火山引擎李玉光:字节跳动大规模K8s集群管理实践

嘉宾 | 李玉光 整理 | 贾凯强
出品 | CSDN云原生
2022年5月31日,在CSDN云原生系列在线峰会第6期“K8s大规模应用和深度实践峰会”,火山引擎资深云原生架构师李玉光分享了《字节跳动大规模K8s集群管理实践》。
戳观看李玉光分享视频
![]()
字节跳动云原生体系
字节跳动内部云原生技术的使用贯穿组织技术体系各层面,整体如下图所示。
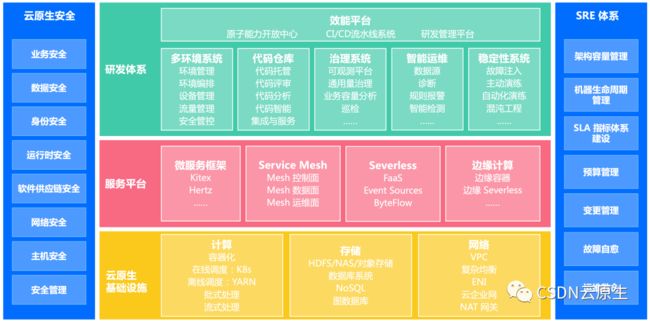
研发体系层:包括CI/CD流水线、可观测平台、研发效能平台、混沌工程平台等。
服务平台层:包括云原生框架体系、服务网格、无服务器计算以及边缘计算等。
基础设施层:包括容器管理平台、计算存储和网络的PaaS平台。
SRE体系:通过SRE整体能力的建设把研发体系到基础设施管理流程串联起来。
云原生安全:涵盖业务安全、身份安全、网络安全等云原生安全能力。
这些能力的建设主要根据业务需求逐步推进,演进过程如下图所示。
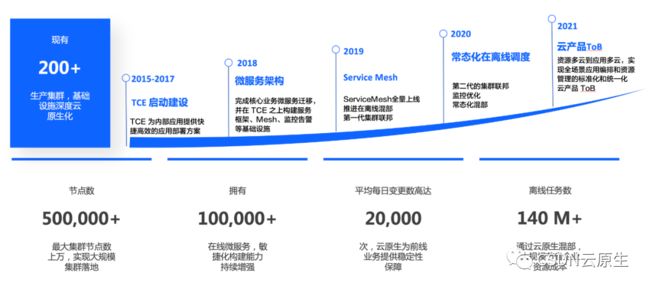
2015-2017年:主要业务为今日头条,面对各种新闻客户端应用的激烈竞争,敏捷迭代尽快将产品的功能推向市场十分重要。为了提供快捷高效的应用部署方案,公司在2016年启动TCE平台的建设。当时TCE专注于服务的生命周期管理,如新建、升级、回滚、高可用、弹性扩展的容器服务,如今TCE发展成庞大的私有云平台。
2018年:启动了Service Mesh的原型开发。当时字节跳动内部多语言版本造成微服务治理框架不一样,既无法做到统一管理,又会有很多重复造轮子的工作。为了统一公司内的工具体系,同时启动了计算PaaS和存储PaaS的建设,开始统一公司级别的SRE体系和监控中心建设。
2019年:公司级服务树实现统一,后续可以基于服务维度出账单,以应用视角管理资源。Service Mesh经过开发及试用阶段,有了全量推广。云基础视角来看,抖音在2018-2020年间发展快速,成本不断增加,服务器规模体量越来越大,团队关注重点转向资源利用率的提升,推进在离线混部架构;为应对大规模集群问题,第一代的集群联邦解决方案实施。从SRE的视角来看,平台集成了各种PaaS能力,包括数据、运维、监控等能力,构建了统一的部署监控、报警治理一体化的工具矩阵;“推广搜”的物理机服务与在线微服务进行全面融合,实现统一容器化调度并达到全量托管。
