Java入门(六)MySql 数据库
目录
-
- 一、数据库简介、SQL基本操作
- 二、SQL分类、DML、DDL、数据库数据类型、查询、没有条件检查的查询语句、忘记数据库的密码怎么办
- 三、别名、去重、WHERE、AND和OR、LIKE、ORDER BY、LIMIT分页、常用函数、聚合函数
- 四、分组查询、HAVING子句、子查询、关联查询、笛卡尔积、等值连接/内连接、左外连接、右外连接
- 五、自连接、自关联查询、多对一关联、多对多关联、权限管理
- 六、视图、索引、约束、事务
:哈喽~☀️欢迎加入程序大家庭,快点开始✒️自己的黑客帝国吧 ~
内容简述:数据库简介、SQL基本操作、SQL分类、DML、DDL、DQL、筛选、排序、分组、聚合、关联、笛卡儿积、表之间的对应关系、权限管理、视图、索引、约束、事务。
一、数据库简介、SQL基本操作
1.数据库简介
-
之前使用的流操作把数据存储到txt文档上,对于修改/插入等,首先代码繁琐,对于查询操作效率极。
另外,如果数据很大,不可能长期保存在文件中。 为了解决上述问题,我们需要使用数据库。
-
DB:文件仓库
-
DBMS:数据库的管理软件
-
数据库的分类
-
关系型数据库
- 用"表"保存数据,相关数据存入一张表中
-
非关系数据库
- 键值数据库
- 对象数据库
-
-
2.主流关系型数据库
-
Oracle 甲骨文 拉里.艾力森 收费 核 闭源 卖产品
-
DB2 IBM,应用于大型系统,UNIX/linux,是Oracle的主要竞争对手
-
SQL Server 微软 只能在windows下运行 .net(C#)
-
Mysql 免费 开源 卖服务
2008被sun收购,除了5.1版本;
2010年sun超过2000亿,被Oracle74亿收购;
Mysql牛X程序员,要求Mysql不能闭源,Oracle口头答应,没签合同;
mysql除了5.5版本,使用了Oracle的核心技术,性能提升了15%-30%;
mysql威胁到了Oracle市场,导致5.5版本闭源收费;
Mysql牛X程序员,mariadb;
mysql免费开源社区,支持mariadb;mysql5.5 mariadb5.5 mysql5.6 mariadb10.0
3.SQL基本操作
- SQL语言是操作数据库的语言 每一种数据都有自己独特的方言;
- linux 打开终端 输入 mysql -u root -p回车 password:(有密码就输入密码回车,没密码就直接回车);
-
操作数据库
-
对数据库的操作
-
1.显示所有的数据
- SHOW databases;
-
2.选定要操作的数据库
- USE 库名;
-
3.创建新的数据库
- CREATE database 库名;
-
4.查看创建数据库的语句
- SHOW CREATE database 库名;
-
5.设置默认解码的创建库语句
- CREATE database demo default CHARacter SET UTF8;
-
6.删除数据库
- DROP database 库名; DROP database demo;
-
7.显示所有表
- SHOW tables;
-
8.查询表结构
- desc 表名;
-
-
创建表
-
CREATE TABLE 表名( 列名 数据类型(长度) 约束, 列名 数据类型(长度) 约束, … 列名 数据类型(长度) 约束 );
CREATE TABLE stu( id INT NOT NULL, name VARCHAR(10), sex VARCHAR(10) );
-
-
查看表结构
- desc 表名;
输出CREATE TABLE stu ( id INT(11) NOT NULL, name VARCHAR(10) DEFAULT NULL, sex VARCHAR(10) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=UTF8;mysql的引擎(ENGINE)有两种:
-
InnoDB
- 支持数据库高级功能
- 事务(不能中断,若中断则回滚)
- 外键(连接两个表)
- 支持数据库高级功能
-
myisam
- 数据存储基本功能
- 效率非常高
课堂练习:
CREATE TABLE user(
name VARCHAR(16),
age INT
)ENGINE=innodb CHARSET=gbk;
对已经创建好的表进行修改(语句中表名前都需要加table)
-
修改表名
- RENAME TABLE 旧表名 TO 新表名;
RENAME TABLE user TO tb_user; -
修改表属性(引擎,字符编码)
- ALTER TABLE 表名 ENGINE=myisam CHARSET=UTF8;
ALTER TABLE tb_user ENGINE=myisam CHARSET=UTF8; -
添加字段
-
ALTER TABLE 表名 ADD 新字段 新字段的数据类型 新字段的约束 first;
-
ALTER TABLE tb_user ADD id INT first;
-
ALTER TABLE tb_user ADD( gender CHAR(5), tel CHAR(11) );
-
-
修改字段名称
- ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新字段数据类型;
ALTER TABLE tb_user CHANGE gender sex VARCHAR(10); -
改数据类型
-
删除某一个字段,再添加一个新的使用命令关键字直接修改:
-
ALTER TABLE 表名 MODIFY 字段名 字段新类型;
ALTER TABLE tb_user MODIFY tel VARCHAR(11); -
-
修改列的顺序
- ALTER TABLE 表名 MODIFY 目标列名 目标列数据类型 after 某一列列名;
ALTER TABLE tb_user MODIFY tel VARCHAR(11) after age;- 小练习,把sex 放到age字段的前面:
ALTER TABLE tb_user MODIFY sex VARCHAR(10) after name; -
删除列
- ALTER TABLE 表名 DROP 列名;
ALTER TABLE tb_user DROP sex; -
删除表
- DROP TABLE 表名;
DROP TABLE TB_USER;-
补充:判断表是否存在,存在则删除该表(创建表前使用)
DROP TABLE if exists 表名;
DROP TABLE IF EXISTS TB_USER;
- 课堂练习1
-- 创建员工表emp
CREATE TABLE emp (
empno INT ( 4 ) COMMENT "工号",
ename VARCHAR ( 10 ) COMMENT "姓名",
job VARCHAR ( 10 ) COMMENT "工种",
mgr INT ( 4 ) COMMENT "上级领导的工号",
hiredate DATE COMMENT "入职时间",
sal DOUBLE ( 7, 2 ) COMMENT "工资",
comm DOUBLE ( 7, 2 ) COMMENT "奖金",
deptno INT ( 4 ) COMMENT "所属部门编号"
) COMMENT = "员工表";
-- 创建部门表emp
CREATE TABLE dept (
deptno INT ( 4 ) COMMENT "部门编号",
dname VARCHAR ( 14 ) COMMENT "部门名称",
loc VARCHAR ( 13 ) COMMENT "部门办公所在地"
) COMMENT = "部门表";
注意:DOUBLE(7,2)是指一共7位数字(包括小数),其中小数是两位。
DML–对表中数据做操作的语句(表名前不需要加table)
INSERT语句
-
INSERT INTO 表名 (列名1,列名2,…) VALUES (值1,值2,…);
INSERT INTO emp(empno,ename,job,sal) VALUES (1001,'lily','programmer',5500); INSERT INTO emp(empno,ename,job,sal) VALUES (1001,"lily","programmer",5500); INSERT INTO emp(empno,ename,hiredate) VALUES (1002,'simth','18-01-24');
UPDATE语 句
-
UPDATE 表名 SET 字段名=值 WHERE 列名=值;
UPDATE emp SET ename='lucy' WHERE empno=1001;
课堂练习
-
把叫simth的员工的入职时间改为17年10月12日
UPDATE emp SET hiredate="17-10-12" WHERE ename="simth"; -
插入新员工lilei,工号1003,工资3000,奖金5000,上级领导编号1002
INSERT INTO emp(empno,ename,sal,comm,mgr) VALUES(1003,'lilei',3000,5000,1002); -
插入新员工zhangsanfeng,工号1004,上级领导编号1001,工资8000,奖金1000
-- 修改字段类型 ALTER TABLE emp MODIFY ename VARCHAR(20); INSERT INTO emp(empno,ename,mgr,sal,comm) VALUES( 1004, 'zhangsanfeng', 1001, 8000, 1000); -
插入新员工liuchuanfeng,工号1005,上级领导1004,入职时间18年01月22日,工资800,奖金2000
-
修改zhangsanfeng的工资,修改为8500
-
修改lilei的奖金,修改为2000
-
修改liuchuanfeng的上级领导为1001,工资为3000
UPDATE emp SET mgr=1001,sal=3000 WHERE ename='liuchuanfeng';
DELETE语句(注意:delete后面没有“*”)
-
DELETE FROM 表名 WHERE 条件
DELETE FROM emp WHERE job IS NULL;(区别于:SELECT * FROM 表名)
DDL–是对表本身操作的语句
TRUNCATE语句
-
TRUNCATE删除表内容的原理:
先把整张表删除,然后重新创建一个表结构一模一样的空表
-
TRUNCATE TABLE 表名
TRUNCATE TABLE emp; -
补充:
- DDL不支持事务,运行后马上执行,不能回滚;
- DML支持事务。
课堂练习:
练习1:
- 创建员工表emp 2.创建部门表dept;
练习2:
- 给dept表插入4条数据
- 10,‘ACCOUNTING’,‘NEW YORK’ --财务部 纽约
- 20,‘RESEARCH’,‘DALLAS’ --研究部 达拉斯市
- 30,‘SALES’,‘CHICAGO’ --销售部 芝加哥
- 40,‘OPERATIONS’,‘BOSTON’ --运营部 波士顿
