pytorch中分布式Collective通信API学习
随着各种大模型的不断迭出,感觉现在的NLP领域已经来到了大模型的时代。那么怎么来训练一个大模型呢?其中比较关键的一个技术基础就是分布式训练。在阅读GLM源码的时候,感觉其中的分布式训练代码不是很熟悉,看起来有点吃力,为此专门对pytorch中分布训练环境的搭建和通信API进行了学习,这个对大模型训练中利用不同显卡上的梯度和数据进行训练的理解有着促进作用。
pytorch对不同的后端,有不同的支持,下面来看一张基于1.8版本的torch对后端支持的情况:
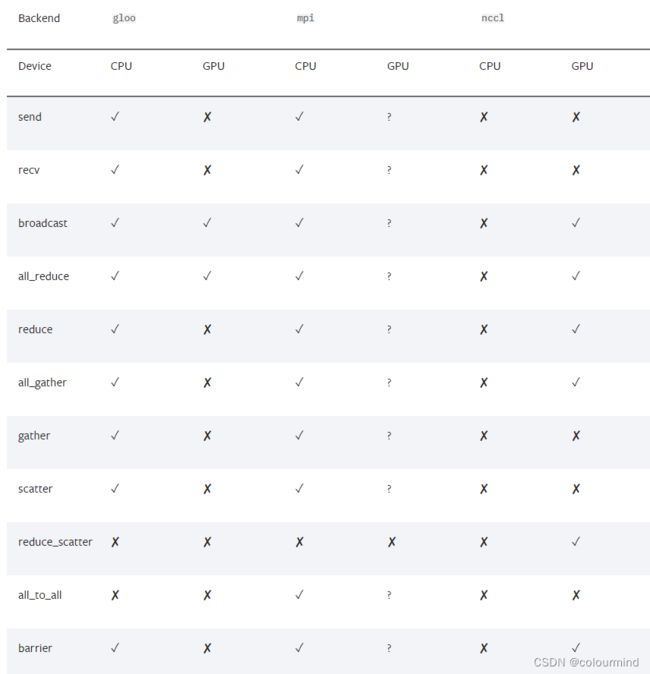
可以看到1.8版本下,pytorch对一些操作是不支持的。由于我们训练的时候大多采用N卡,所以这里就只是对NCCL后端下的API进行学习和理解。
分布式环境初始化
既然是分布式,肯定是多进程的,每一个进程占用一张卡进行计算和推理。同时也要进行进程之间的通信连接和建立,torch自带的multiprocessing和distributed能很好的实现上述功能。初始化流程:首先开启多进程,为每一个进程指定一个后端,得到group;同时设定环境中的主机地址和端口;最后在每个进程实现不同的业务功能。详细代码如下:
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def init_dist_process(rank, world_size, test_fun, backend='nccl'):
"""
初始化分布式环境,指定主机地址和端口号
:param rank:
:param world_size:
:param test_fun:
:param backend:
:return:
"""
os.environ["MASTER_ADDR"] = '127.0.0.1'
os.environ["MASTER_PORT"] = '2222'
# 初始化分布式进程,指定backend和rank world_size
dist.init_process_group(backend=backend,rank=rank,world_size=world_size)
#要执行的功能
test_fun(rank,world_size)
def create_processes_run(world_size,test_fun):
"""
创建进程给到每一张显卡
:param world_size:
:param test_fun:
:return:
"""
processes = []
for rank in range(world_size):
p = mp.Process(target = init_dist_process,args=(rank,world_size,test_fun))
p.start()
processes.append(p)
for p in processes:
p.join()
if __name__ == '__main__':
mp.set_start_method("spawn")
create_processes_run(world_size=2,test_fun=...)注意torch多进程启动方式最好采用spawn,然后create_processes_run开启多进程同时初始化分布式环境,然后执行业务功能。下面的各种API测试都是采用如上的流程进行。
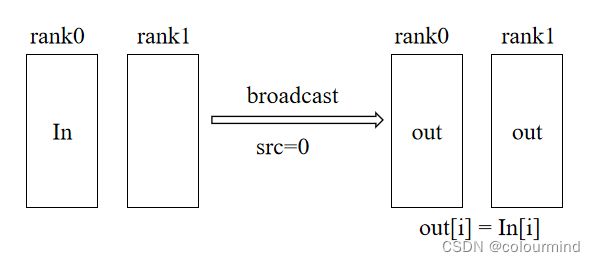
1、broadcast
如下图所示,src=0上的tensor经过broadcast后,在group中的所有显卡都能接收到该tensor,因此
out[i] = In[i],每个显卡上的数据都相同。
代码如下:
def broadcast_test(rank, world_size):
"""
broadcast测试,把数据从src卡广播到其他所有组内的卡
:param rank:
:param world_size:
:return:
"""
group = dist.new_group(list(range(world_size)))
data = [rank+1] * 5
device = torch.device("cuda",rank)
tensor = torch.tensor(data,dtype=torch.long).to(device)
print('before broadcast Rank:', rank, '-----data:', tensor)
# 0卡上的数据广播到其他显卡上
dist.broadcast(tensor=tensor, src=0, group=group)
print('after broadcast Rank:', rank, '-----data:', tensor)把0卡上的数据广播上1卡上,结果如下:
before broadcast Rank: 1 -----data: tensor([2, 2, 2, 2, 2], device='cuda:1')
before broadcast Rank: 0 -----data: tensor([1, 1, 1, 1, 1], device='cuda:0')
after broadcast Rank: 0 -----data: tensor([1, 1, 1, 1, 1], device='cuda:0')
after broadcast Rank: 1 -----data: tensor([1, 1, 1, 1, 1], device='cuda:1')
可以看到执行广播后,0卡上的数据被广播到1上了,0卡和1卡的数据都是一样的了。
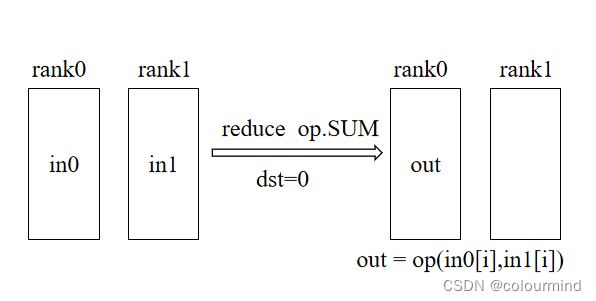
2、reduce
会把当前所有显卡的tensor按照指定的操作后,发送到dst显卡上。如下图所示:
代码如下:
def reduce_test(rank,world_size):
"""
reduce测试,归约操作,把所有卡上的数据都归约到dst卡上进行相应的dist.ReduceOp操作
:param rank:
:param world_size:
:return:
"""
group = dist.new_group(list(range(world_size)))
data = [rank+1] * 5
device = torch.device("cuda", rank)
tensor = torch.tensor(data, dtype=torch.long).to(device)
print('before reduce Rank:', rank, '-----data:', tensor)
#所有的rank都发送数据,dst=0卡接收, op是dist.ReduceOp.SUM
dist.reduce(tensor=tensor,dst=0,op=dist.ReduceOp.SUM,group=group)
print('after reduce Rank:', rank, '-----data:', tensor)把所有卡上的数据归约到1卡上,归约操作采用sum,结果如下:
before reduce Rank: 1 -----data: tensor([2, 2, 2, 2, 2], device='cuda:1')
before reduce Rank: 0 -----data: tensor([1, 1, 1, 1, 1], device='cuda:0')
after reduce Rank: 1 -----data: tensor([2, 2, 2, 2, 2], device='cuda:1')
after reduce Rank: 0 -----data: tensor([3, 3, 3, 3, 3], device='cuda:0')
可以看到reduce之后0卡上的数据是reduce之前0卡和1卡的数据之和
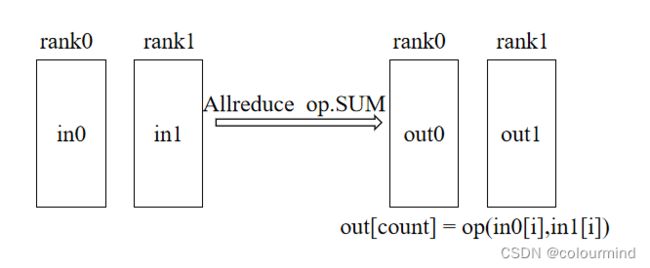
3、all_reduce
和reduce的操作一样,只不过是把reduce.op后的数据发送到group内所有的显卡上,如下图所示:
def allreduce_test(rank,world_size):
"""
allreduce测试,归约操作,把所有卡上的数据都归约到所有的卡上进行dist.ReduceOp操作
:param rank:
:param world_size:
:return:
"""
group = dist.new_group(list(range(world_size)))
data = [[rank+1] * 5]*5
device = torch.device("cuda", rank)
tensor = torch.tensor(data, dtype=torch.long).to(device)
print('before all_reduce Rank:', rank, '-----data:', tensor)
dist.all_reduce(tensor=tensor,op=dist.ReduceOp.SUM,group=group)
print('after all_reduce Rank:', rank, '-----data:', tensor)把所有卡上的数据归约到所有的卡上,结果如下:
before all_reduce Rank: 1 -----data: tensor([[2, 2, 2, 2, 2],
[2, 2, 2, 2, 2],
[2, 2, 2, 2, 2],
[2, 2, 2, 2, 2],
[2, 2, 2, 2, 2]], device='cuda:1')
