翻译:Towards Lingua Franca Named Entity Recognition with BERT(基于BERT的通用语命名实体识别)
**基于BERT的通用语命名实体识别笔记整理**
- 基于BERT的通用语命名实体识别
-
- 摘要
- 简介
-
- 命名实体识别(NER)
- 现存问题
- 本文主要思想
- 现有研究工作
-
- 多语言工作
- 多任务学习
- 任务和框架
- 实验:基线
-
- 数据和实验设置
- 比较方法
-
- 单语言训练
- 多语言训练
- Zero-shot 推理
- 实验结果与分析
- 讨论:Zero-shot
- 实验:部分更新
- 实验:多任务学习
-
- 语言ID(LI)
- 完形填空任务(CL)
- 预测完形填空任务(PC)
- 次要任务的组合
- 实验细节
- 实验结果
-
- 单语言zero-shot
- 结论
基于BERT的通用语命名实体识别
本文是关于学习Towards Lingua Franca Named Entity Recognition with BERT1 论文时翻译和笔记的记录,便于日后查看。
摘要
信息抽取是自然语言处理中的一项重要任务,它能够自动抽取数据以填充关系数据库。从历史上看,研究和数据是为英文文本生成的,随后几年是阿拉伯文、中文、荷兰文、西班牙文、德文和许多其他语言的数据集。自然趋势是将每种语言视为不同的数据集,并为每种语言构建优化的模型。
本文研究了一个基于多语言BERT的命名实体识别模型,该模型同时在多种语言上联合训练,能够比只在一种语言上训练的模型更准确地解码这些语言。为了改进初始模型,我们研究了多任务学习和部分梯度更新等正则化策略的使用。
除了是一个可以处理多种语言(包括代码转换)的单一模型之外,该模型还可以用于对一种新语言进行零触发预测,即使是那些没有现成训练数据的语言。结果表明,该模型不仅在单语模型上具有竞争力,而且在荷兰语和西班牙语数据集、阿拉伯语和汉语数据集上也取得了最好的结果。此外,它在没见过的语言上表现相当好,在三种语言上实现了最先进的零触发。
简介
命名实体识别(NER)
命名实体识别(NER)是信息抽取和自然语言处理中的一项重要任务。它的主要目标是在非结构化文本中识别对现实世界实体的连续类型引用,如人员、组织、设施和位置。作为识别实体(填充关系数据库)和事件(其中实体是事件的参数)之间语义关系的先驱,它非常有用。
现存问题
NER的绝大多数研究一次只关注一种语言,用单语数据为每种语言构建和调整不同的模型。这些模型已经从基于规则的模型发展到统计模型,紧密遵循自然语言处理的一般趋势:从基于Winnow和Transformation的学习,到基于最大熵、SVMs和CRF的模型,投票感知机,到深度神经网络,以及最近在大量未标记数据上使用预先训练的模型(ELMo、BERT)。然而,研究的单一语言方面保持不变,除了少数例外,稍后在先前的工作中描述。单语模型将无法跨语言共享资源,需要每种语言的大量人工标注数据。
本文主要思想
假设使用适当的统计模型在不同语言之间共享数据不仅是可能的,而且肯定是有益的,即使在语言不是来自同一语系或使用相同脚本的情况下。在BERT多语言模型的基础上,证明了:
- 一个模型可以同时处理多种语言;
- 联合模型的性能优于建立在同一架构上但只有一种语言的模型;
- 该模型可以用于以合理的精度执行0-shot(语言方式)NER。
这种跨语言模型在生产环境中有许多优势:简化的部署和维护、易于扩展、相同的内存/CPU/GPU占用空间,当然还有0-shot能力。然而,从标准培训/评估/模型选择过程的角度来看,0-shot学习框架存在一些限制,我们试图通过几项修改来克服这些限制,从而进一步推动SOTA。特别是,我们检查了训练框架的扩展,包括部分梯度更新和合并额外的任务,如完形填空预测和语言预测。
现有研究工作
命名实体识别及其后继者,提及检测,在自然语言处理中有着广阔的历史——完整的描述超出了本文的范围。我们将触及与这里呈现的结果直接相关的深度学习研究。