练习3:
-
创建 mydb 数据库,使用 UTF8 编码
-
创建 t_item 商品表
-
在 t_item 表插入商品数据
- 7,‘苹果’,iphONe X,9999 now()
-
修改 id 是7的商品,修改库存量为20
-
删除商品 7
二、SQL分类、DML、DDL、数据库数据类型、查询、没有条件检查的查询语句、忘记数据库的密码怎么办
SQL分类
- 数据定义语言 DDL 重点
- 数据操纵语言 DML 重点 增 删 改
- 数据查询语言 DQL SELECT 查
- 事务控制语言 TCL
- 数据库控制语言 DCL
数据定义语言 DDL(重点)
- 负责数据结构定义,与创建数据库对象的语言
- 常用create ALTER DROP
- DDL不支持事务,DDL语句执行之后,不能回滚(面试老问)
数据操纵语言 DML(重点)
- 对数据库中更改数据操作的语句
- SELECT INSERT UPDATE DELETE–> CRUD 增删改查(CREATE,READ,UPDATE,DELETE)
- 通常把select相关操作,单独出来,称之为DQL
- DML支持事务,在非自动提交模式时,可以利用ROLLBACK回滚操作。数据库在一般情况下默认开启了自动提交模式。
数据查询语言 DQL(属于DML)–SELECT
- 筛选,分组,连表查询 面试重点
事务控制语言TCL 和数据库控制语言DCL
-
事务控制语句TCL
-
负责实现数据库中事务支持的语言,COMMIT ROLLBACK savepoint等指令
-
DCL数据库控制语言
-
管理数据库的授权,角色控制等,grant(授权),revoke(取消授权)
练习:
-
案例:创建一张表customer(顾客)
CREATE TABLE customer( cid INT(4) PRIMARY KEY COMMENT '顾客编号', cname VARCHAR(50) COMMENT '顾客姓名', sex CHAR(5) COMMENT '顾客性别', address VARCHAR(50) COMMENT '地址', phONe VARCHAR(11) COMMENT '手机', email VARCHAR(50) COMMENT '邮箱' ); SHOW CREATE TABLE customer; -
插入5条数据
INSERT INTO customer VALUES(1001,'小明','男','楼上18号','123','[email protected]'); INSERT INTO customer VALUES(1002,'小红','女','楼上17号','1234','[email protected]'); INSERT INTO customer VALUES(1003,'老王','男','楼上18号隔壁','1234','[email protected]'); INSERT INTO customer VALUES(1004,'老宋','男','楼上17号隔壁','1234','[email protected]'); INSERT INTO customer VALUES(1005,'小马','女','楼上17号隔壁','1234','[email protected]');-
修改一条数据的姓名 小红的姓名
-
修改一条数据的性别 老王的性别
-
修改一条数据的电话 1001号的电话
-
修改一条数据的邮箱 邮箱为[email protected],改成[email protected]
-
查询性别为 男的所有数据
SELECT * FROM customer WHERE sex="男"; -
自定义DDL操作的需求,5道题,可以同上面book表的操作
-
数据库数据类型
-
主要包括5大类
-
整数类型 INT, BIG INT
-
浮点数类型 DOUBLE DECIMAL
-
字符串类型 CHAR VARCHAR TEXT
-
日期类型 DATE DATETIME TIMESTAMP TIME YEAR…
-
其他数据类型 SET…
字符串
-
CHAR(固定长度) 定长字符串 最多255个字节 -
定多少长度,就占用多少长度
-
多了放不进去,少了用空格补全
-
不认识内容尾部的空格
-
VARCHAR(最大长度) 变长字符串 最大65535字节,但是使用一般不超过255 -
只要不超过定的长度,都可以放进去
-
以内容真实长度为准
-
认识内容尾部的空格
-
TEXT最大65535字节 -
BLOB大数据对象,以二进制(字节)的方式存储
整数
-
TINYINT1字节 -
SMALLINT2字节 -
INT4字节 (使用次数最多) -
BIGINT8字节
注意:INT(6)其中的6影响的是查询时显示长度(ZEROFILL),不影响数据的保存长度
CREATE TABLE t1(id1 INT,id2 INT(5));
INSERT INTO t1 VALUES(111111,111111);
ALTER TABLE t1 MODIFY id1 INT ZEROFILL;
ALTER TABLE t1 MODIFY id2 INT(5) ZEROFILL;
INSERT INTO t1 VALUES (1,1);
补充:ZEROFILL——当插入的数值比定义的属性长度小的时候,bai会在数值前面进行补值操作。
-
FLOAT4字节 -
DOUBLE8字节DOUBLE(8,2) 可能会产生精度的缺失 10.0/3 3.3333333336;
DECIMAL 不会缺失精度,但是使用的时候需要指定总长度和小数位数。
日期
-
DATE年月日 -
TIME时分秒 -
DATETIME年月日时分秒,最大值到9999年,而且需要手动输入,如果没有手动输入,就显示null. -
TIMESTAMP年月日时分秒,在没有数据手动插入时,自动填入当前时间.最大值2038年 -
BIGINT1970-1-1 0:0:0 格林威治时间 到现在的毫秒数
案例:
创建表t,字段d1 DATE,d2 TIME,d3 DATETIME,d4 TIMESTAMP
CREATE TABLE t(
id INT,
d1 DATE,
d2 TIME,
d3 DATETIME,
d4 TIMESTAMP
);
INSERT INTO t (d1,d2) VALUES ('1910-01-10','12:32:12');
INSERT INTO t VALUES(1,'2018-12-21','15:12:00','1995-02-10 12:08:12','2030-10-10 15:19:32');
INSERT INTO t VALUES(2,'3018-01-25','15:12:34','9234-12-31 12:12:12','2030-12-31 12:12:12');
INSERT INTO t VALUES(2,'3018-01-25','15:12:34','9999-12-31 23:59:59','2030-12-31 12:12:12');
练习:
创建人物表,插入,修改,查询
CREATE TABLE persON(
id INT(4) PRIMARY KEY,
name VARCHAR(50),
age INT(3)
);
INSERT INTO persON VALUES(1,"梅超风",36);
INSERT INTO persON VALUES(2,"洪七公",96);
INSERT INTO persON VALUES(3,"杨过",40);
INSERT INTO persON VALUES(4,"令狐冲",28);
INSERT INTO persON VALUES(5,"张三丰",100);
INSERT INTO persON VALUES(6,"张翠山",27);
INSERT INTO persON VALUES(7,"张无忌",27);
INSERT INTO persON VALUES(8,"赵敏",18);
INSERT INTO persON VALUES(9,"独孤求败",250);
INSERT INTO persON VALUES(10,"楚留香",36);
技巧1:将需要批量执行的语句放入一个sql文件中,通过source命令即可批量执行
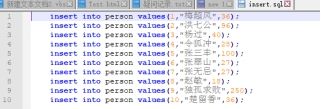
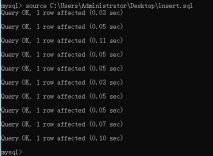
技巧2:
-
如果是批量插入数据可以缩写insert INTO XXX(XX, XX…) VALUES
-
例如:
INSERT INTO persON VALUES(1,"梅超风",36); INSERT INTO persON VALUES(2,"洪七公",96); -- 可以缩写为: INSERT INTO persON VALUES(1, "梅超风",36), (2,"洪七公",96);
课堂练习:
1.案例:修改张三丰的name为刘备,id为11
UPDATE persON SET name="刘备",id=11 WHERE name="张三丰";
2.案例:修改2号人物的的name为夏侯渊
UPDATE persON SET name="夏侯渊" WHERE id=2;
3.案例:根据条件修改persON表中的数据,修改id是6的数据中,姓名改为’任我行’, 年龄改为39
UPDATE persON SET name="任我行",age=39 WHERE id=6;
4.案例:修改姓名是"楚留香’的数据,把id改为20,年龄改为19
UPDATE persON SET id=20,age=19 WHERE name="楚留香";
5.案例:把persON所有的数据的年龄全部改为20
UPDATE persON SET age=20;
6.案例:修改id为7的数据,把id改为100,姓名改为杨过,年龄改为21
UPDATE persON SET id=100,name="杨过",age=21 WHERE id=7;
7.案例:修改姓名是独孤求败,把年龄改为35
UPDATE persON SET age=35 WHERE name="独孤求败";
8.案例:修改id=8的信息,把姓名改为房玄龄
UPDATE persON SET name="房玄龄" WHERE id=8;
9.案例 :修改id为20并且年龄为20的人的姓名为刘德华(郑少秋也行)提示 WHERE…AND…
UPDATE persON SET name="郑少秋" WHERE id=20 AND age=20;
查询(没有条件的简单查询)
-
SELECT * FROM 表名;查询表中所有的数据
SELECT * FROM persON; SELECT * FROM t; SELECT * FROM emp; SELECT * FROM dept; -
查询某些列中的值
SELECT name as '姓名' FROM persON; SELECT name as '姓名',age as '年龄' FROM persON; SELECT id as '编号',name as '姓名',age as '年龄' FROM persON; -
学习过程的编程习惯select * FROM 表;*多一步查列表名称的操作,效率低!
