分布式降级,限流,熔断
雪崩场景:
对于一个复杂的分布式服务来说,单个微服务处理自己的业务逻辑,这样做的好处是能够解决服务之间的依赖,降低耦合。同样也能够进行水平扩容,提高吞吐量。
但是在实际的过程中,我们往往一个服务会调用多个服务(中间以rpc作为通讯),如果其中一个服务提供者(provider)由于某些原因导致不可用,那么其他服务也会阻塞,最终导致整个系统面临崩溃的危险,而这及时雪崩场景
如下图所示 AB服务调用C,C服务调用D,这也是所谓的"扇出",此时由于某些原因,在扇出的链路上D服务响应过慢或者不可用,这个时候C服务的请求越来越多 而得不到处理,进而导致AB服务都出现问题
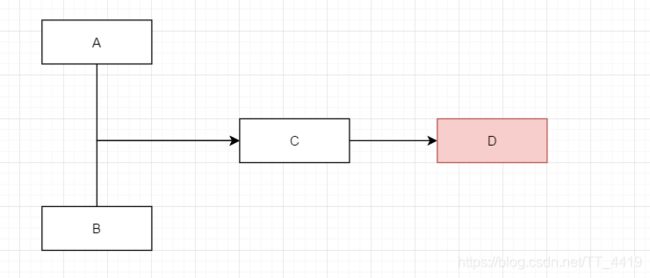
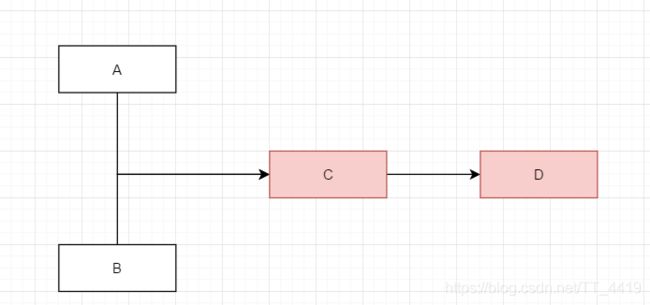

雪崩是系统中的蝴蝶效应导致其发生的原因多种多样,有不合理的容量设计,或者是高并发下某一个方法响应变慢,亦或是某台机器的资源耗尽。从源头上我们无法完全杜绝雪崩源头的发生,但是雪崩的根本原因来源于服务之间的强依赖,所以我们可以提前评估,做好相关措施。
预防机制
在开发高并发系统时有三把利器用来保护系统:缓存、降级和限流。
缓存:
目的是提升系统访问速度和增大系统能处理的容量,在实际的开发过程中,针对于一些基础档案类数据或者配置参数类数据,我们一般用缓存读取,原因是这些数据的变化性不大,这一部分我们可以减少和数据库的IO交互
缓存失效分为几种场景:1.缓存服务挂了 2.高分期缓存失效 3.热点缓存失效
解决方案:注意这里的校验是两次,这里参照单列模式的DCL双重校验锁机制。(嗯....讲道理这里要整一个 volatile 内存屏障 )

降级:
降级是指在某些高并发场景下,把某些非核心的业务统统往下调。诸如双11交易时,查看蚂蚁深林,蚂蚁庄园之类的服务,仅仅显示一百条数据。
当然降级的颗粒度 ,可以自由调配,根据实际业务和当前的服务器并发请求。比如说,你也可以限制数据库的跟新与插入,但是允许查询操作。
从RPC的角度来说,我访问的是本地服务的伪装者,而不是应用服务本身。
限流:
限流指的是降低一定时间内的并发访问量 一般两种做法 一种是拉长时间,一种是降低访问QPS()
一般开发高并发系统常见的限流有:限制总并发数(比如数据库连接池、线程池)、限制瞬时并发数(如nginx的limit_conn模块,用来限制瞬时并发连接数)、限制时间窗口内的平均速率(如Guava的RateLimiter、nginx的limit_req模块,限制每秒的平均速率);其他还有如限制远程接口调用速率、限制MQ的消费速率。另外还可以根据网络连接数、网络流量、CPU或内存负载等来限流。
限流算法:
限流算法一般分为以下几种:滑动窗口,漏桶,令牌桶.
滑动窗口:
发送和接受方都会维护 一 个数据帧的序列,这个序列被称作窗口。发送方的窗口大小由接受方确定,目 的在于控制发送速度,以免接受方的缓存不够大,而导致溢出,同时控制流量也可以避免网络拥塞。下 面图中的 4,5,6 号数据帧已经被发送出去,但是未收到关联的 ACK , 7,8,9 帧则是等待发送。可以看出发送 端的窗口大小为 6 ,这是由接受端告知的。此时如果发送端收到 4 号 ACK ,则窗口的左边缘向右收缩,窗 口的右边缘则向右扩展,此时窗口就向前 滑动了 ,即数据帧 10 也可以被发送。

