Elasticsearch 8.X 如何生成 TB 级的测试数据 ?
1、实战问题
我只想插入大量的测试数据,不是想测试性能,有没有自动办法生成TB级别的测试数据?
有工具?还是说有测试数据集之类的东西?
——问题来源于 Elasticsearch 中文社区
https://elasticsearch.cn/question/13129
2、问题解析
其实类似的问题之前在社群也经常被问到。实战业务场景中在没有大规模数据之前,可能会构造生成一些模拟数据,以实现性能测试等用途。
真实业务场景一般不愁数据的,包含但不限于:
生成数据
业务系统产生数据
互联网、设备等采集生成的数据
其他产生数据的场景.....
回归问题,Elasticsearch 8.X 如何构造呢?
社群达人死敌wen大佬给出的方案:两个 sample data的index来回reindex,一次操作数据量翻倍。
实际,死敌 wen 大佬指的是如下三部分的样例数据。
那么有没有其他的解决方案呢?本文给出两种方案。

3、方案一、elasticsearch-faker 构造数据
3.0 elasticsearch-faker 工具介绍
elasticsearch-faker 是一个用于为 Elasticsearch 生成虚假数据的命令行工具。
它通过模板来定义将要生成的数据结构,并在模板中使用占位符来表示动态内容,比如随机用户名、数字、日期等。
这些占位符将由 Faker 库提供的随机生成数据填充。执行时,该工具会根据指定的模板生成文档,并将它们上传到 Elasticsearch 索引中,用于测试和开发,以检验 Elasticsearch 查询和聚合的功能。
3.1 第一步:安装工具集
https://github.com/thombashi/elasticsearch-faker#installation
pip install elasticsearch-faker
3.2 第二步:制作启动脚本 es_gen.sh
#!/bin/bash
# 设置环境变量
export ES_BASIC_AUTH_USER='elastic'
export ES_BASIC_AUTH_PASSWORD='psdXXXXX'
export ES_SSL_ASSERT_FINGERPRINT='XXddb83f3bc4f9bb763583d2b3XXX0401507fdfb2103e1d5d490b9e31a7f03XX'
# 调用 elasticsearch-faker 命令生成数据
elasticsearch-faker --verify-certs generate --doc-template doc_template.jinja2 https://172.121.10.114:9200 -n 1000同时,编辑模版文件 doc_template.jinja2。
模版如下所示:
{
"name": "{{ user_name }}",
"userId": {{ random_number }},
"createdAt": "{{ date_time }}",
"body": "{{ text }}",
"ext": "{{ word }}",
"blobId": "{{ uuid4 }}"
}3.3 第三步:执行脚本 es_gen.sh
[root@VM-0-14-centos elasticsearch-faker]# ./es_gen.sh
document generator #0: 100%|███████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [00:00<00:00, 1194.47docs/s]
[INFO] generate 1000 docs to test_index
[Results]
target index: test_index
completed in 10.6 secs
current store.size: 0.8 MB
current docs.count: 1,000
generated store.size: 0.8 MB
average size[byte]/doc: 831
generated docs.count: 1,000
generated docs/secs: 94.5
bulk size: 200
3.4 第4步:查看导入数据结果, kibana 查看。


"hits": [
{
"_index": "test_index",
"_id": "2ff2971b-bc51-44e6-bbf7-9881050d5b78-0",
"_score": 1,
"_source": {
"name": "smithlauren",
"userId": 207,
"createdAt": "1982-06-14T03:47:00.000+0000",
"body": "Risk cup tax. Against growth possible something international our themselves. Pm owner card sell responsibility oil.",
"ext": "mean",
"blobId": "c4f5c8dc-3d97-44ee-93da-2d93be676b8b"
}
},
{4、使用 Logstash generator 插件生成随机样例数据

4.1 准备环境
确保你的环境中已经安装了 Elasticsearch 8.X 和 Logstash 8.X。Elasticsearch 应该配置正确,并且运行在 HTTPS 上。
另外,确保 Elasticsearch 的相关证书已经正确配置在 Logstash 中。
4.2 生成样例数据
我们将使用 Logstash 的 generator 输入插件来创建数据,并使用 ruby 过滤器插件来生成 UUID 和随机字符串。
4.3 Logstash 配置
创建一个名为 logstash-random-data.conf 的配置文件,并填入以下内容:
input {
generator {
lines => [
'{"regist_id": "UUID", "company_name": "RANDOM_COMPANY", "regist_id_new": "RANDOM_NEW"}'
]
count => 10
codec => "json"
}
}
filter {
ruby {
code => '
require "securerandom"
event.set("regist_id", SecureRandom.uuid)
event.set("company_name", "COMPANY_" + SecureRandom.hex(10))
event.set("regist_id_new", SecureRandom.hex(10))
'
}
}
output {
elasticsearch {
hosts => ["https://172.121.110.114:9200"]
index => "my_log_index"
user => "elastic"
password => "XXXX"
ccacert => "/www/elasticsearch_0810/elasticsearch-8.10.2/config/certs/http_ca.crt"
}
stdout { codec => rubydebug }
}4.4 分析配置文件
1.Input
a.generator 插件用于生成事件流。
b.lines 包含一个 JSON 字符串模板,它定义了每个事件的结构。
c.count 指定了要生成的文档数量。
d.codec 设置为 json 以告诉 Logstash 期望的输入格式。
2.Filter
a.ruby 过滤器用于执行 Ruby 代码。
b.代码片段内生成了一个 UUID 作为 regist_id。
c.company_name 和 regist_id_new 使用随机十六进制字符串填充。
3.Output
a.指定 Elasticsearch 的主机、索引、用户认证信息及证书。
b.stdout 输出用于调试,它会输出 Logstash 处理后的事件。
4.5 运行 Logstash
将配置文件保存后,在终端运行以下命令以启动 Logstash 并生成数据:
$ bin/logstash -f logstash-random-data.conf执行结果如下:

kibana 查看数据结果如下:
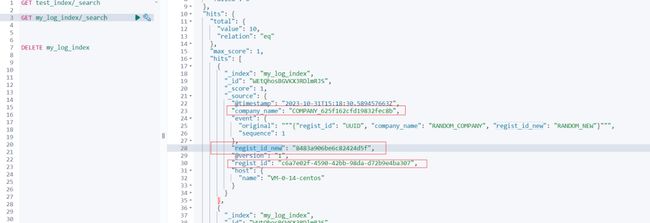
借助 Logstash,我们可以轻松生成大量的随机样例数据,用于 Elasticsearch 的测试和开发。这种方法不仅高效,而且可以灵活地根据需求生成各种格式的数据。
5、小结
上述的验证都是使用 Elasticsearch 8.10.2 版本验证通过的。
其实除了文章给出的两种方案外,还有很多其他的方案,比如:esrally 生成测试数据、借助 Python 的 Faker 实现样例数据构造,Common Crawl、Kaggle 等网站提供大型的公共数据集,可以作为测试数据的来源。
大家有没有遇到类似问题,是如何实现的?欢迎留言交流。
推荐阅读
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单
如何系统的学习 Elasticsearch ?
那些 ChatGPT4 也搞不定的 Elasticsearch 问题,请抛给我们!

更短时间更快习得更多干货!
中国50%+Elastic认证专家出自于此!

比同事抢先一步学习进阶干货!