冲鸭~~!10分钟部署清华ChatGLM2-6B,效果测试:不愧是中文榜单第一
来源: AINLPer公众号(每日干货分享!!)
编辑: ShuYini
校稿: ShuYini
时间: 2023-9-25
引言
今年6月份清华大学发布了ChatGLM2,相比前一版本推理速度提升42%。最近,终于有时间部署测试看看了,部署过程中遇到了一些坑,也查了很多博文终于完成了。本文详细整理了ChatGLM2-6B的部署步骤,同时也记录了安装过程中遇到的一些坑和心得,希望能帮助大家快速部署测试。
另外:作者已经把模型以及安装依赖全部整理好了,如需,关注 AINLPer公众号 直接回复:chatglm2-6b
本文主要分为七个部分,分别为:显卡驱动安装、Python虚拟环境、ChatGLM2依赖安装、模型文件准备、模型加载Demo测试、模型API部署、OpenAI接口适配,具体如下图所示。只要机器显卡驱动已装,按步骤20分钟即可完成安装测试!

说在前面
本文主要安装环境为:Centos7(8C24G)、T4(16G)显卡,由于实验室的电脑不能联网,本文主要是离线安装。所以这里将整个安装包分为了三个部分:ChatGLM2依赖文件、ChatGLM2模型文件、ChatGLM2 Demo展示文件、其它依赖包,如下图所示。注:不论您是离线安装,还是在线安装,直接拷贝下面几个文件至对应的目录下面,直接启动Demo测试就能运行此程序,那么现在开始!!!
一、显卡驱动安装
跑模型少不了了显卡驱动,这部分主要内容包括:显卡驱动型号对齐、驱动依赖安装、显卡安装等三个部分。如果安装过了显卡驱动可以跳过这一步。
注:对应Linux机器来说,显卡的安装需要用到root用户,不能使用应用用户。如果是自己安装测试,直接root用户一套下来也没有问题,如果涉及企业级应用或者对机器权限有限制,需要联系系统管理员要服务器root权限。
1、查看服务器型号
cat /etc/redhat-release
2、查看服务器显卡型号
sudo lshw -numeric -C display 或 lspci | grep -i vga
3、下载显卡驱动
访问英伟达官网:https://www.nvidia.cn/Download/index.aspx?lang=cn,根据自己显卡的系列型号,选择对应的版本,进行下载。 如下图所示:
我使用的显卡是T4,操作系统是Centos7.9,所以选择这个版本。这里又一点需要注意,CUDA Toolkit的版本需要和使用的Pytorch、Tensorflow等框架版本一致。目前我看Pytorch最高可以支持11.8的CUDA版本。如果您的显卡驱动和我一样,可以直接在我的资源包里面获取,具体为:./packages/NVIDIA-Linux-x86_64-515.105.01.run
4、安装GCC、kernal组件、dkms等相关依赖
yum install gcc
yum install gcc-c++
yum -y install kernel-devel
yum -y install kernel-headers
yum -y install epel-release
yum -y install dkms
5、关闭nouveau
其中Nouveau 是由第三方为 NVIDIA 显卡开发的一个开源 3D 驱动,也没能得到 NVIDIA 的认可与支持。虽然 Nouveau Gallium3D 在游戏速度上还远远无法和 NVIDIA 官方私有驱动相提并论,不过却让 Linux 更容易的应对各种复杂的 NVIDIA 显卡环境,让用户安装完系统即可进入桌面并且有不错的显示效果,所以,很多 Linux 发行版默认集成了 Nouveau 驱动,在遇到 NVIDIA 显卡时默认安装。企业版的Linux 更是如此,几乎所有支持图形界面的企业 Linux 发行版都将 Nouveau 收入其中。
对于个人桌面用户来说,处于成长阶段的 Nouveau 并不完美,与企业版不一样,个人用户除了想让正常显示图形界面外很多时候还需要一些 3D 特效,Nouveau 多数时候并不能完成,而用户在安装 NVIDIA 官方私有驱动的时候 Nouveau 又成为了阻碍,不禁用 Nouveau 安装时总是报错, 错误如下:ERROR: The Nouveau kernel driver is currently in use by your system. This driver is incompatible with the NVIDIA driver……
- 1)查看是否有nouveau在运行
lsmod | grep nouveau
- 2)修改系统黑名单配置文件
进入到/etc/modprobe.d文件夹下面,找到具有blacklist.conf字样的文件。通过vim修改该配置文件,在文件中新增以下内容,最后通过!wq保存。
blacklist nouveau
blacklist lbm-nouveau
options nouveau modeset=0
alias nouveau off
alias lbm-nouveau off
- 3)更新内核服务器参数(如果第一个命令不行,可以尝试第二个)
update-initramfs -u 或者 dracut --force
- 4)重启服务器
reboot
- 5)再次查看是否有nouveau在运行,如果没有,则表示nouveau完全关闭了。
lsmod | grep nouveau
5、安装显卡驱动
将驱动拷贝到服务器上,执行以下命令,(如果安装报错,请看下面第6条):
chmod +x NVIDIA-Linux-x86_64-515.105.01.run
sh NVIDIA-Linux-x86_64-515.105.01.run
6、显卡安装报错排查
在安装过程中,我主要遇到的报错为:ERROR:Unable to find the kernel source tree for the currently running kernel…