这个是滑动窗口的演示地址,很形象
https://media.pearsoncmg.com/aw/ecs_kurose_compnetwork_7/cw/content/interactiveanimations/selective-repeat-protocol/index.html

漏桶(控制传输速率 leaky bucket):
漏桶算法思路是,不断的往桶里面注水,无论注水的速度是大还是小,水都是按固定的速率往外漏水; 如果桶满了,水会溢出;
桶本身具有 一 个恒定的速率往下漏水,而上方时快时慢的会有水进入桶内。当桶还未满时,上方的水可 以加入。 一 旦水满,上方的水就无法加入。
桶满正是算法中的 一 个关键的触发条件(即流量异常判断成 立的条件)。而此条件下如何处理上方流下来的水,有两种方式
在桶满水之后,常见的两种处理方式为:
1 )暂时拦截住上方水的向下流动,等待桶中的 一 部分水漏走后,再放行上方水。
2 )溢出的上方水直接抛弃。
特点
1. 漏水的速率是固定的
2. 即使存在突然注水量变大的情况,漏水的速率也是固定的

令牌桶(解决突发流量)
令牌桶算法是网络流量整形(Traffiffiffic Shaping)和速率限制(Rate Limiting)中最常使用的 一 种算法。 典型情况下,令牌桶算法用来控制发送到网络上的数据的数目,并允许突发数据的发送。
令牌桶是 一 个存放固定容量令牌(token)的桶,按照固定速率往桶里添加令牌; 令牌桶算法实际上由三 部分组成:两个流和 一 个桶,分别是令牌流、数据流和令牌桶
令牌流与令牌桶
系统会以 一 定的速度生成令牌,并将其放置到令牌桶中,可以将令牌桶想象成 一 个缓冲区(可以用队列 这种数据结构来实现),当缓冲区填满的时候,新生成的令牌会被扔掉。
这里有两个变量很重要: 第 一 个是生成令牌的速度, 一 般称为 rate 。比如,我们设定 rate = 2 ,即每秒钟生成 2 个令牌,也就 是每 1/2 秒生成 一 个令牌;
第二个是令牌桶的大小, 一 般称为 burst 。比如,我们设定 burst = 10 ,即令牌桶最大只能容纳 10 个 令牌。
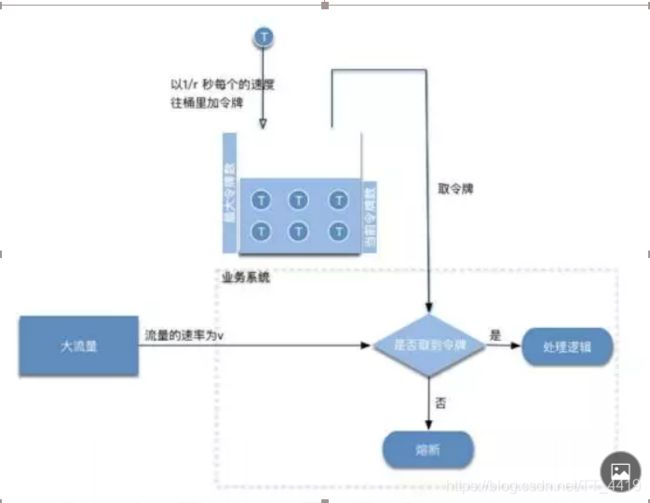
有以下三种情形可能发生:
数据流的速率 等于 令牌流的速率 。这种情况下 , 每个到来的数据包或者请求都能对应 一 个令牌 , 然 后无延迟地通过队列;
数据流的速率 小于 令牌流的速率 。通过队列的数据包或者请求只消耗了 一 部分令牌,剩下的令牌 会在令牌桶里积累下来,直到桶被装满。剩下的令牌可以在突发请求的时候消耗掉。
数据流的速率 大于 令牌流的速率 。这意味着桶里的令牌很快就会被耗尽。导致服务中断 一 段时 间,如果数据包或者请求持续到来 , 将发生丢包或者拒绝响应。
处理机制
熔断:
熔断机制是应对雪崩效应的一种微服务链路保护机制。在微服务中,扇出的微服务不可用或者相应时间过长的话会对服务降级,进而熔断该服务节点,快速返回错误信息,释放资源。
而当检测到微服务响应正常后,则恢复调用。
隔离 :
这种模式就像对系统请求按类型划分成一个个小岛的一样,当某个小岛被火烧光了,不会影响到其他的小岛。
