JAVA提取嵌套夹带文件之Apache Tika
目录结构
-
- 前言
- tika简介
- Tika支持的文件格式
- MAVEN依赖
- JAVA程序
- JAVA测试程序
- 测试文件
- 测试结果
- 部分文件提取失败
- 参考连接
前言

Apache Tika提取文件整理如下,如有特定的文件需要提取可以先参照【部分文件提取失败】章节对照,以免浪费您的宝贵时间,如有问题或者解决办法还望大牛不吝赐教,小编在此谢过!
tika简介
Tika全名Apache Tika,是用于文件类型检测和从各种格式的文件中提取内容的一个库。
Tika使用现有的各种文件解析器和文档类型的检测技术来检测和提取数据。
使用Tika,可以轻松提取到的不同类型的文件内容,如电子表格,文本文件,图像,PDF文件甚至多媒体输入格式,在一定程度上提取结构化文本以及元数据。
统一解析器接口:Tika封装在一个单一的解析器接口的第三方解析器库。由于这个特征,用户逸出从选择合适的解析器库的负担,并使用它,根据所遇到的文件类型。
使用的Tika facade类是从Java调用Tika的最简单和直接的方式,而且也沿用了外观的设计模式。可以在 Tika API的org.apache.tika包Tika 找到外观facade类。
Tika提供用于解析不同文件格式的一个通用API。它采用83个现有的专业解析器库,所有这些解析器库是根据一个叫做Parser接口单一接口封装。
Tika支持的文件格式
| 文件格式 | 类库 | Tika中的类 |
|---|---|---|
| XML | org.apache.tika.parser.xml | XMLParser |
| HTML | org.apache.tika.parser.htmll and it uses Tagsoup Library | HtmlParser |
| MS-Office compound document Ole2 till 2007 ooxml 2007 onwards | org.apache.tika.parser.microsoftorg.apache.tika.parser.microsoft.ooxml and it uses Apache Poi library | OfficeParser(ole2)OOXMLParser(ooxml) |
| OpenDocument Format openoffice | org.apache.tika.parser.odf | OpenOfficeParser |
| portable Document Format(PDF) | org.apache.tika.parser.pdf and this package uses Apache PdfBox library | PDFParser |
| Electronic Publication Format (digital books) | org.apache.tika.parser.epub | EpubParser |
| Rich Text format | org.apache.tika.parser.rtf | RTFParser |
| Compression and packaging formats | org.apache.tika.parser.pkg and this package uses Common compress library | PackageParser and CompressorParser and its sub-classes |
| Text format | org.apache.tika.parser.txt | TXTParser |
| Feed and syndication formats | org.apache.tika.parser.feed | FeedParser |
| Audio formats | org.apache.tika.parser.audio and org.apache.tika.parser.mp3 | AudioParser MidiParser Mp3- for mp3parser |
| Imageparsers | org.apache.tika.parser.jpeg | JpegParser-for jpeg images |
| Videoformats | org.apache.tika.parser.mp4 and org.apache.tika.parser.video this parser internally uses Simple Algorithm to parse flash video formats | Mp4parser FlvParser |
| java class files and jar files | org.apache.tika.parser.asm | ClassParser CompressorParser |
| Mobxformat (email messages) | org.apache.tika.parser.mbox | MobXParser |
| Cad formats | org.apache.tika.parser.dwg | DWGParser |
| FontFormats | org.apache.tika.parser.font | TrueTypeParser |
| executable programs and libraries | org.apache.tika.parser.executable | ExecutableParser |
MAVEN依赖
目前已经有2.8.0版本,有兴趣的朋友可以尝试一下,使用感受可以和小编交流一下哦~
<repositories>
<repository>
<id>com.e-iceblueid>
<name>e-icebluename>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/url>
repository>
repositories>
<dependencies>
<dependency>
<groupId>org.apache.tikagroupId>
<artifactId>tika-parsersartifactId>
<version>1.24version>
dependency>
<dependency>
<groupId>org.apache.tikagroupId>
<artifactId>tika-coreartifactId>
<version>1.24version>
dependency>
dependencies>
JAVA程序
package com.xxx.xxx.carry;
import cn.hutool.core.lang.UUID;
import com.jacob.activeX.ActiveXComponent;
import com.jacob.com.ComThread;
import com.jacob.com.Dispatch;
import com.jacob.com.Variant;
import org.apache.commons.io.FilenameUtils;
import org.apache.tika.config.TikaConfig;
import org.apache.tika.detect.Detector;
import org.apache.tika.exception.TikaException;
import org.apache.tika.extractor.EmbeddedDocumentExtractor;
import org.apache.tika.extractor.ParsingEmbeddedDocumentExtractor;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.mime.MediaType;
import org.apache.tika.mime.MimeTypeException;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.ContentHandler;
import org.xml.sax.SAXException;
import java.io.IOException;
import java.io.InputStream;
import java.nio.file.Files;
import java.nio.file.Path;
public class CarryingFileUtils {
// 创建解析器,使用AutoDetectParser可以自动检测一个最合适的解析器
private static Parser parser = new AutoDetectParser();
