python办公自动化(八)python-docx实现word的批量合并、制作邀请函以及数据的情感分析
合并多个word文件
现有3个word文档,需要把3个文档里的内容放到新的文档里,实现将多个word文件合并到一个word文件里。

1.获取文件夹下所有文件的路径
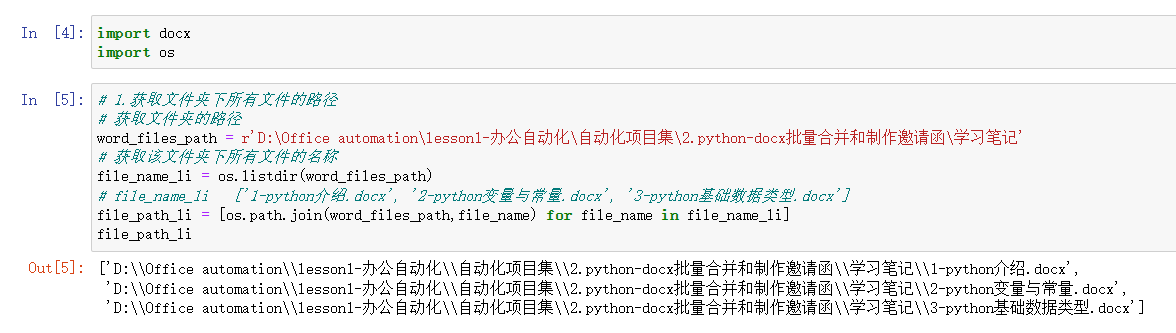
2.合并多个docx文件
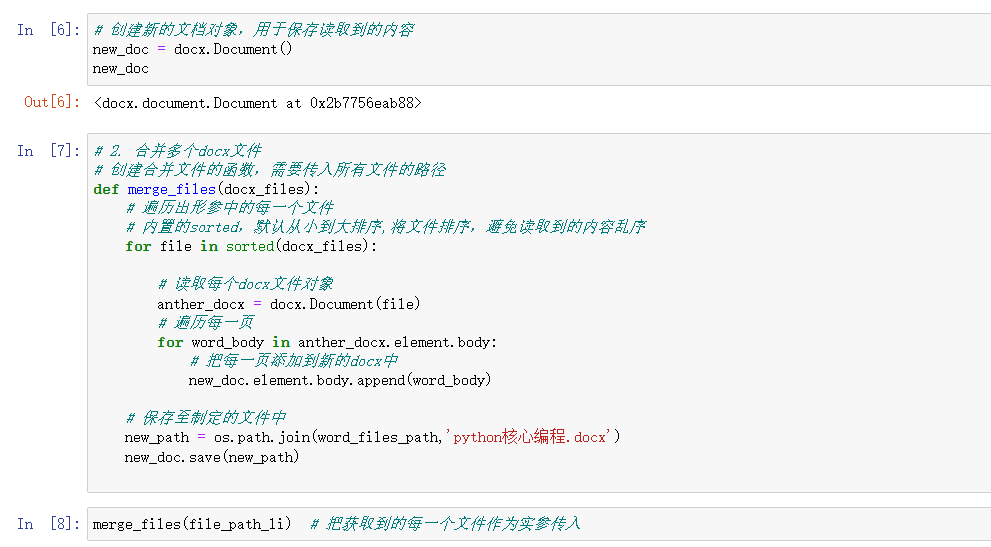
实现了按顺序获取每一个word文档,分别读取文档中每一页的内容,放到新的文档中,保留原文档的格式。

制作邀请函
制作邀请函,实现word与excel的合并,将excel中的信息填到word对应的位置。
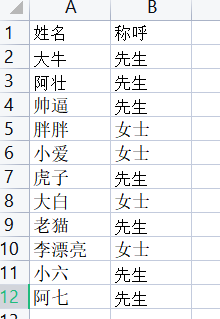

