2022年华为软件精英挑战赛(杭厦赛区冠军,全球第五)
写在前面
时光匆匆流逝。转眼一年稍纵即逝。去年软调历历在目。
去年参加比赛体验极佳,虽然没有打入决赛,但是和各个大佬互相竞争,斗智斗勇还是挺有意思的。
于是乎今年又参加了华为软调。
仰慕去年零零妖大哥冲榜时之手遮天的气魄,于是乎加了妖哥大佬的联系方式。
得益于紧抱妖哥大腿,今年打到总决赛季军,全球排名第五。
复盘
2022软挑也落下帷幕,作为两届老玩家,也是学生时代的最后一个比赛,有遗憾也有进步,这里总结一下我队方案:
精简(去掉了很多可能没用的搜索)并整理了一下代码: github源码地址
详细赛题移步: 大赛官网
转载请注明出处。
1. 初赛
经历了秋招有鹅选鹅,随后过个年互联网就被重拳出击、大量裁员的惨兮兮一届在这里。年初的心态是只想躺平,其实本来想一直躺下去,也没有想做这个比赛来着的。然而太过无聊,小试一下,这两年都是以华为云的具体业务作为课题,去年是虚拟机分配和调度;今年是流量分配调度,看起来这两年华为很喜欢组合优化。
杭厦赛区历来有初赛训练赛奖品激励,这也是今年参赛的一开始唯一动力了。最开始看到题想去搜搜别人论文是怎么做的,可惜没有搜到什么有用的资料,迅速地就把关键点定位到95计费法免费的5%部分,于是很快就做出一个当时比较高的分数,经去年的巨巨巨佬reku大哥的提点下用最大流做了个初始可行解,但是线上的数据似乎都很宽松也没什么用。不过想着拿奖品应该稳了,就此躺平吧。这里也感谢一下杭厦群里厦大同学做的判题器和数据生成器。
组队即将截止时我找上了妖哥,妖哥也是去年的参赛选手之一,于是我俩一拍即合,今年决定再好好整一整,妖哥这个大腿抱的好才有精彩的比赛体验。合并代码后又做了一些新思路的调整,但是没上什么分。不过,按去年经验复赛题目会变化比较大,也不必过分纠结初赛的结果,能进个复赛就行。


简单总结一下题目:
节点可以分为两类:客户节点和边缘节点。给定了一个服务质量矩阵qos,客户和边缘的连接延迟必须小于某个值才视为联通。
客户节点在每个时刻有流量需求,这些流量需要由边缘节点提供,每个边缘节点有能够提供的带宽上限。
任务:将所有客户的流量需求分配到边缘节点上,使得所有服务成本最小,成本为所有边缘节点成本之和,单个边缘成本采用95计费(所有时刻使用量从小到大排序,取95%位使用的带宽作为成本)
显而易见,每个节点的后5%是可以白嫖的,因此要尽可能增加白嫖的流量。初赛阶段,每个流量是可分的,比如一个流量需求是100M,它可以将50M分配给边缘节点A,50M分配给边缘节点B。为了保证出可行解,可以套最大流。
最大流的思想:所有客户节点连接到一个超级源点,所有边缘节点连接到一个超级汇点。客户到源点的约束设为客户需求的流量,边缘到汇点的约束设为该边缘的最大带宽,客户到边缘的约束设为INF,然后套dinic求解。
最大流的优化:第一种是把“边缘到汇点的约束设为该边缘的最大带宽”乘一个[0, 1]的系数,不断降低这个系数直到无解;第二种是“不断踢出度小的节点”直到无解,这时候再用第一种方法压一压。由于一共有8950个时刻,可以采用退流等方法进行优化速度(但实测是没有差太多)
使用简单最大流的方法就可以做到挺不错的解(没记错的话初赛训练赛可以做到38W左右),但是线上其实基本不会无解(可能是业务真实数据)。
于是引入贪心的做法,贪心目标就是要尽可能提高5%吸收的流量,这里也有两种方法:
- 先出可行解,然后通过迁移,尽可能降低每个节点95%分位的带宽量(后简称v95),最大化5%免费使用部分吸收的流量
- 预分配填充5%->分配剩余需求->迁移微调所有边缘节点的v95。
方法1大致也是做到38w附近;
方法2的拓展空间比较大,这也是我们后续赛程的基本框架,下面详细介绍一下方案2。
- 预分配:按某种奇怪的顺序选择边缘节点,然后根据某种评价指标选出免费的5%时刻。选出时刻后,遍历该时刻客户的流量需求,尽可能打满到带宽上限。
- 分配:这步要将未分配的客户流量需求分配完。度小的客户先分,遵从“缓慢扩容,尽量填满”,先放到不引起成本增加的边缘节点中(优先剩余免费空间大的),否则放到引起代价增加最少的边缘节点。
- 迁移:定义利用率=前95%带宽之和/v95,选择利用率最低的边缘节点。从95分位开始迁移需求(尽可能搬空)到其他边缘节点上。迁移的原则是降低迁出点的成本,但不引起迁入点v95升高。可以反复执行几次,直到分数稳定不变。
浅做一下,反正复赛会换题。这一阶段,“奇怪的顺序”选择为边缘节点最大带宽 / 度 大到小排序比较好;“某种评价指标”指能吸收最大流量的时刻(不考虑实际的最大带宽限制)。需要指出的是,对于任一边缘,按吸收最大流量的时刻选出的时刻,一定是使用量最高的5%个时刻,因此在预分配之后,剩余需求分配阶段直接维护每个边缘节点带宽使用的最大值,即为其v95。
初赛训练赛
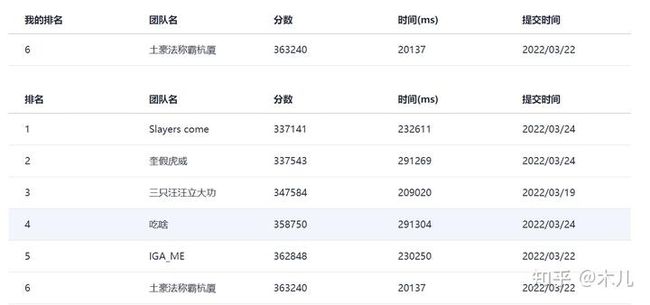

初赛正赛,增加了对“奇怪顺序”的搜索


2. 复赛
不出意外题目变化比较严重,很多基于网络流选手相当于换题了。但我们的大框架还是可以用的,继续小改一下爬山,爬着爬着发现分数就非常高了,但是还是担心正赛翻车,毕竟组合优化是个玄学。另外,今年因为疫情没有办法杭州旅游了,非杭州地区的伙伴正赛改线上进行,非常可惜,还想去西湖跑圈,又一年东坡肉梦碎。
正式比赛的时候第一发800W吓得一身冷汗,还好在家很快冷静下来并解决了问题,紧接着一发53W宣告下班。比较可惜的cf红名巨佬slayer comes、浙大的手机又卡了、奎假等队伍没有进决赛。杭厦赛区还是有好多巨佬的,没进来决赛还是感到非常可惜。
复赛到决赛中间有一个月漫长的周期。
相对于初赛,主要的变更点是:
- 每个客户在每个时刻可能有多个类型的流量需求(≤100)
- 每个类型的流量的分配不可拆分,必须完整地分配到一个边缘节点上
- 成本计算方式发生了变化,每个节点一旦使用过,即便v95=0,也有一个base_cost的成本;节点成本与该节点的v95呈平方关系,而不再简单使用v95作为成本。
最大流不再适用了,基于初赛的框架继续魔改,主要的修改点如下:
- 由于每个客户有多种需求,且一个需求必须完整分配到一个边缘节点上(引入了组合优化),为了让边缘节点填充的更满,将需求按从大到小统一排序。
- 预分配选择免费的5%时刻中,初赛取吸收流量最大的时刻。为了优先考虑度小但需求大的客户,取 (需求大小/客户的度)之和 最大的5%时刻(这个在复赛阶段对分数有一定影响)。
- 修改5%时刻选择后,预分配选择的时刻未必就是吸收流量最大的,因此需要使用堆维护每个边缘节点的v95。
- 在分配阶段,引起分数涨幅最小的可能在全局上并不一定够优,一种比较理想的状态是所有节点的v95都相差不大,因此在扩容阶段尽可能选择使用量最少、度较大的节点进行扩容。
