机器学习考试复习
文章目录
- 绪论
-
- 机器学习能干什么
- 机器学习的发展
- 神经网络发展有三次高峰
- 手写字符识别
- 国际象棋
- 总结
- 机器学习算法分类
-
- 学习路线
- Linear Regression
-
- 问题和模型
- 模型表示
- 损失函数
- 符号表示
- 优化损失函数
-
- 解析式求导
- 什么时候X^T * X不可逆
- 梯度下降法
- 关于梯度下降算法的一些细节
- 判断题
- 梯度下降法 v.s. 解析法
- 扩展线性回归法
-
- feature scaling
- mean normalization
- learning rate
- 多元线性回归
- 罗杰斯特回归
-
- 模型
- cost function
-
- 交叉熵
- 多分类
- 线性判别分析 (LDA)
- examples
- 神经网络
-
- 发展历程
- 神经元模型
- 万能近似定理
- 解决之前的逻辑运算
-
- 与
- 或
- 非
- 异或
- 多分类问题
- 总结
- 机器学习中的正则化
-
- 什么是过拟合
-
- 出现原因
- 损失函数中的正则项
- 增加正则项的线性回归
- 增加正则项的逻辑回归
- 总结
- 误差反向传递算法
- 深度神经网络
-
- 深度神经网络框架
-
- DBN 深度信念网络
- RNN 循环神经网络
- LSTM 长短期记忆 (RNN的一种)
- GANs 生成对抗网络
- CNN 卷积神经网络
- SVM
-
- 线性可分问题的最大化间隔问题
- 结构化风险
- 最小化
- 机器学习评估
-
- 机器学习预测结果的评估
-
- 准确率
- 查准率, 查全率
- F1 measure
- ROC
- sensitive cost
- 显著性差异检测
- 机器学习模型的评估
-
- 如何调试一个学习算法
- 经验风险, 期望风险, 结构风险
- cross validation (交叉验证)
- BP算法原理
- 过拟合, 正则项
- 异或 与 或 非 的神经元实现
- SVM
- 性能指标
绪论
机器学习能干什么
- 光学字符识别
- 语音识别
- 下棋
- 自动驾驶
- 垃圾邮件分类
- 商品推荐
- 人脸识别
机器学习的发展
让机械具备基本智能(木牛流马) -> 图灵测试(差分机, 解密码) -> 定理证明(四色定理, 第一个用人工智能, 逻辑推理的方法推出的人没有推出的定理) , 知识工程(人的智慧是因为有知识) -> 神经网络(从机器上模拟人的记忆)
神经网络发展有三次高峰
- 模拟一个神经元
- BP算法, 两层神经网络
- 深度神经网络 (多层)
手写字符识别
- 贝叶斯法则

国际象棋
- IBM DeepBlue ||, 1997
- 每秒检索 2 亿步棋
- 促进他们买机器, 买软件
- AlphaGo
总结
-
训练 : 从历史经验 (带专家标注) 中学习规律 (一个对应关系)
- 假设 : 历史经验, 和要预测的任务 都需要来源同一分布, 任务相关的, 长时间不变的. 对于一些变化因素多的不适合机器学习
-
预测 : 利用学习的规律预测新的样本结果 (提供x, 利用学习到的f, 预测y)
-
只能解决一些客观问题, 主观问题无能为力.
-
program by learning from experience
-
计算机程序发现数据中的规律, 并根据规律给出预测的一种智能技术.
机器学习算法分类
- 分类(classification) : 把事物按标准分成一些类别
- 垃圾邮件诊断
- 疾病诊断
- 是否发放信用卡
- 是否录用
- y=f(x) , y={-1, +1, 2, 3, 4}
- 回归(Regression) : 由过去, 现在的数据计算出未来的状态
- 预测身高
- 预测年龄
- 预测方形盘旋转角度
- y=f(x), y为连续值
- 聚类(clustering, 无监督学习) : 没有类别的标准, 按事物间的相似性划分成一些类别.
- 人以类聚, 物以群分
学习路线
- 线性回归
- 单变量线性回归
- 多变量线性回归
- 线性判别分析 (用回归的方法做分类)
- 罗杰斯特回归 (分类方法) (Logistic Regression) 和 正则化 (Regularization)
- 神经网络
- representation
- learning
- introduction to deep learning
- 支持向量机(support vector machine)
- Learning from network : PageRank and Graph Ranking
- Dimensionality Reduction & Concept Learning
- PCA (Principle Component Analysis) 主成分分析
- NMF (Non-Negative Matrix Factorization) 非负矩阵分解
- Clustering (Unsupervised Learning)
- Bayes Classification 贝叶斯分类
- Ensemble Learning : Boosting, Bagging and EM(期望最大化)
- Evaluation of Machine Learning 机器学习的评估
- Theory of Statistical Learning 统计学习理论
Linear Regression
问题和模型
- 通过一个线性模型根据输入的向量和值预测一个实数值
- 定价, 物质成分农浓度, 资信
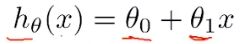
- 训练模型其实就是求theta0 和 theta1
- h : hypothesis
- 皮尔森相关系数越大, 线性相关程度越高
模型表示
损失函数
-
最小二乘法 (最小化误差的平方和寻找最佳的匹配参数)
- 解决方法由高斯提出, 模型是由高尔顿提出, 两个人不一样
-
关于模型参数(theta0, theta1/)的函数, 这里的x,y是已知值