例如可以对不同类型的请求使用线程池来资源隔离,每种类型的请求互不影响,如果一种类型的请求线程资源耗尽,则对后续的该类型请求直接返回,不再调用后续资源。
这种模式使用场景非常多,例如将一个服务拆开,对于重要的服务使用单独服务器来部署,再或者公司最近推广的多中心。
熔断设计
在熔断的设计主要参考了hystrix的做法。其中最重要的是三个模块:熔断请求判断算法、熔断恢复机制、熔断报警
(1)熔断请求判断机制算法:使用无锁循环队列计数,每个熔断器默认维护10个bucket,每1秒一个bucket,每个blucket记录请求的成功、失败、超时、拒绝的状态,默认错误超过50%且10秒内超过20个请求进行中断拦截。
(2)熔断恢复:对于被熔断的请求,每隔5s允许部分请求通过,若请求都是健康的(RT<250ms)则对请求健康恢复。
(3)熔断报警:对于熔断的请求打日志,异常请求超过某些设定则报警。
隔离设计
隔离的方式一般使用两种
(1)线程池隔离模式:使用一个线程池来存储当前的请求,线程池对请求作处理,设置任务返回处理超时时间,堆积的请求堆积入线程池队列。这种方式需要为每个依赖的服务申请线程池,有一定的资源消耗,好处是可以应对突发流量(流量洪峰来临时,处理不完可将数据存储到线程池队里慢慢处理)
(2)信号量隔离模式:使用一个原子计数器(或信号量)来记录当前有多少个线程在运行,请求来先判断计数器的数值,若超过设置的最大线程个数则丢弃改类型的新请求,若不超过则执行计数操作请求来计数器+1,请求返回计数器-1。这种方式是严格的控制线程且立即返回模式,无法应对突发流量(流量洪峰来临时,处理的线程超过数量,其他的请求会直接返回,不继续去请求依赖的服务)
服务降级与熔断的相关异同点:
相同点:
目的很一致,都是从可用性可靠性着想,为防止系统的整体缓慢甚至崩溃,采用的技术手段;
最终表现类似,对于两者来说,最终让用户体验到的是某些功能暂时不可达或不可用;
粒度一般都是服务级别,当然,业界也有不少更细粒度的做法,比如做到数据持久层(允许查询,不允许增删改);
自治性要求很高,熔断模式一般都是服务基于策略的自动触发,降级虽说可人工干预,但在微服务架构下,完全靠人显然不可能,开关预置、配置中心都是必要手段;
区别:
触发原因不太一样,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(比如降级一般是从最外围服务开始)
实现方式不太一样;服务降级具有代码侵入性(由控制器完成/或自动降级),熔断一般称为自我熔断。
参考博客: https://www.jianshu.com/p/c0937bf9849d
https://blog.csdn.net/llianlianpay/article/details/79768890
实际项目(springboot+dubbo+sentinel)
1.整体dubbo服务搭建

父子工程,整体由api服务暴露者和provider服务处理者
api有且仅有一个对外的接口暴露

看一下 provider的pom.xml

服务端一个具体实现类,注意是用dubbo的service

application.properties 配置服务的相关信息 以properties启动dubbo服务

看一下web服务(也就是我们常常说的controller)


