【论文解读 MM 2017 | att-RNN】Multimodal Fusion with RNNs for Rumor Detection on Microblogs

论文题目:Multimodal Fusion with Recurrent Neural Networks for Rumor Detection on Microblogs
论文来源:MM 2017
论文链接:https://doi.org/10.1145/3123266.3123454
关键词:多模态融合,谣言检测,LSTM,注意力机制,microblog
文章目录
- 1 摘要
- 2 引言
- 3 模型
-
- 3.1 模型概览
- 3.2 文本和社交上下文的联合表示
- 3.3 图像的视觉表示
- 3.4 用于视觉表示的注意力
- 3.5 模型的训练
- 4 实验
- 5 总结
- References
1 摘要
本文解决的是谣言检测问题。提出使用注意力机制的RNN(att-RNN)融合多模态的特征:图像特征、文本特征、社交上下文特征,以用于谣言检测。
是第一个使用深度神经网络将社交网络上的多模态内容整合,以解决假新闻检测问题的工作。
具体来说,使用LSTM得到文本和社交上下文的联合特征,然后将图像特征与其合并。当融合视觉特征时,运用到了LSTM输出的neural attention。
在两个多模态谣言数据集(Weibo, Twitter)上进行实验,结果表明att-RNN利用多模态数据进行谣言检测的有效性。
2 引言
(1)现有方法的不足
现有方法大多采用hand-crafted特征,不能学习到复杂并且可扩展的文本或视觉特征。
On one hand, hand-crafted features in existing works are limited to learn complicated and scalable textual or visual features.
现有的多模态的方法是通过特征拼接或者取平均,实现特征的融合。这类融合方法太过简单,不能有效地结合不同模态的优势。
On the other hand, existing fusing methods are quite preliminary which could fail to e ectively combine the benefits from di erent modalities
(2)本文提出
考虑到上述的局限性,本文的动机在于利用多模态的内容,提出端到端的带有注意力机制的RNN,融合来自于文本、图像和社交上下文的特征,以完成谣言检测任务。
与传统的人工特征不同,本文采用的文本、视觉和社交上下文特征是使用深层神经网络得到的。
如图 2所示,作者使用RNN学习到文本和社交上下文的联合表示。使用预训练的深层CNN学习到图像的视觉特征。接着使用注意力机制捕获到视觉特征和文本/社交联合特征间的关联,将两者融合。
This network fuses features from three modalities and utilizes the attention mechanism for feature alignment.

3 模型
3.1 模型概览
将一个推文实例定义成三元组 I = { T , S , V } I={\{T,S,V}\} I={T,S,V},其中 T T T表示文本内容, S S S表示社交上下文, V V V表示视觉内容。本文提出的模型从这三种模态中获得特征 R T , R S , R V R_T, R_S, R_V RT,RS,RV,然后整合成 R I R_I RI,作为推文 I I I的表示。
首先,使用RN将文本和社交上下文特征混合生成联合表示 R T S R_{TS} RTS,使用CNN得到视觉特征 R V R_V RV。然后,在RNN每一个时间步输出都使用注意力进一步微调 R V R_V RV。在最后一步,将 R T S R_{TS} RTS和注意力聚合的 R V ′ R_{V}^{'} RV′拼接,作为最终的多模态表示 R I R_I RI。然后使用这一表示进行二元分类,判断推文的真假。
att-RNN模型的整体结构如图 2所示,有三个主要部分组成:
1)RNN sub-netowrk:学习文本特征和社交上下文特征的联合表示;
2)visual sub-network:生成视觉表示;
3)the neural-level attention part:使用RNN的输出来对齐视觉特征。
3.2 文本和社交上下文的联合表示
使用LSTM学习到文本和社交上下文的联合表示。

