YOLO V1学习笔记
为什么要学YOLOV1_哔哩哔哩_bilibili
这个视频讲解的很好,建议在看这个之前看看卷积神经网络,会对卷积后的结果理解更加深刻一点。
一 背景
目标检测分为单阶段和两阶段模型。
之前的目标检测DPM、R-CNN、Fast-RCNN、Faster-RCNN都是双阶段模型,也就是说需要先提取候选框,然后对各个候选框进行分类、甄别。双阶段模型没有全图信息,容易丢失很多信息。识别精度高,但是识别速度始终是技术瓶颈。

YOLO V1开启了单阶段模型的大潮流。
最开始对密集的、小物体的检测不很友好,但是随着技术的发展,现在在密集和小物体的检测方面已经相当友好。

map指标:
machine learning - How to calculate mAP for detection task for the PASCAL VOC Challenge? - Data Science Stack Exchange
二 优点
实时识别,yolo的识别非常快;
端到端;
它输入是一张完整的图片,前后文联系会比较紧密。
三 原理
1 预测阶段网络结构:


把它当成黑盒模型就可以啦,只要明确输入和输出。
也可以把这整个过程当作对图像全局信息的编码,从人眼可得到的各种信息转变为方便网络学习的各种特征。
1.1 编码:得到boungding box
输入:一张图片(448*448*3)
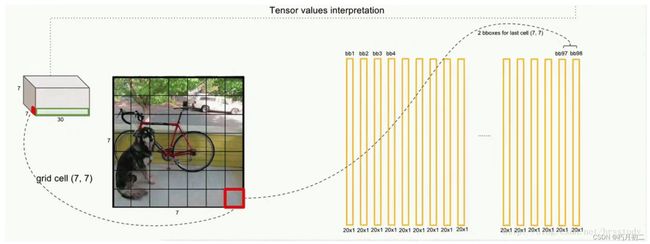
输出:7*7*30的信息张量(其中包含所有预测框的坐标、置信度和类别结果),其实就是boundingbox的信息。
接下来的工作就是对7*7*30的信息张量进行解码。(获取其中的分类+回归的信息)
1.2 解码:表示boungding box的7*7*30

1.3 为什么是7*7?
首先要将输入图片划分为S*S个grid cell。

这里的S=7,所以是7*7,一共是49个grid cell。
1.4 为什么是30?
![]()
每个gridcell包含两个bounding box,通过bounding box来拟合图片中的已标注目标。(yolo将这个任务视为一个监督学习任务,图片中的目标(ground truth)已经人工标注好了。)
也就是一共会有49*2=96个bounding box。
每个bounding box的中心点都在它所属于的grid cell里面。
bounding box的信息表示为![]()
 表示其中心点位置
表示其中心点位置
![]() 表示其高度和宽度
表示其高度和宽度
这四个值唯一确定bounding box
![]() 表示置信度
表示置信度
已经标注好的数据集中分类目标有20类,所以20指的是每个grid cell分别对20个类别的概率。
5是bounding box的信息,如上所述,每个grid cell有两个bounding box。
所以每一个grid cell需要![]() 个数字来描述。
个数字来描述。

其实7*7*30最后的表示就是上图。
2 对bounding box 进行后处理
低置信度过滤、非极大值抑制NMS、去掉重复框(IOU),得到以下预测结果。

3 训练阶段的反向传播
yolo的损失函数:


YOLO1是什么_SiMoNe10010的博客-CSDN博客
当grid cell有物体的时候,计算损失函数第1,2,3,5项,当grid里没有物体的时候计算第4项。
损失函数一共有5项:
1.中心点定位误差
2.宽高定位误差
3.confidence误差
4.不负责检测Bbox confidence误差
5.负责grid cell 检测误差
首先的是中心坐标的损失函数,用了我们最熟悉的均方误差MSE,这个很好理解。(中心点定位误差)
然后是高和宽,没有简单的用MSE,而是用平方根的MSE,这是为什么呢?(宽高定位误差)
第一个原因是更容易优化,但是还有更重要的原因:
看下面的表格:

首先,我们只考虑var1和var2在0和1之间。当var1和var2都很小的时候,也即是w和h都很小,意味着这个物体很小,那么我们应该尽量放大一些损失函数,让模型在识别小物体的时候准确一点。当var1和var2都很大,意味着这个物体也很大,甚至可能已经布满整张图片了,这时我么可以减小一些损失函数,毕竟很大的物体不需要很高的精度。
一句话,使用平方根的MSE而不是MSE其实就是像让模型对小尺度的物体更敏感。或者说,对大的和小的物体同样敏感。
接下来的三项都使用了MSE,其实用交叉熵可能会更好
其中第4项是用来判断一个bounding box中究竟有没有物体的。