科洛博特和韦斯顿(2008)是第一个现代的序列分类方法,包括NER,使用卷积神经网络架构,推进了英语国家的艺术。Lample等人(2016)引入了双向LSTM (Bi-LSTM)网络,以提高CoNLL数据集的SotA NER性能,建立了4个模型,每种语言一个。
2018年引入了强语言模型预训练模型,首先是ELMo,然后是BERT。Peters等人使用大量未标记的英语数据,用字符嵌入的输入训练一个3层LSTM网络,然后将其作为标准的双LSTM网络的输入,在许多任务中获得最先进的结果。以类似的方式,Devlin等人(2018)在大量未标记文本上训练了一个基于变压器的架构,使用完形填空和下一个句子预测目标,然后将句子/段落嵌入到一个线性前馈层,在许多任务中再次超过SotA。
Akbik、Blythe和Vollgraf (2018)通过在字符级别计算 Bi-LSTM序列来扩展ELMo框架,然后将两个对齐的片段与嵌入的作品一起组合到双向LSTM层中,并显示所有的结果和OntoNotes。英语CoNLL’03中的当前SotA是由(Baevski等人,2019)获得的,他对完形填空任务预训练了一个双塔注意力模型,然后应用结果嵌入来获得GLUE任务的SotA结果,并在英语CoNLL’03数据集上获得93.5的F1值。
多语言工作
最近有一些关于构建可以同时处理多种语言的模型的研究。
- sil (2015)对英语和西班牙语的联合提及检测模型进行了培训,从而提高了西班牙语数据的性能。
- Akbik、Blythe和V ollgraf (2018)通过在所有CoNLL’02和’ 03语言上训练Flair,并在他们的系统的github页面上提供Flair github(2019)的一个模型——这个系统是最接近这里描述的模型,我们将我们的模型与他们的模型进行比较。主要的区别在于,我们的系统可以轻松地在不共享输入脚本的新语言上运行,正如我们将在实验部分中展示的那样。
在相关工作中,Xie等(2018)将英语的单语嵌入对齐到西班牙语、德语和荷兰语,然后将英语CoNLL数据集翻译成这些语言,并使用翻译语言建立自关注的Bi-LSTM-CRF模型,创建0-shot NER系统。皮雷、施林格和加雷特(2019)使用多语言BERT和类似于我们的0-shot基线的技术,在所有四种CoNLL语言中获得了0-shot的最好的准确率。
多任务学习
多任务学习(Multi-task learning, MTL)已经成功地应用于机器学习的许多应用中很多年了。
- Caruana(1997)对MTL进行了很好的概述,指出:“MTL通过利用相关任务的训练信号中包含的领域特定信息来改善泛化。”MTL在自然语言处理中也很受欢迎。
- Collobert和Weston(2008)利用MTL有效地共同学习了词性标注、组块、命名实体识别、语义角色标注等多种自然语言处理任务,这些任务共享一个单一的网络。
- 从那时起,就有一些工作将MTL实现为一个硬共享网络,或软参数共享,其中每个任务都有自己的模型和自己的参数。然后对模型参数之间的距离进行正则化,以使参数相似。
- BERT模型也使用MTL进行训练,它们共享一个网络来同时学习两个任务,一个是完形填空风格的语言模型,另一个是下一个句子预测模型。
任务和框架
大多数基于神经网络的NER系统都是从捕捉语言使用的word embedding开始构建的。这通常是通过使用各种技术(如CBoW、skip-gram、ELMo、BERT、RoBERTa、XLNet等)对word embedding进行预训练来实现的。
建立在多种语言上的挑战,特别是如果它们有不同的脚本,是能够训练这些单词嵌入,以这样一种方式,在不同的语言中相似的单词有相似的表示。Ni、Dinu和Florian(2017)使用了两种语言(如西班牙语到英语)之间的表示投影,从而能够在西班牙语数据上使用英语NER tagger,取得了一定的成功,但模型本身并没有从两种(或多种)语言的数据中受益。
