机器学习初学-使用Keras波士顿房价boston_housing数据集使用sklearn Linear Regression线性回归算法建模
波士顿房价数据集包含一些特征字段和一个标签字段,用于预测波士顿地区房价的中位数。下面是波士顿房价数据集的特征字段和标签字段的描述:
特征字段:
1. CRIM:城镇人均犯罪率。
2. ZN:住宅用地超过 25,000 平方英尺的比例。
3. INDUS:城镇非零售商业用地比例。
4. CHAS:查尔斯河虚拟变量(如果边界是河流,则为 1;否则为 0)。
5. NOX:一氧化氮浓度(每千万份)。
6. RM:住宅平均房间数。
7. AGE:1940 年之前建成的自住单位比例。
8. DIS:到波士顿五个就业中心的加权距离。
9. RAD:径向高速公路的可达性指数。
10. TAX:每 10,000 美元的全值财产税率。
11. PTRATIO:城镇师生比例。
12. B:1000(Bk - 0.63)^2,其中 Bk 是城镇黑人的比例。
13. LSTAT:人口中地位较低人群的百分比。标签字段:
14. MEDV:自住房屋的中位数价值(以千美元计)。
在这个数据集中,特征字段用于描述房屋和地区的相关特征,而标签字段则表示房屋的中位数价值,即我们所要预测的目标变量。通过使用特征字段的值,我们可以建立一个线性回归模型来预测房屋的中位数价值。
step1
from keras.datasets import boston_housing # 导入波士顿房价数据集
from sklearn.linear_model import LinearRegression # 导入线性回归算法模型
import matplotlib.pyplot as plt # 导入Matplotlib库
# 导入数据集
(train_x, train_y), (test_x, test_y) = boston_housing.load_data()
# 导入波士顿房价数据集,并将数据集分为训练集和测试集
# boston_housing.load_data()函数用于加载波士顿房价数据集,返回一个元组,其中包含训练集和测试集数据。
# (train_x, train_y)表示训练集数据,(test_x, test_y)表示测试集数据。
# train_x: 训练集的输入特征,是一个二维数组,每一行表示一个训练样本,每一列表示一个特征。
# train_y: 训练集的标签,是一个一维数组,每个元素表示对应训练样本的标签值。
# test_x: 测试集的输入特征,格式与train_x相同。
# test_y: 测试集的标签,格式与train_y相同。
# 这一行代码将从boston_housing数据集中加载数据,并将数据分为训练集和测试集,分别存储在(train_x, train_y)和(test_x, test_y)中。
print('训练集样本案例:', train_x[0], '训练集标签:', train_y[0])
# 创建线性回归模型
model = LinearRegression()
# 拟合模型
model.fit(train_x, train_y)
# 预测测试集
pred_y = model.predict(test_x)
print('真实值:', test_y)
print('预测值:', pred_y)
加载波士顿房价数据集,创建了一个线性回归模型,并使用训练集对模型进行拟合,并用模型预测测试集。
训练集样本案例: [ 1.23247 0. 8.14 0. 0.538 6.142 91.7
3.9769 4. 307. 21. 396.9 18.72 ] 训练集标签: 15.2
真实值: [ 7.2 18.8 19. 27. 22.2 24.5 31.2 22.9 20.5 23.2 18.6 14.5 17.8 50.
20.8 24.3 24.2 19.8 19.1 22.7 12. 10.2 20. 18.5 20.9 23. 27.5 30.1
9.5 22. 21.2 14.1 33.1 23.4 20.1 7.4 15.4 23.8 20.1 24.5 33. 28.4
14.1 46.7 32.5 29.6 28.4 19.8 20.2 25. 35.4 20.3 9.7 14.5 34.9 26.6
7.2 50. 32.4 21.6 29.8 13.1 27.5 21.2 23.1 21.9 13. 23.2 8.1 5.6
21.7 29.6 19.6 7. 26.4 18.9 20.9 28.1 35.4 10.2 24.3 43.1 17.6 15.4
16.2 27.1 21.4 21.5 22.4 25. 16.6 18.6 22. 42.8 35.1 21.5 36. 21.9
24.1 50. 26.7 25. ]
预测值: [ 9.69267239 21.05859431 20.94145461 34.25223414 25.95902598 20.56741038
28.15310405 25.07113862 20.30519458 22.82489511 20.29027213 18.07938917
16.46141024 35.31166595 19.41369959 19.34727116 24.58140904 21.01346252
19.99079236 23.79286427 12.20780045 17.14218992 22.51468752 12.92570511
21.18070615 23.94073547 33.46176314 24.2631555 13.35213096 20.71939252
23.45082103 19.1486881 36.09743765 23.47113531 19.03141995 5.92425733
14.02090469 22.96425377 16.01731242 27.09134249 22.06997029 28.61755389
17.75679772 34.75579014 31.29455712 24.73234165 31.12655323 18.09268992
22.62638989 24.21208909 30.5854317 18.71860574 10.50163617 13.73779292
34.4022841 27.53140317 18.08151522 40.05101982 37.63271513 24.64021422
25.73823434 20.64369987 20.33514699 21.38393124 24.63485497 23.53071805
17.42141466 26.76911736 3.83782148 11.97063636 24.2602519 23.67191799
23.66639182 8.4403269 28.52690962 20.94071229 20.44489658 24.77678169
33.77299778 7.02038331 24.55379254 36.73923493 16.09878612 18.14663987
20.48899554 18.7928142 22.45683561 26.19154506 23.36585592 28.89583791
17.48243942 16.05642916 26.69532678 28.1393996 35.04164989 20.05308052
36.25269116 38.51475052 25.13506119 41.49062194 34.65500235 25.33950895]step2
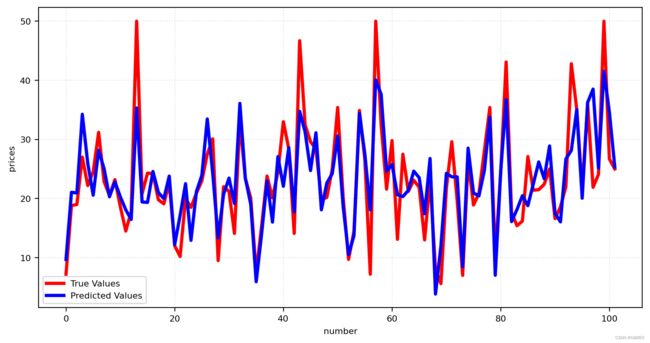
# 绘制真实值和预测值折线图
plt.figure(figsize=(10, 5), dpi=200)
plt.plot(range(len(test_y)), test_y, linestyle='-', linewidth=3, color='r', label='True Values')
plt.plot(range(len(pred_y)), pred_y, linestyle='-', linewidth=3, color='b', label='Predicted Values')
# 绘制网格
plt.grid(alpha=0.4, linestyle=':')
plt.legend()
plt.xlabel('number') # 设置x轴的标签文本
plt.ylabel('prices') # 设置y轴的标签文本
plt.show() # 显示房价分布和机器学习到的函数模型
绘制了真实值和预测值的折线图
step3
# 计算决定系数r2
score = model.score(test_x, test_y)
print("Coefficient of Determination (R²):", score)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error: ", mse)计算了模型的决定系数和均方误差
Coefficient of Determination (R²): 0.7213535934621551
Mean Squared Error: 23.19559925642298