【PyTorch 卷积】实战自定义的图片归类
前言
卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一,它通过卷积层、池化层、全连接层等结构,可以有效地处理如时间序列和图片数据等。关于卷积的概念网络上也比较多,这里就不一一描述了。实战为主当然要从实际问题出发,用代码的方式加深印象。在写代码前,我先说一下为什么我要写这篇文章?
之前我也用 Tensorflow.js 跟着别人试过图片分类,虽然结果是有了,但是对代码的理解和印象并不深刻。后来由于工作业务原因才接触 PyTorch,发现这个框架更好上手,整一圈后就想用这个把之前用得图片也实现一下分类。开始也是看文章实现,但是网上大部分都是用 MNIST 数据集实现的手写字识别,而业务中有时就是一些指定的不规则小众图片识别,所以下面就简单实现一个自定义的图片集归类。

流程
- 根据自己的定义,收集图片并归类
- 读取图片数据和归类标签,保存数据集
- 固定图片大小 (会变形),归一化转张量
- 定义超参数,损失函数和优化器等
- 炼丹,重复查看损失值准确率等指标
- 保存模型参数,加载测试图片分类效果

环境
- Python 3.8
- Torch 1.9.0
- Pillow 10.0
- Torchvision
- Numpy
- Pandas
- Matplotlib
编码
写代码前已经把需要的图片做好了分类,上面的依赖包也已经安装完毕。由于只是演示这里没有用预训练模型(ResNet、VGG),因为训练时要用的是 Tensor,所以需要先读取文件夹内的图片先转化为 PIL 的对象数据或 Numpy 数据,然后可以对图片进行调整,最后全都转成 Tensor(也可以跳过 PIL 直接转张量)。这里需要注意的是对灰彩图片通道,不同尺寸图的统一处理,就是灰色图的单通道要通过复制的方式创建三个通道,所以图片设置一样的像素大小。因为在卷积网络中,输入的通道数和输入大小要一致,不然可能在训练中报错。
图片数据生成
这里就是遍历各个分类文件夹的图片转换为对象信息数据,和提取所有分类,分别保存到指定位置,当然也可以在这里划分训练数据,校验数据,测试数据,需要的可以扩展这里就跳过了。
# -*- coding: utf-8 -*-
import os
import pickle as pkl
import pandas as pd
from PIL import Image
all_cate = []
data_set = []
directory = "./data/train"
for index, data in enumerate(os.walk(directory)):
root, dirs, files = data
if index == 0:
all_cate += dirs
else:
sorted(all_cate)
root_names = root.split("\\")
dir_name = root_names[-1]
for img in files:
img_path = root + "\\" + img
img_np = Image.open(img_path)
dict = {}
dict['img_np'] = img_np
dict['label'] = all_cate.index(dir_name) + 1
data_set.append(dict)
# 字典转DataFrame
df = pd.DataFrame(data_set)
pkl.dump(df, open('data/train_dataset.p', 'wb'))
open("data/all_cate.txt", encoding="utf-8", mode="w+").write("\n".join(all_cate))
print("存档数据成功~")
批量数据集标准化
这里是读取序列化的图片信息,对所有图片统一像素 (一般配置电脑最好在 100px 以内,不然会很卡) 并标准归一化后,转换为 Tensor。然后判断图片通道数,如果是灰色图,可以复制张量三次以创建三个通道,最后通过 torch 的 DataLoader 在训练前完成数据集的加载。
# -*- coding: utf-8 -*-
import torch
from torchvision import transforms
import pickle as pkl
from torch.utils.data import Dataset
class DataSet(Dataset):
def __init__(self, pkl_file):
df = pkl.load(open(pkl_file, 'rb'))
self.dataFrame = df
def __len__(self):
return len(self.dataFrame)
def __getitem__(self, item):
img_np = self.dataFrame.iloc[item, 0]
label = self.dataFrame.iloc[item, 1]
transform = transforms.Compose([
transforms.Resize((100, 100)), # 根据需要调整图像大小
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]) # 标准归一化, p1.均值 p2.方差
])
image_tensor = transform(img_np)
if image_tensor.shape[0] == 1:
image_tensor = image_tensor.repeat(3, 1, 1)
res = {
'img_tensor': image_tensor,
'label': torch.LongTensor([label-1]) # 需要实际的索引值
}
return res神经网络模型
这里创建的是卷积神经网络,接收 3 通道,第一层卷积层卷积核 3x3,输出 25 维张量,通过批标准化(BatchNorm2d)进行归一化处理,最后通过 ReLU 激活函数进行非线性变换。第一层池化使用 2x2 的最大池化操作对卷积后的特征图进行下采样。第二层也是卷积和对应的池化,最后是全连接层。将经过池化的特征图展平,然后通过一个有 1024 个神经元的全连接层,再通过 ReLU 激活函数进行非线性变换。之后是一个有 128 个神经元的全连接层,最后再通过 ReLU 激活函数进行非线性变换,输出 5 个神经元代表分类的概率分布。
# -*- coding: utf-8 -*-
import torch.nn as nn
import torch
import math
import torch.functional as F
