拓扑排序-信息学奥赛
拓扑排序
制作人:(CwinSpider)
文章目录
- 拓扑排序
-
- 一、前置知识
- 二、知识讲解
-
- 1. 什么是拓扑排序?
- 2. 拓扑排序的实现
- 3. 拓扑排序的应用
- 4. 拓扑排序的复杂度分析
- 三、课堂练习题
-
- 课堂练习(一)
- 课堂练习(二)
- 四、精选例题
-
- 例题1
- 例题2
- 五、总结
- 六、课后作业
一、前置知识
- 图的基本概念
- 深度优先搜索(DFS)和广度优先搜索(BFS)算法
- 队列和栈的基本操作
二、知识讲解
1. 什么是拓扑排序?
拓扑排序是一种对有向无环图(DAG)进行排序的算法。拓扑排序的结果是一个有序的顶点列表,其中每个顶点只出现一次,且满足:若存在一条从顶点A到顶点B的边,那么在排序结果中,顶点A出现在顶点B的前面。
拓扑排序算法主要包括以下几个步骤:
- 找到所有入度为0的顶点,并将它们放入一个队列中。
- 对于队列中的每个顶点,将其出度的边删除,并将出度变为0的相邻顶点入队。
- 重复步骤2直到队列为空,或所有顶点都已经被处理过。
2. 拓扑排序的实现
我们可以使用邻接表来表示有向无环图,并使用一个数组 i n d e g r e e [ ] indegree[] indegree[] 来记录每个顶点的入度。具体实现步骤如下:
2.1 数据准备
#include 备注:数据准备阶段,可以使用邻接表来距离图中顶点的指向边;另外使用一维数组indegree来存放顶点的入度数量。
2.2 主函数
int main() {
int n, m;
cin >> n >> m;
// 读入有向图
for (int i = 0; i < m; i++) {
int u, v;
cin >> u >> v;
G[u].push_back(v);
indegree[v]++;
}
if (topological_sort(n)) {
// 输出拓扑排序的结果
for (int i = 1; i <= n; i++) {
cout << i << " ";
}
cout << endl;
} else {
cout << "存在环路,排序失败!" << endl;
}
return 0;
}
备注:a.读入每个顶点的指出边存放到 邻接表 中,b.调用拓扑排序函数,根据 函数的返回值 来确定是否构成有 向无环图,如果可以则输出每个顶点DAG后的顺序,否则处理存在 环路 的情况。
2.3 核心代码
bool topological_sort(int n) {
queue<int> q; // 存放入度为0的顶点
for (int i = 1; i <= n; i++) {
if (indegree[i] == 0) {
q.push(i);
}
}
while (!q.empty()) {
int u = q.front();
q.pop();
for (auto v : G[u]) {
indegree[v]--;
if (indegree[v] == 0) {
q.push(v);
}
}
}
for (int i = 1; i <= n; i++) {
if (indegree[i] != 0) {
return false; // 存在环路,排序失败
}
}
return true; // 排序成功
}
备注:核心代码的流程,a.利用队列来进行层序遍历(BFS的特点就是可以在当前结点遍历前确定好上一层父节点的所有信息)。b.查找所有顶点入度为 0 0 0 的顶点入队(入度为 0 0 0 代表着什么?代表着优先级高哇!没有结点指向它,说明它不需要完成前置任务。)。c.按照队列存放的结点 x x x 逐个遍历,遍历的过程中追溯每个结点指出的边对应的结点 y y y ,将该节点入度值减一(为什么减一?现在已经到达了 x x x 结点工作了,如果 x x x 结点对应的 y y y 任务做完,那么 x x x ⟶ \longrightarrow ⟶ y y y 这条边就可以删除了),删除后立刻判断该结点 y y y 的入度是否为 0 0 0,如果是说明该结点也成为了没有前置任务的点,可以加入到队列中。重复执行步骤 c ,直到所有结点从队列中出队,此时已完成拓扑排序(DAG)。d.循环处理后的入度数组 i n d e g r e e [ ] indegree[] indegree[] 如果还存在入度值不等于 0 0 0 的结点,说明存在有向环图,不适合用该算法处理,否则为有向无环图。
看一组图+视频来解释DAG的运行过程:
a.以下是不是有向无环图?