-
把每一个theta0, theta1, 都用这个损失函数求一个值, 选择最小值, 用来选出最好的theta0, theta1
符号表示
- x : 一个数
- x : 向量
- X :多个向量 (m*n)
- m : 表示样本个数
- n : 表示特征
- x^(i) : 第i组 数据
优化损失函数
- 目标 : 使用带标注的数据挑选出最好的参数组合 (theta0, theta1)
- 方法 : 高斯的最小二乘法
- 解析式求导
- 梯度下降法
解析式求导
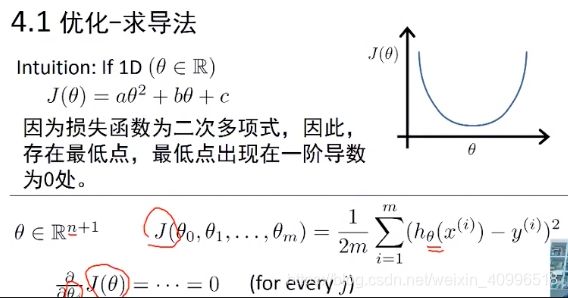
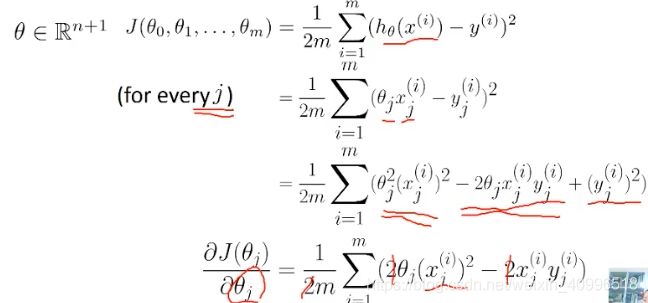

- X^T * X 需要可逆
- 矩阵满秩
- 伪逆 : pinv() ; 逆 : inv
- 如果用一次项 : 求导后theta消失
- 如果用三次方, 无法求最值, theta无穷小时最小, 但是此时模型并不是最优的
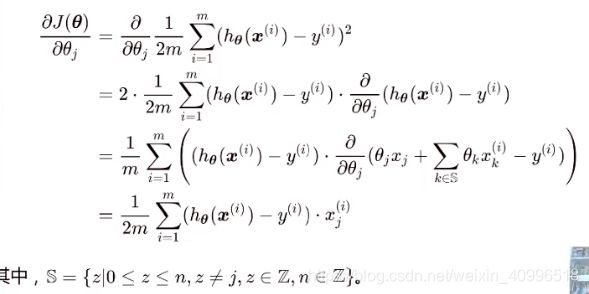

