢复的时候直接加载到内存即可,不用做其他处理,这种文件适合用于做灾备处理.可以通过自定义时间点执行redis指令bgsave或者save保存快照,实现多个版本的备份 比如: 可以在最近的24小时内,每小时备份一次RDB文件,并且在每个月的每一天,也备份一个 RDB文件。这样的话,即使遇上问题,也可以随时将数据集还原到指定的不同的版本。
- RDB在大数据集时恢复的速度比AOF方式要快
2 RDB 模式缺点
- 不能实时保存数据,可能会丢失自上一次执行RDB备份到当前的内存数据
- 如果需要尽量避免在服务器故障时丢失数据,那么RDB并不适合。虽然Redis允许设置不同的保存点(save point)来控制保存RDB文件的频率,但是,因为RDB文件需要保存整个数据集的状态,所以它可能并不是一个非常快速的操作。因此一般会超过5分钟以上才保存一次RDB文件。在这种情况下,一旦发生故障停机,就可能会丢失较长时间的数据。
- 在数据集比较庞大时,fork()子进程可能会非常耗时,造成服务器在一定时间内停止处理客端请求,如果数据集非常巨大,并且CPU时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒或更久。另外子进程完成生成RDB文件的时间也会花更长时间.
AOF 工作原理

AOF 即 AppendOnlyFile,AOF 和 RDB 都采有COW机制,AOF可以指定不同的保存策略,默认为每秒钟执行一次 fsync,按照操作的顺序地将变更命令追加至指定的AOF日志文件尾部
在第一次启用AOF功能时,会做一次完全备份,后续将执行增量性备份,相当于完全数据备份+增量变化
如果同时启用RDB和AOF,进行恢复时,默认AOF文件优先级高于RDB文件,即会使用AOF文件进行复
在第一次开启AOF功能时,会自动备份所有数据到AOF文件中,后续只会记录数据的更新指令
注意: AOF 模式默认是关闭的,第一次开启AOF后,并重启服务生效后,会因为AOF的优先级高于RDB,而AOF默认没有数据文件存在,从而导致所有数据丢失
尽量重启,用stop 关 用start开,修改完之后重启他就重启写入
[root@ubuntu1804 ~]#redis-cli
127.0.0.1:6379> dbsize
(integer) 10010011
[root@ubuntu1804 ~]#vim /apps/redis/etc/redis.conf
appendonly yes #修改此行
[root@ubuntu1804 data]#systemctl restart redis
[root@ubuntu1804 ~]#redis-cli
127.0.0.1:6379> dbsize
(integer) 0
#这样重启数据就不会丢失了
[root@ubuntu2004 data]#redis-cli -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> CONFIG GET appendonly
1) "appendonly"
2) "no"
127.0.0.1:6379> CONFIG sET appendonly yes
OK
127.0.0.1:6379> CONFIG GET appendonly
1) "appendonly"
2) "yes"
[root@centos8 ~]#vim /etc/redis.conf
appendonly yes #改为yesAOF 相关配置
appendonly no #是否开启AOF日志记录,默认redis使用的是rdb方式持久化,这种方式在许多应用中已经
足够用了,但是redis如果中途宕机,会导致可能有几分钟的数据丢失(取决于dump数据的间隔时间),根据
save来策略进行持久化,Append Only File是另一种持久化方式,可以提供更好的持久化特性,Redis会
把每次写入的数据在接收后都写入 appendonly.aof 文件,每次启动时Redis都会先把这个文件的数据读入
内存里,先忽略RDB文件。默认不启用此功能
appendfilename "appendonly.aof" #文本文件AOF的文件名,存放在dir指令指定的目录中
appendfsync everysec #aof持久化策略的配置
#no表示由操作系统保证数据同步到磁盘,Linux的默认fsync策略是30秒,最多会丢失30s的数据