遇到这个问题的时候,网上看了很多的例子,这里再做一下整理。这个报错意思是说操作系统运行的内核版本与kernel-devel不一致。这里将两者版本对齐就可以了。具体操作如下:
- 1)查看系统运行版本的内核编号
cat /proc/version
- 2)列出目前系统所有内核相关资源
rpm -qa | grep kernel
- 或者直接列出安装的kernel-devel、kernel-headers的版本
yum info kernel-devel、kernel-headers
如下图所示:
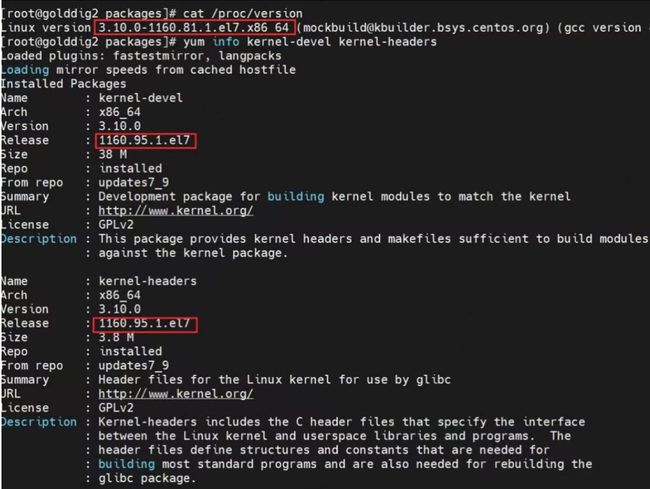
可以发现,服务器运行的内核编号和kernel-devel、kernel-headers的版本编号并不一样。这个时候有两种做法,一种是让服务器的内核版本编号与kernel-devel、kernel-headers版本编号对齐,另外一种是让kernel-devel、kernel-headers的版本编号与服务器系统运行的内核编号对齐。
- 1)系统内核编号与kernel-devel等编号对齐。
# 根据kernel-devel编号安装对应的系统内核
yum install kernel-3.10.0-1160.95.1.el7.x86_64
# 设置系统默认启动内核版本
grub2-set-default kernel-3.10.0-1160.95.1.el7.x86_64
# 重启服务器
reboot
# 再次进入服务器,查看系统运行内核编号
cat /proc/version
- 2)kernel-devel等编号与系统内核编号对齐(这里假如系统内核编号为:kernel-3.10.0-1160.95.1.el7.x86_64)
# 根据系统内核编号安装对应的kernel-devel、kernel-headers
yum install kernel-headers-3.10.0-1160.95.1.el7.x86_64
yum install kernel-devel-3.10.0-1160.95.1.el7.x86_64
以上不管是按照哪种方式,得到的结果如下图所示,此时按照上面第5步的命令,安装显卡驱动就可以了。
另外,如果有其它的服务,需要之前的内核,那么就需要给服务器切换内核。具体操作如下:
# 进入到/boot/grub2或者/etc目录下面,其中:/etc/grub2.cfg文件是一个文件链接,实际链接到/boot/grub2/grub.cfg
#看一下是否有:grub.cfg,如果没有需要创建。
grub2-mkconfig -o /boot/grub2/grub.cfg
#查看当前内核
grub2-editenv list
#查看已安装内核
awk -F' '$1=="menuentry " {print i++ " : " $2}' /boot/grub2/grub.cfg
# 设置默认启动版本
grub2-set-default xx #xx为你看到的内核编号
# 重建内核配置文件
grub2-mkconfig -o /boot/grub2/grub.cfg
# 重启生效
reboot
按照以上方式解决了报错问题之后,再按照第 5) 步执行显卡安装命令,最后通过nvidia-smi查看显卡安装是否成功。具体命令如下所示:
# 执行显卡安装命令
chmod +x NVIDIA-Linux-x86_64-515.105.01.run
sh NVIDIA-Linux-x86_64-515.105.01.run
# 按照以上命令完成安装,通过以下命令查看是否安装成功。
nvidia-smi
最后截图如下所示:

二、Python虚拟环境创建
1、为什么要安装Python虚拟机环境?
答:一台服务器上面,可能需要跑多个模型,每个模型所依赖的python版本或者依赖包的版本不同,比如:模型A依赖的python2.7版本、transformers4.30.2,模型B依赖的是python3.8的版本、transformers4.26.1;这就需要做python虚拟机环境的隔离。如果您这台服务器未来就单独跑这一个模型,可以忽略这一步,也没有问题。
2、创建Python虚拟环境方法
python虚拟机环境创建大概有两个主流的方法:一个是安装virtualenv库,实现python虚拟机环境管理;另外一个是通过conda。因为自己一开始就用的conda,所以对virtualenv不是很熟悉,所以这里主要介绍通过conda的方式创建Python虚拟环境。如果有小伙伴对virtualenv感兴趣,百度一下应该有很多教程。
3、Miniconda介绍
个人比较喜欢Miniconda,自己需要什么库就自己下载安装。以下是Miniconda和Anaconda的对比。它们两个非常流行的Python发行版。Miniconda只包含最基本的工具和库,需要手动安装其他工具;Anaconda是一个完整的发行版,包含许多重要工具和库。相对于Anaconda,Miniconda更加轻量级和灵活,适合具有需要在不同的环境中切换.
4、Miniconda的安装
- 1)获取Miniconda安装包:因为chatglm2用到了pytorch框架,按照官网的建议,这里选择了python3.8版本。
方法一 直接拉到文章最后,获取方式放在最后,在others文件包中。
方法二 因为Miniconda自带python,所以要在官网下载python版本为3.8的Miniconda版本。下载地址为:https://docs.conda.io/en/latest/miniconda.html#linux-installers,具体截图如下。
- 2)安装Miniconda
将Miniconda下载安装包放到你要放的目录,这里我放在:/home/work/miniconda 中,然后执行sh Miniconda3-latest-Linux-x86_64.sh 如下图所示: 执行完之后按照提示进行回车(enter)就好了,注意:最后选择“yes”,这样每次启动,它都会自动给你切换到conda的base环境中。
执行完之后按照提示进行回车(enter)就好了,注意:最后选择“yes”,这样每次启动,它都会自动给你切换到conda的base环境中。
- 3) 创建虚拟机环境
miniconda支持创建多个虚拟环境,用来支撑不同版本(python)版本的代码,这里就为chatglm2-6b创建一个单独的python虚拟机环境,名字叫:chatglm2,后面会在该环境中安装跑chatglm-6b模型的所有依赖。下面是命令及截图:
conda create -n chatglm2 # 如果能连网,可以直接执行该命令,如果不能安装执行下面带‘clone’的命令
或conda create -n chatglm2 --clone base # 注:因为是离线安装这里选择clone的方式创建,直接创建会报错,因为这里是离线安装
conda env list # 获取环境列表
conda activate chatglm2 # 切换chatglm2环境
- 4) 默认python虚拟机环境设置
如果需要每次进入机器都默认使用chatglm2的环境,可以通过以下方式进行配置。(这一步不是必须的!)
vi ~/.bashrc
# 在最后面添加:conda activate chatglm
# 执行以下命令就可以了
source ~/.bashrc
三、Chatglm2-6B依赖安装
1、将chatglm2的依赖包:chatglm2-dependence,拷贝到:/home/work/chatglm2/下面。(这里work可以是你自己用户名)如下图所示:

2、通过pip进行安装,命令如下:
pip install --no-index --find-links=/home/work/chatglm2/chatglm2-dependence -r requirements.txt
3、授之以渔(非必须)
chatglm2-dependence中的所有依赖,主要通过https://github.com/THUDM/ChatGLM2-6B的requirment.txt进行下载得到的。相关依赖包的下载命令为:
pip download -d ./chatglm2-dependence -r requirements.txt
四、模型文件准备
1、将chatglm2的模型文件:chatglm2-model,拷贝到:/home/work/chatglm2/下面。如下图所示

2、授之以渔(非必须)
模型文件是在https://huggingface.co/THUDM/chatglm2-6b/tree/main下载得到,具体截图如下:

五、模型加载Demo测试
关于模型加载Demo的展示,目前官网给出了三种方式:分别为命令行、基于 Gradio 的网页版、基于 Streamlit 的网页版。下面是具体的操作方法。
1、首先,将chatglm-web,拷贝到:/home/work/chatglm2/下面。如下图所示

2、方法1:命令行模型Demo测试:进入到chatglm-web文件夹中,修改cli_demo.py文件中的模型路径地址,如下图所示

具体地,将上面的“THUDM/chatglm2-6b”修改成自己的模型文件路径,我们这里模型路径是在:/home/work/chatglm2/chatglm2-model,修改之后结果如下:

最后,wq!保存修改信息。这里有一个需要注意点:尽可能地用绝对路径,之前看有人部署的时候用的相对路径,在加载模型的时候找不到。
修改完配置文件,执行以下命令,直接就可以启动该脚本了。
python cli_demo.py
运行起来的截图如下所示:

3、方法2,通过基于Gradio的网页版运行模型加载测试Demo。
和方法1类似,这里也主要是修改web_demo.py配置文件,将“THUDM/chatglm2-6b”修改成自己的模型文件路径。然后执行以下命令,直接就可以启动该脚本了。
python web_demo.py
另外,如果要指定服务运行的IP和端口port可以按照以下方式修改。
![]()
4、方法3,通过基于 Streamlit 的网页版运行模型加载测试Demo。
和方法1类似,这里也主要是修改web_demo2.py配置文件,将“THUDM/chatglm2-6b”修改成自己的模型文件路径。然后执行以下命令,直接就可以启动该脚本了。另外,该种方式可以直接通过命令指定服务的端口、IP地址。
streamlit run web_demo2.py --server.address='0.0.0.0' --server.port=8099
六、模型API部署
对模型进行API接口封装,可以实现模型的联机调用,具体操作方法如下:
1、文件放置
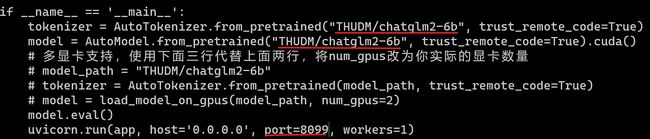
进入到/home/work/chatglm2/chatglm2-web下面,修改api.py的文件,更改模型文件路径,如若要修改服务端口,可以在下面修改port参数,这里修改成了8099端口。
2、安装相关依赖:fastapi、uvicorn。
pip install fastapi uvicorn
注:如果前面直接把chatglm2-dependence相关依赖都安装了,这一步可以忽略。我把这部分的依赖也都放到chatglm2-dependence里面了。
3、启动模型api服务
python api.py
4、测试。通过Postman、或者curl命令测试api接口是否正常。
# 通过命令行进行测试
curl -X POST "http://xxx.xxx.xxx.xxx:8099" \
-H 'Content-Type: application/json' \
-d '{"prompt": "猪为什么能够上树吃苹果", "history": []}'
七、OpenAI接口适配
实现了OpenAI格式的流式API部署。即如果您之前调用的是ChatGPT的接口,可以实现缝切换chatglm2-6b。具体实现方式如下:
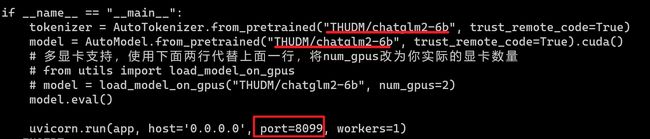
1、进入到/home/work/chatglm2/chatglm2-web下面,修改openai_api.py的文件,更改模型文件路径,如若要修改服务端口,可以在下面修改port参数,这里修改成了8099端口。
2、然后启动服务
python openai_api.py
3、测试服务的可用性, API 调用的示例代码为:
import openai
if __name__ == "__main__":
openai.api_base = "http://xxx.xxx.xxx.xxx:8099/v1"
openai.api_key = "none"
for chunk in openai.ChatCompletion.create(
model="chatglm2-6b",
messages=[
{"role": "user", "content": "你好"}
],
stream=True
):
if hasattr(chunk.choices[0].delta, "content"):
print(chunk.choices[0].delta.content, end="", flush=True)
总结
以上就是作者部署的整个过程了,其实当时自己花的时间较多的是显卡报错和模型文件问题。尤其是模型文件问题,模型下载下来和官网大小一致,没有对比MD5,结果有一个模型文件MD5不对导致模型一致不输出结果,搞了一天才发现这个问题。如有问题,关注 AINLPer 公众号,加群交流!