- i表示行, k表示列
- 向量都是列向量

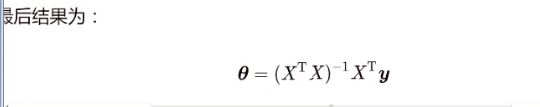
什么时候X^T * X不可逆
- 冗余性质
- 样本特征 >> 样本个数

梯度下降法
- 解析式法的缺点
- 矩阵不可逆
- 损失函数不一定可以求导
- 损失函数导数有多个零点, 多个级值
- 梯度下降法
- 梯度的方向是函数增长最快的方向
- 梯度的反方向就是函数减少最快的方向
- 计算一个函数的最小值, 就可以从一个初始点, 向着当前位置梯度反方向移动

- 所有的theta计算完后, 统一更新.(simultaneously 同时)
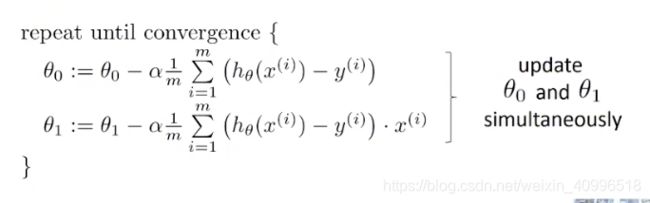
关于梯度下降算法的一些细节
- 梯度有正有负, 负梯度一直向着最小值去有些不解
- 是损失函数的值一直向着最小值去
- 而theta参数值, 负梯度增大, 正梯度减小
- 怎么将梯度法 扩展到多个变量上
- 控制变量, 一会只变一个theta
- theta之间相互独立, 就可以单独求导
- 初始值对算法的影响
- 影响看损失函数, 对于线性回归, 初始值影响不大, 只是得到最优解的速度快慢而已
- 如果对于多峰多谷的损失函数, 初始值会有影响.
- 多设几个初始值, 然后选择损失函数最小的那个
- 在谷底的时候, 可以跨一大步, 跳出谷底, 然后在慢慢减少
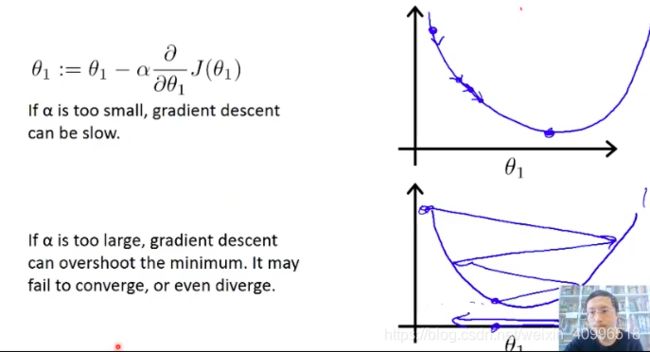
- 步长对学习速率的影响
- 如果太小, 收敛速度太慢
- 如果太大, 无法收敛, theta一会儿大一会儿小
- 初期步长大, 之后慢慢缩小
- 收敛或者达到最大迭代次数
- 要么收敛到最小值
- 如果无法收敛到最小值, 达到一定的迭代次数也可以停止.

判断题
- 解析式求导法一定比梯度下降法快 (X)
- 求逆非常耗费时间
- 使用解析法求线性回归最优参数时, 样本矩阵X^T * X一定是可逆的 (X)
- 使用梯度下降法优化损失函数, 步长越大收敛越快 (X)
梯度下降法 v.s. 解析法

- 各个纬度需要相互独立, 才能独立求导

扩展线性回归法
feature scaling
- 将每个特征的数值尺度化为同等数量级

mean normalization
- 减均值 / 标准差
- 减最小值 / (最大值- 最小值)

