通用高速缓存原理
文章目录
-
-
- 存储单元
- 存储器层次结构
- 通用高速缓存存储器结构
- 替换策略
- 写策略
- 高速缓存性能评估
- 高速缓存优化方法
-
- 第一种优化方法:增大块大小
- 第二种优化方法:增大缓存容量
- 第三种优化方法:采用多级缓存
- 第四种优化方法:合理利用缓冲区
- 第五种优化方法:路预测
- 其他优化方法
- 其他问题
-
存储单元
不同于主存采用DRAM进行存储,高速缓存一般采用SRAM(Static Random Access Memory)进行存储。与DRAM相比,SRAM的优点是稳定,不需要刷新,并且可以工作在很高的频率下;其缺点是占用面积大,成本高。与ROM或闪存相比,其特点是供电停止后,SRAM中存储的数据也会丢失。
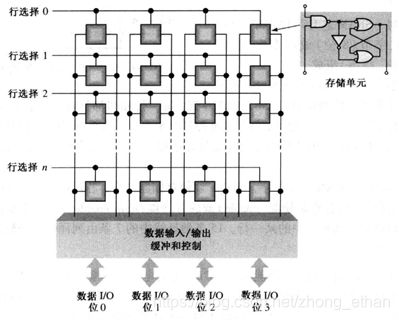
SRAM通常使用锁存器作为存储单元,如下图所示。该存储单元是一个D锁存器,选择信号置为1时,数据输入0,数据输出为0,数据输入为1,数据输出为1。

为了将一个数据单位写到内存阵列指定的单元行中,行选择线就会进入有效状态,并且将四个数据位置于数据输入/输出线上,这是写入线进入有效状态,每一个数据位保存到相关列选中的单元上。为了读出一个数据,读出线进入它的有效状态,使得存储在选择行中的四个数据位出现在数据IO线上。
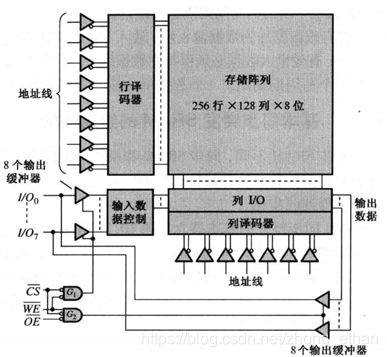
SRAM有异步SRAM,同步SRAM,管道SRAM(PB sram)。异步SRAM不需要时钟,通过使能信号控制数据读出或写入。同步SRAM在时钟边沿工作。管道SRAM通过一个输入输出寄存器,可连续传输数据。
SRAM的端口信号通常有地址线ADDR,输入输出IO,片选信号CS,写使能信号WE和读使能信号OE。
存储器层次结构
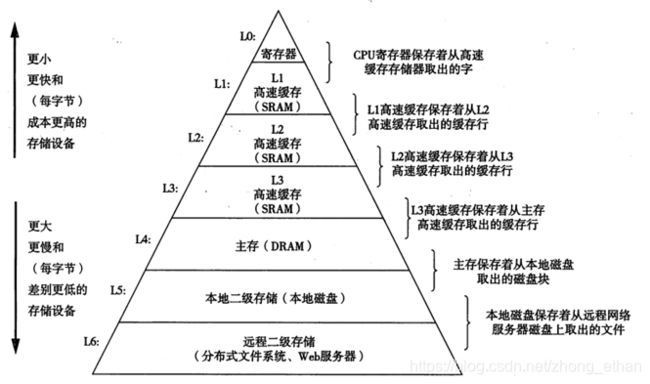
局部性原理指的是一个编写良好的计算机程序倾向于引用邻近于其他最近引用过的数据项,或者最近引用过的数据项本身。局部性通常有时间局部性和空间局部性两种。在一个具有良好时间局部性的程序中,被引用过一次的存储器位置很可能在不远的将来再被多次引用;在一个具有良好空间局部性的程序中,如果一个存储器位置被引用了一次,那么程序很可能在不远的将来引用附近的一个存储器位置。