是的,因为所有结点符合不存在环图,且是有向图。
b.接下来我们来观看拓扑排序的过程([视频],由于GIF图太模糊)。
拓扑排序的动图展示
3. 拓扑排序的应用
拓扑排序经常用于解决任务调度问题,例如在编译器中,需要对源代码进行编译,但是源代码之间存在依赖关系,即某些 源代码 必须先被 编译 才能 编译其他源代码 。这个问题可以抽象成一个有向无环图,其中每个源代码是一个顶点,源代码之间的依赖关系是有向边。在这个图上进行拓扑排序,就可以得到源代码的编译顺序。
4. 拓扑排序的复杂度分析
拓扑排序的时间复杂度为 O ( V + E ) O(V+E) O(V+E),其中 V V V 和 E E E 分别为图的顶点数和边数。因为需要遍历每个顶点和每条边,所以时间复杂度与图的大小成线性关系。
三、课堂练习题
课堂练习(一)
B3644 【模板】拓扑排序 / 家谱树 普及-
题目描述
有个人的家族很大,辈分关系很混乱,请你帮整理一下这种关系。给出每个人的后代的信息。输出一个序列,使得每个人的后辈都比那个人后列出。
输入格式
第 1 1 1 行一个整数 N N N( 1 ≤ N ≤ 100 1 \le N \le 100 1≤N≤100),表示家族的人数。接下来 N N N 行,第 i i i 行描述第 i i i 个人的后代编号 a i , j a_{i,j} ai,j,表示 a i , j a_{i,j} ai,j 是 i i i 的后代。每行最后是 0 0 0 表示描述完毕。
输出格式
输出一个序列,使得每个人的后辈都比那个人后列出。如果有多种不同的序列,输出任意一种即可。
样例输入
5
0
4 5 1 0
1 0
5 3 0
3 0
样例输出
2 4 5 3 1
如下图所示(本题抽象后的图形)

AC_Code
#include 课堂练习(二)
P1807 最长路 普及/提高-
本题注意包含(动态规划思想)
题目描述
设 G G G 为有 n n n 个顶点的带权有向无环图, G G G 中各顶点的编号为 1 1 1 到 n n n,请设计算法,计算图 G G G 中 1 , n 1, n 1,n 间的最长路径。
输入格式
输入的第一行有两个整数,分别代表图的点数 n n n 和边数 m m m。
第 2 2 2 到第 ( m + 1 ) (m + 1) (m+1) 行,每行 3 3 3 个整数 u , v , w u, v, w u,v,w( u < v u
输出格式
输出一行一个整数,代表 1 1 1 到 n n n 的最长路。
若 1 1 1 无法到达 n n n,请输出 − 1 -1 −1。
提示
【数据规模与约定】
- 对于 20 % 20\% 20%的数据, n ≤ 100 n \leq 100 n≤100, m ≤ 1 0 3 m \leq 10^3 m≤103。
- 对于 40 % 40\% 40% 的数据, n ≤ 1 0 3 n \leq 10^3 n≤103, m ≤ 1 0 4 m \leq 10^{4} m≤104。
- 对于 100 % 100\% 100% 的数据, 1 ≤ n ≤ 1500 1 \leq n \leq 1500 1≤n≤1500, 0 ≤ m ≤ 5 × 1 0 4 0 \leq m \leq 5 \times 10^4 0≤m≤5×104, 1 ≤ u , v ≤ n 1 \leq u, v \leq n 1≤u,v≤n, − 1 0 5 ≤ w ≤ 1 0 5 -10^5 \leq w \leq 10^5 −105≤w≤105。
样例输入
2 1
1 2 1
样例输出
1
新增数据点
5 6
1 2 1
2 3 2
3 5 3
1 4 1
4 5 2
3 4 1
输出
3
下图给出新增数据点的连接图

可以从图中看出,1->5的最短路径为1->4->5,路径长度为1+2=3。
本题注意坑点:
-
题目已经保证了点 1 是起点,而且不会出现环,满足了拓扑排序的要求。但是题目**却没有保证只有点 1 是如度为 0 的点。**所以要判断其他入度为 0 的点 x x x,按照以往的操作我们是将该点 x x x 加入到队列中,但这次不能这么操作,为什么呢?