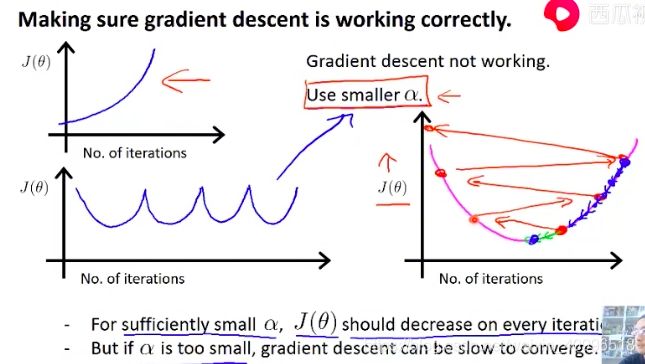
learning rate
- 损失函数和迭代次数的图


多元线性回归

- 在线性的基础上, 重新构造参数, 增加多次, 拟合各种曲线, 用来描述更复杂的情况
罗杰斯特回归
-
虽然叫回归, 其实是一个分类方法. 统计模型向预测方向发展
- 垃圾邮件检测
- 恶性肿瘤检测
-
+1 是我们关注的(恶性肿瘤), -1是不关注的(良性肿瘤)
-
设置阈值
- 虽然所有数据都能够被判别, 但是阈值附近的值判别存在较大的误差风险
-
设置拒绝域 (“三类分类”)
- 在拒绝域之内的值不予判别
- 提高了准确率, 但是有一部分没法判别

模型
- 线性回归模型的输出是和输入有一定关系的, 要想利用线性回归模型做分类,就需要把所有输出映射到[0,1范围内, 因此增加一个激励函数(sigmoid函数), 对原来的输出在做一次映射
- 这个激励函数还需要方便求导
- 阶跃函数(大于0.5的变为1, 小于0.5的变为0)虽 然也可以映射输出, 但是不方便求导.
- arctan函数也可以, 但是也不方便求导

- 最后的输出还可以作为概率显示

- 非线性决策边界

cost function
- 判别的时候只需要theta^T * X
- 下面连个函数关于 x = 0.5 对称

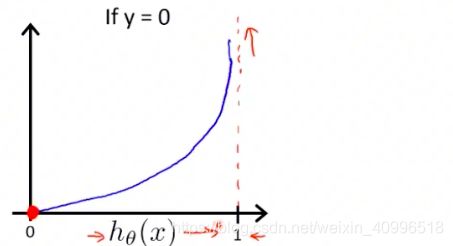


-罗杰斯特回归给出的损失函数 其实就是交叉熵
交叉熵





- 共轭梯度下降法
- 随机梯下降法
多分类
- 对n类问题, 做n个单独针对某一类的二类分类器, 属于该类 和 不属于该类
线性判别分析 (LDA)
- Fisher 1936年提出, 用来线性分类, 降纬
- 核心思想 : 使用超平面切分两类样本, 使得样两类样本类内距最小, 类间距最大
- 使用最内间距 / 类内距,求最大值.
- 类间散度矩阵
- 类内散度矩阵
- 拉格朗日函数

- 正态分布, 方差小, 越凸起. 均值大, 越向右.
examples
- logistic回归是一种监督式机器学习算法 ( 对 )
- logistic回归属于分类算法, 只能做二值分类, 不能直接做多值分类 (对)(需要多个logistic回归, 多个二值分类)
- logistic回归使用sigmoid函数将输出概率限定在[0,1]之间 (X) ((0,1) 端点取不到)
- logistic回归利用梯度下降算法进行优化时无法得到全局最优解, 因此应采用更高级的共轭梯度, 局部优化 (X) (不是无法, 是不一定, 大多数时候还是可以得到的, 这些梯度下降法没有高级不高级, 只有适合不适合, 都各有应用场景)
神经网络
发展历程
- 使用神经元进行逻辑运算
- 感知器模型, 可以分类, 布尔运算->逻辑回归
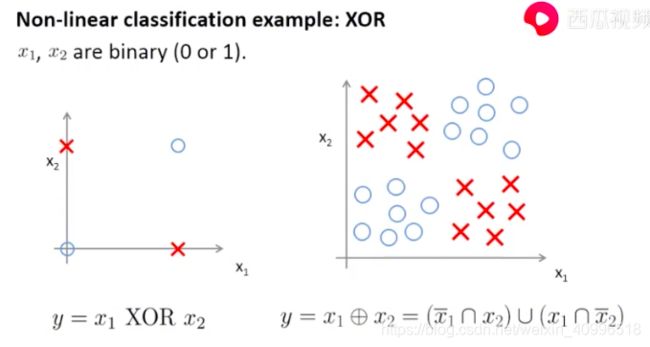
- 异或(XOR)问题的出现, 无法解决非线性问题, 神经网络发展出现寒冬.
- 训练多层神网络 ---- 反向误差传递算法
- 统计机器学习, SVM
- 深度神经网络
神经元模型
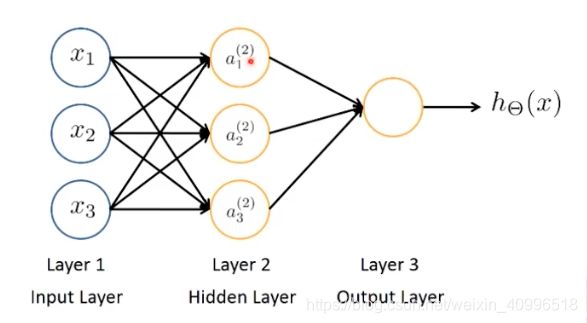