我们在此假设,通过预训练,BERT词块向量很好地对齐,以便基于BERT的系统能够成功地训练多种语言,并能够对一种新语言的文本进行0-shot推断。此外,这种方法有一个伟大的特性,即无论它可以对多少种语言进行推理,它都拥有相同的内存/CPU/GPU占用空间。
本研究基于(Devlin et al. 2018) BERT框架,对所有模型使用预先训练的BERT基础多语言词向量。这些词向量训练在最大的维基百科(谷歌研究Github 2018)的前100种语言。随着语言大小的变化,使用指数平滑加权方法对数据进行采样,以平衡训练语料库中的语言表示。这些向量包括一个共有的110万个单词,跨越许多非欧洲文字,包括阿拉伯语和汉语。
我们以一种标准的方式来处理NER:一种基于上下文为每个单词分配一个标签的序列标签任务。
- 给定一个句子 { w 1 , w 2 , . . . . w n } \{w_1, w_2,....w_n\} {w1,w2,....wn} ,将其输入BERT模型,得到每个单词的上下文BERT emdedding { v 1 , v 2 , … v n } \{v_1, v_2,…v_n\} {v1,v2,…vn},通过每一层的多个注意力头捕捉每个单词的上下文;
- 然后将这些嵌入信息送入线性前馈层获得标签 { y 1 , y 2 , … y n } \{y_1, y_2,…y_n\} {y1,y2,…yn} 对应于每个词块(见图1)。
- 整个网络用每一轮进行训练,从而对NER任务的BERT embedding进行微调。我们使用实体的IOB1编码(Tjong Kim Sang和Veenstra 1999),因为它在初步结果中表现最好。
图1:BERT-ML 架构

我们使用BERT的HuggingFace PyTorch实现(HuggingFace github 2019)和BERT 词段标记器。我们遵循(Devlin et al. 2018)中构建命名实体标记器的方法:为了将NER标记从标签转换为单词片段,我们将标记的标签分配给它的第一个片段,然后将特殊标记“X”分配给所有其他片段。在训练和测试期间,不会对“X”标记进行预测。图1显示了所提模型的架构和NER注释风格。
实验:基线
在这一节中,我们检查了我们在基本0-shot设置中的方法,在这种设置中,我们使用能直接使用的多语种BERT嵌入,并且只在非目标语言的语言集上进行调整和微调,然后对目标语言进行评估。
数据和实验设置
我们在两个数据集上训练/评估我们的模型,即NER 02/03和OntoNotes 5.0。CoNLL数据集由四种欧洲语言西班牙语、荷兰语、英语和德语的新闻专线数据组成,并以四种实体类型(PER、LOC、ORG、MISC)进行注释。
OntoNotes 5.0是一个更具挑战性的语料库,包含三种不共享脚本的语言:阿拉伯语、汉语和英语,并包含18种NER类型。
对于大多数实验,我们使用 5 − 5 5^{-5} 5−5 的学习率和 32 或 100 的批量,训练20个epoch。我们在开发中调整超参数,并选择开发集上F1成绩最好的模型。我们在那个模型上报告测试值(训练数据不包括开发测试)。显示的所有测试值都是三次运行的平均值。模型是在一台装有两张Nvidia 2080Ti卡的台式电脑上接受训练的;训练时间从0.5到1.5小时不等。
比较方法
单语言训练
作为基准,我们分别在所有四种通用语言和三种OntoNotes语言上训练模型2。
多语言训练
我们训练了 CoNLL 数据的联合多语言模型和带有 OnNotes 数据的多语言模型。为了进行多语言训练,我们随机混合所有语言的句子,并在每一轮对它们进行训练。两者都是基于相同的架构的单语和多语模型,唯一的区别是用于训练模型的数据。
Zero-shot 推理
为了测试训练后的模型执行Zero-shot推断的能力,我们以循环的方式在三种CoNLL语言上进行训练,在第四种语言上进行测试,同样在两种OntoNotes语言上进行训练,在第三种语言上进行测试。