- 尝试关机以压缩整体成本(最终我们选择的方式是在算法之外套一层关机机器搜索,这样优化相对比较稳定,否则很难选择禁用哪些边缘节点)。
- 优化代码执行速度。
给出复赛阶段的整体流程:
- 预分配:按某种奇怪的顺序选择边缘节点,然后根据上述指标选出免费的5%时刻,选出时刻后,从大到小遍历该时刻所有流量需求,尽可能打满到带宽上限。
- 分配:这步要将未分配的客户流量需求分配完。度小的客户先分,遵从“缓慢扩容,尽量填满”,先放到不引起成本增加的边缘节点中(优先剩余免费空间大的),否则放到使用量最少的边缘节点上。
- 迁移:定义利用率=前95%带宽之和/v95,选择利用率最低的边缘节点。从95分位开始迁移需求(从大到小,尽可能搬空)到其他边缘节点上。迁移的原则是降低迁出点的成本,但不引起迁入点v95升高。可以反复执行几次,直到分数稳定不变。
- 关机:生成初始解后,按边缘节点的度从小到大,尝试关机。如果关机后提高了分数,则确认关机该节点,否则回退该节点,直到尝试过所有的边缘节点或时间不足。
依旧是搜“某种奇怪的顺序”,复赛训练赛:

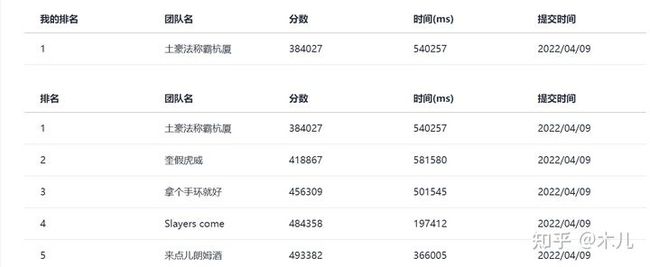
复赛正赛,多了一个变更点,可以选择10台机器,其计费分位变为90%。由于现场只有三个小时,简单处理,选择带宽×度最大的十台:
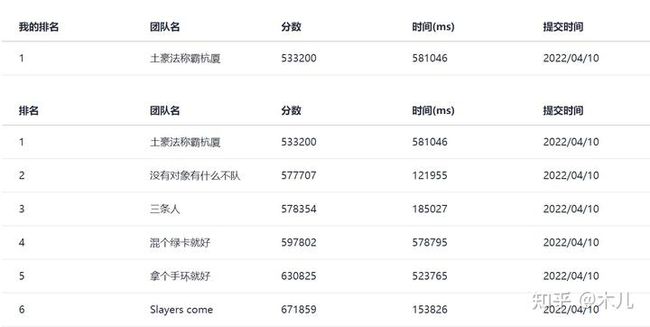
然后水进决赛,杭厦赛区被杭电的朋友们包围了,瑟瑟发抖.jpg
3. 决赛
决赛赛题变化非常大。
复赛结束后躺了三四天起来,成渝兄弟们已经卷到95w了简直非常恐怖。自己这边交一发复赛原版分数180w(倒一)直接自闭,随后根据决赛要求改了一个版本上去,还是180w(顿时大为震惊且想弃赛)。蛋疼了一天和余哥重新看题发现我理解错了题意!总之就是赛题变化明显,按新的理解几乎重写了框架各个函数的实现,随后一发冲到前四,挣扎了一下最终分数定格在100w左右,但该版本还是有很多问题。
然后封榜了,决赛延期。复赛到决赛的间隔实在太久了,久到甚至不想做,我们有一天没一天地瞎调着其实也没什么用,因为数据集不透明,然后中间水了个中兴捧月,迷迷糊糊一个月就过去了。
放榜后调参交了一发发现88w,随后开始了漫长的爬山生涯,最后爬到74w左右(爬山全靠余哥)。
最后决赛是深圳三日游,还是挺欢乐的。正赛现场做了一个不大不小的改动,由于太过紧张很多我们细节没有想到,也写了很多bug,果然还是要在家比较冷静....比赛过程中主办方一直盯着我们看为什么还不出成绩,我们也很无奈orz,问就是脑子很混乱对着新需求写了一堆bug。大概过了一个小时吧我们才把bug修好出分,现场我们应该是最后一个出分的队伍。然后还是上不去分,因为本身我们的方案就有很强的搜索能力,前几发上不了分后面基本也没戏,脑袋也有点一团浆糊。看着大家应该是都发现了一些trick我们还是毫无发现,一通乱交上分全看脸...然后最终下场就是翻车orz..
正赛结束后,主办方带我们坐游轮绕着大湾区港珠澳大桥开了一圈,海风惬意,吹的提醒我2XL已经无法包裹住我瘦小的身材=w=... 因为疫情今年没能去东莞溪背村,还是很怀念去年决赛在那里玩的魔法大作战,不过应该没什么机会去了。回家的路上也很惨,由于只有我一个从福州来的(他们都是杭州的,明年改名杭州赛区吧QAQ)大包小包路途遥远真的没手拿...