-
工作中的编程习惯select id,name,age FROM persON;
-
查询emp表中所有员工的姓名,上级领导的编号,职位,工资
SELECT ename,mgr,job,sal FROM emp; -
查询emp表中所有员工的编号,姓名,所属部门编号,工资
SELECT empno,ename,deptno,sal FROM emp; -
查询dept表中所有部门的名称和地址
SELECT dname,loc FROM dept;
如果忘记了mysql的用户名和密码怎么办
-
卸载重新装
-
不重装软件如何修改密码
- 1.停止mysql服务
- 2.cmd中输入一个命令
mysqld --skip-grant-tables; -通过控制台,开启了一个mysql服务- 3.开启一个新的cmd
/> mysql -u root -p #可以不使用密码进入数据库 /> SHOW databases;----mysql /> USE mysql; /> UPDATE user SET password=password('新密码') WHERE user="root";- 4.关闭mysqld这个服务/进程
- 5.重启mysql服务
三、别名、去重、WHERE、AND和OR、LIKE、ORDER BY、LIMIT分页、常用函数、聚合函数
别名
-
SELECT 字段名 as 别名 FROM 表名;
-
SELECT 字段名 别名,字段名 别名 FROM 表名;
SELECT ename '员工姓名' FROM emp; SELECT e.ename '员工姓名' FROM emp e; SELECT e.ename,e.job,e.sal FROM emp e;---表的别名
DISTINCT 去重
-
查询emp中所有的职位
SELECT job FROM emp; -
查询emp中所有的部门领导编号
-
查询emp中有多少个部门领导
SELECT DISTINCT mgr FROM emp;
WHERE
-
WHERE子句用于规定选择的标准
-
如果需要有条件的从表中选取数据,可将WHERE子句添加到SELECT语句的后面
-
WHERE子句是决定一条查询语句最后显示多少条目数的关键,
- 查询上级领导编号为7698的员工所有信息
SELECT empno,ename,job,mgr FROM emp WHERE mgr=7698; (条目数===对象数量) -
在WHERE中我们会使用一些运算符,大致与java相同
WHERE(续)
-
AND OR
SELECT * FROM emp WHERE mgr=7698 AND (comm>1000 OR deptno=3) -
LIKE
-
< , > , <= , >= , = , != <> (不等于)
-
IS NULL , IS NOT NULL, in (112,113)(112或113) , NOT
-
BETWEEN XX AND XXX
课堂练习:
1.案例:查询工资高于2000的所有员工的编号,姓名,职位,工资
SELECT empno,ename,job,sal
FROM emp
WHERE sal>2000;
2.案例:查询工资小于等于1600的所有员工的编号,姓名,工资
SELECT empno,ename,sal
FROM emp
WHERE sal<=1600;
3.案例:查询部门编号是20的所有员工的姓名,职位以及所属部门的编号
SELECT ename,job,deptno
FROM emp
WHERE deptno=20;
4.案例:查询职位是MANAGER的所有员工的姓名,职位
SELECT ename,job
FROM emp
WHERE job="MANAGER";
5.案例:查询不是10号部门的所有员工的编号,姓名,以及所属部门的编号(2种方法)
-- 方法一:
SELECT empno,ename,deptno
FROM emp
WHERE deptno!=10;
-- 方法二:
SELECT empno,ename,deptno
FROM emp
WHERE deptno <> 10;
6.案例: 查询单价等于128的商品
SELECT *
FROM t_item
WHERE price=128;
7.案例:查询单价不等于8443的商品
-- 方法一:
SELECT *
FROM t_item
WHERE price != 8443;
-- 方法二:
SELECT *
FROM t_item
WHERE prcie <> 8443;
AND 和 OR 运算符
- 在WHERE子句中两个或者多个条件结合起来
- 结合的结果与java中的&& || 一致
- 在不明确优先级的情况下,请使用()
课堂练习:
1.案例:查询不是10号部门的并且工资小于3000的所有员工的编号,姓名,以及所属部门的编号
SELECT empno,ename,deptno
FROM emp
WHERE deptno<>10 AND sal<3000;
2.案例:查询部门编号是30或者上级领导为7698的所有员工的姓名,职位以及所属部门的编号
SELECT ename,job,deptno
FROM emp
WHERE deptno=30 OR mgr=7698;
SQL LIKE 操作符
-
like用于在WHERE子句中搜索列中的指定的 模式
-
sql 模式 —>通配符
-
%代替一个或者多个字符
- a%、%a、a%a
-
_代替一个字符
- A_ 、_B 、A_B 、_A_
-
小演示
- %@%.% [email protected]
- %@%.cn %@163.%
- WHERE ename LIKE ‘%a_’
课堂练习:
1.案例:查询标题包含记事本的商品
SELECT *
FROM t_item
WHERE title LIKE '%记事本%';
2.案例:查询有赠品的DELL产品 sell_point
SELECT *
FROM t_item
WHERE title LIKE '%DELL%' AND sell_point LIKE '%赠%';
3.案例:查询单价低于100的笔记本 price
SELECT *
FROM t_item
WHERE title LIKE '%笔记本%' AND price<1000;
4.案例:查询价格介于50到200之间的得力商品
-- 方法一:
SELECT *
FROM t_item
WHERE title LIKE '%得力%' AND price>=50 AND price <=200;
-- 方法二:
SELECT *
FROM t_item
WHERE title LIKE '%得力%' AND price BETWEEN 50 AND 200;
5.案例:查询有图片的得力商品 image
SELECT *
FROM t_item
WHERE title LIKE '%得力%' AND image IS NOT NULL;
6.案例:查询分类为238,917的产品
SELECT *
FROM t_item
WHERE category_id=238 OR category_id=917;
-- 或者:
-- WHERE category_id IN (238,917);
7.案例:查询标题中不含得力的商品
SELECT *
FROM t_item
WHERE title NOT LIKE '%得力%';
8.案例:查询分类不是238,917的商品
SELECT *
FROM t_item
WHERE category_id NOT in (238,917);
9.案例:查询价格介于50到200之外的商品
SELECT *
FROM t_item
WHERE price NOT BETWEEN 50 AND 200;
ORDER BY 子句
- 用于根据指定列对结果集进行排序
- 默认升序 小—>大
- asc为升序,desc降序
- ORDER BY必须写在WHERE语句之后
课堂练习:
1.案例:查询所有带燃字的商品,按单价升序排列
2.案例:查询所有DELL商品,按单价降序排列
3.案例:查询所有DELL商品,按分类升序单价降序排列
LIMIT 子句–分页
-
LIMIT begin,size
-
begin 本页数据的起始行,从0开始
-
size 本页显示多少行
举个栗子:
-- 查询所有商品,并按单价正序排列,显示其中第1页(每页5条)
SELECT price
FROM t_item
ORDER BY price LIMIT 0,5;
-- 查询所有商品,并按单价正序排列,显示其中第2页(每页5条)
SELECT price
FROM t_item
ORDER BY price LIMIT 5,5;
函数
- 很多函数功能与java中相关api类似;
- 但是,除了几种特殊的需求以外,我们开发时,尽量不要在数据库中进行函数计算。
CONCAT()函数
-
CONCAT(str1,str2,…)
-
如果任何一个str是null,返回值就为null
SELECT CONCAT('今天周5了','下周讲完数据库') FROM dual; SELECT CONCAT(ename,mgr) FROM emp; -- 查询商品,并将标题和单价,加上元,拼到一起进行展现 SELECT CONCAT(title,price,'元') FROM t_item;
打印 Hello World
SELECT 'Hello World' FROM dual;
数值计算
-
运算符 + - * / %(求模/取余) mod()
-
弱数据类型 字符串与数字进行计算 ‘10’-5
-
取余 % 7%2等同于mod(7,2)
-- 查询商品,并在结果中显示商品的总价值 SELECT price '单价',num '库存',price*num 总价值 FROM t_item ORDER BY 总价值;
DATE_FORMAT() 函数
-
now() 返回当前的日期和时间
-
curdate() 返回当前的日期
-
curTIME() 返回当前的时间
-
DATE(时间日期表达式)提取这个表达式日期的部分
-
TIME(时间日期表达式)提取这个表达式时间的部分
-
EXTRACT(时间日期表达式)提取这个表达式单独的一部分(年月日时分秒)
SELECT now() FROM dual;--打印当前的日期和时间 SELECT DATE(now());--打印当前的日期 SELECT TIME(now());--打印当前的时间 SELECT EXTRACT(YEAR FROM now());--打印当前的年份 SELECT EXTRACT(mONth FROM now());--打印当前的月份 SELECT EXTRACT(day FROM now());--打印当前是几号
DATE_FORMAT()
- 以不同的格式显示时间/日期数据
- 语法 DATE_FORMAT(日期表达式,’
format’); DATE_FORMAT(now(),’%c-%d’) format- %c 月 1-12
- %M 月 英文
- %d 月的天(00-31)
- %D 月的天 英文
- %H 小时(00-23)
- %h 小时(01-12)
- %i 分钟
- %m 月 01-12
- %S 秒
- %Y 年 (四位数的年)
- %y年 (两位数的年)
注意:
20201130在Java和MySQL中的表示方式不同:
- Java,yyyyMMdd
- MySQL,%Y%m%d
课堂练习:
1.显示emp中hiredate为XXXX年XX月XX日
SELECT DATE_FORMAT(hiredate,"%Y年%m月%d日") FROM emp;
2.显示当前时间 格式为 23:12:16
SELECT DATE_FORMAT(now(),"%h:%i:%s");
3.显示当前日期和时间,格式为XXXX-XX-XX xx:xx:xx
SELECT DATE_FORMAT(now(),"%Y-%m-%d %h:%i:%s");
4.显示当前日期为 日/月/年
SELECT DATE_FORMAT(now(),"%d/%m/%Y");
5.查询商品,并显示商品上传日期(x年x月x日)
SELECT DATE_FORMAT(createdtime,"%Y年%m月%d日") FROM t_item;
STR_TO_DATE 把字符串转换成日期格式
-
把字符串格式的时间,转换成时间格式
-
第一个参数为字符串,第二个参数为格式和第一个参数一样的fromat字符
-
如果格式不同,结果为null
SELECT STR_TO_DATE('08/09/2008','%m/%d/%Y'); SELECT STR_TO_DATE('08/09/08','%m/%d/%y'); SELECT STR_TO_DATE('08.09.2008','%m.%d.%y'); SELECT STR_TO_DATE('08.08.2008 08:00:00','%m.%d.%Y %h:%i:%S');
IFNULL() 的函数
-
空值处理函数;
-