文本内容是单词序列: T = { T 1 , T 2 , . . . , T n } T={\{T_1, T_2, ..., T_n}\} T={T1,T2,...,Tn}, n n n表示单词个数。文本中的每个单词 T i ∈ T T_i\in T Ti∈T都表示为一个词嵌入向量。词嵌入是在给定数据集上进行无监督预训练得到的。
社交上下文指的是hash-tag topic, mention, retweets, 文本语义特征 例如情感极性。使用这些上下文形成社交上下文的初始表示 R S = [ s 1 , s 2 , . . . , s k ] T R_S=[s_1, s_2, ..., s_k]^T RS=[s1,s2,...,sk]T, k k k是社交上下文特征的维度, s i s_i si是第 i i i维的值。
通过一个全连接层(图 3中的soc-fc)将 R S R_S RS转换为和词嵌入向量维度相同的 R S ′ R_{S^{'}} RS′:
在每个时间步,LSTM将 R T i S = [ R T i ; R S ′ ′ ] R_{T_iS}=[R_{T_i};R_{S^{''}}] RTiS=[RTi;RS′′]作为输入,即第 i i i个单词的嵌入 R T i R_{T_i} RTi和转换后的社交上下文特征 R S ′ ′ R_{S^{''}} RS′′的拼接。对LSTM输出的每个单词的表示取平均,就得到文本和社交上下文的联合表示 R T S R_{TS} RTS。整个过程如图 3所示。
3.3 图像的视觉表示
visual sub-network将推文图像作为输入并生成视觉神经元(visual neurons)作为图像的特征。如图 2所示,前面一层和VGG-19有着同样的结构,然后作者在此之后添加了两个512-neuron全连接层(vis-fc1, vis-fc2),以为每个图像生成512-neuron视觉表示 R V = [ v 1 , v 2 , . . . , v 512 ] T R_V=[v_1, v_2, ..., v_{512}]^T RV=[v1,v2,...,v512]T。
visual sub-network可以先用辅助数据集进行微调,在和LSTM sub-netowrk联合训练时,只需要更新最后两个全连接层的参数。
其中, R V p R_{V_p} RVp是从预训练的VGG网络中得到的视觉特征, W v f 1 W_{vf_1} Wvf1第一层带有ReLU激活函数的全连接层的权重, W v f 2 W_{vf_2} Wvf2是第二层带有softmax函数的权重, ψ \psi ψ表示ReLU激活函数。
在模型中直接利用视觉和联合的社交-文本表示面临着一个挑战:一个表现可能会压倒另一个,从而导致最终的表示对这一模态有明显的倾向性。
One big challenge of directly utilizing the visual and joint social-textual representation in the model is that one representation will probably overwhelm the other, which results in the biased performance towards this modality.
为了最大化多模态特征的优势,需要共同学习不同模态下的对齐方法。在接下来的部分中,作者引入注意力机制,根据RNN在每个时间步的输出调整视觉表示,同时生成聚合的visual neurons。
3.4 用于视觉表示的注意力
作者假定谣言推文中的图像和文本/社交上下文具有一定的关联性。为了描述这些关联,作者以文本和社交上下文的联合表示的neuron为指导,提出了用于视觉特征的neuron-level注意力机制。
作者假定文本内容中的单词可能和图像中的一些语义概念有关联,作者的目的是自动地找到这些关联。具体来说,和单词有相似语义的visual neurons应该被赋予更多的权重。
作者提出的visual-neuron注意力机制对不同neurons对不同单词的贡献进行了加权。为了实现这一目标,利用LSTM在每个时间步输出的隐层状态 h m h_m hm作为指导。将 h m h_m hm和带有ReLU激活函数的全连接层相连,再和带有softmax函数的全连接层相连,以得到注意力向量 A m ∈ R 512 A_m \in \mathbb{R}^{512} Am∈R512,该向量和visual neurons R V R_V RV的维度一致。
其中 h m h_m hm是LSTM在第 m m m个时间步的隐层状态, W a f 1 W_{af_1} Waf1和 W a f 2 W_{af_2} Waf2是两个全连接层的权重, ψ \psi ψ是ReLU激活函数。文本中第 m m m个单词和图像间的关联计算如下。其中, A m ( i ) A_m(i) Am(i)是第 i i i个visual neuron的注意力值。
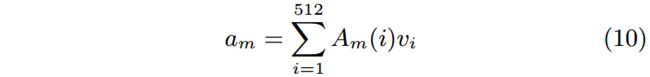
通过LSTM生成的注意力向量 A m A_m Am决定了那些visual neurons更重要。最终的视觉表示是一组映射值: R V ′ = [ a 1 , a 2 , . . . , a n ] R_{V^{'}}=[a_1, a_2, ..., a_n] RV′=[a1,a2,...,an], n n n是给定文本的单词数量。
需要指出的是,与传统的视觉识别任务相比,谣言检测任务中的高级视觉语义很难识别。注意模型中没有明确保证这种匹配关系学习的机制。但作者仍然假设,使用这样的注意力机制进行训练可以发掘一些隐式的关联,并且改善特征对齐。
3.5 模型的训练
目前为止,我们得到了文本和社交上下文的联合表示 R T S R_{TS} RTS,以及一个attention-aggregated视觉表示 R V ′ R_{V^{'}} RV′。将这两个特征进行拼接,就得到了给定推文的多模态表示 R I = [ R T S ; R V ′ ] R_I = [R_{TS}; R_{V^{'}}] RI=[RTS;RV′]。使用交叉熵定义第 m m m个推文的损失:

其中 R I m R^m_I RIm是第 m m m个推文实例的多模态表示; W s W_s Ws是线性模型softmax层的参数; l m l^m lm是第 m m m个推文的ground turth label,1表示不是谣言,0表示是谣言。
整个att-RNN模型使用batched SGD进行端到端的训练以最小化如下的损失函数,其中 N N N表示推文实例总数。

4 实验
(1)数据集
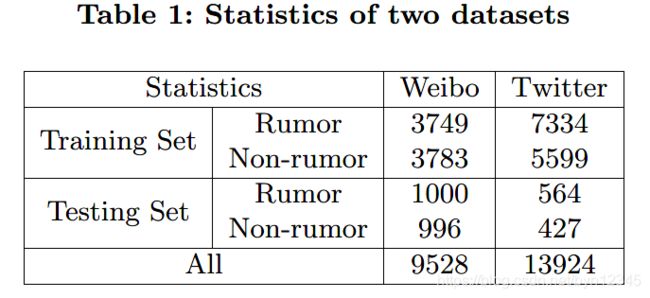
作者在[1]的基础上,构建了Weibo数据集和Twitter数据集。
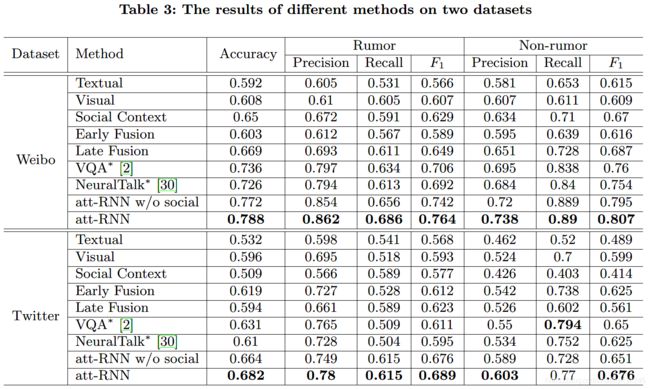
(2)实验结果
5 总结
本文提出使用带有注意力机制的RNN(att-RNN),融合文本、图像和社交上下文特征,以实现谣言检测任务。
对于给定的推文,首先使用LSTM融合其文本和社交上下文。然后再将这一联合表示与从预训练的深层CNN中得到的视觉特征进行融合。在融合过程中,利用LSTM在每个时间步的输出作为neuron-level注意力,以调节视觉特征。
在Weibo和Twitter两个数据集上进行了实验,和已有的基于特征的方法以及基于神经网络的多模态融合的方法相比,可以有效地基于多媒体内容实现谣言的检测。
References
[1] Christina Boididou, Katerina Andreadou, Symeon Papadopoulos, Duc-Tien Dang-Nguyen, Giulia Boato, Michael Riegler, and Yiannis Kompatsiaris. 2015. Verifying Multimedia Use at MediaEval 2015. In MediaEval 2015 Workshop, Sept. 14-15, 2015, Wurzen, Germany.