before all_reduce Rank: 0 -----data: tensor([[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]], device='cuda:0')
after all_reduce Rank: 0 -----data: tensor([[3, 3, 3, 3, 3],
[3, 3, 3, 3, 3],
[3, 3, 3, 3, 3],
[3, 3, 3, 3, 3],
[3, 3, 3, 3, 3]], device='cuda:0')
after all_reduce Rank: 1 -----data: tensor([[3, 3, 3, 3, 3],
[3, 3, 3, 3, 3],
[3, 3, 3, 3, 3],
[3, 3, 3, 3, 3],
[3, 3, 3, 3, 3]], device='cuda:1')
执行all_reduce之后0卡和1卡的数据都是all_reduce之前所有卡的数据之和
4、all_gather
allgather把所有的显卡上的数据收集后,组成一个list发送到所有的显卡上,如下图所示
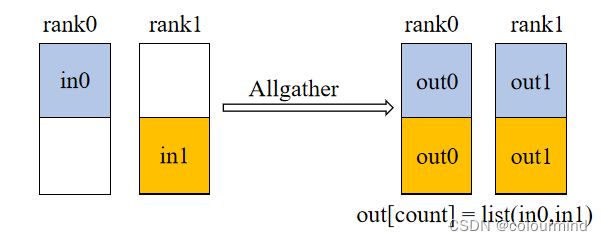
0卡和1卡上的数据(不同的颜色)经过allgather后组成一个新的list,发送到所有的显卡上。
代码如下:
def allgather_test(rank,world_size):
"""
allgather测试,聚合操作,把所有卡上的数据都聚合到一起形成一个list到所有卡上
:param rank:
:param world_size:
:return:
"""
group = dist.new_group(list(range(world_size)))
data = [rank+1] * 5
device = torch.device("cuda", rank)
tensor = torch.tensor(data, dtype=torch.long).to(device)
print('before all_gather Rank:', rank, '-----tensor:', tensor)
tensor_list = [ torch.zeros_like(tensor).to(tensor.device) for _ in range(world_size)]
print('before all_gather Rank:', rank, '-----tensor_list:', tensor_list)
dist.all_gather(tensor=tensor,group=group,tensor_list=tensor_list)
dist.barrier()
print('after all_gather Rank:', rank, '-----tensor_list:', tensor_list)
tensor_list = torch.stack(tensor_list)
print('tensor_list shape', tensor_list.shape)
print('after all_gather Rank:', rank, '-----tensor_list:', tensor_list)0卡和1卡上分别是tensor([1, 1, 1, 1, 1], device='cuda:0')和tensor([2, 2, 2, 2, 2], device='cuda:1'),执行allgather后,结果如下
before all_gather Rank: 0 -----tensor: tensor([1, 1, 1, 1, 1], device='cuda:0')
before all_gather Rank: 0 -----tensor_list: [tensor([0, 0, 0, 0, 0], device='cuda:0'), tensor([0, 0, 0, 0, 0], device='cuda:0')]
before all_gather Rank: 1 -----tensor: tensor([2, 2, 2, 2, 2], device='cuda:1')
before all_gather Rank: 1 -----tensor_list: [tensor([0, 0, 0, 0, 0], device='cuda:1'), tensor([0, 0, 0, 0, 0], device='cuda:1')]
after all_gather Rank: 0 -----tensor_list: [tensor([1, 1, 1, 1, 1], device='cuda:0'), tensor([2, 2, 2, 2, 2], device='cuda:0')]