IFNULL(expr1,expr2) 如果expr1不是null,ifnull返回的就是expr1,如果是null,返回expr2
-- 查询没有奖金(comm字段)的员工,并把没有奖金的数值变成0 SELECT IFNULL(comm,0) FROM emp;
聚合函数
-
对多行数据进行合并统计
-
使用聚合函数,要注意,聚合函数一般只有一行结果,如果其他要查询的列,有多行结果,那么只会显示,其他结果被舍弃
-
原因,数据库不支持行合并
-
不要把聚合函数和普通列放到同一个dql语句中,除非普通列只有一条数据
-
SUM():返回列的总数(总额)
SELECT SUM(sal) FROM emp; -
AVG(): 返回数值的平均值,但是null不包含在计算中
SELECT SUM(sal),AVG(comm) FROM emp; SELECT comm FROM emp; -
COUNT(): 返回指定列的总数目,null不计数
SELECT COUNT(comm) FROM emp; -
MAX():这一列中的最大值,null不计算
-
MIN():这一列中的最小值,null不计算
-- 查询得力商品的库存合计 SELECT SUM(num) FROM t_item WHERE title LIKE "%得力%"; -- 查询得力商品的平均单价 SELECT AVG(price) FROM t_item WHERE title LIKE '%得力%'; -- 查询DELL商品的条目数 SELECT COUNT(1) FROM t_item WHERE title LIKE '%DELL%'; -- 查询DELL商品的最高单价 SELECT MAX(price) FROM t_item WHERE title LIKE '%DELL%'; -- 查询DELL商品的最小库存 SELECT MIN(num) FROM t_item WHERE title LIKE '%DELL%';
注意:区分COUNT(*)、COUNT(1)、COUNT(列名):
- COUNT(*),统计行数,包括值为NULL的,多字段时效率低;
- COUNT(1),统计行数,包括值为NULL的,效率不受字段影响;
- COUNT(列名),统计当前列不为NULL的行数。
字符串的函数
-
CHAR_LENGTH()–字符数
SELECT CHAR_LENGTH("中国"); -- 2 SELECT LENGTH("中国"); -- 6,UTF8编码,一个汉字三个字节 -
INSTR(‘abcdefg’,‘bcd’) 返回第二个字符串在第一个中占的位置,从1开始,找不到返回0
SELECT INSTR('abcdefg','bcd'); -- 2 -
LOCATE(‘abc’,’—abc—abc—abc’) 返回第一个字符串在第二个中占的位置,从1开始,找不到返回0
SELECT LOCATE('abc','---abc---abc---abc'); -- 4 -
INSERT(“abcdefghajdfkafjsdak”,2,5,’—’) 用子串取代第一个字符串的位置,从2开始,取代5个长度
SELECT INSERT("abcdefghajdfkafjsdak",2,5,'---'); -- a---ghajdfkafjsdak -
LOWER()转化成小写
SELECT LOWER("aBc"); -- abc -
UPPER()转换成大写
SELECT LOWER("aBc"); -- ABC -
LEFT(“abcdef”,3)返回左边3个字符
SELECT RIGHT("abcdef",3); -- def -
RIGHT(“abcdef”,3)返回右边3个字符
SELECT RIGHT("abcdef",3); -- abc -
TRIM(" a b c ")去除的是两边空格
-
SUBSTRING(“fdafadfadsfsad”,4)从4开始截取
-
SUBSTRING(“fdafadfadsfsad”,4,6);从4开始截取,截取6个字符
SELECT SUBSTRING("fdafadfadsfsad",4,6); -- fadfad -
REPEAT(“abc”,3) 重复3遍
-
REPLACE(“hello my sql”,“my”,“your”)子串替换
-
REVERSE()-反转字符串
数学相关函数
-
FLOOR()向下取整
-
ROUND(32.25)四舍五入取整
-
ROUND(32.2523432,2)四舍五入,取小数点后两位
-
ROUND(4332.25,-2)小数点左移两位,然后四舍五入取整
SELECT ROUND(4332.25,-2); -- 4300 -
TRUNCATE(234.234,1) 保留小数点后1位,不四舍五入
SELECT TRUNCATE(234.294,1); -- 234.2
SELECT语句技巧:
写SELECT语句的时候,
1.先写FROM语句,
2.再写SELECT语句,
3.然后写WHERE语句,
4.最后写ORDER BY语句。别小看这样幼稚,但是效率高,速度快,逻辑清楚。
练习
1.案例:查询没有上级领导的员工的编号,姓名,工资
2.案例:查询emp表中没有奖金的员工的姓名,职位,工资,以及奖金
3.案例:查询emp表中含有奖金的员工的编号,姓名,职位,以及奖金
4.案例:查询含有上级领导的员工的姓名,工资以及上级领导的编号
5.案例:查询emp表中名字以"S"开头的所有员工的姓名
6.案例:查询emp表中名字的最后一个字符是’S’的员工的姓名
7.案例:查询倒数的第2个字符是"E"的员工的姓名
8.案例:查询emp表中员工的倒数第3个字符是
9.案例:查询emp表中员工的名字中包含"A"的员工的姓名
10.案例:查询emp表中名字不是以’K’开头的员工的所有信息
11.案例:查询emp表中名字中不包含"A"的所有员工的信息
12.案例:做文员的员工人数(jobid 中 含有 CLERK 的)
13.案例:销售人员 job: SAXXXXX 的最高薪水
14.案例:最早和最晚入职时间
15.案例:查询每种类别的商品数量
16.案例:查询 类别 163 的商品
17.案例:查询商品价格不大于100的商品名称(TITLE)列表
18.案例:查询品牌是联想,且价格在40000以上的商品名称和价格
19.案例:查询品牌是三木,或价格在50以下的商品名称和价格
20.案例:查询品牌是三木、广博、齐心的商品名称和价格
21.案例:查询品牌不是联想、戴尔的商品名称和价格
22.案例:查找品牌是联想且价格大于10000的电脑名称
23.案例:查询联想或戴尔的电脑名称列表
24.案例:查询联想、戴尔、三木的商品名称列表
25.案例:查询不是戴尔的电脑名称列表
26.案例:查询所有是笔记本的商品品牌、名称和价格
27.案例:查询品牌是末尾字符是’力’的商品的品牌、名称和价格
28.案例:名称中有联想字样的商品名称
29.案例:查询卖点含有’赠’产品名称
30.案例:查询emp表中员工的编号,姓名,职位,工资,并且工资在1000~2000之间。
【后30题作为提升】
31.案例:查询emp表中员工在10号部门,并且含有上级领导的员工的姓名,职位,上级领导编号以及所属部门的编号
32.案例:查询emp表中名字中包含’E’,并且职位不是MANAGER的员工的编号,姓名,职位,以及工资。
33.案例:查询emp表中10号部门或者20号部门中员工的编号,姓名,所属部门的编号
34.案例:查询emp表中没有奖金或者名字的倒数第2个字母不是T的员工的编号,姓名,职位以及奖金
35.案例:查询工资高于3000或者部门编号是30的员工的姓名,职位,工资,入职时间以及所属部门的编号
36.案例:查询不是30号部门的员工的所有信息
37.案例:查询奖金不为空的员工的所有信息
38.案例:查询emp表中所有员工的编号,姓名,职位,根据员工的编号进行降序排列
39.案例:查询emp表中部门编号是10号或者30号中,所有员工姓名,职务,工资,根据工资进行升序排列
40.案例:查询emp表中所有的数据,然后根据部门的编号进行升序排列,如果部门编号一致,根据员工的编号进行降序排列
41.案例:查询emp表中工资高于1000或者没有上级领导的员工的编号,姓名,工资,所属部门的编号,以及上级领导的编号,根据部门编号进行降序排列,如果部门编号一致根据工资进行升序排列。
42.案例:查询emp表中名字中不包含S的员工的编号,姓名,工资,奖金,根据工资进行升序排列,如果工资一致,根据编号进行降序排列
43.案例:统计emp表中员工的总数量
44.案例:统计emp表中获得奖金的员工的数量
45.案例:求出emp表中所有的工资累加之和
46.案例:求出emp表中所有的奖金累加之和
47.案例:求出emp表中员工的平均工资
48.案例:求出emp表中员工的平均奖金
49.案例:求出emp表中员工的最高工资
50.案例:求出emp表中员工编号的最大值
51.案例:查询emp表中员工的最低工资。
52.案例:查询emp表中员工的人数,工资的总和,平均工资,奖金的最大值,奖金的最小值,并且对返回的列起别名。
53.案例:查询emp表中每个部门的编号,人数,工资总和,最后根据人数进行升序排列,如果人数一致,根据工资总和降序排列。
54.案例:查询工资在1000~3000之间的员工信息,每个部门的编号,平均工资,最低工资,最高工资,根据平均工资进行升序排列。
55.案例:查询含有上级领导的员工,每个职业的人数,工资的总和,平均工资,最低工资,最后根据人数进行降序排列,如果人数一致,根据平均工资进行升序排列
56.案例:查询工资在1000~3000之间每一个员工的编号,姓名,职位,工资
57.案例:查询emp表中奖金在500~2000之间所有员工的编号,姓名,工资以及奖金
58.案例:查询员工的编号是7369,7521,
59.案例:查询emp表中,职位是ANALYST,
60.案例:查询emp表中职位不是ANALYST,
四、分组查询、HAVING子句、子查询、关联查询、笛卡尔积、等值连接/内连接、左外连接、右外连接
18.案例:查询品牌是联想,且价格在40000以上的商品名称和价格
SELECT title,price
FROM t_item
WHERE title LIKE '%联想%' AND price >40000;
19.案例:查询品牌是三木,或价格在50以下的商品名称和价格
SELECT title,price
FROM t_item
WHERE title LIKE '%三木%' OR price <50;
20.案例:查询品牌是三木、广博、齐心的商品名称和价格
select title,price
FROM t_item
WHERE title LIKE '%三木%' OR title LIKE '%广博%' OR title LIKE '%齐心%';
21.案例:查询品牌不是联想、戴尔的商品名称和价格
SELECT title,price
FROM t_itme
WHERE title NOT LIKE '%联想%' AND title NOT LIKE '%戴尔%';
22.案例:查找品牌是联想且价格大于10000的电脑名称
SELECT title
FROM t_item
WHERE title LIKE '%联想%' AND price >10000 AND title LIKE '%电脑%';
23.案例:查询联想或戴尔的电脑名称列表
SELECT title
FROM t_item
WHERE (title LIKE '%联想%' OR title LIKE '%戴尔%') AND title LIKE '%电脑%';
24.案例:查询联想、戴尔、三木的商品名称列表
SELECT *
FROM t_item
WHERE title LIKE '%联想%' OR title LIKE '%戴尔%' OR title LIKE '%三木%';
25.案例:查询不是戴尔的电脑名称列表
SELECT title
FROM t_item
WHERE title NOT LIKE '%戴尔%' AND title LIKE '%电脑%';
26.案例:查询所有是记事本的商品品牌、名称和价格
SELECT item_type,title,price
FROM t_item
WHERE title LIKE '%记事本%';
分组查询(GROUP BY)
-
关键字:“每”
GROUP BY deptno -- 查询每个部门的。。。(平均值/数量/最大值/最小值。。) GROUP BY deptno,mgr -- 查询每个部门下主管的。。。(平均值/数量/最大值/最小值。。) -
查看每个部门的平均工资
-- 错误演示 SELECT AVG(sal),deptno FROM emp ORDER BY deptno; -- 正确演示 SELECT AVG(sal),deptno FROM emp GROUP BY deptno;
* 分组查询通常和聚合函数一起使用
* 一般情况下,查询字段中出现聚合函数和普通列,一起查询的时候,那么分组的条件就是普通列
* 当select子句中含有聚合函数时,凡是不在聚合函数中的其他单独字段,都必须出现在GROUP BY子句中.