2020年:由于业务天然依赖边缘渲染,团队强化了边缘计算能力;各种底层软硬件也进行了优化,比如打造智能网卡、自研DPU、优化SSD控制器等;其次,为更好地在离线融合以及解决第一代集群联邦的问题,团队构建了第二代的集群联邦。继续推进在离线混部架构,通过自研的融合调度器丰富了混部调度能力和资源管控,进一步提升资源调度效率,实现了常态化混部。完成数据库、缓存等存储系统云原生化改造。在SRE体系上,由于已经有了工具基础,会关注如何更快速定位问题,因此进行了底层的容器监控优化,如利用eBPF实现内核级别的监控。同时对容器隔离进行了优化。
2021年:除了针对微服务框架、服务治理、编排调度、监控运维等方面架构的继续优化,最重要的是:云基础产品开始面向ToB,火山引擎正式推出公有云服务。
截至2021年底,字节跳动已经建设了完善的云原生基础设施:拥有200多个生产集群,共计50万节点,容器数超过1000万;拥有10万多在线微服务,平均每日变更数达2万次,离线任务数超过1.4亿。
![]()
字节跳动大规模K8s混合部署实践
字节跳动私有云平台TCE的底层使用K8s作为编排调度的系统,字节内部几乎所有无状态服务都以容器的形式部署在TCE上,无状态服务主要包括各种微服务和算法服务等。随着业务的增长,TCE上接管的服务数量越来越多,集群规模越来越庞大,导致了资源成本的不断增长,因此必然要关注集群的整体资源利用率的问题。
为了解决资源利用率的问题,首先要对业务的流量特点进行分析。
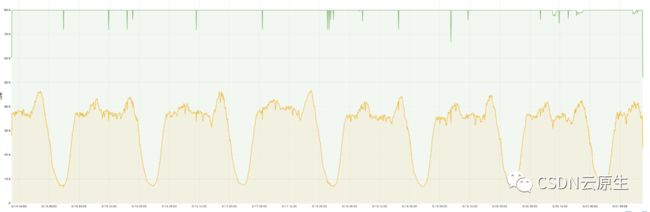
如上图所示,在线业务的一个特点是每天请求量有明显波峰波谷;同时,业务会倾向于申请比实际需求更多的资源以确保服务的稳定性,但这也会导致集群的整体资源利用率特别低,造成大量的资源浪费。
解决思路
在线业务动态超售
针对上述发现,实际做法是实现在线业务的动态超售。动态超售是指动态控制和调整服务的资源申请量以减少冗余资源,服务级别动态超售的目标是在不影响业务QoS的前提下提升服务的资源利用率。实现方式主要包含以下几方面。
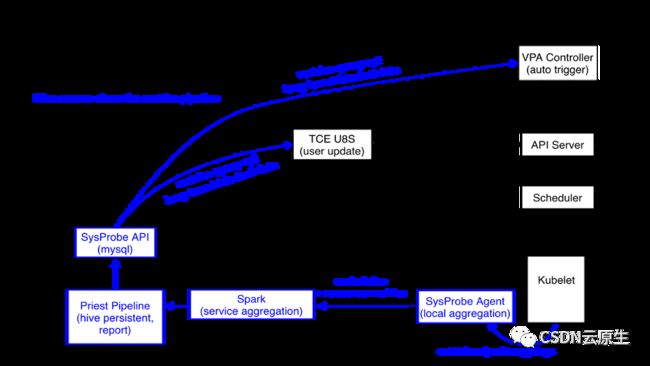
资源控制:通过SysProbe组件,收集实例级别的容器资源利用率Metrics和Pod的meta信息,并将这些推送到Spark里面做聚合分析。之后每次服务上线,业务会通过TCE Platform提交一个DeploymentRequest,包含了业务配置的资源申请,TCE U8S组件会去查询SysProbe提供的API,根据每个应用的历史数据计算出其实际需求的资源并作出相应的控制。