#always表示每次写入都执行fsync,以保证数据同步到磁盘,安全性高,性能较差 #每次都写入
#everysec表示每秒执行一次fsync,可能会导致丢失这1s数据,此为默认值,也生产建议值
dir /path
#rewrite相关
no-appendfsync-on-rewrite yes
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes手动执行AOF重写 BGREWRITEAOF 命令 #误删除回复
#原理
BGREWRITEAOF
时间复杂度: O(N), N 为要追加到 AOF 文件中的数据数量。
执行一个 AOF文件 重写操作。重写会创建一个当前 AOF 文件的体积优化版本。
即使 BGREWRITEAOF 执行失败,也不会有任何数据丢失,因为旧的 AOF 文件在 BGREWRITEAOF 成功之
前不会被修改。
重写操作只会在没有其他持久化工作在后台执行时被触发,也就是说:
如果 Redis 的子进程正在执行快照的保存工作,那么 AOF 重写的操作会被预定(scheduled),等到保存
工作完成之后再执行 AOF 重写。在这种情况下, BGREWRITEAOF 的返回值仍然是 OK ,但还会加上一条
额外的信息,说明 BGREWRITEAOF 要等到保存操作完成之后才能执行。在 Redis 2.6 或以上的版本,可
以使用 INFO [section] 命令查看 BGREWRITEAOF 是否被预定。
如果已经有别的 AOF 文件重写在执行,那么 BGREWRITEAOF 返回一个错误,并且这个新的
BGREWRITEAOF 请求也不会被预定到下次执行。
从 Redis 2.4 开始, AOF 重写由 Redis 自行触发, BGREWRITEAOF 仅仅用于手动触发重写操作。
案例:
127.0.0.1:6379> dbsize 查看
(integer) 16483
127.0.0.1:6379> FLUSHALL 用来清空redis所有的库
OK
127.0.0.1:6379> dbsize
(integer) 0
127.0.0.1:6379> set house big
OK
127.0.0.1:6379> get house
"big"
127.0.0.1:6379> dbsize
(integer) 1
在另一个页面 打开删除这三行
[root@ubuntu2004 data]#systemctl stop redis
[root@ubuntu2004 data]#vim appendonly.aof
[root@ubuntu2004 data]#systemctl start redis
127.0.0.1:6379> dbsize
(integer) 16484

rewrite 重写

将一些重复的,可以合并的,过期的数据重新写入一个新的AOF文件,从而节约AOF备份占用的硬盘空间,也能加速恢复过程
可以手动执行bgrewriteaof 触发AOF,第一次开启AOF功能,或定义自动rewrite 策略
AOF rewrite 重写相关配置
#同时在执行bgrewriteaof操作和主进程写aof文件的操作,两者都会操作磁盘,而bgrewriteaof往往会
涉及大量磁盘操作,这样就会造成主进程在写aof文件的时候出现阻塞的情形,以下参数实现控制
no-appendfsync-on-rewrite no #在aof rewrite期间,是否对aof新记录的append暂缓使用文件同步
策略,主要考虑磁盘IO开支和请求阻塞时间。
#默认为no,表示"不暂缓",新的aof记录仍然会被立即同步到磁盘,是最安全的方式,不会丢失数据,但是要
忍受阻塞的问题
#为yes,相当于将appendfsync设置为no,这说明并没有执行磁盘操作,只是写入了缓冲区,因此这样并不
会造成阻塞(因为没有竞争磁盘),但是如果这个时候redis挂掉,就会丢失数据。丢失多少数据呢?Linux
的默认fsync策略是30秒,最多会丢失30s的数据,但由于yes性能较好而且会避免出现阻塞因此比较推荐
#rewrite 即对aof文件进行整理,将空闲空间回收,从而可以减少恢复数据时间
auto-aof-rewrite-percentage 100 #当Aof log增长超过指定百分比例时,重写AOF文件,设置为0表
示不自动重写Aof日志,重写是为了使aof体积保持最小,但是还可以确保保存最完整的数据
auto-aof-rewrite-min-size 64mb #触发aof rewrite的最小文件大小