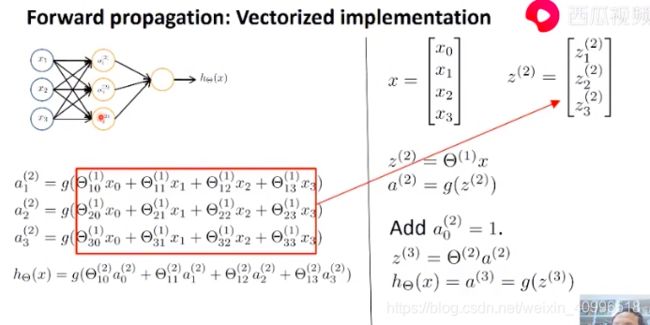
- 上标表示层号
- 下标表示第几行第几个
万能近似定理
- 一个前馈神经网络如果具有线性输出层和至少一层具有任何一种“挤压”性质的激活函数的隐藏层, 只要给予网络足够数量的隐藏单元, 他可以以任意精度来近似任何从一个优先维空间到另一个有限维空间的Borel可测函数.
- 只需一个包含足够多神经的隐层, 多层前馈神经网络就能以任意精度逼近任意复杂度的连续函数. 然而, 如何设置隐层神经元的个数仍是个位置问题, “试错法”进行调整.
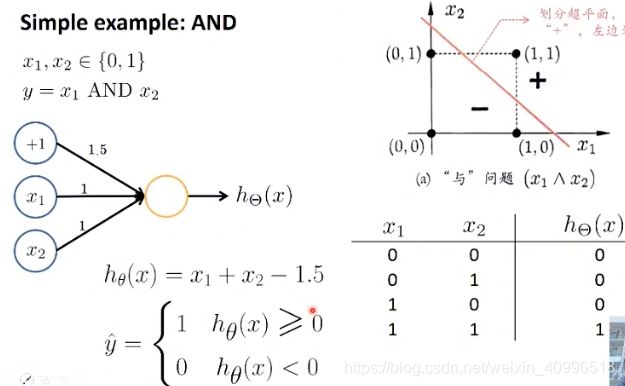
解决之前的逻辑运算
与
或
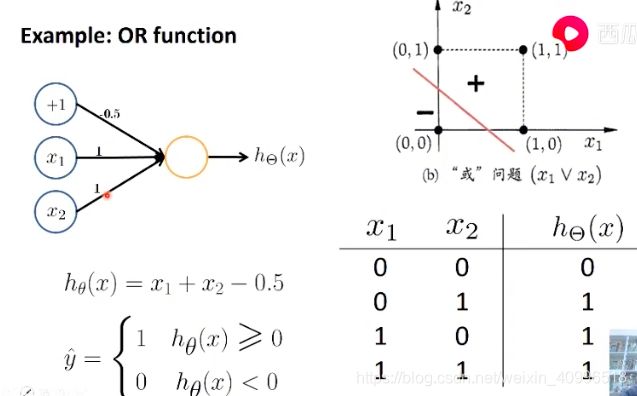
非