-
因为该点 x x x 是本身是无法到达的点,且不可能延伸其他地方,如果入队了会导致个别点,甚至所有点的答案错误。那么我们是置于它不管吗?还是错!为什么错?
-
如果不管,那么延伸出来的点的入度永远大于0,可能会导致永远无法到达终点!如何解决呢?
-
正确的做法,将这些点 x x x 所能延伸的点 y y y 入度 减 1,注意!如果这些延伸的点 y y y 减 1 后还是为0,做上述同样的处理。
-
至于一个点的最长路的转移方程就是:
m i n ( 入度 1 + 对应边,入度 2 + 对应的边 . . . 入度 n + 对应的边 ) min({入度1 + 对应边,入度2 + 对应的边 ... 入度n + 对应的边}) min(入度1+对应边,入度2+对应的边...入度n+对应的边)
AC_Code
#include 四、精选例题
例题1
P4017 最大食物链计数 普及/提高-(拓扑排序)
题目背景
你知道食物链吗?Delia 生物考试的时候,数食物链条数的题目全都错了,因为她总是重复数了几条或漏掉了几条。于是她来就来求助你,然而你也不会啊!写一个程序来帮帮她吧。
题目描述
给你一个食物网,你要求出这个食物网中最大食物链的数量。
(这里的“最大食物链”,指的是生物学意义上的食物链,即最左端是不会捕食其他生物的生产者,最右端是不会被其他生物捕食的消费者。)
Delia 非常急,所以你只有 1 1 1 秒的时间。
由于这个结果可能过大,你只需要输出总数模上 80112002 80112002 80112002 的结果。
输入格式
第一行,两个正整数 n 、 m n、m n、m,表示生物种类 n n n 和吃与被吃的关系数 m m m。
接下来 m m m 行,每行两个正整数,表示被吃的生物A和吃A的生物B。
输出格式
一行一个整数,为最大食物链数量模上 80112002 80112002 80112002 的结果。
样例输入 #1
5 7
1 2
1 3
2 3
3 5
2 5
4 5
3 4
样例输出 #1
5
抽象成图所示
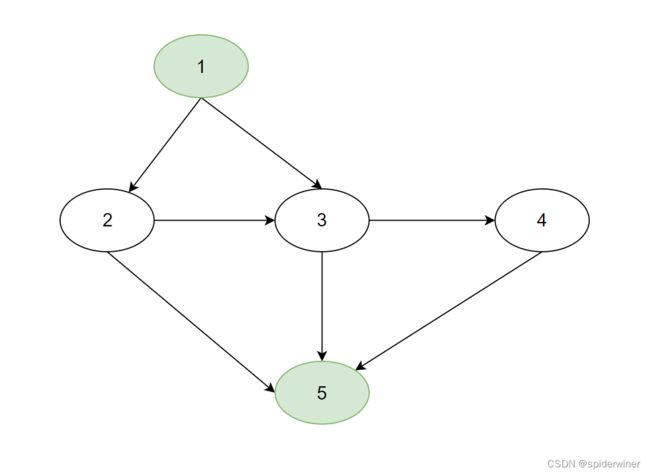
提示和补充说明
各测试点满足以下约定:
n ≤ 5000 , m ≤ 500000 n\leq5000,m\leq500000 n≤5000,m≤500000
【补充说明】
给出解题思路(仅作参考)
这道题目是一道 DAG 上的动态规划问题(DP+DAG),需要用到 DAG 的拓扑排序来解决。
首先,我们可以根据题目中的要求, 将 DAG 中的点按照它们的拓扑序排列。 这个过程可以使用拓扑排序来实现。在拓扑排序的过程中,我们需要用到一个队列,将入度为 0 的点加入队列中,并顺序遍历它们的后继节点,更新它们的状态。