aof-load-truncated yes #是否加载由于某些原因导致的末尾异常的AOF文件(主进程被kill/断电等),
建议yesAOF 模式优点
- 数据安全性相对较高,根据所使用的fsync策略(fsync是同步内存中redis所有已经修改的文件到存储设备),默认是appendfsync everysec,即每秒执行一次 fsync,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync会在后台线程执行,所以主线程可以继续努力地处理命令请求)
- 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中不需要seek, 即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,可以通过 redis-check-aof 工具来解决数据一致性的问题
- Redis可以在 AOF文件体积变得过大时,自动地在后台对AOF进行重写,重写后的新AOF文件包含了恢复当前数据集所需的最小命令集合。整个重写操作是绝对安全的,因为Redis在创建新 AOF文件的过程中,append模式不断的将修改数据追加到现有的 AOF文件里面,即使重写过程中发生停机,现有的 AOF文件也不会丢失。而一旦新AOF文件创建完毕,Redis就会从旧AOF文件切换到新AOF文件,并开始对新AOF文件进行追加操作。
- AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,也可以通过该文件完成数据的重建
- AOF文件有序地保存了对数据库执行的所有写入操作,这些写入操作以Redis协议的格式保存,因此 AOF文件的内容非常容易被人读懂,对文件进行分析(parse)也很轻松。导出(export)AOF文件也非常简单:举个例子,如果不小心执行了FLUSHALL.命令,但只要AOF文件未被重写,那么只要停止服务器,移除 AOF文件末尾的FLUSHAL命令,并重启Redis ,就可以将数据集恢复到FLUSHALL执行之前的状态。
AOF 模式缺点
- 即使有些操作是重复的也会全部记录,AOF 的文件大小一般要大于 RDB 格式的文件
- AOF 在恢复大数据集时的速度比 RDB 的恢复速度要慢
- 如果 fsync 策略是appendfsync no, AOF保存到磁盘的速度甚至会可能会慢于RDB
- bug 出现的可能性更多
RDB和AOF 的选择、
- 如果主要充当缓存功能,或者可以承受较长时间,比如数分钟数据的丢失, 通常生产环境一般只需启用RDB即可,此也是默认值
- 如果一点数据都不能丢失,可以选择同时开启RDB和AOF
- 一般不建议只开启AOF
Redis 常用命令
INFO 显示当前节点redis运行状态信息
redis-cli info server #可以指定或者全部
SELECT切换数据库,相当于在MySQL的 USE DBNAME 指令 #0-15 16个
127.0.0.1:6379[1]> SELECT 15
OK
KEYS 查看当前库下的所有key,此 命令慎用!
FLUSHALL强制清空当前Redis服务器所有数据库中的所有key,即删除所有数据,此命令慎用
#生产建议修改配置使用rename-command禁用此命令
vim /etc/redis.conf
rename-command FLUSHALL "“ #flushdb和flushall 配置和AOF功能冲突,需要设置 appendonly
no
#rename-command 可能会在后续版本淘汰
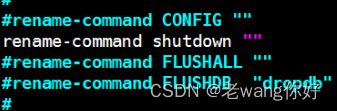
SHUTDOWN
可用版本: >= 1.0.0
时间复杂度: O(N),其中 N 为关机时需要保存的数据库键数量。
SHUTDOWN 命令执行以下操作:
关闭Redis服务,停止所有客户端连接
如果有至少一个保存点在等待,执行 SAVE 命令
如果 AOF 选项被打开,更新 AOF 文件
关闭 redis 服务器(server)
如果持久化被打开的话, SHUTDOWN 命令会保证服务器正常关闭而不丢失任何数据。
另一方面,假如只是单纯地执行 SAVE 命令,然后再执行 QUIT 命令,则没有这一保证 —— 因为在执行
SAVE 之后、执行 QUIT 之前的这段时间中间,其他客户端可能正在和服务器进行通讯,这时如果执行 QUIT