资源调整:集群里很多长期不升级的服务占用了不少资源,而且资源利用率非常低,但无法通过第一种方式对其调整。因此通过VPA Controller watch所有的deployment,一旦发现有长期没有更新的deployment,就会主动修改其request并进行更新。
弹性伸缩:最后结合Pod的弹性伸缩来回收流量低谷时期的资源,从而大幅提升资源利用率。
在离线业务混部
下一步需要考虑的是如何利用这部分在线业务节省下来的资源。因为所有在线业务的低谷时段几乎都是吻合的,比如在凌晨之后,一般所有在线APP的使用频率都会减少,因此不能通过扩容在线业务的方式来消耗这部分资源。但字节内部存在很多离线任务需要大量的计算资源去进行处理,例如视频转码、模型训练等。这些离线任务对资源的需求与时间无关,天然适合使用在线闲置资源,开启在离线混部架构,能够把在线业务的闲置资源出让给离线业务使用。
字节的大数据业务都是基于Yarn体系的,在线应用和一些AI应用部署在K8s上,最开始的时候我们把Node manager做了一些修改之后和Kubelet一起部署在了K8s的node上。总体来说,整个平台是由以K8s核心控制面为主的在线编排调度系统,以Yarn为主的离线调度系统,以及SysProbe组件为中心Hybrid Controller构成。离线业务混部示意图如下:
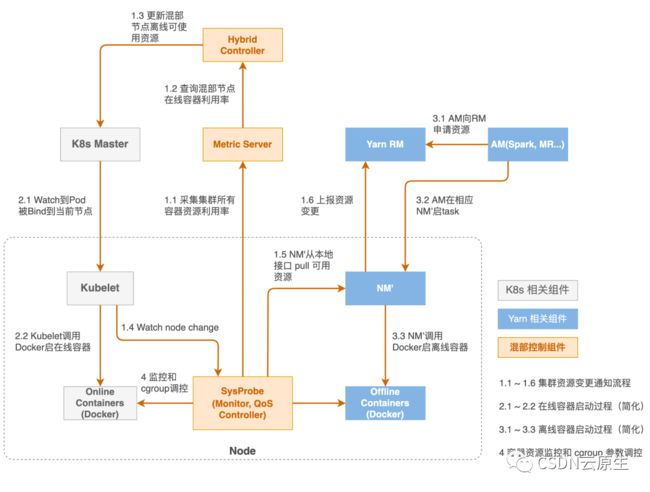
在离线业务混部要实现的效果是:在优先满足在线微服务需求的前提下,把剩余资源尽可能多地供给离线业务使用;当在线业务需要更多资源时,可以快速地调回离线侧的资源。
从具体实现角度来说,通过SysProbe系统监控,获取单机层面的各种容器的资源使用情况;通过机器学习算法,推导出该集群上可以出让给离线侧去使用的资源;将这些信息传给Node manager,动态上报到中心的RM进行资源的统一展示。Hybrid Controller主要是负责集群整体的容灾降级策略和水位控制相关的事务。
整个调度系统分为三个层面构建:集群层面、节点层面和内核层面,分别承担了三种资源调度的角色。
集群层面:K8s Scheduler和Yarn的ResourceManager负责完成集群层面的调度,把容器调度到合适的节点。
节点层面:但当节点层面在线业务发生QoS抖动时,需要做出更快的响应,此时分钟级的调度响应延迟通常是不能接受的。因此,系统在节点层面进行处理,提供了Sysprobe的QoS Controller组件,动态实时地调整节点的实际资源分配。当在线业务发生QoS抖动,需要更多资源时,能够快速将离线资源回收回来,实现秒级响应。