在本题中,我们需要求出从 起点到终点的最长路径条数。 为了求出最长路径条数,我们需要 对每个点记录一下从起点到该点的最长路径条数。 状态转移方程推导过程:设 f ( i ) f(i) f(i) 表示从起点到点 i i i 的最长路径条数。因为该 DAG 是有向无环图,所以我们可以使用拓扑排序的顺序,从起点开始逐个遍历它们的后继节点 j j j,并更新最长路径条数: f ( j ) = f ( j ) + f ( i ) f(j) = f(j) + f(i) f(j)=f(j)+f(i)。
具体地,我们可以在拓扑排序中,每次从队列中弹出一个点 i i i 后,计算从起点到 i i i 的最长路径条数 f ( i ) f(i) f(i),然后遍历 i i i 的所有后继节点 j j j,并更新 f ( j ) f(j) f(j)。如果 j j j 的入度为 0,说明 j j j 的前置任务已经完成,可以将 j j j 加入队列中。
最后,我们只需要统计所有出度为 0 的点的最长路径条数之和,即为所求的结果。
需要注意的是,由于本题中的最长路径条数可能非常大,需要使用取模的方式来避免溢出。此外,如果 DAG 中存在环路,就无法进行拓扑排序,也就无法求出最长路径条数,此时需要特别处理。
以上就是本题的主要思路和实现方法。
数据中不会出现环,满足生物学的要求。
#include 批注:有需要的老师可以自行画图带着学生去理解,很简单不做图了。
例题2
P1113 杂务 普及/提高-(有向无环图)
题目描述
John的农场在给奶牛挤奶前有很多杂务要完成,每一项杂务都需要一定的时间来完成它。比如:他们要将奶牛集合起来,将他们赶进牛棚,为奶牛清洗乳房以及一些其它工作。尽早将所有杂务完成是必要的,因为这样才有更多时间挤出更多的牛奶。当然,有些杂务必须在另一些杂务完成的情况下才能进行。比如:只有将奶牛赶进牛棚才能开始为它清洗乳房,还有在未给奶牛清洗乳房之前不能挤奶。我们把这些工作称为完成本项工作的准备工作。至少有一项杂务不要求有准备工作,这个可以最早着手完成的工作,标记为杂务 1 1 1。John有需要完成的 n n n个杂务的清单,并且这份清单是有一定顺序的,杂务 k ( k > 1 ) k(k>1) k(k>1)的准备工作只可能在杂务 1 1 1至 k − 1 k-1 k−1中。
写一个程序从 1 1 1到 n n n读入每个杂务的工作说明。计算出所有杂务都被完成的最短时间。当然互相没有关系的杂务可以同时工作,并且,你可以假定John的农场有足够多的工人来同时完成任意多项任务。
输入格式