异或
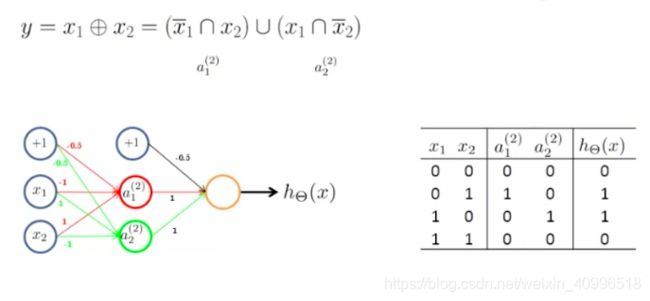
多分类问题
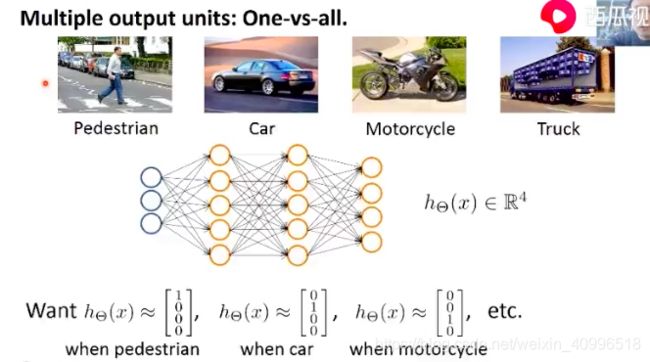
总结
- 计算机的神经网络是从模仿神经元开始的, 但是经过多年发展, 已经归于统计学习理论, 与生物上的脑科学没有太大关联
- 使用神经元模型实现逻辑运算
- 使用多层神经元实现异或运算
- 使用多层感知机模型实现非线性分类
机器学习中的正则化
什么是过拟合
- 在给定的训练数据集上拟合的非常好, 因为训练模型过于复杂,但是预测效果不好.
出现原因
- 描述一个对象使用的特征过于多
- 减少特征数量, 只选择影响较大的
- 通过训练学习, 让影响较小的特征前的系数变小.
损失函数中的正则项
增加正则项的线性回归

- theta0 不参与惩罚项

增加正则项的逻辑回归
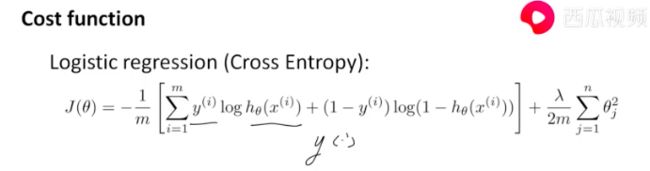
总结

误差反向传递算法
-
BackPropagation Algorithm (BP算法)
- 用于多层前馈网络的训练
-
价值 : 最终层的误差如何分解到每个节点的输出上
- 将误差分解到各个节点的输出上, 才能够通过梯度调整各节点的输入权重.
-
a^(4) 是前馈网络的最终输出, 损失函数是他的交叉熵, 所以可以对其求导






深度神经网络
-
机器学习的一个分支, 基于一系列算法旨在提高模型抽象数据的程度, 解决了传统BP算法的梯度消失问题.
-
BP算法的缺陷
- 隐藏层过多, 会导致梯度消失问题 (误差传递到最后输入层, 会导致权重下降甚至消失)
- 计算力的不足限制了隐藏层节点的个数
-
李飞飞教授推动了机器学习发展
深度神经网络框架
DBN 深度信念网络
- 生成模型
- 由多个 限制玻尔兹曼机 层构成
RNN 循环神经网络
- 结合上下文分析语义
- 机器翻译, 语音识别
- 可以记住前面的信息用来计算当前输出
LSTM 长短期记忆 (RNN的一种)
- 适合于处理和预测时间序列中间隔和延迟非常长的重要事件
GANs 生成对抗网络
- 非监督式学习
- 一个生成网络, 一个判别网络, 互相博弈, 共同进化.
CNN 卷积神经网络
-
用类似视觉的方式保留了图像的特征,当图像做翻转,旋转或者变换位置时,它也能有效的识别出来是类似的图像
-
激活函数
- Softmax layer
-
三部分构成
- 卷积层 : 提取图像特征
- 池化层 : 降维, 防止过拟合
- 全连接层 : 输出结果
-
应用
- 图像分类, 检索
- 面部识别
- 目标定位检测
- 目标分割
-
AlexNet
- 5层卷积层, 3层全连接层, 非饱和的ReLU函数
- 避免过拟合 : Dropout, Data Augmentation (数据增强)
-
LeNet
- 3层卷积层, 2层池化层, 1层全连接层, 1个输出层
SVM
- 90年代后期, 10年前后深度学习兴起之前, SVM被认为是机器学习当时最成功, 表现最好的方法.
- 机器学习第二次衰落(算力不足)被SVM唤起
线性可分问题的最大化间隔问题
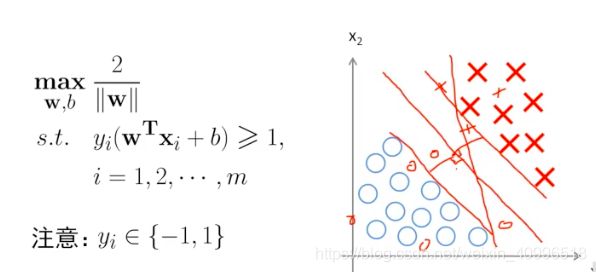
- 度量模型输出和实际标注差异的办法
- 最小二乘法 (Linear Regression)
- 交叉熵 (Logistic)
- 同号, 不同号的方法 (SVM)