实验结果与分析
单语和多语实验的结果如表1(CoNLL)所示,如表2(Ontonotes)所示。
表1:单语言和多语言在 CoNLL ’ 02, CoNLL ’ 03上的F1值。Flair-ML是在(Akbik, Blythe, and V ollgraf 2018)中描述的系统,多语言培训,可从(Github 2019)获得。

表2:OntoNotes上的单语、多语言和0-shot语言的F1值。WordPiece fertility是给定语言中每个标记的BERT单词的平均数量。

对于CoNLL和OntoNotes来说,在所有语言上训练的模型(BERT-ML)在所有情况下都比在一种语言上训练的模型(BERT-SL)表现更好,表明BERT-ML模型能够受益于来自所有语言的信息来改进每种语言,验证了我们的前两个假设:我们可以有效地建立一个多语言模型,并且它比单个模型表现更好。相对于其他已发表的结果,Bert-ML CoNLL模型获得西班牙语和荷兰语的SotA(最棒)结果,德语排名第二,Bert-ML OntoNotes模型获得中文和阿拉伯语的SotA结果,英语排名第三。此外,请注意,BERT-ML模型的性能优于Flair-ML模型(除了英语),尽管前者的大小/架构与每种语言相同3 4。
为了验证第三个假设,表3显示了 0-shot 实验的结果。BERT-ML系统在西班牙语、德语、荷兰语和汉语(OntoNotes)上获得了良好的结果,而没有看到该语言的任何训练数据。对于所有语言来说,其表现与参加原始比赛的顶级系统的结果非常接近,荷兰语比获胜系统高2F。表中还显示了(前一个)在CoNLL上的-shot跨语言NER的SotA结果。仅用英语训练的BERT-SL模型在各个方面都有很好的表现。
表3:在CoNLL语言上训练的模型的0-shot 的F1值。 B E R T − M L k \small{BERT-ML^k} BERT−MLk是在k语言上训练的BERT-ML系统。(Pires,Schlinger和Garrette 2019)的数字来自他们表1中的英语行。有关CL、CL+LI、LI、PC、PC+LI系统的详细信息,请参见各自章节;在这种设置中,英文数字不是 0-shot 的。

对于OntoNotes,表2中所有语言中,阿拉伯语在 0-shot 场景中表现不佳——只有12.6F。在BERT分词器中查看单词词典,我们发现阿拉伯语没有得到很好的表示。正如我们在最后一行所示,一个阿拉伯符号平均被分割成7.42个单词块,而所有其他语言的范围都在1.8-2.5之间。由于标记的延长,这会产生破坏性的影响,导致阿拉伯语的行为明显比其他语言的行为更糟糕。尽管如此,当一起训练时,该模型仍然能够整合来自英语和汉语的信息,并且比仅使用阿拉伯语的模型提高了1.2F。
讨论:Zero-shot
表3中关于BERT-ML 0-shot的结果给人留下了深刻的印象,尤其是考虑到没有使用相应目标语言的标注数据。然而,当我们检查这些模型在各个训练时期的发展数据集上的表现时,一个奇特的画面出现了(图2)。
图2:0-shot BERT多语言版本在CoNLL开发中的性能,平均运行5次。

考虑到在使用荷兰语、德语和西班牙语标记的数据训练模型时目标语言是英语的情况,我们在每轮之后对英语发展集进行评估。平均五次运行的总得分,我们清楚地看到随着训练的进行,总得分呈下降趋势。这超出了大多数带标签数据的统计学习问题的正常范围,在这些问题中,我们预计随着学习的进展,F值会逐渐增加,然后可能会出现一个平稳期,而不是图中所示的持续下降轨迹。
这可能发生的原因之一源于我们最初的假设,即多语言BERT嵌入是良好对齐的。但这可能只是在开始微调伯特模型之前的情况。在对标记数据进行微调时,相对于目标语言的过度训练比在标准设置中发生得快得多。这是有道理的,因为我们实际上并没有对目标语言进行任何训练,因此我们假设有标签的语言的学习目标与我们心中的目标(即在目标语言上做好NER)是分离的。