private static Detector detector = ((AutoDetectParser) parser).getDetector();
private static TikaConfig config = TikaConfig.getDefaultConfig();
public static void extract(InputStream is, Path outputDir) throws SAXException, TikaException, IOException {
Metadata m = new Metadata();
// 指定最基本的变量信息(即存放一个所使用的解析器对象)
ParseContext c = new ParseContext();
BodyContentHandler h = new BodyContentHandler(-1);
c.set(Parser.class, parser);
EmbeddedDocumentExtractor ex = new MyEmbeddedDocumentExtractor(outputDir, c);
c.set(EmbeddedDocumentExtractor.class, ex);
// InputStream-----指定文件输入流
// ContentHandler--指定要解析文件的哪一个内容,它有一个实现类叫做BodyContentHandler,即专门用来解析文档内容的
// Metadata--------指定解析文件时,存放解析出来的元数据的Metadata对象
// ParseContext----该对象用于存放一些变量信息,该对象最少也要存放所使用的解析器对象,这也是其存放的最基本的变量信息
parser.parse(is, h, m, c);
}
private static class MyEmbeddedDocumentExtractor extends ParsingEmbeddedDocumentExtractor {
private final Path outputDir;
private int fileCount = 0;
private MyEmbeddedDocumentExtractor(Path outputDir, ParseContext context) {
super(context);
this.outputDir = outputDir;
}
@Override
public boolean shouldParseEmbedded(Metadata metadata) {
return true;
}
@Override
public void parseEmbedded(InputStream stream, ContentHandler handler, Metadata metadata, boolean outputHtml) throws IOException {
//try to get the name of the embedded file from the metadata
String name = metadata.get(Metadata.RESOURCE_NAME_KEY);
if (name == null) {
name = "file_" + fileCount++;
} else {
//make sure to select only the file name (not any directory paths
//that might be included in the name) and make sure
//to normalize the name
name = name.replaceAll("\u0000", " ");
int prefix = FilenameUtils.getPrefixLength(name);
if (prefix > -1) {
name = name.substring(prefix);
}
name = FilenameUtils.normalize(FilenameUtils.getName(name));
}
//now try to figure out the right extension for the embedded file
MediaType contentType = detector.detect(stream, metadata);
if (name.indexOf('.') == -1 && contentType != null) {
try {
name += config.getMimeRepository().forName(
contentType.toString()).getExtension();
} catch (MimeTypeException e) {
e.printStackTrace();
}
}
// 夹带文件名编码格式调整
name = new String(name.getBytes("ISO-8859-1"), "GBK");
Path outputFile = outputDir.resolve(name);
if (Files.exists(outputFile)) {
outputFile = outputDir.resolve(UUID.randomUUID().toString() + "-" + name);
}
Files.createDirectories(outputFile.getParent());
String formart = name.substring(name.lastIndexOf(".") + 1).toUpperCase();
// 去除无关文件
if (!"EMF,WMF".contains(formart)) {
Files.copy(stream, outputFile);
}
}
}
}
JAVA测试程序
package com.xxx.xxx.utils;
import com.xxx.xxx.carry.CarryingFileUtils;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.InputStream;
import java.nio.file.Path;
import java.nio.file.Paths;
public class Jkx {
public static void main(String[] args) {
// 提取文件
String inputFilrPath = "C:\\Users\\Administrator\\Desktop\\file_check\\qiantao\\Excel文件嵌套doc.xlsx";
// 输出文件路径
String outFilePath = "C:\\Users\\Administrator\\Desktop\\file_check\\nest_file\\";
try {
InputStream inputStream = new BufferedInputStream(new FileInputStream(inputFilrPath));
Path outFileUrl = Paths.get(outFilePath);
CarryingFileUtils.extract(inputStream, outFileUrl);
} catch (Exception e) {
e.printStackTrace();
}
}
}
测试文件
测试文件_百度网盘提取链接
测试结果
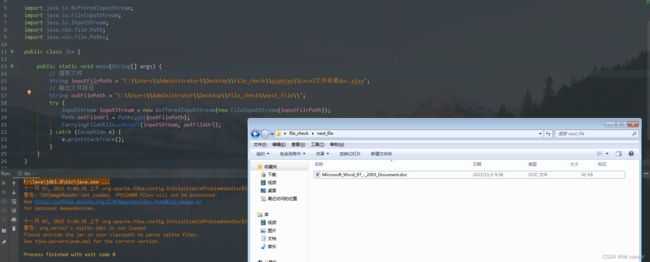
部分文件提取失败
提取失败文件整理如下,如有大牛有解决办法还望不吝赐教:
| 文件类型 | 嵌套文件类型 |
|---|---|
| .dot | .doc |
| .doc | .docm |
| .doc | .wps |
| .wps | .wps |
| .xls | .xls |
| .et | .et |
| .xls | .et |
| .xltm | .ett |
| .pps | .ppt |
| .html | .wps |
| .mht | .wps |
| .mhtml | .wps |
| .pot | .pot |
| .cebx | .* |
| .dot | .doc |
| .dps | .dps |
| .pptx | .dps |
| .dpt | .dps |
| .docx | .eid |
| .doc | .eis |
| .png | .odp |
| .png | .ods |
| .png | .odt |
参考连接
- https://www.jianshu.com/p/407735f03094?v=1672195773961