对于计算机系统来说,程序指令存储在硬盘中。如果处理器取指令每次都从硬盘中取,则一次取指令的周期太长,大大降低处理器的执行效率。为了更快的取指令,可以先把程序以“块”(block)的形式放在主存(DRAM)中。然而,处理器从主存中取指令的周期也比较长,大约为30-200ns。为了再快的取指令,可以再把程序以“块”的形式放在高速缓存(cache)中,处理器从高速缓存中取指令周期大约为0.5-15ns。
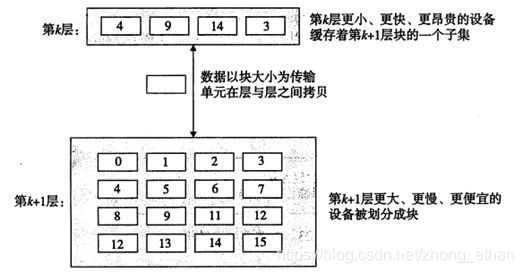
数据在存储器层次之间总是以“块”大小进行传输。高速缓存与主存之间块大小一般为8-64字节;主存与本地存储器之间块大小一般为几百至几千字节。
CPU从缓存中取数据有缓存命中和缓存不命中两种情况。处理器从cache中查找数据d,如果d刚好在cache中,称为缓存命中,CPU直接从cache中取数据;如果cache中没有数据d,称为缓存不命中。需要cache从主存中取出包含数据d的块。如果cache已满,可能就会覆盖一个现存的块。覆盖一个块称为替换。
通用高速缓存存储器结构
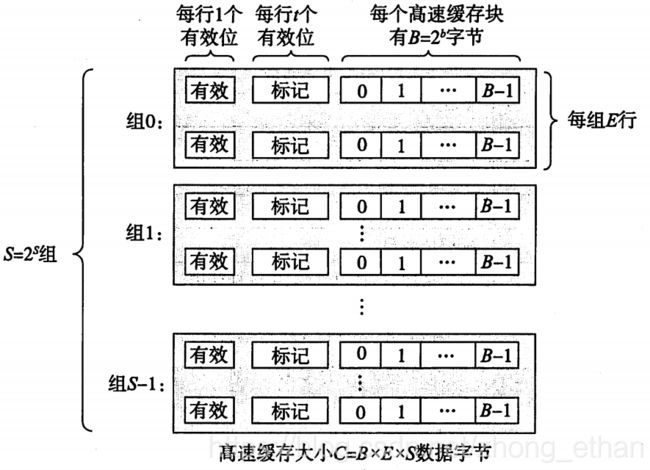
高速缓存分为S个组,每组E行,每行B个字节。总的容量大小为:S * E * B。
一个块首先被映射到一个组中,然后可以将块放在组的任意行中。要查找一个块,首先将块映射到这个组,然后再在组内并行搜索块。
高速缓存的结构将m位地址划分成t个标记位,s个组索引和b个块偏移位
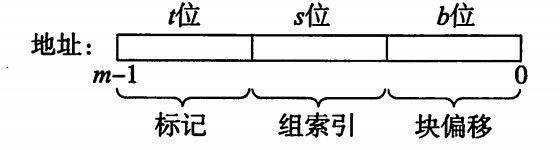
组索引决定当前地址的数据放在哪一组中。根据每组行数,高速缓存被分为不同的类,每组只有一行的高速缓存称为直接映射高速缓存。每组有多个高速缓存行的称为组相联高速缓存。只有一个组的称为全相联高速缓存。全相联高速缓存只适合做小的高速缓存,例如虚拟存储器系统中的翻译备用缓冲器(TLB),用来缓存页表项。
替换策略
如果CPU请求的数据不在高速缓存中,也就是缓存不命中时,高速缓存会从存储器中取出数据。取出数据后,如果数据对应的组中每一行被占用,那么新的数据该替换哪一行呢?