* GROUP BY子句要写在ORDER BY之前,WHERE后
* GROUP BY 可以根据多个字段分组
* 查看同部门同职位的平均工资
```sql
SELECT deptno,job,AVG(sal) FROM emp GROUP BY deptno,job;
-
查询部门平均工资 SELECT deptno AVG(sal) FROM emp GROUP BY deptno;
-
查询每个领导有多少个员工,显示领导id和员工数量
SELECT mgr,COUNT(*) FROM emp GROUP BY mgr;
练习
1.案例:查询emp表中每个部门的编号,人数,工资总和,最后根据人数进行升序排列,如果人数一致,根据工资总和降序排列。
SELECT deptno,COUNT(*),SUM(sal)
FROM emp
GROUP BY deptno
ORDER BY COUNT(*),SUM(sal) desc;
2.案例:查询工资在1000~3000之间的员工信息,每个部门的编号,平均工资,最低工资,最高工资,根据平均工资进行升序排列。
SELECT deptno,AVG(sal),MIN(sal),MAX(sal)
FROM emp
WHERE sal>=1000 AND sal<=3000
GROUP BY deptno
ORDER BY AVG(sal);
3.案例:查询含有上级领导的员工,每个职业的人数,工资的总和,平均工资,最低工资,最后根据人数进行降序排列,如果人数一致,根据平均工资进行升序排列
SELECT COUNT(*),SUM(sal),AVG(sal),MIN(sal),job
FROM emp
WHERE mgr IS NOT NULL
GROUP BY job
ORDER BY COUNT(*) desc,AVG(sal);
4.案例:查询工资在1000~3000之间每一个员工的编号,姓名,职位,工资
SELECT empno,ename,job,sal
FROM emp
WHERE sal BETWEEN 1000 AND 3000;
5.案例:查询emp表中奖金在500~2000之间所有员工的编号,姓名,工资以及奖金
SELECT empno,ename,sal,comm
FROM emp
WHERE comm BETWEEN 500 AND 2000;
6.案例:查询员工的编号是7369,7521,XXXX
SELECT * FROM emp
WHERE empno in(7369,7521,XXXX);
7.案例:查询emp表中,职位是ANALYST,
SELECT * FROM emp
WHERE job='ANALYST'
8.案例:查询emp表中职位不是ANALYST,
SELECT * FROM emp
WHERE job!='ANALYST'
练习
-- 查询出所有分类商品所对应的库存总量
SELECT category_id,SUM(num)
FROM t_item
GROUP BY category_id;
-- 查询出所有分类商品所对应的平均单价
SELECT category_id,AVG(price)
FROM t_item
GROUP BY category_id;
-- 1. 每个部门的人数
SELECT deptno,COUNT(*)
FROM emp
GROUP BY deptno;
-- 2. 每个部门中,每个主管的手下人数
SELECT deptno,mgr,COUNT(*)
FROM emp
GROUP BY deptno,mgr; -- 注意:这个题在分组的时候看包含关系,部门包含主管,所以先写部门,后写主管
-- 3. 每种工作的平均工资
SELECT job,AVG(sal)
FROM emp
GROUP BY job;
-- 提高题 4. 每年的入职人数
SELECT COUNT(*),EXTRACT(YEAR FROM hiredate) YEAR
FROM emp
GROUP BY YEAR;
HAVING 子句(有条件分组统计)
-
关键词:“条件是”
例:HAVING AVG(sal)>2000 条件是平均工资大于两千 -
查询部门的平均工资,前提是该部门的平均工资高于2000
-- 错误演示 SELECT AVG(sal),deptno FROM emp WHERE AVG(sal)>2000 GROUP BY deptno; -- 正确演示 SELECT AVG(sal),deptno FROM emp GROUP BY deptno HAVING AVG(sal)>2000;
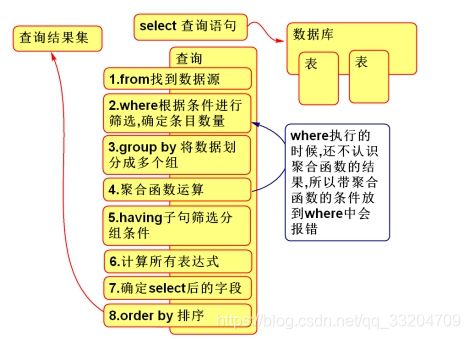
SQL的执行流程:
-
GROUP BY 使用HAVING过滤条件
-
在sql语句中添加HAVING子句的原因,是因为WHERE的执行顺序在集合函数之前,WHERE关键字无法与聚合函数一起使用
-
WHERE条件用于过滤行数,HAVING条件用于过滤分组数量
-
执行顺序,首先执行WHERE,然后执行GROUP BY,根据一个或多个列进行分组,之后执行HAVING.对分组以后的数据再次过滤.最后执行排序ORDER BY
-- 查询所有分类商品所对应的库存总量中,高于1000的总量
SELECT SUM(num),category_id
FROM t_item
GROUP BY category_id
HAVING SUM(num)>1000;
-- 查询所有分类商品所对应的平均单价中,低于100的均价
SELECT AVG(price),category_id
FROM t_item
GROUP BY category_id
HAVING AVG(price)<=100;
-- 查询编号238和编号917分类商品的平均单价
-- 方法一:
SELECT AVG(price),category_id
FROM t_item
GROUP BY category_id
HAVING category_id in (238,917);
-- 方法二:
SELECT AVG(price),category_id
FROM t_item
WHERE category_id in (238,917)
GROUP BY category_id;
总结:
- HAVING子句经常跟聚合函数一起使用,
- 如果没有使用到聚合函数,要注意是否可以写在WHERE中,
- 如果可以写在WHERE,优先使用WHERE过滤。
课堂练习
1.案例:查询emp表中,每个部门的平均工资高于2000的部门的编号,部门的人数,平均工资, 最后根据平均工资进行升序排列。
SELECT deptno,COUNT(*),AVG(sal)
FROM emp
GROUP BY deptno
HAVING AVG(sal)>2000
ORDER BY AVG(sal);
2.案例:查询emp表中名字中不是以’K’开头的信息,每个部门的最低工资高于1000的部门的编号,工资总和,平均工资以及最低工资,最后根据平均工资进行升序排列。
SELECT deptno,SUM(sal),AVG(sal),MIN(sal)
FROM emp
WHERE ename NOT LIKE 'K%'
GROUP BY deptno
HAVING MIN(sal)>1000
ORDER BY AVG(sal) asc;
3.案例:查询emp表中部门编号是10,30号部门的员工,每个职业的最高工资低于5000的职业的名称,人数,平均工资,最高工资,最后根据人数进行升序排列,如果人数一致,根据最高工资进行降序排列。
SELECT job,COUNT(*),AVG(sal),MAX(sal)
FROM emp
WHERE deptno in (10,30)
GROUP BY job
HAVING MAX(sal)<=5000
ORDER BY COUNT(*),MAX(sal) desc;
4.案例:查询emp表中,每个部门的编号,人数,工资总和,最高工资以及最低工资,过滤掉最高工资是5000的部门,根据部门的人数进行升序排列,如果人数一致,则根据最高工资进行降序排列。
SELECT deptno,COUNT(*),SUM(sal),MAX(sal),MIN(sal)
FROM emp
GROUP BY deptno
HAVING MAX(sal)!=5000
ORDER BY COUNT(*),MAX(sal) desc;
5.案例:查询emp表中工资在1000~3000之间的员工信息,每个部门的编号,工资总和,平均工资,过滤掉平均工资低于2000的部门,按照平均工资进行升序排列
SELECT deptno,SUM(sal),AVG(sal)
FROM emp
WHERE sal>=1000 AND sal<=3000
GROUP BY deptno
HAVING AVG(sal)>=2000
ORDER BY AVG(sal);
6.案例:查询emp表中名字不是以"S"开头,每个职位的名字,人数,工资总和,最高工资,过滤掉工资是3000的职位,根据人数进行升序排列,如果人数一致,根据工资总和进行降序排列。
SELECT job,COUNT(*),SUM(sal),MAX(sal)
FROM emp
WHERE ename NOT LIKE 'S%' AND sal!=3000
GROUP BY job
ORDER BY COUNT(*) ,SUM(sal) desc;
7.案例:查询emp表的信息,每个职位的名称,人数,平均工资,最低工资,过滤掉平均工资是3000的职位信息,根据人数进行降序排列,如果人数一致,根据平均工资进行升序排列
SELECT job,COUNT(*),AVG(sal),MIN(sal)
FROM emp
GROUP BY job
HAVING AVG(sal)!=3000
ORDER BY COUNT(*) desc,AVG(sal);
MySQL子查询
-
子查询是指,在DQL语句,嵌套了另外一个查询(DQL)语句
-
某些DDL也可以使用子查询
-
子查询语句,称为内部查询,而包含子查询的查询语句,称为外部查询
-
常用的子查询会出现两种
- 外部查询的WHERE子句使用子查询 (最常用);
- 子查询在from后面,用子查询的结果集充当一张表。
-
子查询可以在表达式的任何地方使用,但是必须在括号中关闭
-
子查询可以嵌套在另外一个子查询中
课堂练习
1.案例:拿最低工资的员工信息
-- 方法一
SELECT MIN(sal) FROM emp;
-- 方法二
SELECT * FROM emp WHERE sal=(SELECT MIN(sal) FROM emp);
2.案例:工资多于平均工资的员工信息
-- 方法一
SELECT AVG(sal) FROM emp;
-- 方法二
SELECT * FROM emp WHERE sal>(SELECT AVG(sal) FROM emp);
3.案例:最后入职的员工信息
SELECT empno,ename,hiredate
FROM emp
WHERE hiredate=(SELECT MAX(hiredate) FROM emp);
4.案例:查询出有商品的 分类信息
-- 方法一
SELECT DISTINCT category_id FROM t_item;
-- 方法二
SELECT * FROM t_item_category WHERE id in (SELECT DISTINCT category_id FROM t_item);
5.案例:查询工资高于20号部门最高工资的员工的所有信息
-- 方法一
SELECT MAX(sal) FROM emp WHERE deptno=20;
-- 方法二
SELECT * FROM emp WHERE sal>(SELECT MAX(sal) FROM emp WHERE deptno=20);
6.案例:查询emp表中姓名是"KING"所属的部门的编号,名称
-- 方法一
SELECT deptno FROM emp WHERE ename='KING';
-- 方法二
SELECT deptno,dname FROM dept WHERE deptno=(SELECT deptno FROM emp WHERE ename='KING');
7.案例:查询部门名称是SALES的部门下所有员工的编号,姓名,职位,以及所属部门的编号
SELECT empno,ename,job,deptno FROM emp
WHERE deptno=(SELECT deptno FROM dept WHERE dname='SALES');
8.案例:查询部门地址是DALLAS的部门下所有员工的所有信息(查询在DALLAS工作的所有员工信息)