内核层面:由于SysProbe是处于用户态的角色,通常也会受到单机层面高负载等异常情况的影响,因此需要在内核级别,比如在CPU的调度器、IO的调度器上做更深度的定制。这样能够实现更强的系统层面的能力,更好地兼顾延迟敏感型的在线微服务和吞吐型离线任务对于计算资源和网络带宽资源的需求,达到整体效能的最大化。
由此,初步的在离线混部完成,但还有一些需要继续优化的内容。比如对于系统而言,资源抽象还不够完整,只有部分类型的离线业务利用了这些不稳定的资源;系统各自独立,在一个node上既部署了Kubelet负责在线业务,又部署了Node manager负责离线任务,资源管理体系分离,上层平台独立建设,底层服务器供给运维分开,导致更大范围的共池复用比较困难。
统一资源池,常态混部
为应对上述挑战,新的融合调度器被开发出来。其能统一管理在离线资源,后续也能支持更多资源的管理和更多类型任务的调度,如下图所示。
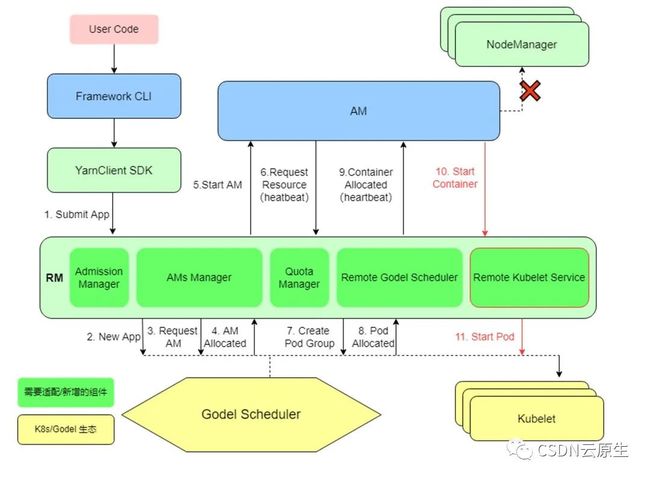
首先需要通过K8s管理离线应用,这就需要支持Yarn的Gang Scheduler以及其他调度算法。因此选择去掉Yarn的Slave节点相关的管控逻辑,将其Resource Manager Operator化;相应的调度逻辑下沉到自研K8s调度器Godel Scheduler,只保留对应的离线作业生命周期管理以及周边功能,进而实现离在线无缝迁移和并池的能力;将公司所有Yarn上的存量大数据业务无缝迁移至新的调度平台,来实现在离线资源池的统一。最后,获取了单集群的在离线统一调度能力后,就可以通过集群联邦对多个集群的在离线资源进行统一管理。
联邦化:Global Scheduling和Quota
在2019年引入了第一代联邦系统,实现了超大规模集群管理,提供了以下能力:
用户体验:通过资源池化,SRE团队不需要管理自己的集群节点,降低维护成本;集群版本升级在mumber集群层面实现,用户无感知;
自动容灾:集群或者机房故障时,自动实现全量容器的迁移;
运维效率:支持集群快速升级换代、上线下线;
多云多集群:自建IDC和公有云IaaS快速接入。
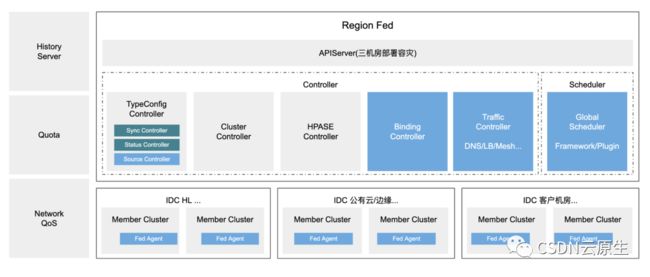
随着更大范围的离线和在线的融合需求,联邦系统演进到了第二代。第二代联邦系统的升级主要体现在:
轻量级多集群管理:用户看到的是单集群的视角,又能够保证member集群层面的资源复用。实现了原生Cluster和Namespace范围的资源访问隔离,以及K8s原生对象和CRD对象的创建和访问的隔离。
联邦化Workload:能够实现全场景应用联邦化,一般社区的联邦方案,通常只能接入有限的负载类型;而字节内部实现了各种离线大数据场景、机器学习场景等业务的统一接入,结合全局的资源管控和优化,能够实现进一步的调度;同时,方案融合了离线和在线的容灾体系,进一步实现整个数据中心层面的资源共享和复用。
调度系统终态视图
基于上述的调整和升级,调度系统最终演进成如下图所示的分层架构。
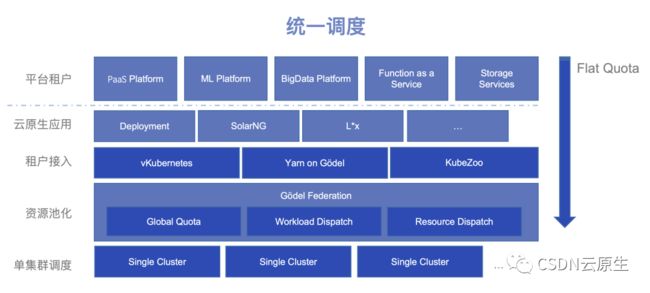
首先,单集群调度层面会运行承载所有的资源,运用统一的调度器、统一的资源管理、统一的隔离能力来实现资源的共享和复用;其次,联邦层实现整个数据中心层面任务的统一编排调度和资源管理;再对接到上层,实现不同的租户隔离能力和接入手段;最后,对接上层的PaaS平台、机器学习平台和大数据平台等不同的业务系统。
服务QoS保障
对于大规模的混部集群而言,需要注意的是服务的QoS保障,因此监控非常必要。
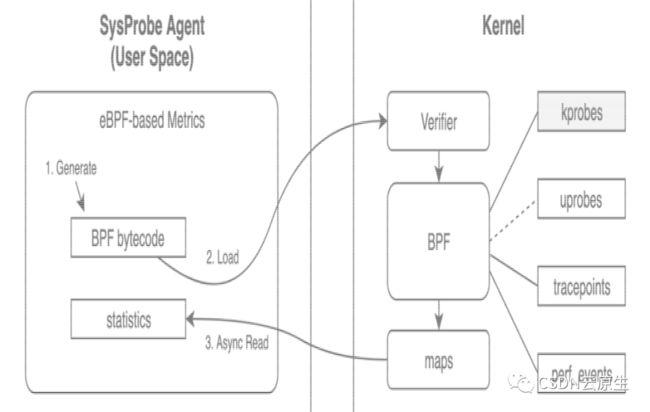
基于eBPF内核机制,在SysProbe系统中集成了内核监控的能力;
在CPU和内存层,复用了Cgroups的数据,同时扩展增加了throttle、组线程数和状态,以及实例Load等更能反映实例负载真实情况的一些指标;
在BlockIO层,通过识别Hook的VFS层关键的函数以及系统的调用,实现了准确识别实例的读写行为;
在网络IO层,探测服务的Socket级别的连接的状态,以及实时的SLA,比如SRTT的抖动。
基于这些监控机制,能够不断发现并且解决混部过程中遇到的影响业务QoS的问题,最终实现完善的隔离机制。
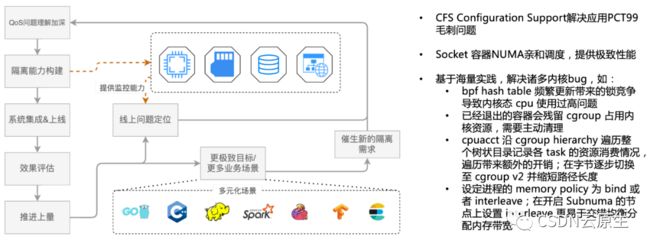
上图中左侧流程是发现问题并且解决问题的飞轮模型,右边为实际解决的问题,如CFS调参的扩展解决应用PCT99毛刺,以及其他内核bug等,都是通过这种机制发现并不断优化。
业务效果
在常态场景下,业务效果如下图所示。
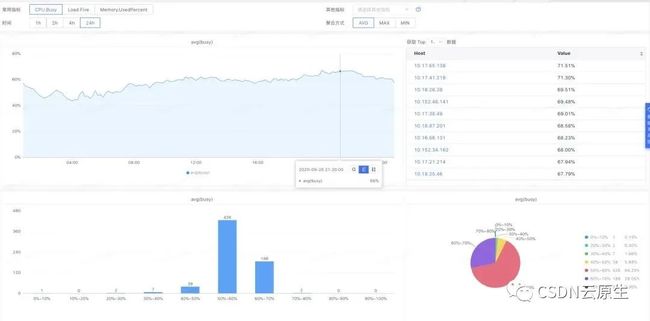
资源利用率情况,在线集群和离线集群的资源利用率从原来的平均23%提升到63%,节省40%左右的服务器成本。
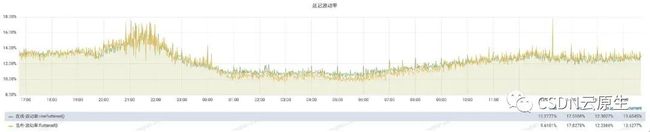