效果图:

如果以上配置完成的话,代表至少这个dubbo的项目是能跑了,但是现在限流,并没有直接关系
2.引入sentinel.jar进行管理
先看一下provider的pom.xml 这里引入了一个核心jar,如果要看你控制台的话,还需要引入 sentinel-transport-simple-http

引入完监控之就是这样了

代码中需要配置限流规则
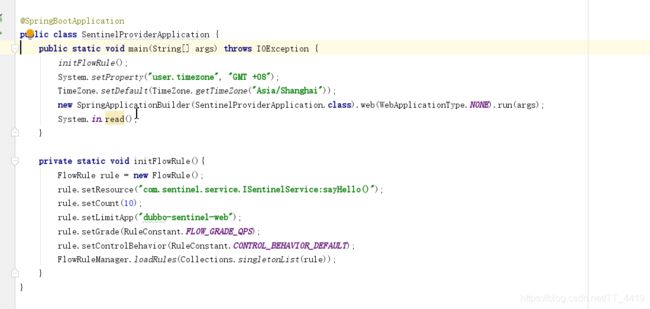
这里需要解释一下,各个参数的意义(详情可以参考官方文档 http://dubbo.apache.org/zh-cn/blog/sentinel-introduction-for-dubbo.html )
以及https://github.com/alibaba/Sentinel/wiki/%E6%B5%81%E9%87%8F%E6%8E%A7%E5%88%B6
-
resource :资源名,即限流规则的作用对象
-
count : 限流阈值
-
grade : 限流阈值类型(QPS 或并发线程数)
-
limitApp : 流控针对的调用来源,若为 default 则不区分调用来源
-
strategy : 调用关系限流策略
-
controlBehavior : 流量控制效果(直接拒绝、Warm Up、匀速排队)
其中的resource 指的是类名全路径 加上方法签名以及参数(参数是 java.lang.String的形式的)
count+grade 指的是限制你每秒多少个并发线程数还是QPS
limitApp指的是 我对哪些来源进行限制
controlBehavior指的是控制行为 分为以下三种:
直接拒绝(RuleConstant.CONTROL_BEHAVIOR_DEFAULT)方式是默认的流量控制方式,当QPS超过任意规则的阈值后,新的请求就会被立即拒绝,拒绝方式为抛出FlowException。这种方式适用于对系统处理能力确切已知的情况下,比如通过压测确定了系统的准确水位时。
warm Up(RuleConstant.CONTROL_BEHAVIOR_WARM_UP)方式,即预热/冷启动方式。当系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过"冷启动",让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮。详细文档可以参考 流量控制 - Warm Up 文档,具体的例子可以参见 WarmUpFlowDemo。
通常冷启动的过程系统允许通过的 QPS 曲线如下图所示:

匀速排队(RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER)方式会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。详细文档可以参考 流量控制 - 匀速器模式,具体的例子可以参见 PaceFlowDemo。
该方式的作用如下图所示:

这种方式主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。
到这一步 单体服务的限流本就可用了,我们调用一下Jmeter来看一下请求的效果
这边请求是瞬时50个请求

然后成功了10个,因为我QPS设置了10个

同样的,我们可以对来源进行区分,只限制A请求,而不限制B请求
具体如下操作:
1.限流规则中配置LimitApp

2.web请求中controller声明来源

此刻将请求切换为noSayHello

效果如下

而当超过限制的QPS范围之后,后台的报错如下。当然了这里后续可用加入一大堆业务逻辑处理

3.关于搭建引起的一系列的坑以及注意点
1.provider要用dubbo的形式启动服务,如果没有任何封装的话,不要忘记在Application上加上线程阻塞,避免主线程关闭。如果是用第三方起来的,则不用加上线程阻塞

2.zk注册服务注册不了,后来发现dubbo的依赖没有引完,需要两个 分别是 dubbo-spring-boot-starter 以及 dubbo

3.注意zookeeper与curator的版本问题

4.注意sentinel与dubbo的版本兼容性问题


就是这个,我sentinel用1.6.3 之前dubbo用2.7.0就报错 关键是每次都是报限制规则中resource的资源找不到,我一直以为是路径问题。
分布式实现限流规则
刚刚其实演示的只是单机情况下,限流的规则以及应用。但是存在这样的业务场景,我们如果对接的一个第三方系统的话,他要求限制入库的qps,那么我们需要对整体的接入的qps做限制,这里看一下架构图