SELECT * FROM emp WHERE deptno=(SELECT deptno FROM dept WHERE loc='DALLAS');
9.案例:查询跟JONES同样工作的员工的所有信息(包含JONES)
SELECT * FROM emp WHERE job=(SELECT job FROM emp WHERE ename='JONES');
不包含JONES
SELECT * FROM emp WHERE job=(SELECT job FROM emp WHERE ename='JONES') AND ename <>'JONES';
关联查询数据
-
从多张表中查询相应记录信息emp.deptno dept.deptno
-
关联查询的重点在于这些表中记录的对应关系,这个关系也称为连接条件(关联条件)
-
查看每个员工的名字以及所在部门的名字
SELECT e.ename,d.dname FROM emp e,dept d WHERE e.deptno=d.deptno; -
如果不写关联关系
SELECT e.ename,d.dname FROM emp e,dept d;
笛卡尔积
- 当多表关联时,如果没有写关联条件,返回的结果集是这几张表条目数的乘积,这个乘积就叫做笛卡尔积 。
- 多数情况下,笛卡尔积是无意义的 (在分组赛中,每个队的每一个成员都要和另一只队的每个成员比一次)
- 非常耗费资源,要尽量避免。
课堂练习
1.查看在NEW YORK工作的员工
SELECT e.ename,d.loc
FROM emp e,dept d
WHERE e.deptno=d.deptno AND d.loc='NEW YORK';
2.查看工资高于3000的员工,名字,工资,部门名,所在地
SELECT e.ename,e.sal,d.dname,d.loc
FROM emp e,dept d
WHERE e.deptno=d.deptno AND e.sal>3000;
等值连接/内连接
- 语法
- SELECT * FROM A,B WHERE A.某字段=B.某字段;
- SELECT * FROM A JOIN B ON A.某字段=B.某字段;
- 完整版:
- SELECT * FROM A [inner] JOIN B ON A.某字段=B.某字段;
课堂练习
1.查看在new yORk工作的员工
-- 方法一
SELECT e.ename,d.loc FROM emp e,dept d WHERE e.deptno=d.deptno AND d.loc='NEW YORK';
-- 方法二
SELECT e.ename,d.loc FROM emp e JOIN dept d ON e.deptno=d.deptno WHERE d.loc='NEW YORK';
2.查看工资高于3000的员工,名字,工资,部门名,所在地
SELECT e.ename,e.sal,d.dname,d.loc
FROM emp e JOIN dept d ON e.deptno=d.deptno
WHERE e.sal>3000;
-
不满足连接条件的记录是不会在关联查询中被查询出来的
SELECT e.ename,e.sal,d.dname,d.loc,d.deptno FROM emp e JOIN dept d ON e.deptno=d.deptno;
左外连接
-
以 JOIN 左侧表作为基准表(驱动表—所有数据都会被显示出来,不管是否符合连接条件),那么当该表中某条记录不满足连接条件时,来自右表的字段全部为null;
-
语法 SELECT * FROM A LEFT JOIN B ON 连接条件;
SELECT e.ename,e.sal,d.dname,d.loc,d.deptno
FROM dept d LEFT JOIN emp e ON e.deptno=d.deptno;
右外连接
-
以 JOIN 右侧表作为基准表(驱动表–所有数据都会被显示出来,不管是否符合连接条件),那么当该表中某条记录不满足连接条件时,来自左表的字段全部为null;
-
语法 SELECT * FROM A RIGHT JOIN B ON 连接条件;
SELECT e.ename,e.sal,d.dname,d.loc,d.deptno
FROM emp e RIGHT JOIN dept d ON e.deptno=d.deptno;
关联查询数据案例
代码实践
-- 查询出所有可以匹配的商品分类及商品数据
SELECT *
FROM t_item t1 JOIN t_item_category t2 ON t1.category_id=t2.id;
-- 查询出所有的分类,以及与之匹配的商品
SELECT *
FROM t_item t1 RIGHT JOIN t_item_category t2 ON t1.category_id=t2.id;
-- 查询出所有的商品,以及与之匹配的分类
SELECT *
FROM t_item t1 LEFT JOIN t_item_category t2 ON t1.category_id=t2.id;
课堂练习
1.每个部门的人数,根据人数排序
SELECT deptno,COUNT(*) c
FROM emp
WHERE deptno IS NOT NULL
GROUP BY deptno
ORDER BY c;
注意:是否需要判断字段为空要根据具体的业务需求,一般按什么分组什么不能为null,还和表的结构中该字段是否可以为空等有关,很多时候数据库里的字段是有约束的,代码里判断是为了防止异常。
2.每个部门中,每个主管的手下人数
SELECT deptno,mgr,COUNT(*) c
FROM emp
WHERE deptno IS NOT NULL AND mgr IS NOT NULL
GROUP BY deptno,mgr
ORDER BY deptno,c;
3.每种工作的平均工资
SELECT job,AVG(sal) FROM emp GROUP BY job ORDER BY AVG(sal);
4.每年的入职人数
SELECT EXTRACT(YEAR FROM hiredate) YEAR,COUNT(*) c FROM emp GROUP BY YEAR ORDER BY c;
5.少于等于3个人的部门(部门ID,部门人数,提高:部门名称)
-- 部门ID,部门人数
SELECT deptno,COUNT(*) c
FROM emp
WHERE deptno IS NOT NULL
GROUP BY deptno HAVING c<=3;
-- 部门ID,部门人数,部门名称
SELECT e.deptno,d.dname,COUNT(e.ename) c
FROM emp e JOIN dept d ON e.deptno=d.deptno
WHERE e.deptno IS NOT NULL
GROUP BY e.deptno HAVING c<=3;
6.拿最低工资的员工信息
SELECT * FROM emp WHERE sal=(SELECT MIN(sal) FROM emp);
7.只有一个下属的主管信息
SELECT mgr FROM emp WHERE mgr IS NOT NULL GROUP BY mgr HAVING COUNT(*)=1;
8.平均工资最高的部门编号
-- 方法一:
SELECT deptno,AVG(sal)
FROM EMP
GROUP BY deptno
HAVING AVG(sal)=(
SELECT MAX(dept.AVG) FROM (SELECT AVG(sal) AVG FROM EMP GROUP BY deptno) dept);
-- 方法二:
SELECT DEPTNO, AVG(IFNULL(SAL, 0))
FROM EMP
GROUP BY DEPTNO
HAVING AVG(IFNULL(SAL, 0)) >= ALL(SELECT AVG(IFNULL(SAL, 0)) FROM EMP GROUP BY DEPTNO);
补充:ALL(list)、ANY(list)、SOME(list)
- ANY、ALL、SOME 是配合>,>=,<,<=使用的;
- SELECT * FROM T2 WHERE N>ALL (SELECT N FROM T1)
- ALL 父查询中的结果集大于子查询中每一个结果集中的值,则为真
- SELECT * FROM T2 WHERE N>ANY(SELECT N FROM T1)
- ANY 父查询中的结果集大于子查询中任意一个结果集中的值,则为真
- SELECT * FROM T2 WHERE N>SOME(SELECT N FROM T1)
- SOME 和 ANY 一样。
9.下属人数最多的人,查询其个人信息
SELECT * FROM EMP
WHERE empno=(
SELECT mgr FROM EMP GROUP BY mgr HAVING COUNT(*)=(
SELECT MAX(mgr.COUNT) FROM (
SELECT COUNT(*) COUNT FROM EMP GROUP BY mgr)mgr));
注意:
数据库出错:ERROR 1248 (42000): Every derived TABLE must have its own alias,每个派生表必须有自己的别名,使用派生表和里面的数据的时候必须加。
10.拿最低工资的人的信息
SELECT * FROM emp WHERE sal=(SELECT MIN(sal) FROM emp);
11.最后入职的员工信息
SELECT * FROM emp WHERE hiredate=(SELECT MAX(hiredate) FROM emp);
12.工资多于平均工资的员工信息
SELECT * FROM emp WHERE sal>(SELECT AVG(sal) FROM emp);
13.查询员工信息,部门名称
SELECT e.*,d.dname FROM emp e JOIN dept d ON e.deptno=d.deptno;
14.员工信息,部门名称,所在城市
SELECT e.*,d.dname,d.loc FROM emp e JOIN dept d ON e.deptno = d.deptno;
15.DALLAS 市所有的员工信息
SELECT e.*,d.loc FROM emp e JOIN dept d ON e.deptno=d.deptno WHERE d.loc='DALLAS';
16.按城市分组,计算每个城市的员工数量
SELECT d.loc,COUNT(e.ename)
FROM EMP e JOIN Dept d ON e.deptno=d.deptno
GROUP BY d.loc;
17.查询员工信息和他的主管姓名
18.员工信息,员工主管名字,部门名
19.员工信息,部门名,和部门经理
20.员工和他所在部门名
SELECT e.*,d.dname FROM emp e JOIN dept d ON e.deptno=d.deptno;
21.案例:查询emp表中所有员工的编号,姓名,职位,工资以及工资的等级,根据工资的等级进行升序排列
SELECT e.empno,e.ename,e.job,e.sal,s.grade FROM emp e LEFT JOIN salgrade s ON e.sal BETWEEN s.losal AND s.hisal ORDER BY s.grade;
22.案例:查询emp表中所有员工的编号,姓名,职位,工资以及该员工上级领导的编号,姓名,职位,工资
SELECT e.*,d.* FROM emp e LEFT JOIN dept d ON e.deptno=d.deptno WHERE e.ename NOT LIKE '%K%';
23.案例:查询emp表中名字中没有字母’K’的所有员工的编号,姓名,职位以及所在部门的编号,名称,地址
SELECT e.empno,e.ename,e.job,d.deptno,d.dname,d.loc
FROM emp e LEFT JOIN dept d ON e.deptno=d.deptno
WHERE e.ename NOT LIKE '%K%';
24.案例:查询dept表中所有的部门的所有的信息,以及与之关联的emp表中员工的编号,姓名,职位,工资
SELECT d.*,e.empno,e.ename,e.job,e.sal FROM emp e RIGHT JOIN dept d ON e.deptno=d.deptno