为了克服F值轨迹中的这种状况,我们提出了两种训练增强:
- 第一是将学习限制在BERT变换器架构的子集,即在学习期间冻结变换器的1个或多个较低层,使得在这些较低层上不发生反向传播和更新。
- 第二种是以无监督的方式结合目标语言,以实现目标语言的迁移学习,同时优化我们有标记数据的语言的模型。
实验:部分更新
为了克服如图2所示的F值的病理轨迹,我们建议在学习时冻结BERT变压器架构的低层,这样在训练时就不会更新它们。我们认为这是模型正则化的一种形式,我们推测这在 0-shot 设置中特别有用,目标是在某些语言上训练一个NER模型,并将其应用到该模型没有训练过的其他语言。在多语言完形填空任务/结果句预测训练中,BERT的基本表示形式部分相同,同时部分适用于NER任务。
我们可以看到这个猜想在图3中得到证实。表4给出了 CoNLL dev实际的数值结果,表5给出了 CoNLL test实际的数值结果。
图3:Zero-shot BERT在CoNLL dev上的多种语言的效果图,包括语言、轮次和冻结层的数量。只有奇数的冰冻层。平均5次运行。
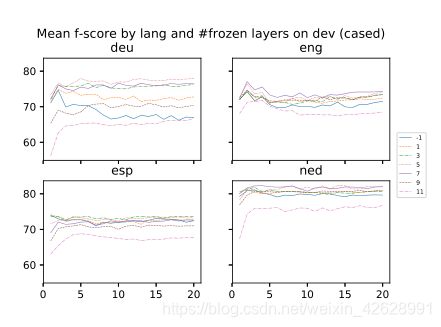
表4:CONLL dev数据的多语言0-shot。#frz对应于训练期间冻结层数。-1是没有东西被冻结的地方,是标准设置。0是仅冻结嵌入的位置。1是嵌入,第一层是冻结,以此类推。12是所有bert层被冻结的地方,只有输出层被调谐。

表5:基于CONLL test数据的多语言0-shot BERT。#frz对应于训练期间冻结层数。-1是没有东西被冻结的地方,是标准设置。0是仅冻结嵌入的位置。1是嵌入,第一层是冻结,以此类推。12是所有bert层被冻结的地方,只有输出层被调谐。

在训练期间,我们冻结−1,0,1,…, 12层。冻结-1层与基线多语言0-shot学习设置相同,在该部分中没有冻结任何内容,所有内容都按照中更新(Devlin et al. 2018)。冻结0层意味着只有BERT emdedding层被冻结,实际的BERT层没有被冻结。冻结1…12层意味着embedding层以及最低的1…12层在训练期间被冻结并且不更新。多语言伯特嵌入使用一个12层变压器。因此,当我们冻结最低层,比如3层时,只有从第四层开始的后续层根据更新方案进行更新(Devlin et al. 2018)。
在图3中,我们只显示了奇数冰冻层(−1,1,….11)的 f-score 图,以减少杂波。聚焦在对应于基本 0-shot 设置的蓝色实线上,病理行为在德语(deu)设置中最清晰可见。然而,当1,3,… 11层被冻结,f值的图稳定下来,不再随着学习的进展而减少。最稳定的轨迹出现在冻结11层时,但相对于冻结更少的层时表现不佳。
表4和表5在冻结层时选择并显示一些更有趣的结果,而不是显示所有可能的结果。在验证和测试过程中,我们都发现使用德语、英语和荷兰语冻结某些层的效果最好。在这个意义上,西班牙语是不正常的,因为没有冻结的效果比没有冻结的效果好(例如1)。此外,西班牙语测试的分数比西班牙语验证的分数要高,这是非常不寻常的,因为大多数模型的验证验证分数通常都比坚持测试分数高。
在验证中,德语在冻结5层时表现最好,英语7层,荷兰语5层。在测试中,德语在冻结3层时表现最好,英语7层,荷兰语3层。
表中给出的#frz 11和12表明在0-shot设置中,有太少的层调整是不利的。冻结12层类似于(Devlin et al. 2018)中的“基于特征的方法”,其中只有输出层针对CoNLL 英语任务进行了调整。那样,作者能够在没有任何微调的情况下在开发集上达到91的 F值。尽管如此,英语成绩达到63.43 f(表4,当输出层仅针对非英语语言进行调整时)仍然是值得注意的。这有力地支持了我们的假设,即多语言的BERT是良好对齐的,并且似乎在一个共享空间中为100+语言生成了一个共同的表示。
实验:多任务学习