相对于复赛,主要的变更点是(建议还是去翻题目书认真理解一下):
- 新增了中心节点,定义E_ai为边缘节点a对流量类型i提供带宽的最大值(可能有多个客户的流量类型i请求到边缘节点a,取其中最大值);定义E_a为边缘节点a对所有类型流量最大值之和;定义E为所有边缘节点E_a, E_b, ..., E_n 代价之和,在该时刻中心节点的代价即为E。
- 新增缓存,当前时刻边缘节点的(使用量+缓存)的5%作为下一时刻的缓存,某节点某时刻带宽使用量为(实际使用量+缓存),其值不得超过边缘节点最大带宽。缓存以平方关系扩散到后续的时刻。
- 成本计算发生变化:原成本+中心节点的v95作为新的成本。
分析:
- 要尽可能把同类型流量打到同一个边缘节点上,这样才能降低中心节点的代价,从而使中心节点的v95降低。因此,所有需求不仅要从大到小排,还要按流的类型区分开,同类型流量内从大到小排。中心节点的5%似乎很难利用,因为不能跨时刻迁移。
- 缓存是影响边缘节点成本至关重要的因素,我们不能像复赛一样打满所有的5%时刻了,否则会因为缓存造成v95升高。
下面给出方案:
3.1 预处理
因此, 在预处理阶段,我们重新设计了免费的5%时刻的获得方式:分块白嫖。如果像之前那样白嫖时刻不连续,会有很多缓存上的浪费;但若在连续的时刻上白嫖,则无法吸收最多的流量。因此,我们动态搜索不同白嫖块的长度,期望在缓存浪费和白嫖流量大小之间找到一个权衡。首先从大到小对每个时刻可吸收的最大流量排序,记为数组T_arr,记录其排序索引值rank。给定参数thre,枚举排序后的数组T_arr,假设可吸收最大流量的时刻为t,向前后搜索t-1/t+1的rank是否小于thre,若是则将白嫖块连上t-1/t+1,否则断开。
通过上述方式找到成片的白嫖块,在每个白嫖块末尾需要占用 cache_num 个时刻用于缓存,其中
cache_num = log(base_cost * 1.0 / edge_nodes.max_bandwidth) / log(0.05)就是当边缘打满后它的缓存需要经过多少天才能衰减到base_cost。
重复上述过程,直到免费时刻用完,可以设计一个评估方式(如吸收的流量总额)来搜索最优的参数thre,具体实现特别是分块搜索上有一些变化,可以参见代码。
此外,由于预分配阶段是乱序的,每天不能完全打满,防止前一天打不进去,可适当预留0.05 * max_bandwidth
或者也可以跑两轮预处理,在第二轮预处理时再尽量填满。
为了支持乱序打需求,我们要准确算出当天可用容量(仅与前后几天的最大带宽有关)和免费容量(与选择的白嫖时刻、当前节点的v95有关),给出可用容量和免费可用的约束公式:
可用最大容量 canuse_bandwidth:
// A1 = (Ct + Ut + Xt) * 0.05 + Ut+1 <= max_bd
// A2 = A1 * 0.05 + Ut+2 <= max_bd
// A3 = A2 * 0.05 + Ut+3 <= max_bd
// A4 = A3 * 0.05 + Ut+4 <= max_bd
Ct表示t时刻缓存, Ut表示t时刻的使用量, Xt表示t时刻还可以使用的量
免费可用容量 freeuse_bandwidth:
// (Ct + Ut + Xt) <= v95 or maxbd
// A1 = (Ct + Ut + Xt) * 0.05 + Ut+1 <= v95 or maxbd
// A2 = A1 * 0.05 + Ut+2 <= v95 or maxbd
// A3 = A2 * 0.05 + Ut+3 <= v95 or maxbd
// A4 = A3 * 0.05 + Ut+4 <= v95 or maxbd
解释同上, 当t被选为白嫖时刻时, 不等式右边取max_bd,否则取v95
题意中,每个边缘节点的最大带宽为100 0000,也就是最多经过4次5%衰减后缓存值的变化会<1。因此我们约束只取到t+4。同理,为了加快运算,更新缓存也可只更新未来5个时刻。然而,一种corner case是缓存一直+1,甚至直到最后一个时刻,为了避免这种情况产生不合法解,我们只能更新到最后一个时刻,但这样做显然代价过大得不偿失。我们稍后再处理这种情况。