第1行:一个整数 n n n,必须完成的杂务的数目( 3 ≤ n ≤ 10 , 000 3 \le n \le 10,000 3≤n≤10,000);
第 2 2 2至 ( n + 1 ) (n+1) (n+1)行: 共有 n n n行,每行有一些用 1 1 1个空格隔开的整数,分别表示:
* 工作序号( 1 1 1至 n n n,在输入文件中是有序的);
* 完成工作所需要的时间 l e n ( 1 ≤ l e n ≤ 100 ) len(1 \le len \le 100) len(1≤len≤100);
* 一些必须完成的准备工作,总数不超过 100 100 100个,由一个数字 0 0 0结束。有些杂务没有需要准备的工作只描述一个单独的 0 0 0,整个输入文件中不会出现多余的空格。
输出格式
一个整数,表示完成所有杂务所需的最短时间。
样例输入
7
1 5 0
2 2 1 0
3 3 2 0
4 6 1 0
5 1 2 4 0
6 8 2 4 0
7 4 3 5 6 0
样例输出
23
粗略的图,凑合的看

开个玩笑,放上 整容后的图片 正经图
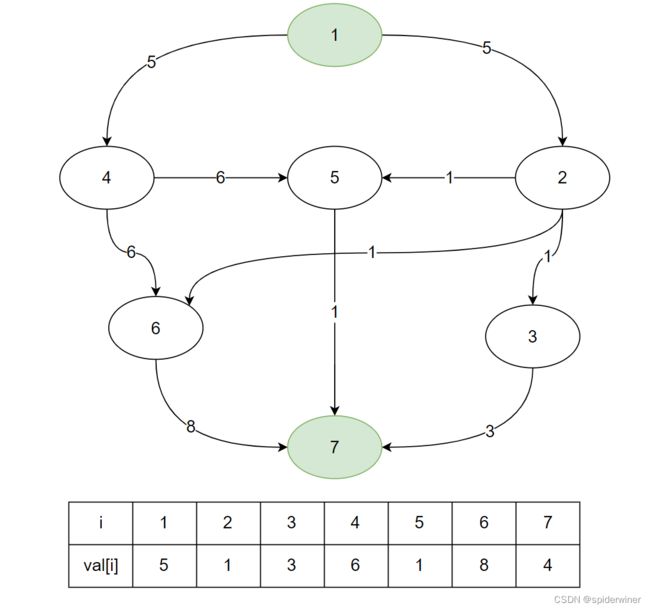
做题思路:
利用数组 f [ i ] f[i] f[i] 来维护完成任务 i i i 所记录的最短时间,然后在 B F S BFS BFS 的过程中去更新 f [ i ] f[i] f[i] 的值。
看下来来观察 f [ i ] f[i] f[i] 数组维护的过程。

如上图所示,顶点 1 1 1 的 f [ 1 ] f[1] f[1] 的值会更新为本身任务所做的时间 5 , f [ 1 ] = 5 5,f[1] = 5 5,f[1]=5,因为入度值为 0 0 0 的点先做,没有任务前置任务。
接下来观看,顶点 1 1 1 所连接的两条边的顶点 4 、 2 4、2 4、2 这两个点的最短时间值的变化 f [ 4 ] 、 f [ 2 ] f[4]、f[2] f[4]、f[2]。
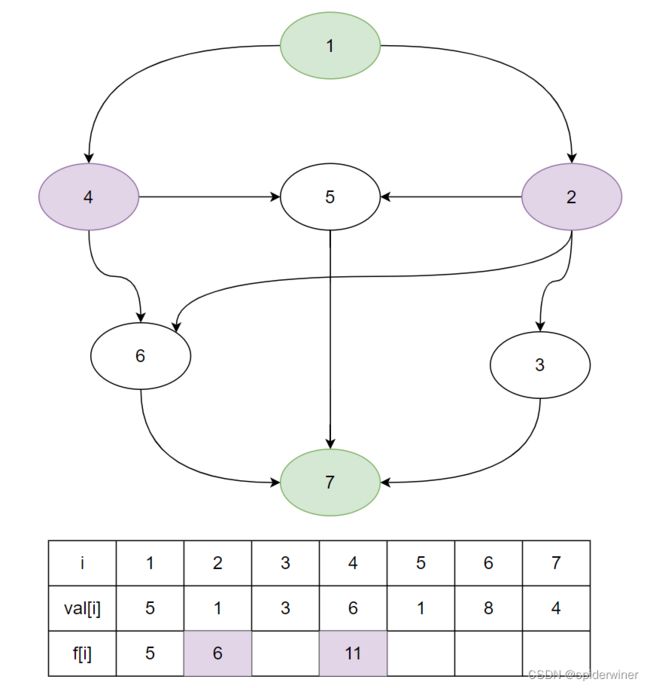
由于顶点 4 、 2 4、2 4、2 这两个点只需要前置的任务 1 1 1 就可以开始工作了,所以他们只在 f [ 1 ] f[1] f[1] 值上去更新。
f [ 2 ] = f [ 1 ] + v a l [ 2 ] = 5 + 1 = 6 f[2] = f[1] + val[2] = 5 + 1 = 6 f[2]=f[1]+val[2]=5+1=6
f [ 4 ] = f [ 1 ] + v a l [ 2 ] = 5 + 6 = 11 f[4] = f[1] + val[2] = 5 + 6 = 11 f[4]=f[1]+val[2]=5+6=11