另一种可能的解决方案是克服如图2所示的总体F值下降的情况,将0-shot学习作为一个多任务学习问题。在0-shot假设下,我们没有目标语言中的任何标记数据。然而,我们有目标语言中未标记的原始数据,而且我们也知道数据来自哪种语言,这是合理的假设。这允许我们使用:
- 目标语言中的原始标记
- 目标语言的名称
因此,在NER问题之上,我们提出了三个额外的任务。设 ( x i l , y i l ) , i ∈ { 1 ⋯ n l } (x^l_i, y^l_i), i∈\{1\cdots n^l\} (xil,yil),i∈{1⋯nl} 是语言 l ∈ { 1 ⋯ L } l∈\{1\cdots L\} l∈{1⋯L} 表示有训练数据的L语言。设 x i u , i ∈ { 1 ⋯ n u } x^u_i, i∈\{1\cdots n^u\} xiu,i∈{1⋯nu} 是语言 u ∈ 1 ⋯ U u∈{1\cdots U} u∈1⋯U表示我们没有标记数据的U语言。
基线0-shot学习问题的培训目标如下:

其中 L L L 为要最小化的总损失, D L D_L DL 为标记的训练数据, N N N 为训练实例总数, ℓ \ell ℓ为标准交叉熵损失, h θ h^θ hθ为BERT编码的softmax输出和前馈层及其相关参数 θ θ θ。
语言ID(LI)
在语言ID (LI)多任务学习设置中,我们增加了一个辅助目标来识别未标记数据的语言。目标语言数据仅在语言识别任务中使用。我们在BERT[’ CLS ']中使用专用的初始分类标记作为语言标识层的位置。我们使用交叉熵损失作为语言标识。我们将这个损失与基线序列预测损失相加。
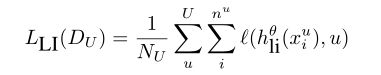
其中 D U D_U DU是未标记数据的集合, N U N_U NU是未标记实例的总数, h l i θ h^θ_{li} hliθ是BERT嵌入的输出和句子分类的前馈层以及相关参数 θ θ θ。因此,要最小化的损失函数变成
![]()
完形填空任务(CL)
第二个变体是完形填空任务(CL)多任务学习目标,其中我们添加了一个语言建模的次要目标,以预测目标语言句子中的屏蔽输入词块,就像最初的BERT训练目标中使用的那样(Devlin et al. 2018)。目标语言数据有一个任意屏蔽的输入单词子集,目标是预测这些屏蔽的单词。我们在完形填空中使用交叉熵损失。我们将此损失与基线序列预测损失相加。
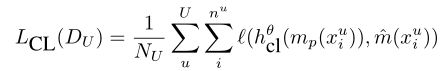
其中, h c l θ h^θ_{cl} hclθ是BERT embedding的输出,以及用于词块预测的前馈层和相关参数 θ θ θ。 m p m_p mp是掩蔽概率为 p p p 的随机掩蔽函数, m ˆ \overset{ˆ}{m} mˆ是相关的输出选择函数,它选择已经被损失函数掩蔽的原始字块。要最小化的损失函数变成
![]()
预测完形填空任务(PC)
最后一种变体是我们所说的预测性完形填空任务,在这种任务中,我们添加了一个次要目标,对目标语言数据进行非轨道完形填空任务。请注意,具有原始参数集的NER模型 h θ h^θ hθ 可以在训练期间的任何时刻切换到解码输入标签。在训练过程中,我们使用训练好的序列标签器的输出来解码目标语言数据。我们屏蔽对应于预测实体跨度的输入单词块,目标是预测这些屏蔽的标记。我们将交叉熵损失用于预测性完形填空任务。我们将这个损失与基线序列预测损失相加。

其中 D U D_U DU为未标记数据集, N U N_U NU 为未标记实例总数, h p c θ h^θ_{pc} hpcθ为 BERT embedding 的输出,以及一个用于词块预测的前馈层和相关参数 θ θ θ。 m m m 是掩蔽函数,其将未标记的文本 x i u x^u_i xiu和 NER 解码器 h θ ( x i u ) h^θ(x^u_i) hθ(xiu)的输出作为输入,以在 x i u x^u_i xiu 上生成掩蔽的输入序列, m ˆ \oversetˆm mˆ是相关的输出选择函数,其选择已经被 m m m 掩蔽的原始单词块作为损失函数。