结构化风险
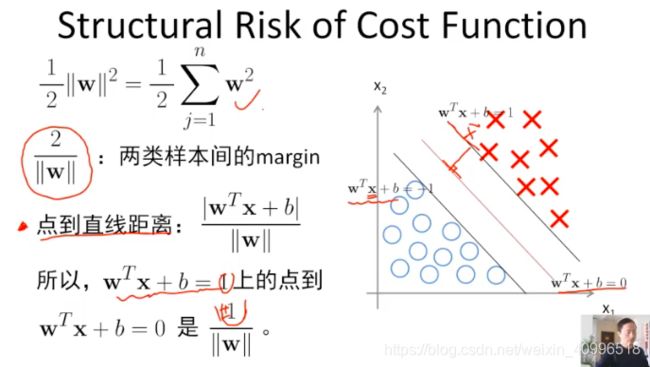
最小化

机器学习评估
-
定义: a computer program learning from experience E, with respect to some class of tasks T and performance measure p.
-
learning algorithm : 求导, 梯度 (offline training)
-
online prediction : 预测过程
-
当新的输入不是虚年数据集中的, 但是是独立同分布的, 预测的输出应该不离谱. 要有举一反三的能力
-
量化评估是工程的基石
-
机器学习是体现自身优化最直观的技术
机器学习预测结果的评估
准确率
- ACC

查准率, 查全率
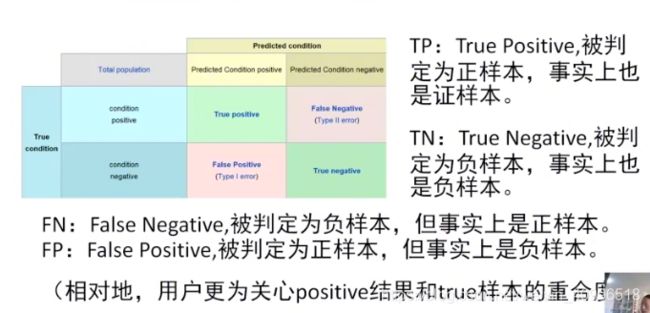

- 查准率(Precision) 可以通过增加拒绝来提升 (减少FP)
- 不轻易判断, 只要判断就对的
- 查全率(Recall) 可以通过降低拒绝来提升 (减少FN)
- 错杀1000, 不放过1个
- Precision 和 Recall相互矛盾
- 使用阈值(threshold)决定判别, 如LR, NN
- 想将所有感兴趣的样本都找出来, 需要降低阈值, 扩大接受范围
- 想提高识别感兴趣的样本的查准率, 需要提高阈值,提高拒绝率.
- 好的方法应该尽量保住对比方法的P-R曲线
- 平衡点(break-event point) “查准率 = 查全率”时的取之, 可以用来作为衡量分类器性能的指标之一.
F1 measure
- precision 和 recall的调和平均, 最差为0, 最好为1