接下来观看,顶点 2 2 2 所连接的两条边的顶点 6 、 3 、 5 6、3、5 6、3、5 ,这三个点的最短时间值的变化 f [ 6 ] 、 f [ 3 ] 、 f [ 5 ] f[6]、f[3]、f[5] f[6]、f[3]、f[5]。
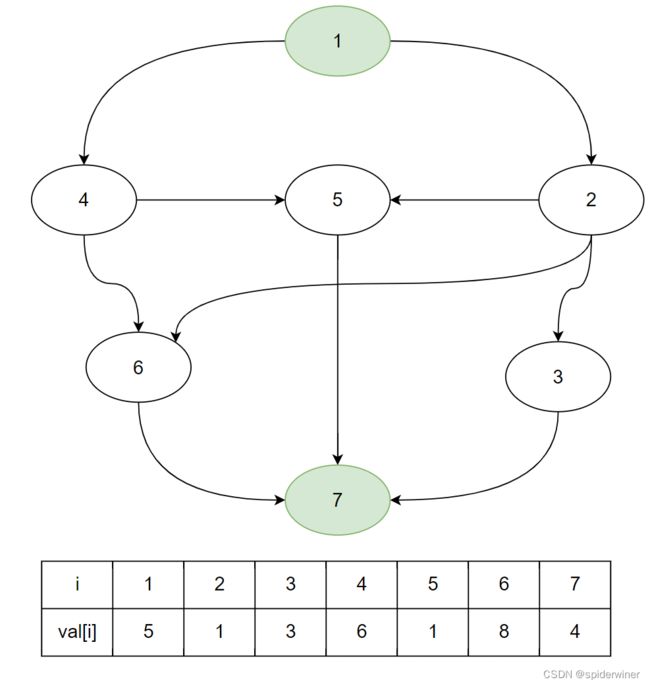
顶点 2 2 2 所能延伸的顶点是 3 、 5 、 6 3、5、6 3、5、6 ,这三个点,所虽然还有其他前置任务但是最先找到他们的任务是 2 2 2 ,所以先由顶点 2 2 2 来先更新顶点 3 、 5 、 6 3、5、6 3、5、6 这三个点的最短完成任务时间。
f [ 3 ] = f [ 2 ] + v a l [ 3 ] = 6 + 3 = 9 f[3] = f[2] + val[3] = 6 + 3 = 9 f[3]=f[2]+val[3]=6+3=9
f [ 5 ] = f [ 2 ] + v a l [ 5 ] = 6 + 1 = 7 f[5] = f[2] + val[5] = 6 + 1 = 7 f[5]=f[2]+val[5]=6+1=7
f [ 6 ] = f [ 2 ] + v a l [ 6 ] = 6 + 8 = 14 f[6] = f[2] + val[6] = 6 + 8 = 14 f[6]=f[2]+val[6]=6+8=14
接下来观看,顶点 4 4 4 所连接的两条边的顶点 5 、 6 5、6 5、6,这三个点的最短时间值的变化 f [ 5 ] 、 f [ 6 ] f[5]、f[6] f[5]、f[6]。

顶点 4 4 4 所能延伸的顶点是 5 、 6 5、6 5、6 ,这两个点,虽然还有其他前置任务但是顶点 4 4 4 是第二个找到他们的。为什么越更新得所需要得时间就越长啊???(思考一下)此时结点 5 、 6 5、6 5、6 不再是第一次被访问了(通俗一点:就是前置任务有多个,现在要找出前置当中做合计时长最长的那个作为本次任务的最短时间,为什么呢?因为我们任务是可以同时进行的呀!!!我们就可以找合计完成时间最长的任务来计算即可包括了所有的前置任务的完成时间),结论:找出完成当前任务 x x x 的前置任务 y y y + 完成任务 x x x 的时间的最大值。
直接上状态转移方程: f [ x ] = m a x ( f [ x ] , f [ y ] + v a l [ x ] ) f[x] = max( f[x],f[y] + val[x]) f[x]=max(f[x],f[y]+val[x])
超级简单的有没有?