抽象出tokenServer(貌似没有一个官方的成熟的,要自己手写) 用于管理限流规则,Nacos用于动态的配置规则,同时单个应用服务,也注册到nacos中
——------------------------------------------------------------v2.0
增加 sentinel熔断规则及其参数配置
压测熔断
问题分析以及猜想
熔断策略
我们通常用以下几种方式来衡量资源是否处于稳定的状态:
- 平均响应时间 (
DEGRADE_GRADE_RT):当 1s 内持续进入 5 个请求,对应时刻的平均响应时间(秒级)均超过阈值(count,以 ms 为单位),那么在接下的时间窗口(DegradeRule中的timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地熔断(抛出DegradeException)。注意 Sentinel 默认统计的 RT 上限是 4900 ms,超出此阈值的都会算作 4900 ms,若需要变更此上限可以通过启动配置项-Dcsp.sentinel.statistic.max.rt=xxx来配置。 - 异常比例 (
DEGRADE_GRADE_EXCEPTION_RATIO):当资源的每秒请求量 >= 5,并且每秒异常总数占通过量的比值超过阈值(DegradeRule中的count)之后,资源进入降级状态,即在接下的时间窗口(DegradeRule中的timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地返回。异常比率的阈值范围是[0.0, 1.0],代表 0% - 100%。 - 异常数 (
DEGRADE_GRADE_EXCEPTION_COUNT):当资源近 1 分钟的异常数目超过阈值之后会进行熔断。注意由于统计时间窗口是分钟级别的,若timeWindow小于 60s,则结束熔断状态后仍可能再进入熔断状态。
配置规则

服务响应时间

压测结果:
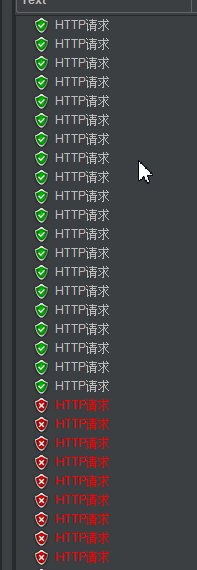
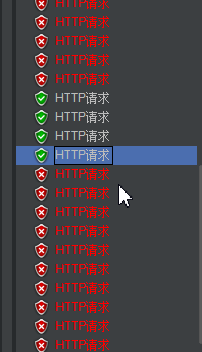
根据官方文档的说法 我来解释一下这个策略情况:
在一秒内接入5个请求 平均请求的相应时间超过设置的10ms,则进入限流模式,在接下来的1s(滑动窗体时间内)不在接收到请求。
等到一秒过后,在次接入请求,同时继续计算平均相应时间,如果不符合策略要求,则再一次进行限流
但是我发现了一个现象,觉得很奇怪。
第一次进来的时候,访问了很多请求,这个我可以理解 因为它拿出了5个请求,做对比,通知限流,开启限流策略,而这些操作都是需要时间的,在这一段时间内,请求时不会被拦截的。但是再限制的滑动窗体走过之后,这里有只有四个请求,但是官方文档上说的时拿五个请求做比较。
猜测:
在抛开官方文档编写错误的情况下,我认为可能的情况是,精准的在高并发场景下,获取5个线程是不可靠的。
首先,准确的记录是 需要增加内存读写屏障,来确保数据的准确性(参考volatile),而在获取平均相应时间和设置阈值之间做比较 也是需要时间的(参考 int i++ 并发累计问题),然而在这种业务场景下,我们对准确性 要求没有那么高。
这边也有阿里提供的官方实例:
https://github.com/alibaba/Sentinel/blob/master/sentinel-demo/sentinel-demo-basic/src/main/java/com/alibaba/csp/sentinel/demo/degrade/RtDegradeDemo.java
效果是一样的,也是先进来,计算并触发熔断策略,在滑动时间过后,再次接入一堆请求,在进行计算又触发熔断策略。