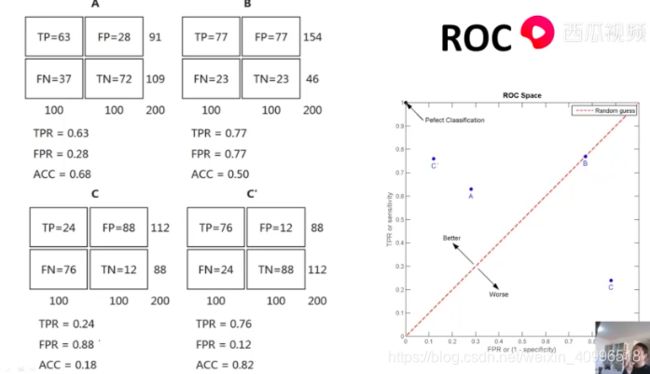
ROC
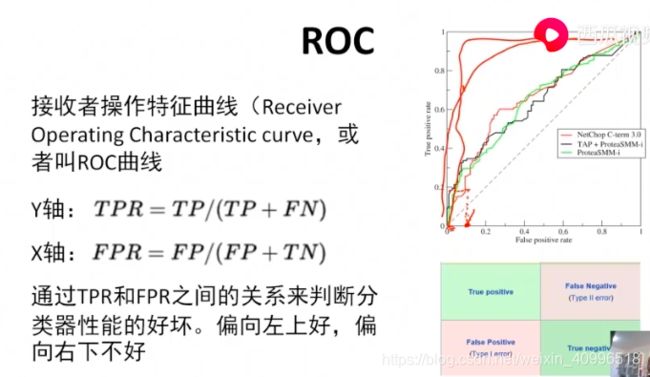

- AUC (AUROC) 还有 AUPR (PR曲线的面积)

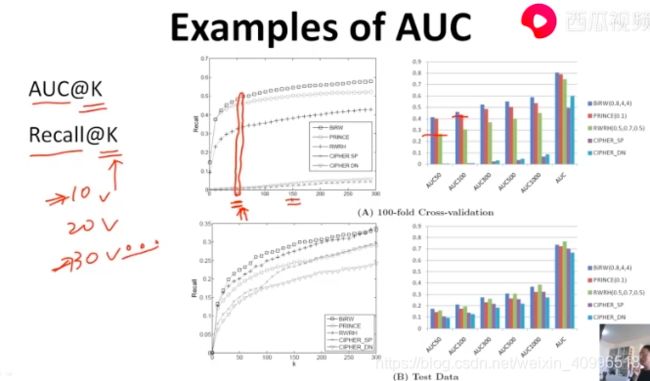
- 前10个表现好 比 前30个表现好更重要.
sensitive cost
- 调整不同类型错误的惩罚程度


显著性差异检测
机器学习模型的评估
如何调试一个学习算法

- 获得更多的训练数据 (范围更广, 普遍性更强)
- 尝试小规模特性
- 尝试获得更多的额外特性
- 尝试增加多项式特征
- 尝试减小lambda
- 尝试增大lambda
经验风险, 期望风险, 结构风险
-
经验风险是对训练集中的所有样本点损失函数的平均最小化。经验风险越小说明模型f(X)对训练集的拟合程度越好
-
期望风险表示的是全局的概念,表示的是决策函数对所有的样本(已知的和未知的)
-
经验风险是局部的,基于训练集所有样本点损失函数最小化的。
-
期望风险是全局的,是基于所有样本点的损失函数最小化的。
-
经验风险函数是现实的,可求的;
-
期望风险函数是理想化的,不可求的;
-
在经验风险函数后面加一个正则化项(惩罚项)便是结构风险了.
-
经验风险越小,模型决策函数越复杂,其包含的参数越多,当经验风险函数小到一定程度就出现了过拟合现象。也可以理解为模型决策函数的复杂程度是过拟合的必要条件,那么我们要想防止过拟合现象的方式,就要破坏这个必要条件,即降低决策函数的复杂度。也即,让惩罚项J(f)最小化,现在出现两个需要最小化的函数了。我们需要同时保证经验风险函数和模型决策函数的复杂度都达到最小化,一个简单的办法把两个式子融合成一个式子得到结构风险函数然后对这个结构风险函数进行最小化。
cross validation (交叉验证)

- LOOCV : 是把n = m