after all_gather Rank: 1 -----tensor_list: [tensor([1, 1, 1, 1, 1], device='cuda:1'), tensor([2, 2, 2, 2, 2], device='cuda:1')]
tensor_list shape torch.Size([2, 5])
tensor_list shape torch.Size([2, 5])
after all_gather Rank: 0 -----tensor_list: tensor([[1, 1, 1, 1, 1],
[2, 2, 2, 2, 2]], device='cuda:0')
after all_gather Rank: 1 -----tensor_list: tensor([[1, 1, 1, 1, 1],
[2, 2, 2, 2, 2]], device='cuda:1'
0卡和1卡上均能得到之前0卡和1卡的tensor,并组成一个list。
5、reduce_scatter
reduce_scatter 这是一个归并再切分的操作,如下图所示,out0对应的数据就是所有显卡上第0部分的数据经过op.SUM操作后的数据。
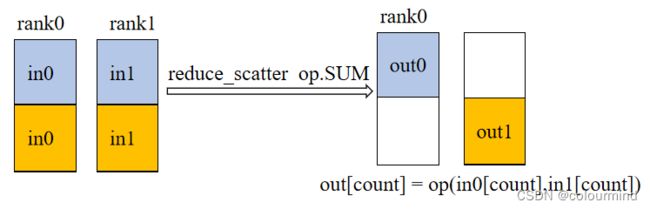
代码如下:
def reduce_scatter(rank, world_size):
"""
scatter_list 一定要是float型的
:param rank:
:param world_size:
:return:
"""
group = dist.new_group(list(range(world_size)))
device = torch.device("cuda", rank)
if rank == 0:
scatter_list = [torch.tensor([1,2,3],dtype=torch.float).to(device),torch.tensor([4,5,6], dtype=torch.float).to(device)]
else:
scatter_list = [torch.tensor([7,8,9], dtype=torch.float).to(device),torch.tensor([10,11,12], dtype=torch.float).to(device)]
print('before reduce_scatter Rank:', rank, '-----scatter_list:', scatter_list)
output = torch.zeros(1,3).to(device)
print('before reduce_scatter Rank:', rank, '-----output:', output)
dist.reduce_scatter(output=output,input_list=scatter_list,group=group,op=dist.ReduceOp.SUM)
print('after reduce_scatter Rank:', rank, '-----output:', output)0卡和1卡在reduce_scatter之前的数据有个list,执行reduce_scatter之后,结果如下:
before reduce_scatter Rank: 0 -----scatter_list: [tensor([1., 2., 3.], device='cuda:0'), tensor([4., 5., 6.], device='cuda:0')]
before reduce_scatter Rank: 1 -----scatter_list: [tensor([7., 8., 9.], device='cuda:1'), tensor([10., 11., 12.], device='cuda:1')]
before reduce_scatter Rank: 0 -----output: tensor([[0., 0., 0.]], device='cuda:0')
before reduce_scatter Rank: 1 -----output: tensor([[0., 0., 0.]], device='cuda:1')
after reduce_scatter Rank: 0 -----output: tensor([[ 8., 10., 12.]], device='cuda:0')
after reduce_scatter Rank: 1 -----output: tensor([[14., 16., 18.]], device='cuda:1')
把0卡和1卡对应index中的tensor相加起来然后发送到index号显卡上。
参考文章
【深度学习】【分布式训练】Collective通信操作及Pytorch示例
pytorch官方文档