次要任务的组合
除了上面列出的任务,我们还考虑了将语言识别任务与完形填空任务或预测完形填空任务相结合的设置。通过增加挑战的任务数量,从而增加间接正则化,我们检查这些是否比 0-shot 设置进一步提高了性能。
实验细节
在实际实验中,使用了小批量更新,而不是上面公式中暗示的批量更新。由于完形填空语言建模任务带来了更高的内存要求,我们将输入序列的最大序列长度减少到64。然而,我们不是截断句子并丢弃剩余部分,而是将长输入序列分割成更小的重叠序列(重叠大小为8),这样就不会丢弃任何训练数据。我们使用掩蔽概率 p = 0.15 p = 0.15 p=0.15,就像在最初的 BERT 论文中一样,用于 CL 任务。
所有实验结果都是用5种不同的种子5次运行的平均值。就解码测试数据的模型选择而言,为每个目标语言设置和种子选择了在相应开发数据上具有最佳总体F值的模型。
实验结果
我们在表6中给出了上述次要任务的CoNLL测试数据的结果。这里,#frz列中的-1值表示在训练期间没有层被冻结,相当于标准设置。至少对于荷兰语和英语来说,我们认为CL、CL+LI、LI、PC帮助是次要任务,并且比ML(-1)基线有所提高。但是,没有对西班牙语有帮助的次要任务。而且只有LI任务对德语有帮助。
表6:ML、LI、CL、CL+LI及不同冻层对照结果。少于8层的冷冻层可能会达到更好的数量。根据表5,最好的结果似乎出现在3个冻结层附近,但根据之前未讨论的实验,选择了8个冻结层,使用英语不区分大小写的多语言BERT。

接下来,我们检查当8层被冻结并且图片被混合时。对于英语来说,它对ML、LI、PC有帮助,但在其他情况下似乎也不会造成伤害。对于西班牙语来说,冻结8层总是效果不好。对于德语和荷兰语,没有直截了当的结论。
单语言zero-shot
我们还研究了训练单一语言的组合,即CoNLL英语,然后假设表7中没有荷兰语、德语和西班牙语的标记数据。
结果如表6所示。ML设置对应于标准的0-shot设置,但标记的训练数据仅来自一种语言。在这里,当3个层面被冻结时,会获得最佳分数。
因为除了LI之外,我们没有 # frz = -1时次要任务的结果,所以很难说它们之间有什么比较。但是,可以找到-1 #frz层ML基线被击败的设置,例如荷兰语的6 #frz层PC设置,或西班牙语的8 #frz层LI设置,或德语的6 #frz层CL+LI设置。
表7:在使用多种语言的测试中,用英语进行的单一语言0-shot

结论
在本文中,我们提出了一个简单而有效的方法来建立多语言NER系统的BERT。通过利用多语言BERT框架,我们不仅能够训练一个可以对英语、德语、西班牙语和荷兰语进行推理的系统,而且它的性能优于一次只对一种语言进行训练的相同模型,并且还能够执行0-shot推理。由此产生的模型在西班牙语和荷兰语数据集上以及在中文和阿拉伯语数据集上产生SotA结果。此外,英语训练模型对西班牙语、荷兰语和德语的0-shot语言产生SotA结果,将其提高了2.4F至17.8F的范围。最后,模型的运行时特征(内存/CPU/GPU)与建立在单一语言上的模型相同,大大简化了其生命周期维护。
我们已经表明,预处理的多语言BERT嵌入可以以无监督的方式有效地使用,同时利用目标语言之外的注释数据。此外,通过部分梯度更新或使用完形填空任务和其他无监督的联合任务来获得进一步的改进,很容易扩展这种方法。
原论文链接 ↩︎
仅发布了用于多语言嵌入的基本模型;期望一个大模型产生更好的结果是不合理的。 ↩︎
Flair-ML模型随着每一种添加的语言线性增长,因为需要该语言的词向量。 ↩︎
我们意识到英语水平低于报告(Devlin et al. 2018)。尽管我们尽了最大的努力,我们还是无法复制这种性能,甚至在社区中也找不到其他成功复制92.4/92.8数字的报道,然而有许多其他不成功的尝试报道,这让我们觉得系统的某些部分没有被完全描述。 ↩︎