就会造成数据丢失。
#建议关闭此指令
vim /etc/redis.conf
rename-command shutdown ""
列表 list
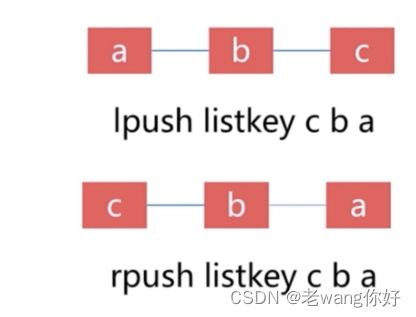
Redis列表就是简单的字符串数组,按照插入顺序排序. 支持双向读写,可以添加一个元素到列表的头部(左边)或者尾部(右边),一个列表最多可以包含2^32-1=4294967295个元素,每个列表元素有下标来标识,下标 0 表示列表的第一个元素,以 1 表示列表的第二个元素,以此类推。 也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,元素值可以重复,常用于存入日志等场景,此数据类型比较常用
列表特点
- 有序
- 可重复
- 左右都可以操作
创建列表和数据
集合间操作
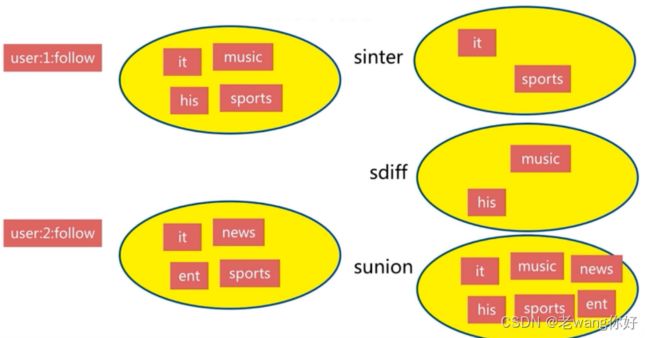
Set 是一个无序的字符串合集,同一个集合中的每个元素是唯一无重复的,支持在两个不同的集合中对数据进行逻辑处理,常用于取交集,并集,统计等场景,例如: 实现共同的朋友
集合特点
- 无序
- 无重复
- 集合间操作
LPUSH key value [value ...]
时间复杂度: O(1)
将一个或多个值 value 插入到列表 key 的表头
如果有多个 value 值,那么各个 value 值按从左到右的顺序依次插入到表头: 比如说,对空列表
mylist 执行命令 LPUSH mylist a b c ,列表的值将是 c b a ,这等同于原子性地执行 LPUSH
mylist a 、 LPUSH mylist b 和 LPUSH mylist c 三个命令。
如果 key 不存在,一个空列表会被创建并执行 LPUSH 操作。
当 key 存在但不是列表类型时,返回一个错误。
RPUSH key value [value ...]
时间复杂度: O(1)
将一个或多个值 value 插入到列表 key 的表尾(最右边)。
如果有多个 value 值,那么各个 value 值按从左到右的顺序依次插入到表尾:比如对一个空列表 mylist
执行 RPUSH mylist a b c ,得出的结果列表为 a b c ,等同于执行命令 RPUSH mylist a 、
RPUSH mylist b 、 RPUSH mylist c 。
如果 key 不存在,一个空列表会被创建并执行 RPUSH 操作。
当 key 存在但不是列表类型时,返回一个错误。
范例
#从左边添加数据,已添加的需向右移
127.0.0.1:6379> LPUSH name mage wang zhang #根据顺序逐个写入name,最后的zhang会在列表
的最左侧。
(integer) 3
127.0.0.1:6379> TYPE name
list
#从右边添加数据
127.0.0.1:6379> RPUSH course linux python go
(integer) 3
127.0.0.1:6379> type course
list列表追加新数据
127.0.0.1:6379> LPUSH list1 tom
(integer) 2
#从右边添加数据,已添加的向左移
127.0.0.1:6379> RPUSH list1 jack
(integer) 3
获取列表长度(元素个数)
127.0.0.1:6379> LLEN list1
(integer) 3

27.0.0.1:6379> LPUSH list1 a b c d
(integer) 4
127.0.0.1:6379> LINDEX list1 0 #获取0编号的元素
"d"
127.0.0.1:6379> LINDEX list1 3 #获取3编号的元素
"a"
127.0.0.1:6379> LINDEX list1 -1 #获取最后一个的元素
"a"
#元素从0开始编号
127.0.0.1:6379> LPUSH list1 a b c d
(integer) 4
127.0.0.1:6379> LRANGE list1 1 2
1) "c"
2) "b"
127.0.0.1:6379> LRANGE list1 0 3 #所有元素
1) "d"
2) "c"
3) "b"
4) "a"
127.0.0.1:6379> LRANGE list1 0 -1 #所有元素