模板中的姓名和性别是需要动态更改的,将excel中的信息填入到模板中,日期是生成邀请函的日期。
1.实现一次的数据替换


运行后可以看到,在邀请函文件夹下生成了新的文件,打开后姓名,性别,今天日期数据都进行了替换。


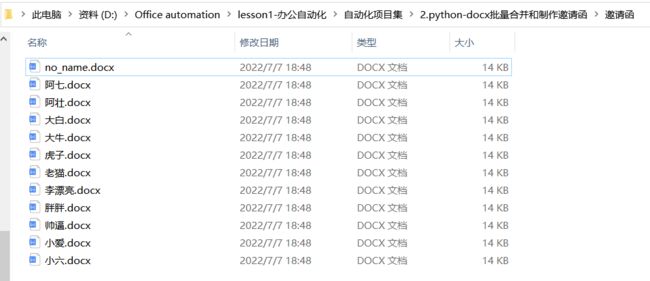
2.批量生成邀请函
实际操作中,用户数据信息都存在excel表格中,需要从excel中获取有用的信息。

程序运行完成后,可以看到在邀请函文件夹下批量生成了所有用户信息的邀请函文件,可以随意打开一个进行验证。

数据情感分析
在涉及市场、运营的过程中,经常根据产品的评论进行情感分析来了解产品的口碑,区分对产品的评价是正向还是负向的,根据反馈结果改变产品的特性。如对外卖的评价,味道很好,但是配送速度慢,从这可以看出对产品内容的评价,对口味的评价是正面的,对配送时间的评价是负面的,我们可以根据这个两个评价内容对口味进行精进,对配送时间进行改进,来调整用户的体验和好感度,这就是比较简单的情感分析。我们会根据多人对外卖的评价来进行情感色彩的分析,把外卖评价的关键词提取出来,进行统计和分类,以致于整个导向和结果等都是建立在数据科学之上,用于更深层次的分析产品。
人工对关键词的分析及产品的评价有很大的局限性。1.不够公平,因为对外卖配送速度的评价,不同人观点不同,有人认为是个问题,有人认为无关紧要。每个人对词语感情色彩的理解不一样,分析时不够公平。2.产品评价非常多,随着用户的增加,评价会不定期的增加,人工分析很难确保及时性,比如分析完前一个月的评价,后面几天的评价数据也在不断增加,分析时可能会错过后面的评价。
在进行词语的情感分析时,我们通常会借助到python的工具来进行,涉及到三步,一是分词,二是优化分词后的词语,三是对词语进行情感分析。
分词
要判断一段话表达的情感是正向还是负向,就需要根据这句话中的关键词来得到情感的倾向。一句话中出现了开心、高兴、物超所值等正向的词语,我们就可以认定,这条产品的评价是正向的;相反出现不开心、非常差等词语,那么评价就是偏负向的。
进行情感分析,首先要将句子的词汇分开,以便于统计词语的词性。分词的定义:简单的说就是将一句话根据语义划分成多个词语。当面对大量评价的时候,就需要借助更加专业的工具,如python的jieba库。
安装的代码为
pip install jieba
例题
将以下评论自动分词。
速度快,包装好,看着特别好,喝着肯定不错!物美价廉
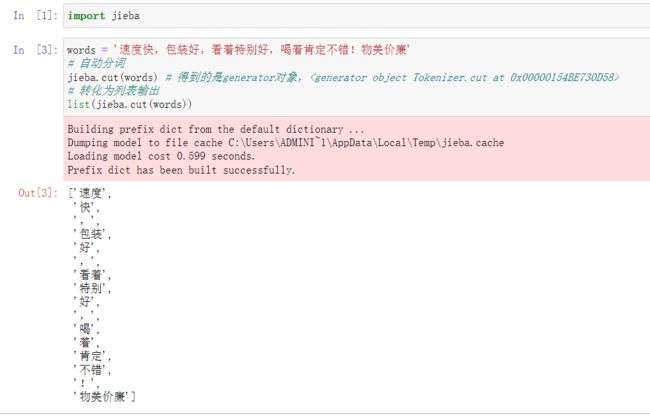
使用jieba分词得到的是generator object,可以强转为列表输出,可以看到分词的精确度比较高,本质上jieba的分词是依赖于词库实现的,比人为的分词要更加精准。注意,在英文中的单词是以空格的形式分隔的,我们在分词的时候也需要 把每个词汇用空格进行分割。

