如何使用Python爬取豆瓣电影Top250的数据,并将结果保存到Excel文件中.
一 . 安装所需的库
首先,请确保你已经安装了这些库。这里导入了requests库用于发送HTTP请求,BeautifulSoup库用于解析HTML内容,以及openpyxl库用于生成以及操作Excel文件。
-
import requests from bs4 import BeautifulSoup from openpyxl import Workbook from openpyxl.styles import Font如果还没有安装,查看下面教程安装它们:
安装方式: 打开命令行或终端,这里我使用的是PyCharm,在其左下角找到终端

(1).requests库:用于发送HTTP请求和获取网页内容。在终端页面终端,输入以下命令并按Enter执行:
pip install requests(2).beautifulsoup4库:用于解析HTML和XML文档。在终端页面终端,输入以下命令并按Enter执行:
pip install beautifulsoup4(3).openpyxl库:用于生成以及操作Excel文件。在终端页面终端,输入以下命令并按Enter执行:
pip install openpyxl(4).如何查看是否安装成功 二.解析网页内容,获取其中想要信息
二.解析网页内容,获取其中想要信息 -
分析豆瓣电影Top250网页
(https://movie.douban.com/top250),右键检查查看网页代码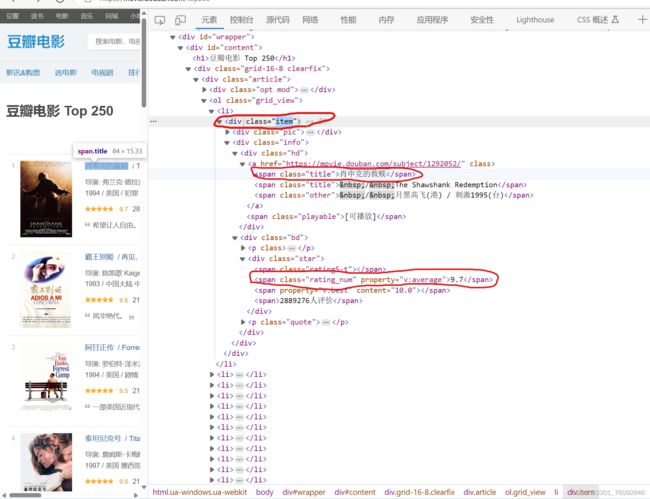
查看网页源码可以知道,每个
标签中包含一部电影的信息,然后使用for循环根据图中所圈的3个class类名('.item','.title','.rating_num')提取电影名称和评分.
-
接下来定义了两个主要的函数:
-
douban_top250():这个函数用于爬取豆瓣电影Top250的数据。它首先构建豆瓣电影Top250的URL,然后循环遍历不同页面,发送请求,解析页面内容,提取电影名称和评分,并将其保存在一个名为movies的列表中。 -
def douban_top250(): # 网页的URL地址 url = 'https://movie.douban.com/top250' # 设置请求头,模拟浏览器访问 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.79'} # 用于存储电影信息的列表 movies = [] # 使用循环爬取豆瓣电影Top250的每一页 for start_num in range(0, 250, 25): page_url = f'{url}?start={start_num}' response = requests.get(page_url, headers=headers) soup = BeautifulSoup(response.text, 'html.parser') # 解析网页内容,提取电影名称和评分,并添加到movies列表中 for movie in soup.select('.item'): title = movie.select_one('.title').text.strip() rating = movie.select_one('.rating_num').text.strip() movies.append((title, rating)) # 返回电影信息列表 return moviescreate_excel(movies):这个函数用于将爬取到的电影数据保存为Excel文件。它创建一个新的Excel文件,将电影名称和评分写入Excel表格,并设置标题的字体样式为红色并加粗。 -
def create_excel(movies): wb = Workbook() ws = wb.active title_font = Font(color='FF0000', bold=True) # 设置标题的字体颜色为红色并加粗 ws.append(['电影名称', '评分']) for cell in ws[1]: cell.font = title_font # 应用标题字体样式 for movie in movies: ws.append(movie) wb.save('豆瓣_top250.xlsx')上面讲解的是思路,最终代码如下
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook
from openpyxl.styles import Font
def douban_top250():
url = 'https://movie.douban.com/top250'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.79'}
movies = []
for start_num in range(0, 250, 25):
page_url = f'{url}?start={start_num}'
response = requests.get(page_url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
for movie in soup.select('.item'):
title = movie.select_one('.title').text.strip()
rating = movie.select_one('.rating_num').text.strip()
movies.append((title, rating))
return movies
def create_excel(movies):
wb = Workbook()
ws = wb.active
title_font = Font(color='FF0000', bold=True) # 设置标题的字体颜色为红色并加粗
ws.append(['电影名称', '评分'])
for cell in ws[1]:
cell.font = title_font # 应用标题字体样式
for movie in movies:
ws.append(movie)
wb.save('豆瓣_top250.xlsx')
if __name__ == '__main__':
movies = douban_top250()
create_excel(movies)
print('Excel文件已生成。')
-
最后,在程序中,首先调用
douban_top250()函数来获取豆瓣电影Top250的数据,然后将数据传递给create_excel(movies)函数,将数据保存为Excel文件。最后,程序会输出"Excel文件已生成。"的提示信息。 -
具体代码运行效果图如下
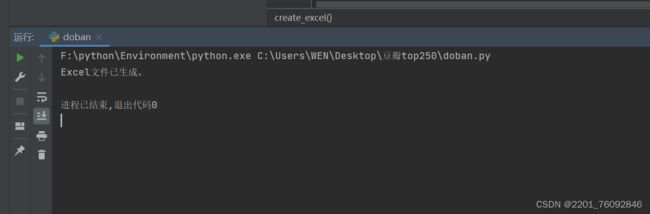
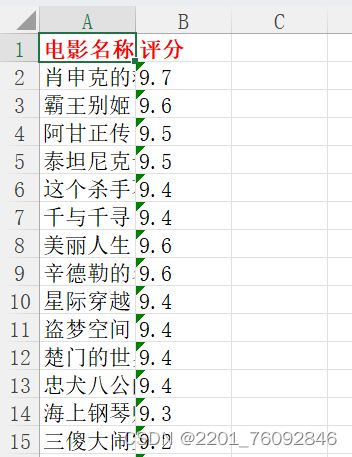 以上本期讲解的全部内容,欢迎大家的指正。
以上本期讲解的全部内容,欢迎大家的指正。
以下是代码文件源码有需要的可以自取:
链接:https://pan.baidu.com/s/1v25KETPAZeb1w70zO4UgIw
提取码:edf4