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(3, 25, kernel_size=3),
nn.BatchNorm2d(25),
nn.ReLU(inplace=True)
)
self.layer2 = nn.Sequential(
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.layer3 = nn.Sequential(
nn.Conv2d(25, 50, kernel_size=3),
nn.BatchNorm2d(50),
nn.ReLU(inplace=True)
)
self.layer4 = nn.Sequential(
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc = nn.Sequential(
nn.Linear(50 * 23 * 23, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 5)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
开始训练
# -*- coding:utf-8 -*-
import torch
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from data_set import DataSet
from torch.autograd import Variable
from utils import *
import cnn
import torch.nn as nn
import numpy as np
import torch.optim as optim
# 定义超参数
batch_size = 1
learning_rate = 0.02
num_epoches = 1
# 加载图片tensor训练集
tain_dataset = DataSet("data/train_dataset.p")
train_loader = DataLoader(tain_dataset, batch_size=batch_size, shuffle=True)
model = cnn.CNN()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
# 训练模型
train_loses = []
records = []
for i in range(num_epoches):
for ii, data in enumerate(train_loader):
img = data['img_tensor']
label = data['label'].view(-1)
optimizer.zero_grad()
out = model(img)
loss = criterion(out, label)
train_loses.append(loss.data.item())
loss.backward()
optimizer.step()
if ii % 50 == 0:
print('epoch: {}, loop: {}, loss: {:.4}'.format(i, ii, np.mean(train_loses)))
records.append([np.mean(train_loses)])
# 绘制模型的损失,准确率走势图
train_loss = [data[0] for data in records]
plt.plot(train_loss, label = 'Train Loss')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.legend()
plt.show()
# 模型评估(略)
# model.eval()
# 模型保存
torch.save(model, 'params/cnn_imgs_02.pkl')
模型检测
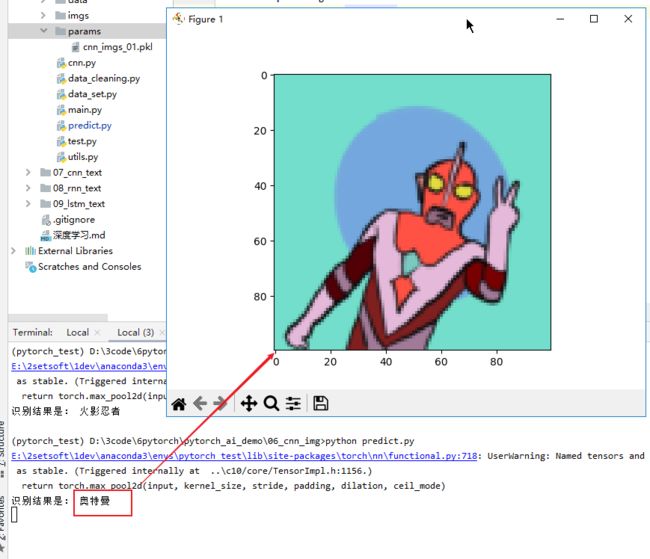
训练完成保存参数到本地,下面就是将加载进的参数来测试其他图片的分类效果,同样的也是将指定图片和训练时一样的转换操作,最后将预测结果取出最大分布索引值,根据索引就可以匹配出分类名称了。另一个是工具函数,将 tensor 格式的图片在预测结果后显示在 pyplot 中。
# -*- coding:utf-8 -*-
import torch
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from data_set import DataSet
from utils import *
import torchvision
from PIL import Image
from torchvision import transforms
import cnn
def imshow(img):
img = img / 2 + 0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
model = torch.load("params/cnn_imgs_02.pkl")
img_path= "imgs/05.jpg"
img_np = Image.open(img_path)
transform = transforms.Compose([
transforms.Resize((100, 100)),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
image_tensor = transform(img_np)
# 如果是灰度图片
if image_tensor.shape[0] == 1:
image_tensor = image_tensor.repeat(3, 1, 1)
image_tensor = image_tensor.view(-1, 3, 100, 100)
predict = model(image_tensor)
indices = torch.max(predict, 1)[1].item()
all_cate = []
for line in open("data/all_cate.txt", encoding="utf-8", mode="r"):
all_cate.append(line.strip())
cate_name = ""
try:
cate_name = all_cate[indices]
except ValueError:
cate_name = "未知"
print("识别结果是:", cate_name)
# imshow(torchvision.utils.make_grid(image_tensor))
# 原图显示
img_np.show()
exit()