25.案例:查询emp表中所有员工的编号,姓名,职位,工资以及工资的等级,该等级的最低工资,按照员工的编号进行升序排列。
SELECT e.empno,e.ename,e.job,e.sal,s.grade,s.losal
FROM emp e LEFT JOIN salgrade s ON e.sal BETWEEN s.losal AND s.hisal
ORDER BY e.empno;
五、自连接、自关联查询、多对一关联、多对多关联、权限管理
自连接/自关联查询
-
自连接,当前表的一条记录可以对应当前表自己的多条记录。
-
自连接是为了解决同类型数据,但是又存在上下级关系的树状结构数据时使用。
-
例如:
-
把emp当成两张表,一张是员工,一张是领导
-
查询员工名及对应的领导名
SELECT e1.ename,e2.ename FROM emp e1,emp e2 WHERE e1.empno=e2.mgr;- 查看’SMITH’上司在哪个城市工作
SELECT e.ename,m.ename,d.loc FROM emp e JOIN emp m ON e.mgr=m.empno JOIN dept d ON m.deptno=d.deptno WHERE e.ename='SMITH';- 查询员工信息和他的主管姓名
SELECT e.*,m.ename FROM emp e JOIN emp m ON e.mgr=m.empno;- 员工信息,员工主管名字,部门名
SELECT e.*,m.ename,d.dname FROM emp e JOIN emp m ON e.mgr=m.empno JOIN dept d ON m.deptno=d.deptno; -
-
案例
- 查询emp表中所有员工的编号,姓名,职位,工资以及该员工上级领导的编号,姓名,职位,工资
SELECT e.*,m.* FROM emp e LEFT JOIN emp m ON e.mgr=m.empno;
设计表结构的一些基本原则
多对一关联(一对多)
-
学生与班级
-
员工和部门
-
例如:多个学生对应一个班级,学生中是存外键,班级中存主键。
-
设计方案,在多(N)中增加一个字段(外键),保存1的主键,形成主外键关系。
多对多关联
- 学生和课程
- 角色和功能
- 设计方案,增加中间表,保存双方的主键(中间表和另外两张表都是一对多的关联关系)
连接方式和关联关系的区别
- 连接方式是匹配数据的方式,是具体实现管理的语法,它能实现任何关联关系的数据查询–sql语句是语法。
- 关联关系是逻辑角度阐述两张表的关系,在这个关系的基础上,可以用任何连接方式查询出相关数据–是设计表的时候的逻辑。
数据库设计之权限管理
-
什么是权限管理?对用户访问软件的权利进行限制的手段
-
如何实现权限管理
- 设计3张表:用户表,角色表,功能表。
权限管理表实现
用户表:
-- 创建表
CREATE TABLE user(
uid INT AUTO_INCREMENT,
uname VARCHAR(100),
create_TIME TIMESTAMP,
PRIMARY KEY(uid)
);
-- 插入数据
INSERT INTO user VALUES(NULL,'张三',now());
INSERT INTO user VALUES(NULL,'李四',now());
INSERT INTO user VALUES(NULL,'王五',now());
角色表:
-- 创建表
CREATE TABLE role(
id INT AUTO_INCREMENT,
name VARCHAR(100),
create_TIME TIMESTAMP,
PRIMARY KEY(id)
);
-- 插入数据
INSERT INTO role VALUES(NULL,'管理员',now());
INSERT INTO role VALUES(NULL,'店小二',now());
INSERT INTO role VALUES(NULL,'普通用户',now());
中间表:
-- 创建表
CREATE TABLE user_role(
id INT AUTO_INCREMENT,
user_id INT,
role_id INT,
PRIMARY KEY(id)
);
-- 插入数据
INSERT INTO user_role VALUES(NULL,1,3);
INSERT INTO user_role VALUES(NULL,2,3);
INSERT INTO user_role VALUES(NULL,3,3);
-
查询用户以及他所对应的角色
SELECT u.uid,u.uname,r.name FROM user u JOIN user_role ur ON u.uid=ur.user_id JOIN role r ON r.id=ur.role_id; -
查询张三对应的角色
SELECT u.uid,u.uname,r.name FROM user u JOIN user_role ur ON u.uid=ur.user_id JOIN role r ON r.id=ur.role_id WHERE u.uname='张三';
功能表:
-- 创建表
CREATE TABLE work(
id INT PRIMARY KEY AUTO_INCREMENT,
rid INT,
work_item VARCHAR(100)
);
-- 插入数据
INSERT INTO work VALUES(NULL,1,'对用户信息,商品信息,订单信息,角色信息等后台数据进行操作');
INSERT INTO work VALUES(NULL,2,'对商品信息,订单信息等后台数据进行操作');
INSERT INTO work VALUES(NULL,3,'浏览商品,购买商品');
-
查询user表中所有用户可以执行的操作
SELECT u.uname,w.work_item FROM user u JOIN user_role ur ON u.uid=ur.user_id JOIN role r ON r.id=ur.role_id JOIN work w ON w.rid=r.id; -
查看张三可以进行的操作
SELECT u.uname,w.work_item FROM user u JOIN user_role ur ON u.uid=ur.user_id JOIN role r ON r.id=ur.role_id JOIN work w ON w.rid=r.id WHERE u.uname='张三';
六、视图、索引、约束、事务
视图
视图概述
-
视图是一张虚拟表,使用方法和使用表一样
-
视图不是真实存在的表
-
视图中对应一个SELECT语句的查询结果集,视图的最重要的作用其一是可以让select子查询语句重复使用很多次
-
创建视图的语法
- CREATE VIEW 视图名 as 子查询;
CREATE VIEW v_emp_10 AS SELECT empno,ename,deptno FROM emp WHERE deptno=10; -
使用视图的目的:简化sql语句的复杂程度、重用子查询
查看视图
- SELECT * FROM 视图名
SELECT * FROM v_emp_10;
-- 结果等价于
SELECT * FROM (SELECT empno,ename,deptno FROM emp WHERE deptno=10) t;
注意:
- 视图本身不包含数据;
- 视图只是映射到基表的一个查询语句;
- 当基表数据发生变化时,视图显示的数据也随之发生变化;
- 如果创建视图时,子查询起了别名,那么视图只认识别名。
修改视图
-- 先创建视图
CREATE VIEW v_emp_10_1
AS
SELECT empno a1,ename a2,deptno a3 FROM emp WHERE deptno=10;
-- 修改视图
CREATE OR REPLACE VIEW v_emp_10_1
AS
SELECT empno id,ename name,deptno FROM emp WHERE deptno=10;
视图的分类
-
视图分为
简单视图和复杂视图。 -
简单视图:创建视图的子查询中,不含有关联查询,查询的字段不包含函数和表达式,没有分组,没有去重。 -
反之就是
复杂视图。
视图数据的操作
-
对视图进行DML操作,只能针对简单视图可以使用:
-
INSERT INTO v_emp_10_1 VALUES(2001,‘lily’,10);
-
对视图进行DML操作,要遵循基表的约束,不然会失败。
-- 视图只能看到10号部分,但是通过视图插入了20号部门的员工,数据是偷渡进去的,对基表进行了污染 INSERT INTO v_emp_10_1 VALUES(2002,'lilei',20); -
对视图的操作就是对基表的操作,操作不当会对基表产生数据污染。
-- 不是数据污染,因为操作的是自己的数据 UPDATE v_emp_10_1 SET name="bbb" WHERE deptno=10; UPDATE v_emp_10_1 SET deptno=20; -- MySQL 更新视图不会数据污染,但是 Oracle 会数据污染 UPDATE v_emp_10_1 SET name="bbb" WHERE deptno=30; -- 删除视图中的数据,不会产生数据污染 DELETE FROM v_emp_10_1 WHERE deptno=30;
总结:
- 在MySQL中,通过视图能够产生数据污染,只有INSERT;
数据污染的管理方案:
- 为视图增加检查选项,可以保证对视图进行DML操作后,视图必须对改变的部分可见(不可见的不许改),否则不允许进行DML操作,这样避免数据污染。
CREATE OR REPLACE VIEW v_emp_10_1
AS
SELECT empno id,ename name,deptno
FROM emp
WHERE deptno=20 with check option;
--增加检查选项
INSERT INTO v_emp_10_1 VALUES(2003,'lili', 20); -- 成功操作
INSERT INTO v_emp_10_1 VALUES(2003,'hanmeimei', 30); -- 操作错误
视图的作用:
-
视图简化复杂查询语句,重用子查询
-
简化复杂查询
-
如果需要经常执行某项复杂查询,可以基于这个复杂查询创建视图
-
-
限制数据访问
-
视图本质上就是一条SELECT语句
-
当访问视图时,只能访问到SELECT语句中涉及到的列
-
对基表中其它列起到安全和保密的作用
-
工作中,对视图一般只进行DQL操作,不进行DML操作。
复杂视图
-
创建一个复杂视图
- 创建一个含有公司部门工资情况的视图,内容如下:
- 部门编号,部门名称,部门的最高,最低,平均工资,工资总和
CREATE VIEW v_dept_sal as SELECT d.deptno,d.dname, MAX(e.sal) max_sal, MIN(e.sal) min_sal,AVG(e.sal) avg_sal, SUM(e.sal) sum_sal FROM emp e JOIN dept d ON e.deptno=d.deptno GROUP BY d.deptno; -
查询出 比自己所在部门的平均工资 高的员工
SELECT e.ename,e.sal,e.deptno,v.avg_sal FROM emp e,v_dept_sal v WHERE e.deptno=v.deptno AND e.sal>v.avg_sal;
删除视图
-
DROP VIEW 视图名;
DROP VIEW v_emp_10_1;
索引
索引概述
-
用来加快查询的技术有很多,最重要的就是索引
-
通常索引可以大幅度提高查询速度
-
如果不使用索引,mysql会从第一条数据开始,读完整个表,直到找到相关的数据,表越大,花费时间越多(时间主要花在磁盘io)
-
索引可以用来改善性能,但是有时索引也可以降低性能
-
索引的统计和应用是数据库自动完成的
-
使用索引的位置
- WHERE deptno=10 会使用索引
- GROUP BY 会使用索引(只要有 BY 语句就会走索引)
- ORDER BY 会使用索引
- DISTINCT 会使用索引
- LIKE 不会使用索引
创建索引
-
CREATE INDEX 索引名 ON 表名(字段);
CREATE INDEX idx_empe_name ON emp(ename); -