1) "d"
2) "c"
3) "b"
4) "a"
127.0.0.1:6379> RPUSH list2 zhang wang li zhao
(integer) 4
127.0.0.1:6379> LRANGE list2 1 2 #指定范围
1) "wang"
2) "li"
127.0.0.1:6379> LRANGE list2 2 2 #指定位置
1) "li"
127.0.0.1:6379> LRANGE list2 0 -1 #所有元素
1) "zhang"
2) "wang"
创建集合
127.0.0.1:6379> SADD set1 v1
(integer) 1
127.0.0.1:6379> SADD set2 v2 v4
(integer) 2
127.0.0.1:6379> TYPE set1
set
127.0.0.1:6379> TYPE set2
set
集合中追加数据
#追加时,只能追加不存在的数据,不能追加已经存在的数值
127.0.0.1:6379> SADD set1 v2 v3 v4
(integer) 3
127.0.0.1:6379> SADD set1 v2 #已存在的value,无法再次添加
(integer) 0
127.0.0.1:6379> TYPE set1
set
127.0.0.1:6379> TYPE set2
set
有序集合 sorted set
Redis有序集合和Redis集合类似,是不包含相同字符串的合集。它们的差别是,每个有序集合的成员都关联着一个双精度浮点型的评分,这个评分用于把有序集合中的成员按最低分到最高分排序。有序集合的成员不能重复,但评分可以重复,一个有序集合中最多的成员数为 2^32 - 1=4294967295个,经常用于排行榜的场景

有序集合特点
- 有序
- 无重复元素
- 每个元素是由score和value组成
- score 可以重复
- value 不可以重复
创建有序集合
127.0.0.1:6379> ZADD zset1 1 v1 #分数为1
(integer) 1
127.0.0.1:6379> ZADD zset1 2 v2
(integer) 1
127.0.0.1:6379> ZADD zset1 2 v3 #分数可重复,元素值不可以重复
(integer) 1
127.0.0.1:6379> ZADD zset1 3 v4
(integer) 1
127.0.0.1:6379> TYPE zset1
zset
127.0.0.1:6379> TYPE zset2
zset#一次生成多个数据:
127.0.0.1:6379> ZADD zset2 1 v1 2 v2 3 v3 4 v4 5 v5
(integer) 5
实现排名
127.0.0.1:6379> ZADD course 90 linux 99 go 60 python 50 cloud
(integer) 4
127.0.0.1:6379> ZRANGE course 0 -1 #正序排序后显示集合内所有的key,按score从小到大显示
1) "cloud"
2) "python"
3) "linux"
4) "go"
127.0.0.1:6379> ZREVRANGE course 0 -1 #倒序排序后显示集合内所有的key,score从大到小显示
1) "go"
2) "linux"
3) "python"
4) "cloud"
127.0.0.1:6379> ZRANGE course 0 -1 WITHSCORES #正序显示指定集合内所有key和得分情况
1) "cloud"
2) "50"
3) "python"
4) "60"
5) "linux"
6) "90"
7) "go"
8) "99"
127.0.0.1:6379> ZREVRANGE course 0 -1 WITHSCORES #倒序显示指定集合内所有key和得分情况
1) "go"
2) "99"
3) "linux"
4) "90"
5) "python"
6) "60"
7) "cloud"
8) "50"
127.0.0.1:6379>
查看集合的成员个数
127.0.0.1:6379> ZCARD course
(integer) 4
127.0.0.1:6379> ZCARD zset1
(integer) 4
127.0.0.1:6379> ZCARD zset2
(integer) 4