业务QPS指标,即在离线混部对业务QPS的影响,整体影响很小。

在保证在线业务资源需求的情况下,离线任务被驱逐的概率很低。
有了稳定的在离线资源调度系统,在需要应急资源的情况下,可以通过系统进行调配。比如2021年春晚抖音红包雨活动,活动期间需要大量的服务器来支持。但如果仅为支撑春晚活动而去采购过多计算资源,活动结束后肯定会浪费,所以团队除少量采购服务器之外,通过采用离线资源拆借和在线混部出让的方案解决了临时资源问题。
离线资源拆借。字节跳动内部有很多离线任务,例如模型训练等,这些任务在时间上并没有特殊约束。所以春晚活动就对这部分业务所占用的服务器进行了拆借,设置离线出让策略后,这些服务器可以在5分钟内转换成在线红包活动的可用状态。
在线资源出让。春晚当天,字节跳动还有大量服务器在支撑其他在线服务。所谓在线混部出让,即在保证其他业务稳定不受影响的前提下,在服务器上插入部分春晚作业。
基于这两种技术方案,在硬件设备有限的情况下,为春晚活动提供了充足的算力。
![]()
火山引擎云原生服务
火山引擎云原生服务的产品矩阵示意图如下所示。
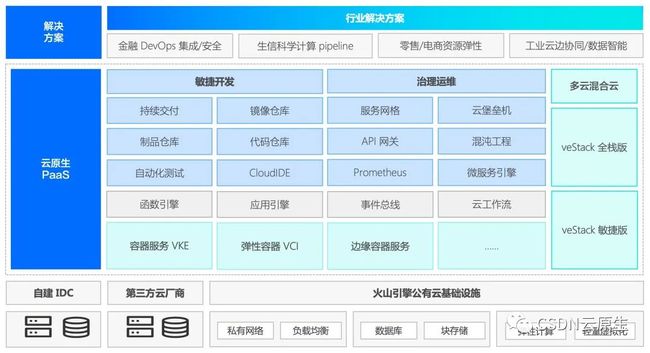
2021年12月,火山引擎发布公有云服务,对外输出字节多年来积累的技术和经验,云原生方向也以PaaS的形态上线了很多服务。
容器服务:包括托管的K8s管理平台VKE、弹性容器平台VCI和边缘容器服务以及多云混合云的产品veStack;
敏捷开发:包括持续交付、镜像仓库等产品;
服务治理:包括服务网格、混沌工程等产品。
上述产品共同组成了云原生产品基础矩阵,火山引擎云原生服务不仅仅提供了托管应用的能力,也融入了字节跳动在多年的实践过程中沉淀的K8s的稳定性、可观测性、服务网格等方面的技术积累和最佳实践,方便用户快速地使用相关技术。
![]()
END
云原生志愿者计划正在招募
精准把握技术趋势,深度学习新技术、新实践
 扫描图片二维码立即申请加入
扫描图片二维码立即申请加入
— 推荐阅读 —
☞百度沙翔宇:百度云原生混部大规模落地实践之路
☞Tetrate高洪涛:解密SkyWalking的APM专用数据库BanyanDB
☞听云研发总监杨金全:以Tracing为核心的可观测性体系
☞云原生应用交付的前世今生与一线实践☞2个维度5大方法,让你的微服务在K8s上跑起来☞透彻解析云原生在数字化转型中的应用实践,PaaS功不可没点这里↓↓↓记得关注标星哦
一键三连 「分享」「点赞」「在看」
成就一亿技术人