只要数据库认为可以使用某个已经创建的索引,索引就会自动应用
-
我们只需要决定要不要给某张表的某个字段创建索引
mysql innodb B+TREE 3次磁盘IO就可以找到
复合索引
CREATE INDEX idx_emp_job_sal ON emp(job,sal);
应用于:
SELECT * FROM emp ORDER BY job,sal;
- 里面的参数必须一致,否则索引不认
创建表的时候加索引
CREATE TABLE mytable(
id INT NOT NULL,
uname VARCHAR(6) NOT NULL,
INDEX idx_mytable_uname (uname)
);
添加表的索引
ALTER TABLE mytable ADD INDEX idx_mytable_uname1 (uname);
删除索引
DROP INDEX idx_mytable_uname1 ON mytable;
索引总结
- 经常出现在WHERE子句中的列需要创建索引;
- 经常出现在GROUP BY子句中列需要创建索引;(只要有 BY 语句就会走索引)
- 经常出现在ORDER BY子句中列需要创建索引;
- 经常出现在DISTINCT后面的列也需要创建索引;
- 如果创建的是复合索引,索引的字段顺序和关键字顺序要一致,不一致索引不认;
- 为经常做为表连接条件的列创建索引。
加入索引后,虽然提高了查询效率,但是降低了插入效率
- 不要在经常做DML操作的表和列上建立索引;
- 不要在小表上创建索引;
- 索引不是越多越好;
- 删除很少使用的或不合理的索引。
MySQL 约束
主键约束(PRIMARY KEY)
-
主键列不允许重复,不允许为空(NULL)
-
创建主键约束
-
列级语法
CREATE TABLE student1( id INT PRIMARY KEY, name VARCHAR(20) ); -
表级语法 CONSTRAINT 约束名 约束类型(列名)
CREATE TABLE student( id INT, name VARCHAR(20) , CONSTRAINT pk_stu_id PRIMARY KEY(id) );注意:没有约束名的约束删不掉,如果不起约束名系统会自动起一个约束名。
CREATE TABLE student2( id INT, name VARCHAR(20), PRIMARY KEY(id) );
-
在表创建之后,添加主键约束(效果相当于表级语法)
-
ALTER TABLE student ADD PRIMARY KEY(id);
-
ALTER TABLE student MODIFY id INT PRIMARY KEY;(Oracle可以使用,mysql不一定可以使用)
删除主键约束
-
ALTER TABLE student DROP PRIMARY KEY;
-
ALTER TABLE student MODIFY id INT;(mysql不起作用,Oracle可以)
主键自增
CREATE TABLE t1(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(10)
);
INSERT INTO t1 VALUES(NULL,'aaa');
INSERT INTO t1 VALUES(10,'bbb');
DELETE FROM t1 WHERE id=13;
主键自增长的细节
-
插入数据时,使用null,自动增长;
-
插入数据时,如果插入一个比较大数,那么下次自增长从这个数开始累加;
-
删除末尾已经存在的条目,这个条目的id,不会再次在表中通过自增长出现,如果删除尚未出现的主键数,这个条目的id还会自增长出该主键数
外键约束(FOREIGN KEY)
-
工作中,除非特殊情况,一般不使用外键,使用逻辑外键
-
外键约束是保证一个或两个表之间的参照完整性,保持数据一致
-
表的外键可以是另一张表的主键,也可以是唯一的索引
-
外键可以重复,可以是null
-
使用外键约束的条件
- 父表和子表必须使用相同的存储引擎;
- 存储引擎必须是innodb;
- 外键列和参照列必须具有相似的数据类型,数字长度,若是有符号,必须相同----但是字符类型长度可以不同;
- 外键列和参照列必须创建索引,如果外键列不存在索引,mysql自动为其创建。
创建外键约束
-
注意,虽然mysql支持外键列级语法创建外键,但是无效
-
表级语法创建外键
CONSTRAINT 外键约束名 FOREIGN KEY(本表列名) REFERENCES 目标表(目标列);
代码实践
-- 创建表
CREATE TABLE teacher_table(
teacher_id INT AUTO_INCREMENT,
teacher_name VARCHAR(255),
PRIMARY KEY(teacher_id)
);
-- 插入数据
INSERT INTO teacher_table VALUES(NULL,'t1');
INSERT INTO teacher_table VALUES(NULL,'t2');
INSERT INTO teacher_table VALUES(NULL,'t3');
INSERT INTO teacher_table VALUES(NULL,'t4');
-- 创建表
CREATE TABLE student_table(
student_id INT AUTO_INCREMENT PRIMARY KEY,
student_name VARCHAR(255),
java_teacher INT,
FOREIGN KEY(java_teacher) REFERENCES teacher_table(teacher_id)
);
-- 插入数据
INSERT INTO student_table VALUES(NULL,'s1',1);
INSERT INTO student_table VALUES(NULL,'s2',1);
INSERT INTO student_table VALUES(NULL,'s3',2);
INSERT INTO student_table VALUES(NULL,'s4',3);
注意:当一个表的字段作为另一个表的字段的外键时,有外键的条目不能够被删除。
(实际开发过程当中,尽量不要使用外键)
唯一约束(UNIQUE)
-
指定表中某一列或者多列不能有重复的值
-
唯一约束可以保证记录的唯一性
-
唯一约束的字段可以为空值
-
每张表可以存在多个唯一约束的列
创建唯一约束
CREATE TABLE t2(
name VARCHAR(20) unique
);
CREATE TABLE t3(
a INT,
b INT,
CONSTRAINT uk_name_pass unique(a)
);
CREATE TABLE temp(
id INT NOT NULL,
name VARCHAR(20),
password VARCHAR(20),
CONSTRAINT uk_name_pwd unique(name,password)---用户名和密码的组合不能重复
);
删除约束
ALTER TABLE temp DROP INDEX uk_name_pwd;
创建表之后再添加唯一约束
-- 单/多字段约束
ALTER TABLE temp ADD unique uk_name_pwd(name,password);
-- 单字段约束
ALTER TABLE temp MODIFY name VARCHAR(25) unique;
非空约束(NOT NULL)
CREATE TABLE t4(
id INT NOT NULL,
name VARCHAR(25) NOT NULL default 'abc'
);
表建好后,修改非空约束
-- 去除非空约束
ALTER TABLE t4 MODIFY id INT NULL;
-- 增加非空约束
ALTER TABLE t4 MODIFY id INT NOT NULL;
默认约束(DEFAULT)
-
用于设定列的默认值
-
要求
- 定义的默认值的常量,必须与这个列的数据类型,精度等相匹配;
- 每个列只能定义一个default约束。
CREATE TABLE t5( id INT , name VARCHAR(20), sex CHAR(10) default '男' ); INSERT INTO t5 (id,name) VALUES(1,'aaa');
检查约束(CHECK)
-
检查约束的作用,验证数据
CREATE TABLE t6( id INT, name VARCHAR(20), age INT, check(age>20) ); INSERT INTO t6 VALUES(1,'aaa',15); -
mysql不支持检查约束,但是可以创建,并且不报错,只不过没有任何效果。
-
Oracle支持检查约束。
什么是事务
- 事务是一组原子性的sql查询,在事务内的语句,要么全都执行,要么全都不执行
事务的 ACID 性质
-
原子性:最小的不可分割的业务单元(Atomic)
-
一致性:都执行或者都不执行,保持同一个状态(Consistent)
-
隔离性:多个事务并发,相互不影响 (Isolated)
-
持久性:COMMIT之后,数据保存在数据库中 (Durable)
MySQL事务
-
使用事务的要求:
- 在mysql众多的引擎中,innodb 和NDB Cluster支持事务;
- mysql默认自动提交事务,想手动提交,需要把默认提交关闭。
-
关闭默认提交
SHOW variables LIKE 'autoCOMMIT'; -- 查看自动提交是否开启 SET autoCOMMIT=0; -- 关闭自动提交,0是关闭,1是开启 START TRANSACTION; -- 开启事务 -
业务逻辑
COMMIT; -- 中间的代码都执行 ROLLBACK; -- 中间的代码都不执行
事务案例
CREATE TABLE account(
id INT,
name VARCHAR(20),
money FLOAT
);
INSERT INTO account VALUES(1,'aaa',1000);
INSERT INTO account VALUES(2,'bbb',1000);
START TRANSACTION; -- 开启事务
UPDATE account SET money=money-100 WHERE name='aaa';
UPDATE account SET money=money+100 WHERE name='bbb';
-
此时没有输入COMMIT,直接关闭终端
-
再次打开终端,把自动提交关闭
-
查询account账户,之前的操作回滚了
-
再次开启事务
-
完成两次update
-
输入COMMIT—>数据真正保存在表中
课堂练习
1.案例:创建一张表customer2, id number(4), name VARCHAR2(50), password VARCHAR2(50), age number(3), address VARCHAR2(50);
修改customer2表的时候设置主键约束 pk_id_name_cus2 修饰 id 和 name列。
2.案例:创建一张book3表,id number(4), name VARCHAR2(50), author VARCHAR2(50), pub VARCHAR2(50), numinput number(10);
修改book3的时候,设置主键约束 pk_id_name_b3 修饰 id 和 name 列,设置唯一约束 uq_author_pub_b3 修饰author和pub列
3.案例:删除temp中的唯一约束uk_name_pwd
4.案例:在book表中author和pub列上添加索引index_author和index_pub
5.案例:删除book中在pub和author上的索引
6.案例:创建一个视图emp_view1,查询emp表中所有的数据,查询语句作为视图emp_view1
7.案例:创建一个视图dept_view,查询dept表中所有的数据,查询语句作为视图dept_view
8.案例:创建一个视图emp_view2,查询emp表中所有员工的编号,姓名,职位,工资,上级领导的编号以及工资的等级,该等级的最低工资和最高工资,查询语句作为emp_view2
9.案例:查询emp表中10,20号部门员工的编号,姓名,职位,工资,所属部门的编号,使用查询语句来修改视图emp_view1
10.案例:删除视图emp_view1,emp_view2