f [ 5 ] = m a x ( f [ 5 ] , f [ 4 ] + v a l [ 5 ] = m a x ( 7 , 12 ) = 12 f[5] = max(f[5], f[4] + val[5] = max(7,12) = 12 f[5]=max(f[5],f[4]+val[5]=max(7,12)=12
f [ 6 ] = m a x ( f [ 6 ] , f [ 4 ] + v a l [ 6 ] ) = m a x ( 14 , 19 ) = 19 f[6] = max(f[6],f[4]+val[6]) = max(14,19) = 19 f[6]=max(f[6],f[4]+val[6])=max(14,19)=19
接下来观看,顶点 3 3 3 所连接的一条边的顶点 7 7 7,这个点的最短时间值的变化 f [ 7 ] f[7] f[7]。
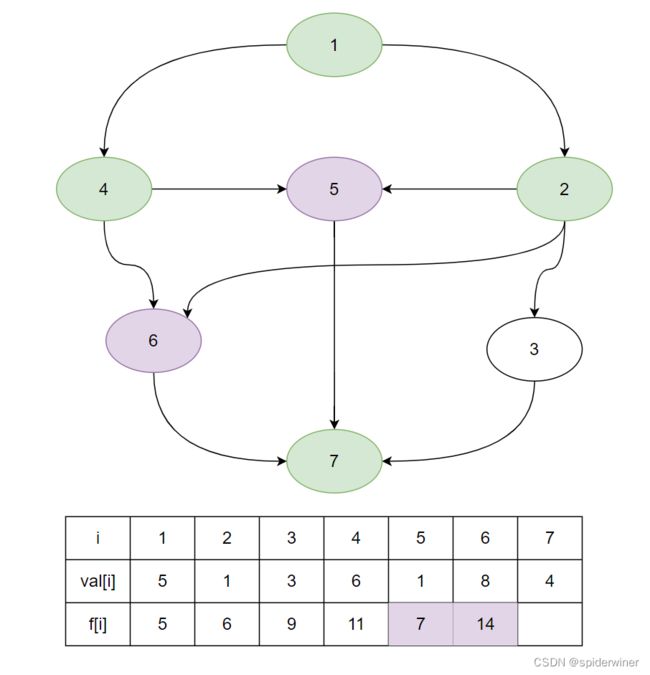
顶点 3 3 3 所能延伸的顶点是 7 7 7 ,这个点算是第一次被连接所以首次更新很简单,就只能来自于任务 3 3 3 完成的最短时间上加本身任务 7 7 7 完成的时间就为任务 7 7 7 的最短时间。
f [ 7 ] = f [ 3 ] + v a l [ 7 ] = 9 + 4 = 13 f[7] = f[3] + val[7] = 9 + 4 = 13 f[7]=f[3]+val[7]=9+4=13
接下来观看,顶点 5 5 5 所连接的一条边的顶点 7 7 7,这个点的最短时间值的变化 f [ 7 ] f[7] f[7]。
顶点 5 5 5 所能延伸的顶点是 7 7 7 ,这个点是第二次被连接所以要进行比对找出最大值,当前任务 7 7 7 所记录的最短完成任务时间 f [ 7 ] = 13 f[7]=13 f[7]=13,与任务 5 5 5 所记录的最短完成任务时间 f [ 5 ] f[5] f[5] + 完成任务7的任务时间 v a l [ 7 ] val[7] val[7] 进行对比。