预处理部分也要考虑中心节点的代价,因此将客户需求按流量类型排序,同类型从大到小排,类型之间按该类的总需求量大到小排。这样可以使得同类型流尽可能地被分配在同一个节点上,从而降低中心成本。
此外,边缘节点的处理顺序还是有讲究,度大的节点会吸收尽可能多的同类需求从而优化中心成本。因此在这里,采用(最大带宽*度) 降序排,会取得一个相对稳定的结果(但也不好说)。
3.2 分配剩余需求
在分配阶段,按t=0-T的处理顺序,采用了如下的优先级分配规则:
- 优先选择白嫖时刻的边缘节点,如果有多个,则优先打到 存在该类型流流量最多的节点。否则权衡剩余免费空间和节点的度综合选择一个(空间倾向大,度倾向小)。
- 优先选择具有免费空间(放入当前需求后小于该节点的v95)的边缘节点,如果有多个,则优先打到 存在该类型流流量最多的节点。否则权衡剩余免费空间和节点的度综合选择一个(空间倾向大,度倾向小)。
- 如果需要扩容(放入当前需求后大于该节点v95),则倾向选择(剩余免费空间大、度大)的节点。
- 还有一种特殊的扩容,在头几个时刻,该边缘节点v95还很小,由预处理的缓存导致了一些较大的带宽用量(但这些时刻并不会被标记为白嫖时刻,它们只作为白嫖时刻的缓存,在v95很小时,这些时刻会被认为是后5%)。在t很小时,有些需求只能放到这类边缘节点上去,可以理解为也是扩容的一种,但v95还无法起指导作用。这一阶段的选择对后续成本影响较大,非常重要。将之以正常扩容区分开,倾向选择(当前使用量小、度大)的节点。
3.3 其他修改
迁移:由于线上数据感觉边缘成本的重要性更大,我们采用121的迁移模式。“1”即不管中心节点成本的情况下尽可能迁移使得边缘成本降低。“2”即锁定边缘v95时尽可能降低中心的成本(搬出只在该边缘分配一次的流量类型)。第三个"1"代表确定中心的后5%时刻后,尽可能降低这些时刻的边缘成本(此时可以控制中心成本不涨,但实际操作中还是没有约束那么死,放开让中心涨一些反而线上分数更优,也算是个玄学)
关机:同复赛方案。
再次优化代码,线上训练赛两个数据集用时大约12~15s,应该还是有不少的优化空间。
并行搜索:为充分压榨机器,我们控制了内存使用,通过四核并行搜索并最终reduce得到最优解。搜索范围主要就是不同的预分配、分配策略、预分配的排序、分配策略不同倾向的权衡、以及关机的节点等(也因此太过混乱导致代码形成屎山)。
解的修复:刚才提到缓存只更新到t+4时刻,而"后面很多个时刻缓存都要+1",这种corner case是没有正确更新的。也就是说,在上述框架下有可能出现"使用量+缓存"大于最大带宽的情况。因此,在得到最优解后,从t=0开始对所有缓存进行矫正,同时对解进行合法性校验,记录不合法的解并尝试通过迁移使得解合法化。由于不合法的流量非常少,我们可以将缓存更新到最后一个时刻T,计算可用带宽时也可用从T开始逆推,从而保证结果正确性。
上述框架帮助我们在决赛训练赛中长期霸占第一的位置,在最后关头被周五快乐小超了一点。
3.4 正赛
决赛现场的正赛中,新增了一个需求:每个时刻可以任选20台机器,他们的缓存保留率在下一时刻将被设置为0.01。
正赛现场写了点BUG,导致很久没出成绩。最后匆匆选择了前一时刻使用量最大的20台机器作为输出,简单更新了一下可用带宽、免费可用带宽的计算函数,但在上述搜索框架下,对结果没有很大的影响。现场看着同学们不断上分,猜测他们一定是发现了什么trick而自己没有发现任何东西内心焦虑无比。最终也是没有发现任何东西草草结束比赛。
赛后交流发现,我们疏忽了最重要的一点:预处理中 cache_num(留给缓存从而避免v95过大的天数)的计算还是按0.05的来。而事实上,每个时刻可以有20台节点的缓存保留率被设为0.01,同一时刻有20台边缘同时被白嫖的概率几乎没有,因此可以直接假设:所有边缘节点白嫖时缓存保留率全为0.01。
这意味着什么呢?意味着预处理阶段能够免费吸收的流量会增加不少,而我们完全没有利用这一点。
正赛现场还是太过紧张了,如果能够冷静地全链路分析一遍应该还是能够轻易发现这一问题的。
最终决赛第5名,相比去年也算进步,但也是有些可惜,吸取教训。
最后,感谢华为!从抵达深圳到离开深圳,全程都感谢主办方的付出。比赛结束到现在又摸了一周多的 ,终于把它写完了。非常感谢两个月以来妖哥和我的共同努力,我们俩探讨了也尝试了许多玄学不玄学的方案,感谢栗子总两个月以来陪无聊的我吹牛不收费!下个比赛我们再接再厉!