发现在分词后,把逗号,感叹号等都当成了一个词语,而这些对情感分析并没有多大的作用,还有可能影响未来分析的准确性,就需要对分词的结果进行优化
优化分词结果
优化分词的目的在于,节省空间和提高匹配词语情感倾向的效率。避免了无用词对情感分析结果的影响,这也是优化分词的目的。
优化分词的手段有两种,一是删除停用词(stop words),即是去除掉无用的词语,二是根据词性提取关键词
删除停用词
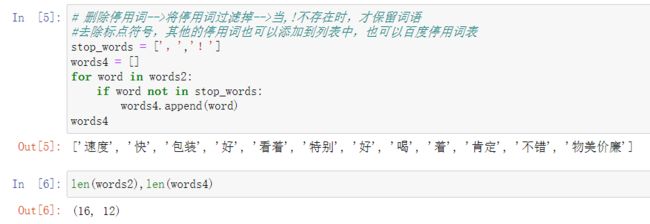
可以看到没有删除停用词的words2长度为16,删除后的words4长度为12,可以百度搜索停用词表,可以放到停用词的列表中进行过滤。
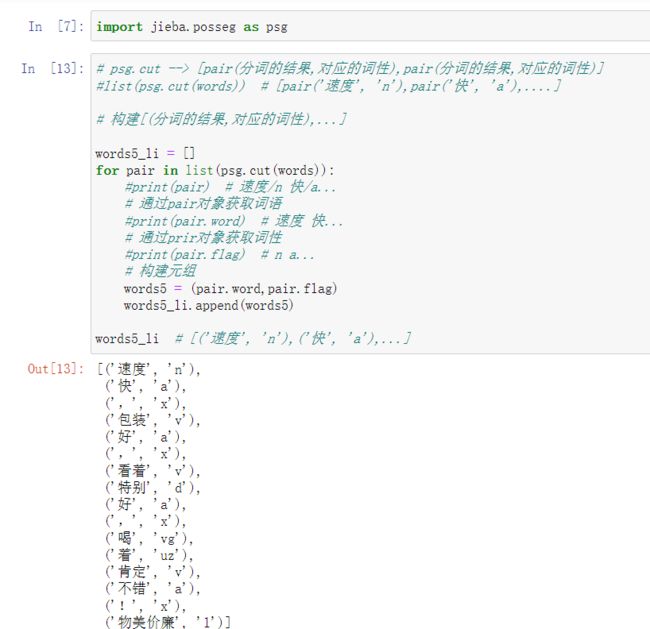
根据词性提取关键词
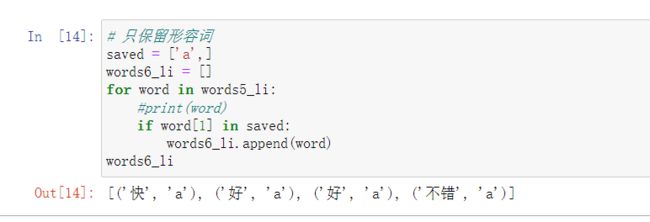
好、非常好、物美价廉等都是形容词,我们可以根据词性提取出对应对应词性的词汇。
| 标签 | 含义 | 标签 | 含义 |
|---|---|---|---|
| n | 普通名词 | ad | 副形词 |
| nr | 人名 | q | 量词 |
| ns | 地名 | u | 助词 |
| a | 形容词 | r | 代词 |
| m | 数量词 | p | 介词 |
| c | 连词 | t | 时间 |
| v | 普通名词 | d | 副词 |
语义情感分析
基于获得的词语,对产品进行分析,得到正向或者负向的结果。可以借助于snownlp库对已经分好词的语句,进行统计词进行正向、负向的情感倾向。snownlp库可以实现分词,也可以计算出词汇出现的频率。snownlp库会将“不喜欢”分成“不”和“喜欢”两个词,会把否定的词分成正向的词汇,会产生较大的误差,所以我们采用jieba进行分词,然后再用snownlp库来实现语义情感分析。

正面,负面的词定义的标准是可以定义的,如果把值定义为0.8,则就会变成1个正面词汇,3个负面词汇。