f [ 7 ] = m a x ( f [ 7 ] , f [ 5 ] + v a l [ 7 ] ) = m a x ( 13 , 16 ) = 16 f[7] = max( f[7],f[5]+val[7] ) = max( 13,16 ) = 16 f[7]=max(f[7],f[5]+val[7])=max(13,16)=16
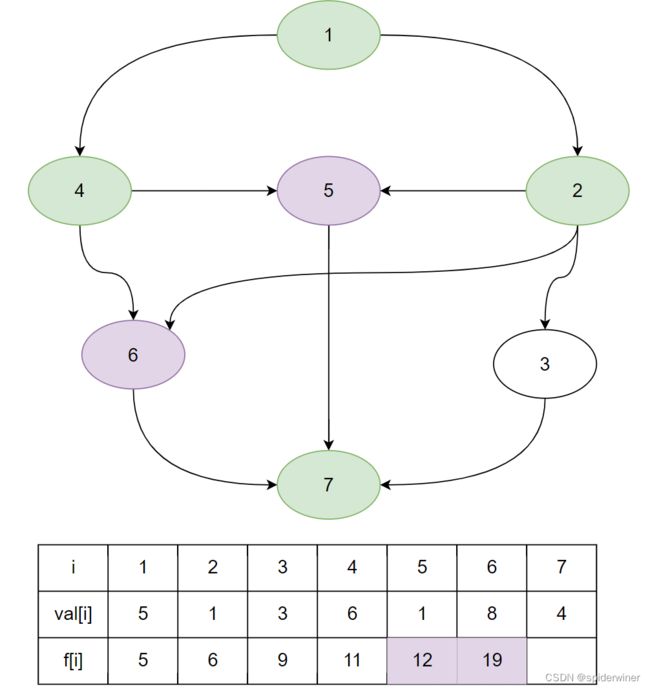
同学们观察上图,还有什么点没有搜索过呀?
剩余点( 6 、 7 6、7 6、7)

f [ 7 ] = m a x ( f [ 7 ] , f [ 6 ] + v a l [ 7 ] ) = m a x ( 16 , 19 + 4 ) = 23 f[7] = max(f[7],f[6]+val[7]) = max(16,19+4) = 23 f[7]=max(f[7],f[6]+val[7])=max(16,19+4)=23
任务 7 7 7 所记录的时间被更新!
由于点 7 7 7 没有延伸点,点 n = 7 n=7 n=7 所记录的就是答案!!!(完成 1 − n 1-n 1−n )所需的最短时间为 f [ 7 ] = 23 f[7]=23 f[7]=23
思路清晰 + 理解透彻,代码就水到渠成!!!
AC_Code
#include 五、总结
本节课讲解了拓扑排序的概念、实现、应用以及复杂度分析。
拓扑排序是一种对有向无环图进行排序的算法,其应用范围非常广泛,例如任务调度、编译器等领域。
拓扑排序的实现需要使用邻接表和入度数组,时间复杂度为O(V+E)。
同学们可以通过练习题和例题来加深对拓扑排序算法的理解和掌握。
六、课后作业
以下是两道拓扑排序相关的课后练习题:
- P2661 [NOIP2015 提高组] 信息传递 普及/提高-
- P8893 「UOI-R1」智能推荐 普及/提高-
希望同学们能够认真完成课后作业,加深对拓扑排序算法的理解和掌握。