对于直接映射高速缓存,替换策略很简单,直接用新取出的行替换当前行。
对于组相联/全相联高速缓存,有以下几种策略。
- FIFO(first in first out):先进先出,相当于轮流替换;
- 最不常使用策略(least frequently used):替换过去某个时间窗口内引用次数最少的那一行;
- 最近很少使用策略(least recently used):替换最后一次访问时间最久远的那一行。
写策略
假设写命中,即该地址已经被缓存了。有两种策略:
- 直写(write-through):在高速缓存中更新了数据拷贝之后,立即将数据所在的高速缓存块写回到低一层中;
- 写回(write-back):在高速缓存中更新了数据拷贝后,推迟更新,直到替换策略要替换当前高速缓存块时再讲起写入到低一层中。
假设写不命中,有两种策略:
- 写分配(write-allocate):加载相应的低一层中块到高速缓存中,然后更新这个块;这种方法优点是利用了写的空间局部性,缺点是每次不命中都会导致一个块从低一层传送到高速缓存中。
- 非写分配(not-write-allocate):避开高速缓存,直接把这个字写到低一层中。
直写高速缓存通常是非写分配的,写回高速缓存通常是写分配。
高速缓存性能评估
评价缓存性能的一种方法是处理器执行时间。
CPU执行时间 = (CPU时钟周期 + 存储器停顿周期) x 时钟周期数
CPU时钟周期包括处理缓存命中时间。处理器等待存储器访问而停顿时的周期数,称为存储器停顿周期。
存储器停顿周期 = 缺失数 x 缺失代价 = 存储器访问次数 x 缺失率 x 缺失代价
缺失率就是缺失的访问数除以访问总量。缺失情形可以简单分为以下三种类型:
- 强制缺失。对一个数据块的第一次访问,这个块不能在缓存中,所以必须将这个块调入缓存中。
- 容量缺失。如果缓存不能包含程序运行期间所需要的全部块,就会导致有些块被替换,再被调入;
- 冲突缺失。对于组相联高速缓存,多个块会被映射到同一个块中,对不同块的访问会导致有的块被放弃,之后再被调入。
另一个度量高速缓存性能的方法是存储器平均访问时间。
存储器平均访问时间 = 命中时间 + 缺失率 x 缺失代价
高速缓存优化方法
有多种优化方法。从存储器平均访问时间公式来看,优化的目标就是,降低命中时间,降低缺失率,以及降低缺失代价。
第一种优化方法:增大块大小
较大的块利用了空间局域性的优势,降低了强制缺失。但是较大的块会增加缺失代价,如果缓存很小,还会增加容量缺失。

第二种优化方法:增大缓存容量
降低容量缺失最明显的办法就是增大缓存容量。缺点是增加成本和功耗。
第三种优化方法:采用多级缓存
第一级缓存容量小,速度快,足以与处理时钟相匹配。第二级缓存容量大。
第四种优化方法:合理利用缓冲区
在写回策略中,修改一个块先将这个块写入高速缓存中,等到这个块被替换时再写入存储器中。假设一次读取缺失将替换一个脏块,我们不是先将脏块写入到存储器中,再读取存储器,而是先将脏块写入到缓冲区,先读存储器,完成读取操作,再将缓冲区的内容写入到存储器中。对于直接映射高速缓存,如果接下来紧接着读脏块的内容,而脏块还没写入到存储器中,也没有在高速缓存中,则需要等待写入缓冲区为空为止。否则会引起数据冒险。
总的来说,就是使读缺失的优先级高于写入缺失,以降低缺失代价。
第五种优化方法:路预测
这种方法主要针对组相联高速缓存。在缓存的每个块中添加块预测位,根据这些位选定要在下一次缓存访问中优先尝试哪些块。如果预测正确,则访问时间就是这一快速命中时间,若预测错误,则尝试其他块。
其他优化方法
(1)缩短命中时间;小而简单的第一级缓存和路预测
(2)增加缓存带宽;流水化缓存,多组缓存和无阻塞缓存
(3)降低缺失代价;关键字优化,合并写缓冲区
(4)降低缺失率;编译器优化
(5)并行降低缺失代价或缺失率。硬件预取和编译器预取
其他问题
缓存一致性
多级缓存